 英偉達GPU廣泛使用 將帶來下一場AI變革
英偉達GPU廣泛使用 將帶來下一場AI變革
日前,英偉達 Developer Blog 上一篇博文詳細陳述了英偉達Volta Tensor Core GPU 在深度學習社群取得的巨大突破,以及種種突破背后的技術細節。
2017 年 5 月,在 GTC 2017 上,英偉達 CEO 黃仁勛發布 Volta 架構 Tesla V100,它被稱為史上最快 GPU 加速器。2018 年 3 月,同樣也是在 GTC 上,黃仁勛發布「全球最大的 GPU」——DGX-2,搭載 16 塊 V100 GPU,速度達到 2 petaflops。
近年來,英偉達在高速計算之路上越走越快。日前,英偉達 Developer Blog 上一篇博文詳細陳述了英偉達Volta Tensor Core GPU 在深度學習社群取得的巨大突破,以及種種突破背后的技術細節。
由深度學習驅動的人工智能現在解決了曾一度被認為不可能的挑戰,比如讓計算機理解自然語言、進行對話以及自動駕駛。既然深度學習能如此有效地解決一系列挑戰,隨著算法復雜度呈現指數級增長,我們是否能將計算變得更快呢?基于此,英偉達設計了Volta Tensor Core架構。
為了更快地計算,英偉達與許多公司以及研究人員一樣,一直在開發計算的軟件和硬件平臺。Google 是個典型的例子——他們的研究團隊創建了 TPU(張量處理單元)加速器,當利用 TPU 進行加速時,在訓練神經網絡時可以達到優異的性能。
這篇文章中,我們分享了英偉達實現 GPU 巨大的性能提升后,在 AI 社群中取得的一些進步:我們已經在單芯片和單服務器上創造了 ResNet-50 的訓練速度記錄。最近,fast.ai也宣布了他們利用英偉達 VoltaTensor Core GPU 在單個云實例上的創紀錄表現 。
以下是我們的結果:
在訓練 ResNet-50 時,一個 V100 Tensor Core GPU 的處理速度能達到 1075 張圖像/秒,與上一代 Pascal GPU 相比,它的性能提高了 4 倍。
一個由 8 個 Tensor Core V100 驅動的 DGX-1 服務器的處理速度能達到 7850 張圖像/秒,幾乎是去年在同一系統上處理速度(4200 張圖像/秒)的兩倍。
一個由 8 個 Tensor Core V100 驅動的 AWS P3 云實例可以在不到 3 小時內完成
ResNet-50 的訓練,比 TPU 實例快 3 倍。
圖 1:Volta Tensor Core GPU 在訓練 ResNet-50 時所取得的速度突破
英偉達 GPU 在對算法進行大規模并行處理時效果極好,因此它極其適合用于深度學習。我們一直都沒有停止探索的腳步,Tensor CoreGPU 是我們利用多年的經驗和與世界各地的人工智能研究人員的密切合作,為深度學習模型創造的一種新的架構。
