 利用強化學習探索多巴胺對學習的作用
利用強化學習探索多巴胺對學習的作用
繼上周在 Nature 發表極受關注的“網格細胞”研究后,DeepMind今天又在《自然-神經科學》發表一篇重磅論文:利用強化學習探索多巴胺對學習的作用,發現AI的學習方式與神經科學實驗中動物的學習方式類似。該研究提出的理論可以解釋神經科學和心理學中的許多神秘發現。
AI系統已經掌握了多種電子游戲,如雅達利經典的“突出重圍”(Breakout)和“乒乓球”(Pong)游戲。但盡管AI在玩游戲方便的表現令人印象深刻,它們仍然是依靠相當于數千小時的游戲時間訓練,才達到或超越人類的水平。相比之下,我們人類通常只花幾分鐘就能掌握一款我們從未玩過的電子游戲的基礎知識。
為什么只有這么少的先驗知識,人類的大腦卻能做這么多的事情呢?這就引出了“元學習”(meta-learning)的理論,或者說“學習如何學習”(learning to learn)。人們認為,人是在兩個時間尺度上學習的——在短期,我們專注于學習具體的例子;而在較長的時間尺度,我們學習完成一項任務所需的抽象技能或規則。正是這種組合被認為有助于人高效地學習,并將這些知識快速靈活地應用于新任務。
在 AI 系統中重建這種元學習結構——稱為元強化學習(meta-reinforcement learning)——已經被證明能夠促進智能體(agents)快速、one-shot的學習。這方面的研究已經有很多,例如DeepMind的論文“Learning to reinforcement learn”和OpenAI的“RL2: Fast Reinforcement Learning via Slow Reinforcement Learning”。然而,促使這個過程在大腦中發生的具體機制是怎樣的,這在神經科學中大部分仍未得到解釋。
今天,DeepMind在《自然-神經科學》(Nature Neuroscience)發表的新論文中,研究人員使用AI研究中開發的元強化學習框架來探索多巴胺在大腦中幫助我們學習時所起的作用。論文題為:Prefrontal cortex as a meta-reinforcement learning system。

