 AI的定位和導航類似于大腦的位置細胞和網格細胞
AI的定位和導航類似于大腦的位置細胞和網格細胞
近日,DeepMind 在 Nature 上發表的一篇論文引起 AI 領域和神經科學領域的極大震撼:AI 展現出與人腦 “網格細胞” 高度一致的空間導航能力。甚至有些學者認為,憑著這篇論文,DeepMind 的作者有可能問鼎諾貝爾獎。本文作者鄧侃博士對這篇突破性的論文進行了解讀。
Google 麾下的 DeepMind 公司,不僅會下圍棋,而且寫的論文也頂呱呱。
2018/5/10,今天的微信朋友圈,被DeepMind 一篇論文刷屏了。論文發表在最近一期 Nature 雜志上,題目是Vector-based navigation using grid-like representations in artificial agents [1]。

有些學者認為,憑著這篇論文,DeepMind 的作者有可能問鼎諾貝爾獎[2]。
重要意義:AI的定位和導航類似于大腦的位置細胞和網格細胞
其實這篇論文是DeepMind 人工智能團隊,與 University College of London(UCL) 的生物學家,合作的產物。
對空間的定位和導航能力,是生物的本能。早在 1971 年,UCL 的生理學教授 John O'Keefe 在大腦海馬體中,發現了位置細胞(Place Cell)。隨后 O'Keefe 的學生,Moser 夫婦于 2005 年發現,在大腦內嗅皮層,存在一種更為神奇的神經元,網格細胞(Grid Cell)。在運動過程中,生物的網格細胞,把空間分割為蜂窩那樣的六邊形,并且把運動軌跡記錄在蜂窩狀的網格上。
2014 年的諾貝爾生理學/醫學獎,頒發給了John O'Keefe 和Moser 夫婦。
人工智能深度學習模型,經常被詬病的一大軟肋,是缺乏生理學理論基礎。深度學習模型中的隱節點的物理意義,也無法解釋。
DeepMind 和 UCL 合著的 Nature 論文,發現深度學習模型中隱節點,與腦內的位置細胞和網格細胞,這兩者的激活機制和數值分布,非常相似,幾乎呈一一對應的關系。
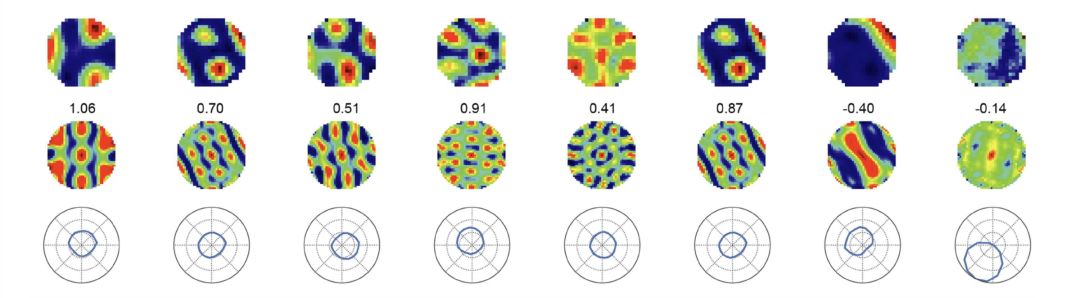
Extended Data Fig 3.d:第一行,深度學習模型的隱節點的激活機制和數值分布。第二行,Moser 夫婦發現的網格細胞的蜂窩狀數值分布。深度學習隱節點與網格細胞的數值分布,極為相似。第三行,數值分布所揭示的空間定位及運動方向。
這篇論文,之所以引起學界轟動,原因在于證明了,把深度學習模型用于空間的定位和導航,其隱節點的物理意義,類似于大腦的位置細胞和網格細胞。進一步猜想,深度學習模型的定位和導航的計算過程,很可能與大腦的定位和導航的生理機制,也極為相似。
為什么DeepMind 熱衷于玩游戲?
面向空間定位和導航的深度學習模型,有哪些應用場景呢?DeepMind 把這個技術用于玩電子游戲,類似于 “反恐精英”(Counter Strike)那樣的走迷宮射殺***的游戲。
DeepMind 下完圍棋以后,玩初級電子游戲,現在升級了,改玩高級游戲了。為什么DeepMind 那么熱衷于游戲呢?