結合高速 NVLink 互連以及在當前所有框架內的深度優化,我們獲得了最先進的性能。英偉達 CUDA GPU 的可編程性在這里也非常重要。
V100 Tensor Core 打破了單處理器的最快處理速度記錄
英偉達 Volta GPU 中引入了Tensor Core GPU 架構,這是英偉達深度學習平臺的巨大進步。這種新硬件能加速矩陣乘法和卷積計算,這些計算在訓練神經網絡時占總計算的很大一部分。
英偉達 Tensor Core GPU 架構能夠提供比功能單一的 ASIC 更高的性能,在不同工作負載下仍然具備可編程性。例如,每一個 Tesla V100 Tensor Core GPU 用于深度學習可以達到 125 teraflop 的運算速度,而 Google TPU 芯片只能達到 45 teraflop。包含 4 個 TPU 芯片的「Cloud TPU」可以達到 125 teraflop,相比之下,4 個 V100 芯片可以達到 500 teraflop。
我們的 CUDA 平臺使每一個深度學習框架都能充分利用Tensor Core GPU 的全部能力,加速諸如 CNN、RNN、GAN、RL 等各類神經網絡,以及基于這些網絡每年出現的成千上萬個變種。
接下來是對Tensor Core架構的更深入講解,大家可以在這里看到它獨特的功能。圖 2 顯示了 Tensor Core 計算張量的過程,雖然存儲是在低精度的 FP16 中,但是用精度更高的 FP32 來進行計算,可以在維持精度時最大化吞吐量。
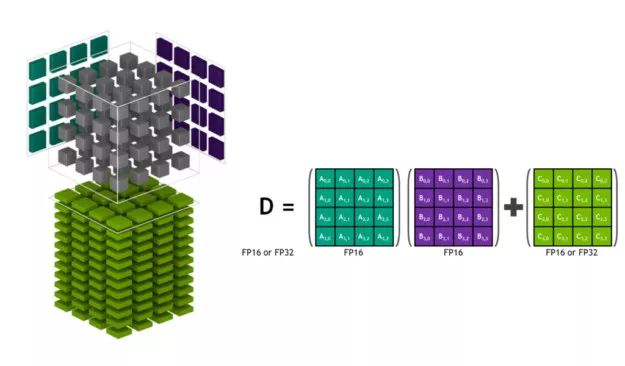
圖 2:Volta Tensor Core 矩陣乘法計算
隨著最近的軟件改進,目前在單個 V100 上訓練 ResNet-50 的速度達到了 1360 張圖像/秒。我們現在正努力將這一訓練軟件集成到流行的框架中,詳情如下。
為了讓性能最佳,基于 Tensor Core 進行張量操作的存儲器布局應該為 channel-interleaved 型數據布局(Number-Height-Width-Channel,常被稱為 NHWC),但往往默認是 channel-major 型數據布局(Number-Channel-Width-Height,通常稱為 NCHW)。因此,cuDNN 庫會在 NCHW 和 NHWC 之間執行張量轉置操作,如圖 3 所示。正如前面所提到的,由于卷積運算現在的速度非常快,所以這些轉置操作占了總運行時間中相當大的一部分。
為了消除這些轉置操作,我們直接用 NHWC 格式表示 RN-50 模型圖中的每個張量,MXNet 框架支持這一功能。此外,對所有其他非卷積層,我們還將優化的 NHWC 實現添加到 MXNet 和 cuDNN 中,從而消除了訓練過程中對張量轉置的需求。
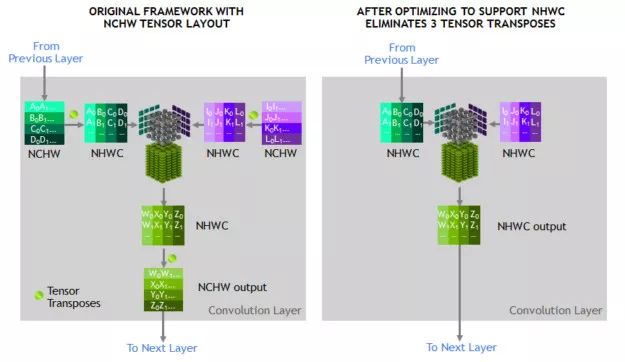
圖 3:優化 NHWC 格式,以消除張量轉置