多巴胺——通常被稱為大腦的愉悅因子——被認為與AI強化學習算法中使用的獎勵預測誤差信號類似。AI系統通過獎勵(reward)指引的試錯來學習如何行動。研究者認為,多巴胺的作用不僅僅是利用獎勵來學習過去行為的價值,而且,多巴胺在大腦的前額葉皮層區扮演者不可或缺的角色,使我們能夠高效、快速、靈活地學習新任務。
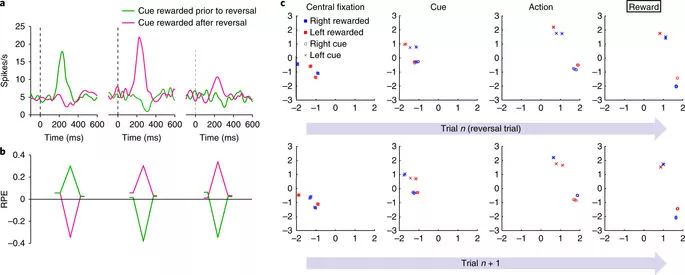
模擬agent的獎勵預測誤差反映了推斷值,而不僅僅是經驗值,類似于在猴子中觀察到的。
DeepMind的研究人員通過模擬重建神經科學領域的6個元學習實驗來測試他們的理論——每個實驗都要求一個agent執行任務,這些任務使用相同的基礎原則(或同一套技能),但在某些方面有所不同。
我們使用標準深度強化學習技術(代表多巴胺的作用)訓練了一個循環神經網絡(代表前額葉皮質),然后將這個循環網絡的活動狀態與之前在神經科學實驗中得到的實際數據進行比較。對于元學習來說,循環網絡是一個很好的代理,因為它們能夠將過去的行為和觀察內在化,然后在訓練各種各樣的任務時借鑒這些經驗。
我們重建的一個實驗叫做Harlow實驗,這是20世紀40年代的一個心理學實驗,用于探索元學習的概念。在原版的測試中,一組猴子被展示兩個不熟悉的物體,只有其中一個會給他們食物獎勵。兩個物體一共被展示了6次,每次的左右放置都是隨機的,所以猴子必須要知道哪個會給它們食物獎勵。然后,他們再次被展示另外兩個新的物體,同樣,只有其中一個會給它們食物。
在這個訓練過程中,猴子發展出一種策略來選擇能得到獎勵的物體:它學會了在第一次的時候隨機選擇,然后,下一次根據獎勵的反饋選擇特定的對象,而不是從左到右選擇。這個實驗表明,猴子可以將任務的基本原理內化,學會一種抽象的規則結構——實際上就是學會了如何學習。
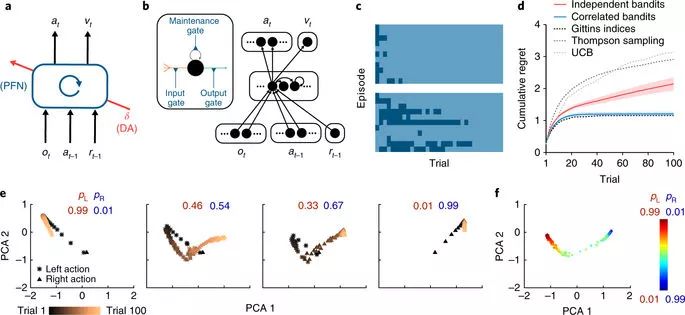
meta-RL 的架構
當我們使用虛擬的計算機屏幕和隨機選擇的圖像來模擬一個非常相似的測試時,我們發現,我們的“元強化學習智能體”(meta-RL agent)似乎是以類似于Harlow實驗中的動物的方式在學習,甚至在被顯示以前從未見過的全新圖像時也是如此。
在模擬的Harlow實驗中,agent必須將它的視線轉向它認為能得到獎勵的對象
實際上,我們發現meta-RL agent可以學習如何快速適應規則和結構不同的各種任務。而且,由于網絡學會了如何適應各種任務,它也學會了關于如何有效學習的一般原則。
很重要的一點是,我們發現大部分的學習發生在循環網絡中,這支持了我們的觀點,即多巴胺在元學習過程中的作用比以前人們認為的更為重要。傳統上,多巴胺被認為能夠加強前額葉系統的突觸連接,從而強化特定的行為。
在AI中,這意味著類多巴胺的獎勵信號在神經網絡中調整人工突觸的權重,因為它學會了解決任務的正確方法。然而,在我們的實驗中,神經網絡的權重被凍結,這意味著在學習過程中權重不能被調整。但是,meta-RL agent仍然能夠解決并適應新的任務。這表明,類多巴胺的獎勵不僅用于調整權重,而且還能傳遞和編碼有關抽象任務和規則結構的重要信息,從而加快對新任務的適應。
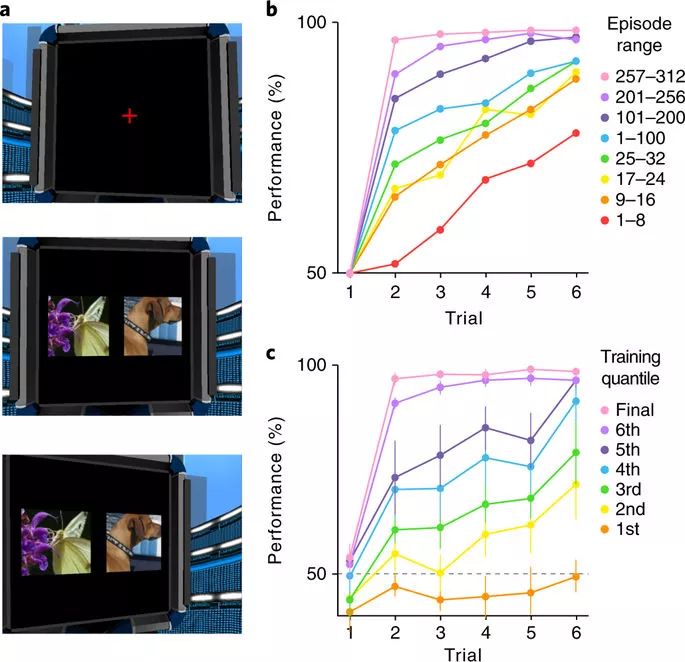
Meta-RL在視覺豐富的3D環境中學習抽象結構和新的刺激
長期以來,神經科學家在大腦的前額葉皮質中觀察到類似的神經活動模式,這種模式能夠快速適應,而且很靈活,但一直以來科學家難以找到能夠解釋為什么會這樣的充分理由。前額葉皮層不依賴突觸重量的緩慢變化來學習規則結構,而是使用直接編碼在多巴胺上的、抽象的基于模式的信息,這一觀點提供了一個更令人信服的解釋。
為了證明AI中存在的引起元強化學習的關鍵因素也存在于大腦中,我們提出了一個理論,該理論不僅與已知的關于多巴胺和前額葉皮層的了解相符,而且可以解釋神經科學和心理學中的許多神秘發現。特別是,該理論對了解大腦中結構化的、基于模式的學習是如何出現的,為什么多巴胺本身包含有基于模式的信息,以及前額葉皮質中的神經元是如何調整為與學習相關的信號等問題提出了新的啟發。
來自AI研究的見解可以用于解釋神經科學和心理學的發現,這強調了,一個研究領域的價值可以提供給另一個領域。展望未來,我們期望能從反過來的方向得到更多益處,通過在為強化學習智能體的學習設計新的模型時,從特定腦回路組織得到啟發。
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
AI
+關注
關注
87文章
30106瀏覽量
268401 -
強化學習
+關注
關注
4文章
266瀏覽量
11213
原文標題:DeepMind用強化學習探索大腦多巴胺對學習的作用
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是深度強化學習?深度強化學習算法應用分析

深度強化學習實戰
將深度學習和強化學習相結合的深度強化學習DRL
薩頓科普了強化學習、深度強化學習,并談到了這項技術的潛力和發展方向
如何深度強化學習 人工智能和深度學習的進階
什么是強化學習?純強化學習有意義嗎?強化學習有什么的致命缺陷?

深度強化學習到底是什么?它的工作原理是怎么樣的
DeepMind發布強化學習庫RLax
機器學習中的無模型強化學習算法及研究綜述

模型化深度強化學習應用研究綜述

什么是強化學習






 工商網監
工商網監
評論