游戲是仿真系統,一切盡在掌控之中,想要什么數據,就能獲取什么數據。所以,每條數據,都很全面,不會有數據丟失。
同時,只要多雇一些玩家,多花一點時間,要多少訓練數據,就有多少訓練數據。
用游戲來驗證深度學習模型,非常方便。這是 DeepMind 熱衷于玩游戲的原因。同時,因為能夠快速地獲取數據,DeepMind 對于深度學習和強化學習研究,領先世界。
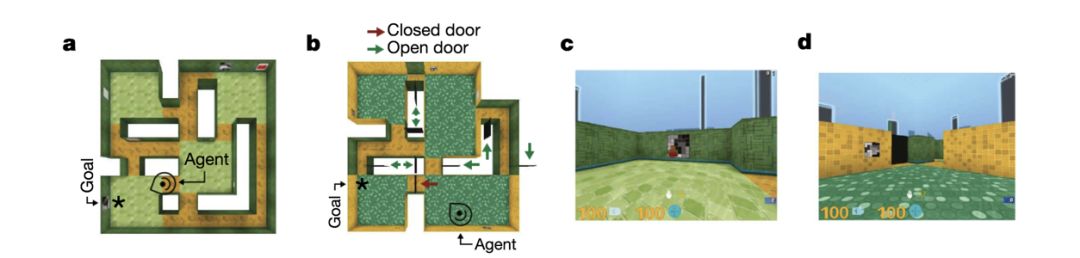
Figure 3. DeepMind 把基于深度學習的空間定位和導航技術,應用于反恐精英(Counter Strike)游戲。
問題是,把適用于游戲的深度學習模型,移用到真實世界,解決實際問題,是否仍然有效?
同是 Google 麾下兄弟,Google Brain 更注重解決實際問題,兄弟倆各有千秋。Google Brain 開發的 Tensorflow成為工程利器,而 DeepMind 的論文,提供新方法,引領研究前沿。
深度學習仿真位置和網格細胞的論文,技術上有什么創新?
短的答案,沒有獨特的創新。
長的答案,得先講講馬爾科夫和強化學習。
強化學習(Reinforcement Learning)是機器學習的一個重要分支,它試圖解決決策優化的問題。所謂決策優化,是指面對特定狀態(State,S),采取什么行動方案(Action,A),才能使收益最大(Reward,R)。很多問題都與決策優化有關,從下棋,到投資,到課程安排,到駕車,到走迷宮等等。
AlphaGo 的核心算法,就是強化學習。AlphaGo不僅穩超勝券地戰勝了當今世界所有人類高手,而且甚至不需要學習人類棋手的棋譜,完全靠自己摸索,在短短幾天內,發現并超越了一千多年來人類積累的全部圍棋戰略戰術。
最簡單的強化學習的數學模型,是馬爾科夫決策過程(Markov Decision Process,MDP)。之所以說 MDP 是一個簡單的模型,是因為它對問題做了很多限制。
1. 面對的狀態 s_{t},數量 t = 1... T,T 是有限的。
2. 采取的行動方案 a_{t},數量t = 1... T,T也是有限的。
3.對應于特定狀態 s_{t},當下的收益 r_{t} 是明確的。
4. 在某一個時刻 t,采取了行動方案 a_{t},狀態從當前的 s_{t} 轉換成下一個狀態 s_{t+1}。下一個狀態s_{t+1}有多種可能,從當前狀態 s_{t}轉換到下一個狀態中的某一種狀態的概率,稱為轉換概率。但是轉換概率,只依賴于當前狀態 s_{t},而與先前的狀態,s_{t-1}, s_{t-2} ... 無關。
解決馬爾科夫決策過程問題的常用的算法,是動態規劃(Dynamic Programming)。
對馬爾科夫決策過程的各項限制,不斷放松,研究相應的算法,是強化學習的目標。
例如對狀態 s_{t}放松限制,
1. 假如狀態 s_{t} 的數量t = 1... T,T雖然有限,但是數量巨大,或者有數量無限,如何改進算法?
2.假如狀態 s_{t} 不能完全確定,只能被部分觀察到,剩余部分被遮擋或缺失,如何改進算法?
3. 假如轉換概率,不僅依賴于當前狀態,而且依賴于先前的運動軌跡,如何改進算法?
4. 假如遇到先前沒有遇見過的新狀態s_{t},有沒有可能在以往遇見過的狀態中,找到相似狀態,從而估算轉換概率,估算收益?