另一個優化是基于阿爾達姆定律(并行計算中的加速比是用并行前的執行速度和并行后的執行速度之比來表示的,它表示了在并行化之后的效率提升情況),這一法則能預測并行處理的理論加速。由于 Tensor Core 顯著地加速了矩陣乘法和卷積層的計算,因此在訓練時對其他層的計算占據了總運行時間很大的一部分。我們可以確定這些新的性能瓶頸并進行優化。
如圖 4 所示,數據會移動到 DRAM 或從 DRAM 中移出,因此許多非卷積層的性能會受到限制。可以利用片上存儲器將連續的層融合在一起,避免 DRAM traffic。例如,我們在 MXNet 中創建一個圖優化傳遞功能,以檢測連續的 ADD 和 ReLu 層,只要有可能就將這些層替換成融合層。在 MXNet 中可以非常簡單地使用 NNVM(神經網絡虛擬機,Neural Network Virtual Machine)來實現這些類型的優化。
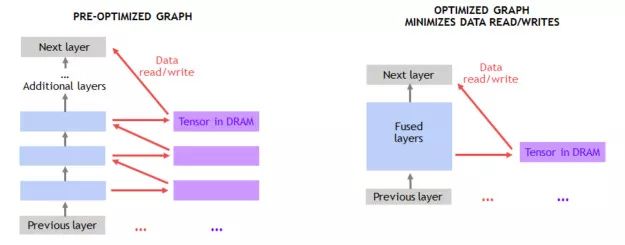
圖 4 :進行層融合操作,消除反復數據讀/寫
最后,我們繼續為常見的各類卷積創建額外的專用 kernel,以進行優化。
我們目前正在將許多這種優化應用于多個深度學習框架之中,包括 TensorFlow、PyTorch 和 MXNet 。我們利用單個 Tensor Core V100 GPU 進行標準的 90-epoch 訓練,基于在 MXNet 上做的改進,處理速度達到 1075 張圖像/秒,與此同時,我們的訓練與單精度訓練一樣達到了相同的 Top-1 分類精度(超過 75%)。我們在單機測試中的處理速度可以達到 1360 張圖像/秒,這意味著性能還有很大的提升空間。可以在NGC(NVIDIA GPU CLOUD)上利用 NVIDIA-optimized deep learning framework containers 實現性能的提升。
創紀錄的最高單節點速度
多個 GPU 可以作為單節點運行,以實現更高的吞吐量。然而,在將多個 GPU 縮到單服務節點中工作時,需要 GPU 之間存在高帶寬/低延遲通信路徑。英偉達 NVLink 高速互連結構允許我們將 8 個 GPU 作為單服務器運行,實現性能擴展。這些大規模的加速服務器可以讓深度學習的計算達到 petaflop 量級的速度,并且在云端和本地部署中都可以被廣泛使用。
然而,雖然將 GPU 擴展到 8 個可以顯著提高訓練性能,但在這種框架下,主 CPU 執行其他工作時性能會受到限制。而且,在這種框架下,對連接 GPU 的數據管道性能要求極高。
數據管道從磁盤中讀取編碼的 JPEG 樣例,然后再執行解碼、調整圖像大小、圖像增強(如圖 5 所示)操作。這些操作提高了神經網絡的學習能力,從而提高了訓練模型的預測準確性。而因為在訓練時,有 8 個 GPU 在進行運算操作,這會限制框架的整體性能。
圖 5:圖像解碼和增強數據管道
