") 一種基于MapReduce模型的并行化k-medoids聚類算法
一種基于MapReduce模型的并行化k-medoids聚類算法
摘要:
隨著電力通信技術(shù)的發(fā)展,產(chǎn)生了大量分布式電力通信子系統(tǒng)以及海量電力通信數(shù)據(jù),在海量數(shù)據(jù)中挖掘重要信息變得十分重要。聚類分析作為數(shù)據(jù)并行化處理和信息挖掘的一個(gè)有效手段,在電力通信中得到了廣泛的應(yīng)用。然而,傳統(tǒng)聚類算法在處理海量電力數(shù)據(jù)時(shí)已不能滿足時(shí)間性能的要求。針對(duì)這一問(wèn)題,提出了一種基于MapReduce模型的并行化k-medoids聚類算法,首先采用基于密度的聚類思想對(duì)k-medoids算法初始點(diǎn)的選取策略進(jìn)行優(yōu)化,并利用Hadoop平臺(tái)下的MapReduce編程框架實(shí)現(xiàn)了算法的并行化處理。實(shí)驗(yàn)結(jié)果表明,改進(jìn)的并行化聚類算法與其他算法相比,減少了聚類時(shí)間,提高了聚類精度,有利于對(duì)電力數(shù)據(jù)的有效分析和利用
0 引言
隨著電力通信網(wǎng)絡(luò)以功能為中心持續(xù)性發(fā)展,產(chǎn)生了大量分專業(yè)、分功能和分管理域的運(yùn)維管理系統(tǒng),進(jìn)而導(dǎo)致大量電力數(shù)據(jù)孤島的產(chǎn)生。如何利用分布式系統(tǒng)更好地處理這些數(shù)據(jù)量巨大且類型復(fù)雜的電力通信運(yùn)維數(shù)據(jù)已成為研究的熱點(diǎn)問(wèn)題。聚類分析作為數(shù)據(jù)處理的一個(gè)有效手段,支持對(duì)大量無(wú)序分散數(shù)據(jù)進(jìn)行整合分類從而進(jìn)行更深層次的關(guān)聯(lián)性分析或者數(shù)據(jù)挖掘,在電力通信網(wǎng)絡(luò)中得到越來(lái)越廣泛的應(yīng)用。同時(shí),分布式系統(tǒng)中并行化處理機(jī)制因其優(yōu)秀的靈活性和高效性逐漸成為數(shù)據(jù)挖掘的一個(gè)重要研究方向。
國(guó)內(nèi)外學(xué)者也越來(lái)越對(duì)這方面加大關(guān)注,文獻(xiàn)[1]提出了一種基于DBSACN算法的并行優(yōu)化的聚類算法。文獻(xiàn)[2]中通過(guò)計(jì)算距離選擇最中心的k個(gè)數(shù)據(jù)點(diǎn)作為初始聚類中心,然后用k-medoids算法進(jìn)行迭代聚類,提高了聚類效果,但不適合處理大規(guī)模數(shù)據(jù);文獻(xiàn)[3]提出了一種蟻群 k-medoids 融合聚類算法,該算法不需要人為確定類簇?cái)?shù)目和初始聚類中心,提高了聚類效果,但也僅只適用于小型數(shù)據(jù)集;文獻(xiàn)[4]采用基于粒計(jì)算的聚類算法,該算法在初始聚類中心的選取過(guò)程中的計(jì)算量較大,且在處理大規(guī)模數(shù)據(jù)時(shí)存在時(shí)延問(wèn)題;文獻(xiàn)[5]提出了將局部搜索過(guò)程嵌入到迭代局部搜索過(guò)程中的方法,顯著減少了計(jì)算時(shí)間。文獻(xiàn)[6]在Hadoop平臺(tái)上實(shí)現(xiàn)了傳統(tǒng)k-medoids聚類算法的并行化處理,減少了聚類時(shí)間,但在初始聚類中心的選取機(jī)制上沒(méi)有進(jìn)行改進(jìn),沒(méi)有提高聚類效果;文獻(xiàn)[7]采用基于核的自適應(yīng)聚類算法,克服了k-medoids 的初值敏感問(wèn)題,但是沒(méi)有降低算法的時(shí)間復(fù)雜度。
綜上所述,k-medoids聚類算法存在初始值敏感、運(yùn)行速度慢、時(shí)間復(fù)雜度較高等問(wèn)題,需要對(duì)k-medoids算法中初始點(diǎn)選取以及并行化方式進(jìn)行算法優(yōu)化設(shè)計(jì)。
1 k-medoids聚類初始點(diǎn)選取改進(jìn)機(jī)制
k-medoids算法是一種基于劃分的聚類算法,具有簡(jiǎn)單、收斂速度快以及對(duì)噪聲點(diǎn)不敏感等優(yōu)點(diǎn),因此在模式識(shí)別、數(shù)據(jù)挖掘等領(lǐng)域都得到了廣泛的應(yīng)用。k-medoids算法初始中心點(diǎn)的選取十分重要,如果初始中心點(diǎn)選擇的是離群點(diǎn)時(shí),就會(huì)導(dǎo)致由離群點(diǎn)算出的質(zhì)心會(huì)偏離整個(gè)簇,造成數(shù)據(jù)分析不正確;如果選擇的初始中心點(diǎn)離得太近,就會(huì)顯著增加計(jì)算的時(shí)間消耗。因此本文算法首先對(duì)初始中心點(diǎn)的選取進(jìn)行優(yōu)化。基于密度的聚類可以很好地分離簇和環(huán)境噪聲,所以本文采用基于密度的聚類思想,盡量減少噪聲數(shù)據(jù)對(duì)選取初始點(diǎn)的影響。
