 谷歌近日發明了一款能自動捕捉精彩時刻的相機
谷歌近日發明了一款能自動捕捉精彩時刻的相機
想記錄美好瞬間,手機還沒掏出來就結束了,怎么辦!不要慌,谷歌近日發明了一款能自動捕捉精彩時刻的相機,它能識別出那些有意義、值得記錄的場景,并在博客上公開了這一技術。以下是論智的編譯。
對我來說,照相就是在一瞬間,對某件事的本質和組織形式進行同步記錄的過程。——Henri Cartier-Bresson
過去幾年,AI產品呈現爆炸式增長,深度學習算法讓計算機視覺技術能認得一幅好照片滿足的各種元素:人物、微笑、寵物、落日、著名地標等等。但是,除了最近的進步,自動拍照仍然是一個非常具有挑戰性的問題,即相機能否自動捕捉到一個完美的瞬間呢?
最近,我們發布了Google Clips,這款相機無需手動操作,就能自動捕捉你生活中有趣的時刻。在設計它時,我們遵循了三條重要的原則:
我們想將計算設計成置于移動端的。除了延長電池的壽命并減少延遲,在移動設備中進行處理意味著你所有的照片都不會自動從設備上刪除,除非你想保存或分享它們,這是有關隱私控制的關鍵。
我們想讓設備捕捉短視頻,而非單一的照片。有動作的時刻才是真正的回憶,并且錄像比拍照要容易得多。
我們想捕捉人或寵物隨意自然的時刻,而不想拍出一張抽象的藝術照。也就是說,我們不會教Clips考慮構圖、色彩平衡、光線等因素,而是要注意選擇拍攝的時間,其中要包含人或動物有趣的瞬間。
學習辨認美好瞬間
如何訓練一套算法學會辨認有趣的時刻呢?和眾多機器學習問題一樣,我們先從數據集開始。我們創建了一個含有上千段視頻的數據集,視頻展示的是不同場景,假設這是用Clips制作出來的。同時,還要保證視頻涵蓋了不同種族、性別和年齡階段的人。之后,我們招募了一些專業攝影師和視頻編輯師,對這些視頻加注并選出最佳短視頻片段。篩選之后,剩余的視頻讓我們對算法最后達到的目標有了概念。但是,只靠這些由人類挑選出來的視頻訓練算法仍然很困難,我們還需要得到一個平滑的標簽梯度,從“perfect”到“terrible”,讓算法學會辨認照片的質量。
為了解決這個問題,我們又加入了一種數據收集方法,目的是讓模型生成連續高質量的視頻。我們吧每段視頻分割成一小段一小段的(就像Clips捕捉到的那樣),然后隨機選取兩段作為一組,讓人們從中選出他們認為更好地一段。
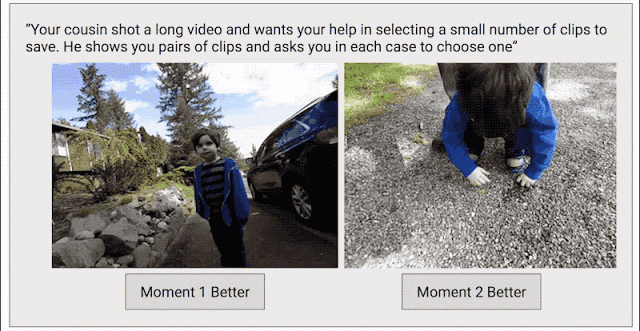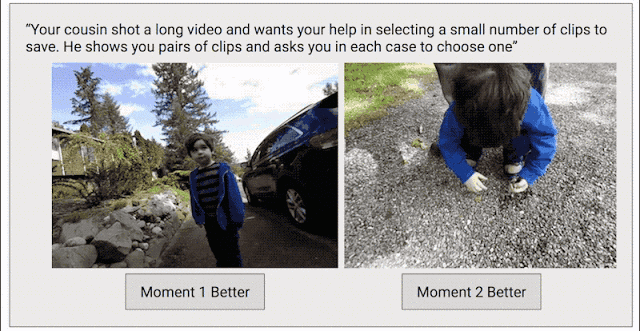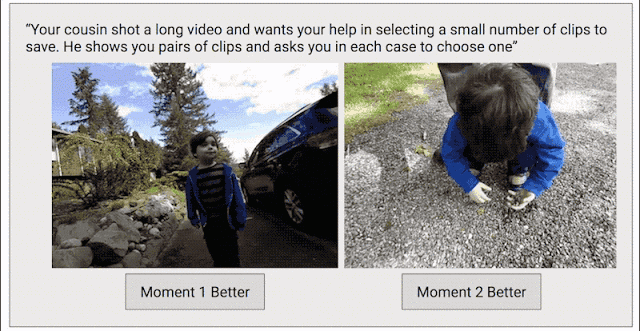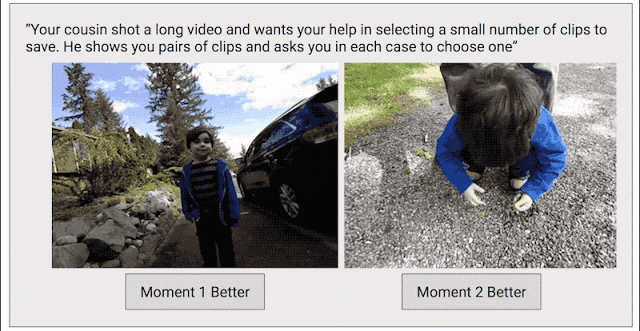
我們之所以選用這種比較法而不直接讓人打分,正是因為二選一比打出具體的分數更容易。我們發現,大家在做二選一時的意見是比較一致的,如果打分的話就不那么統一了。如果某段視頻經過足夠多的小片段對比,我們就能計算出整段視頻的連續質量分數。在這一過程中,我們從超過1000段視頻中一共收集了5000萬個對比片段,工作量真的非常大!