為了解決這個問題,我們開發了 DALI(Data Augmentation Library,數據擴充庫),這是一個與框架無關的庫,可以將計算從 CPU 轉移到 GPU 上。如圖 6 所示,DALI 將 JPEG 解碼的一部分、調整圖像大小以及其他所有增強操作移動到 GPU 上。這些操作在 GPU 上的執行速度要比在 CPU 上快得多,這緩解了 CPU 的負荷。DALI 使得 CUDA 的并行處理能力更加突出。消除 CPU 瓶頸之后,在單節點上的計算速度可以達到 7850 張圖像/秒。
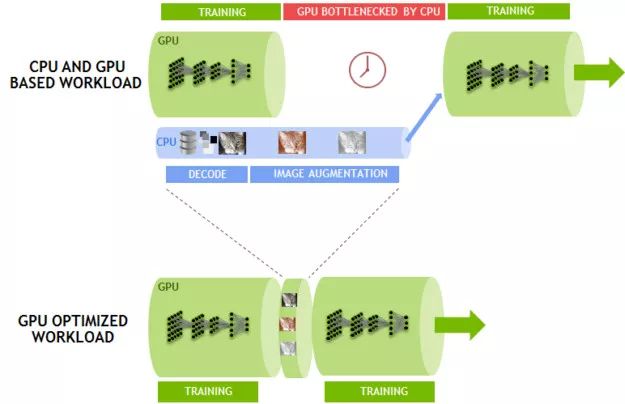
圖 6:利用 DALI 優化工作負荷
英偉達正在幫助將 DALI 融入到所有主流人工智能框架中。這一解決方案有助于提升具備 8 個以上 GPU 的系統的性能,比如英偉達最近發布的帶有 16 個 Tesla V100 GPU 的DGX-2。
創紀錄的單個云實例處理速度
我們使用單 GPU 和單節點運行來訓練 ResNet-50(90 epoch),使預測準確率超過 75%。通過算法的創新和超參數調節,可以進一步減少訓練時間,在更少的 epoch 下達到更高精度。GPU 具備可編程的特性,并支持所有深度學習框架,這使得 AI 研究者能夠探索新的算法,并利用現有的算法進行研究。
fast.ai 團隊最近分享了基于英偉達硬件的優秀成果,他們使用 PyTorch 在遠小于 90 epoch 的訓練下達到了很高的精確度。Jeremy Howard 和 fast.ai 的研究人員利用 8 個 V100 Tensor Core GPU,在一個 AWS P3 實例上用 ImageNet 訓練 ResNet-50。他們對算法進行創新,調節了一系列超參數,不到 3 個小時就將模型訓練好了,這比基于云實例的 TPU 計算(需要將近 9 個小時來訓練 ResNet-50)快三倍。
我們進一步期望這一博客中描述的提高吞吐量的方法同樣也適用于其他訓練,例如前面提到的 fast.ai 的例子。
效果呈現指數級增長
自從 Alex Krizhevsky 利用兩塊 GTX 580 GPU 贏得了 ImageNet 比賽,我們在深度學習加速方面所取得的進步令人難以置信。Krizhevsky 當時花了 6 天時間來訓練他的神經網絡——AlexNet,這一網絡在當時的表現優于所有其他的圖像識別方法,引發了一場深度學習革命。我們最近發布的 DGX-2 可以在 18 分鐘內訓練好 AlexNet。從圖 7 可以看到,在這 5 年多的時間里,隨著硬件性能的提升,處理速度加快了 500 倍。
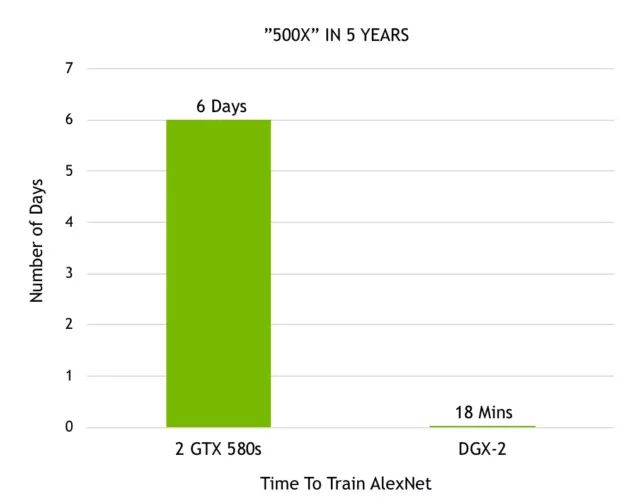
圖 7:在 ImageNet 上訓練 AlexNet 所需要的時間