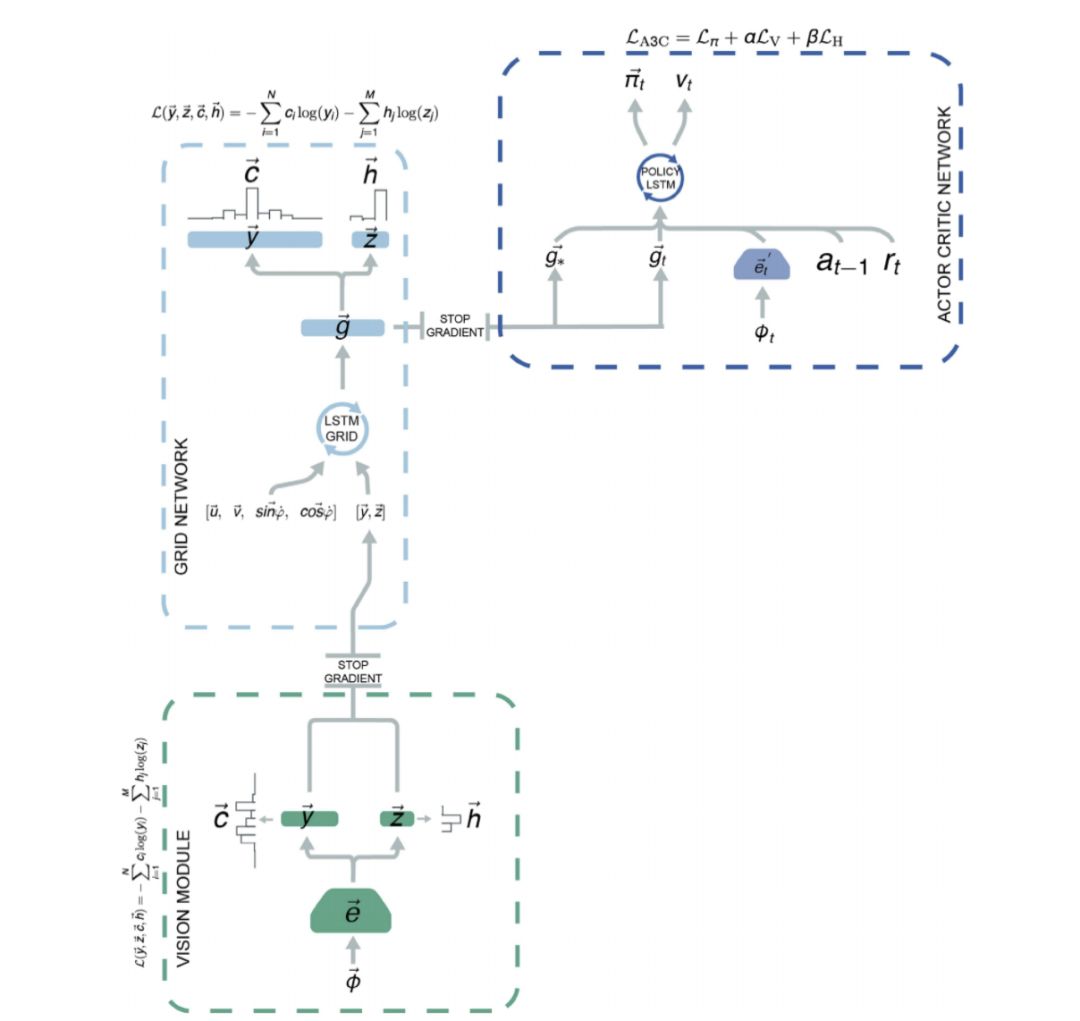
Extended Data Fig 5. 用GridLSTM 來總結以往的運動軌跡,并加上神經網絡 g 來判別當前的空間定位和運動方向。然后基于對當前的空間定位和導航的判斷,用另一個 LSTM 來估算狀態轉換概率,從而決定導航策略。
這篇論文用深度學習模型,來仿真位置和網格細胞。具體來說,
1.用 CNN 來處理圖像,找到周邊環境中的標志物,用于識別當前的空間位置。
2. 把圖像處理的結果,與以往的運動軌跡相結合,用GridLSTM 來估算當前的狀態。
3. 把GridLSTM 估算出的當前狀態,經過一個神經網絡 g 的再加工,得到類似于位置細胞和網格細胞的隱節點。
4. 把當前的位置和運動方向,以及目標的位置,作為第二個 LSTM 模型的輸入,確定導航決策。
上述所有模塊,都是現成技術的集成,并無顯著創新。
-
導航
+關注
關注
7文章
523瀏覽量
42382 -
人工智能
+關注
關注
1791文章
46896瀏覽量
237671 -
深度學習
+關注
關注
73文章
5493瀏覽量
121000
原文標題:專家解讀DeepMind最新論文:深度學習模型復現大腦網格細胞
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
人類首創能生成神經細胞的“迷你大腦”,更精確模擬神經網絡!
人工智能可助辨識細胞結構
細胞融合與單克隆抗體
血細胞的產生與美國科學家成功制造出具有造血干細胞功能的細胞
首次創造出能生成神經細胞的3D版“迷你大腦”
“解碼”單細胞測序的故事
基于人類乳腺細胞圖譜中各細胞亞型之間的位置關系和空間聯系

單細胞細胞注釋詳解之singleR細胞注釋
活細胞的“聚光燈”——前沿活細胞成像的案例分享






 工商網監
工商網監
評論