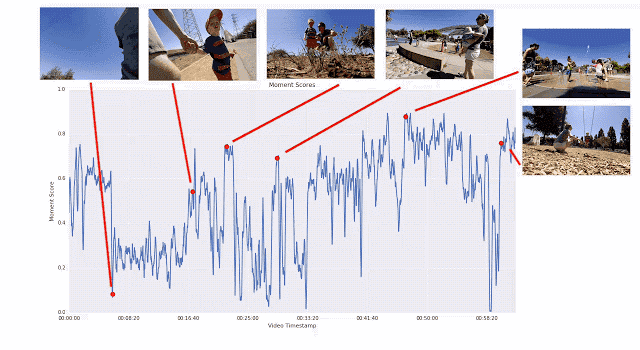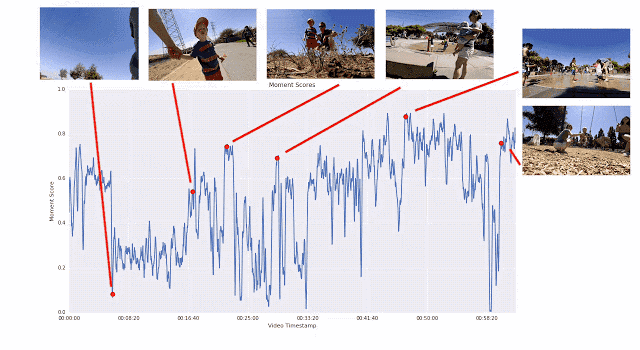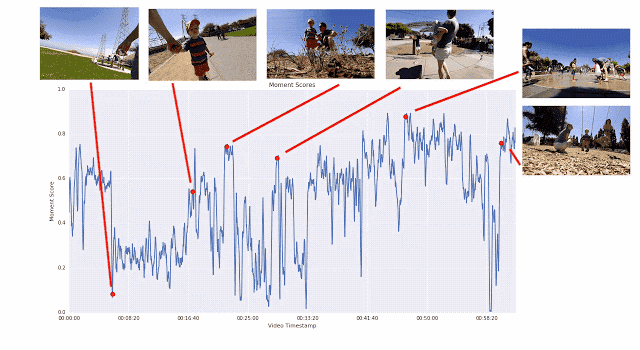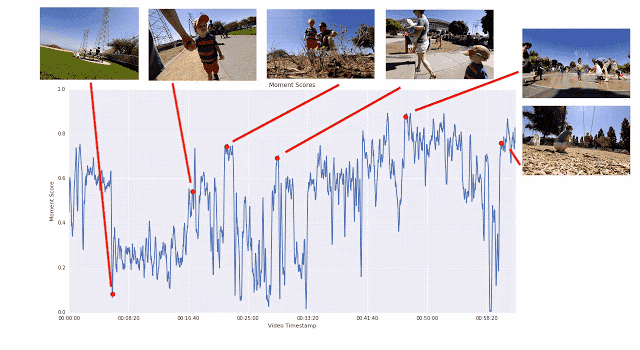
訓練視頻片段質量模型
有了上述的質量分數作為訓練數據,下一步我們就要訓練神經網絡模型預測設備所拍攝的照片質量。首先,我們假設:模型如果能知道照片里有什么(人物、狗狗或者大樹等等),將有助于提高視頻的趣味性。如果這個假設是對的,我們可以學習一個方程,通過辨認照片上的內容預測短視頻的質量分數。
為了辨認我們訓練數據中的內容標簽,我們用了谷歌圖像搜索中的機器學習技術,它可以辨認超過27000種不同的標簽,包括描述物體、概念和動作等標簽。當然,我們不會用到所有的標簽,專業的攝影師只從中挑選了幾百個他們認為“有趣的”標簽。我們還添加了其他能描述照片質量的標簽。
標簽集建立好之后,我們就需要設計一個緊湊高效的模型,可以預測任意提供的照片。由于計算機視覺技術背后都需要強大的GPU支持,想讓算法在移動設備上運行很可能會使速度降低許多。為了訓練這個移動設備模型,我們首先建立了大型照片數據集,然后用谷歌的圖像識別模型預測每個被打上“有趣”標簽的照片可信度。然后訓練一個MobileNet圖像內容模型(ICM),模仿谷歌模型的預測結果。這樣這一緊湊的模型就能夠辨認出照片中最有趣的元素了,同時還能忽略不相關的內容。
最后一步,就是要根據ICM判斷的內容預測單張照片的質量分數。這一分數是由一個分段線性回歸模型計算出來的,它結合了ICM的輸出和幀質量分數。這個幀質量分數是由視頻片段組合成摸個靜止時刻的分數再取平均數得來的。通過讓人們對兩個視頻片段進行對比,我們的模型應該會計算出比人類更高的分數。這一模型經過訓練,所以它的預測盡可能地和人類的選擇相似。
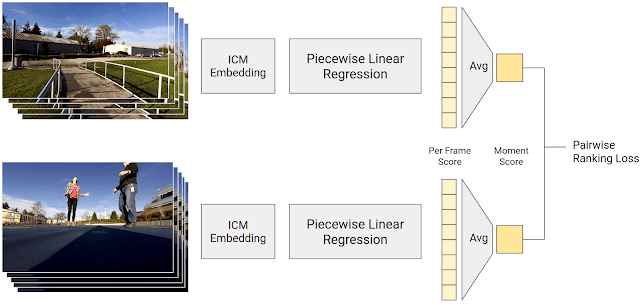
生成幀質量分數的訓練過程。分段線性回歸將ICM的嵌入映射到一個分數
這一過程訓練出的模型既有谷歌圖像識別技術,又加入了人類打分員的評分。雖然由數據生成的結果很好地定義了哪些是“有趣時刻”,但我們仍然在某些情境中加入了額外分數,因為我們希望能讓Clips捕捉到,包括人臉、微笑、寵物等。在最近的版本中,我們還加入了例如擁抱、親吻、跳躍、跳舞等特殊的動作。分辨這些活動需要擴展ICM模型。
拍照控制器
有了預測場景趣味性的模型,Clips相機可以實時決定該捕捉哪些鏡頭。模型的拍照控制算法遵循了以下三個原則:
分別供能 & 熱成像:我們想讓Clips的電池續航大致達到3個小時,并且不想讓設備過熱。Clips大部分都在捕捉幀的速度是每秒一幀,這是不怎么耗電的。如果捕捉的幀的質量超過了Clips最近設立的范圍,它就會編程每秒捕捉15幀,這是非常耗電的模式。Clips會在之后保存第一個質量最高的圖片。
避免重復:我們不想讓Clips一次捕捉所有的動作,同時忽略其他部分。我們的算法會將看起來相似的視頻集合起來,然后限制其中的數量。
后見之明:當你檢查捕捉到的全部片段后,才能決定哪一片段更好。所以,Clips會收集比預定要多的片段。當這些視頻要被轉換到設備上前,Clips會再次檢查,將最佳的、最獨特的視頻傳到設備上。
機器學習的公平性
為了保證我們的視頻數據集具有多樣性,我們還創建了一些其他的測試,保證算法的公平性。我們創建了一個控制變量數據集,其中的樣本對象擁有著不同的性別和膚色,保證其他因素(視頻類型、時長、環境條件)相同。然后,我們用這一數據集測試我們的算法,結果表明雖然對象不同,但性能相似。為了檢測出當改進視頻質量模型時所出現的公平性減弱,我們在自動系統中加入了公平性檢測。軟件中的任何改變都會經過這一測試。需要注意的是,這一方法并不能保證絕對的公平,因為我們不可能測試任何可能的產經和輸出。然而,我們相信這些步驟對于達到機器學習的公平是很有幫助的。
-
谷歌
+關注
關注
27文章
6142瀏覽量
105115 -
機器學習
+關注
關注
66文章
8382瀏覽量
132444 -
深度學習
+關注
關注
73文章
5493瀏覽量
120998
原文標題:谷歌用深度學習創建自動相機Clips,替你記錄美好瞬間
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一款基于幀捕捉的開源圖形調試器應用設計
名校學生逃課四月發明自動種樹機器人
求教工業相機的哪一款性價比高?
SuperEye一款內置CPU的相機--mangotree出品
驢友強烈推薦的一款4K運動相機,用過都說好!
谷歌推出了一款名為“Clips”的新設備 并開始銷售這款產品
Ambarella推出一款名為CV2的新型相機SoC
卡內基梅隆大學研發了一款投影觸控智能手表
Lucid VR宣布與相機公司RED合作,開發一款用于拍攝8K視頻和圖像的180度立體相機
日本一公司推出一款“雨傘無人機”,又一款然并卵的發明
Yi Halo是一款不一樣的VR相機,可在谷歌的Jump平臺上運行
國外發明了一種反向太陽能電池 可利用夜間地球輻射熱量產生電光源
TECNO全球首發智能手機行業第一款雙棱鏡潛望大角度長焦相機






 工商網監
工商網監
評論