Facebook 人工智能研究院(FAIR)開源了他們的語言翻譯模型 Fairseq,在不到一年的時間里,我們基于 DGX-2 和軟件棧的改進(見圖 8),在訓練 Fairseq 時實現了 10 倍的加速。
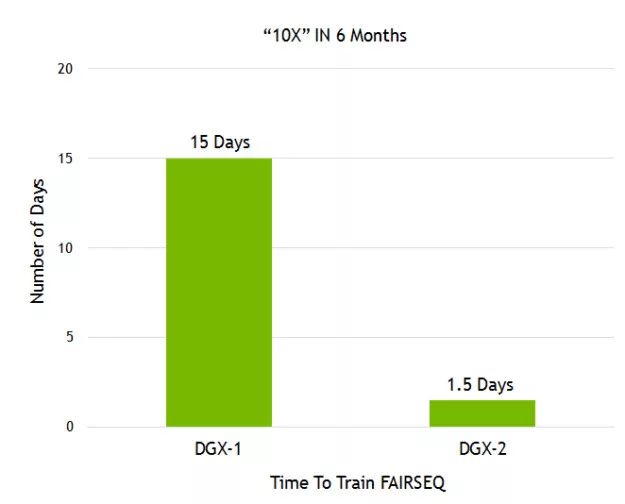
圖 8:訓練 Fairseq 所需要的時間
圖像識別和語言翻譯僅僅是研究人員用 AI 力量解決無數難題的用例之一。Github 上共有超過 6 萬個使用 GPU 加速框架的神經網絡項目,GPU 的可編程性為 AI 社群正在構建的所有類型的神經網絡提供加速。我們的快速改進使得 AI 研究人員能夠想象出更復雜的神經網絡,以解決更困難的挑戰。
這些長久的進步得益于我們對 GPU 加速計算的全堆棧優化算法。從構建最先進的深度學習加速器到復雜的系統(HBM、COWOS、SXM、NVSwitch、DGX),從先進的數字計算庫和深度軟件棧(cuDNN,NCCL,NGC) 到加速所有的 DL 框架,英偉達對 AI 的承諾為 AI 開發者提供了無與倫比的靈活性。
我們將繼續優化整個堆棧,并持續實現性能的指數級提升,為 AI 社群提供推動深度學習創新研究的有力工具。
總結
AI 繼續改變著各行各業,驅動出無數用例。理想的 AI 計算平臺需要提供出色的性能,能支持龐大且不斷增長的模型,并具備可編程性,以應對模型的多樣性需求。
英偉達的 Volta Tensor Core GPU 是世界上最快的 AI 處理器,只用一塊芯片就能讓深度學習的訓練速度達到 125 teraflop。我們很快會將 16 塊 Tesla V100 整合到一個單服務器節點中,以創建世界上最快的計算服務器,提供 2 petaflops 的計算性能。
除了在加速上的優異性能,GPU 的可編程性以及它在云、服務器制造商和整個 AI 社群中的廣泛使用,將帶來下一場 AI 變革。
無論你選擇什么深度學習框架(Caffe2, Chainer, Cognitive Toolkit, Kaldi, Keras, Matlab, MXNET, PaddlePaddle, Pytorch,TensorFlow),都可以用英偉達硬件進行加速。此外,英偉達 GPU 還用于訓練 CNN、RNN、GAN、RL、混合網絡架構以及每年基于這些網絡的成千上萬個變體。AI 社群中目前存在很多驚人的應用,我們期待著為 AI 的下一步發展提供動力。
-
gpu
+關注
關注
28文章
4703瀏覽量
128725 -
英偉達
+關注
關注
22文章
3749瀏覽量
90859
原文標題:5 年提速 500 倍,英偉達 GPU 創紀錄突破與技術有哪些?
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

英偉達著手構建AI大腦,推動企業管理智能化
英偉達Blackwell GPU未來一年訂單爆滿
英偉達或明年將革新AI GPU設計,采用插槽設計






 工商網監
工商網監
評論