定義1:點(diǎn)密度是對(duì)于數(shù)據(jù)集U中的數(shù)據(jù)集的樣本點(diǎn)x,以x為球心,某一正數(shù)r為半徑的球形域中所包含樣本點(diǎn)的個(gè)數(shù),記作Dens(x)。其中:

本文算法中,首先對(duì)每個(gè)數(shù)據(jù)點(diǎn)并行計(jì)算點(diǎn)密度,并將點(diǎn)密度作為該數(shù)據(jù)點(diǎn)的一個(gè)屬性。選取初始聚類中心的具體步驟如下:
(1)計(jì)算數(shù)據(jù)集中m個(gè)數(shù)據(jù)點(diǎn)之間的距離。
(2)計(jì)算每個(gè)樣本點(diǎn)的點(diǎn)密度Dens(xi)以及均值點(diǎn)密度AvgDens,將點(diǎn)密度大于AvgDens的點(diǎn)即核心點(diǎn)存入集合T中,并記錄其簇中所包含的數(shù)據(jù)點(diǎn)。
(3)合并所有具有公共核心點(diǎn)的簇。
(4)計(jì)算各個(gè)簇的類簇密度CDens(ci),選擇其中k個(gè)較大密度的簇,計(jì)算其中心點(diǎn),即為初始聚類中心。
類簇中心點(diǎn)的計(jì)算方法如下:假設(shè)有一個(gè)類簇ci包含m個(gè)數(shù)據(jù)點(diǎn){x1,x2,…,xm},則其中心點(diǎn)ni按如式(5)計(jì)算:

經(jīng)過(guò)上述步驟,可以優(yōu)化初始聚類中心點(diǎn)的選取,使之后的聚類迭代運(yùn)算更加有效,降低搜索范圍,大大減少搜索指派的時(shí)間。
2 k-medoids聚類算法并行化設(shè)計(jì)策略
本文針對(duì)k-medoids算法具有初始點(diǎn)選取復(fù)雜、聚類迭代時(shí)間久、中心點(diǎn)選取消耗資源過(guò)多等缺點(diǎn),使用Hadoop平臺(tái)下的MapReduce編程框架對(duì)算法進(jìn)行初始點(diǎn)的點(diǎn)密度計(jì)算選取并行化、非中心點(diǎn)分配并行化和中心點(diǎn)更新并行化等方面的改進(jìn)。MapReduce分為Map(映射)和Reduce(化簡(jiǎn))兩部分操作,使用MapReduce實(shí)現(xiàn)算法并行化關(guān)鍵在于Map函數(shù)和Reduce函數(shù)的設(shè)計(jì)。其中Map函數(shù)將可并行執(zhí)行的多個(gè)任務(wù)映射到多個(gè)計(jì)算節(jié)點(diǎn),多個(gè)計(jì)算節(jié)點(diǎn)對(duì)各自被分派的任務(wù)并行進(jìn)行處理,Reduce函數(shù)則是在各計(jì)算節(jié)點(diǎn)處理結(jié)束后,將計(jì)算結(jié)果返回給主進(jìn)程進(jìn)行匯總。
2.1 點(diǎn)密度計(jì)算并行化策略
在點(diǎn)密度的計(jì)算中,由于一個(gè)數(shù)據(jù)點(diǎn)的點(diǎn)密度對(duì)其他數(shù)據(jù)點(diǎn)的點(diǎn)密度沒(méi)有影響,所以該計(jì)算過(guò)程是可以并行化的。使用MultithreadedMapper在一個(gè)JVM進(jìn)程里以多線程的方式同時(shí)運(yùn)行多個(gè)Mapper,每個(gè)線程實(shí)例化一個(gè)Mapper對(duì)象,各個(gè)線程并發(fā)執(zhí)行。主進(jìn)程把數(shù)據(jù)點(diǎn)分派給若干個(gè)不同的計(jì)算節(jié)點(diǎn)進(jìn)行處理,計(jì)算節(jié)點(diǎn)將數(shù)據(jù)平均分成k份,且有k個(gè)線程,每個(gè)線程中的數(shù)據(jù)點(diǎn)都與數(shù)據(jù)集中所有點(diǎn)進(jìn)行距離計(jì)算,進(jìn)而計(jì)算出點(diǎn)密度,最后通過(guò)Reduce函數(shù)將計(jì)算結(jié)果匯總并輸出。并行處理使得點(diǎn)密度計(jì)算所用時(shí)間大大減少,提高了算法的執(zhí)行效率。
2.2 非中心點(diǎn)分配及中心點(diǎn)更新并行化策略
非中心點(diǎn)分配階段的主要工作是計(jì)算各數(shù)據(jù)點(diǎn)到每個(gè)中心點(diǎn)的距離,由于每個(gè)數(shù)據(jù)點(diǎn)跟各個(gè)中心點(diǎn)距離的計(jì)算互不影響,所以該計(jì)算過(guò)程也是可并行化的。此階段的MapReduce化過(guò)程中,Map函數(shù)主要負(fù)責(zé)將數(shù)據(jù)集里除中心點(diǎn)外的每一個(gè)樣本點(diǎn)分配給與其距離最近的聚類中心,Reduce函數(shù)則負(fù)責(zé)通過(guò)計(jì)算更新每一個(gè)簇的中心點(diǎn),按照這個(gè)原則迭代下去一直到達(dá)到設(shè)定閾值。主進(jìn)程利用Map函數(shù)把非中心點(diǎn)分配的任務(wù)分派給若干個(gè)計(jì)算節(jié)點(diǎn),每個(gè)計(jì)算節(jié)點(diǎn)采用基于Round-Robin的并行化分配策略。首先把每一個(gè)數(shù)據(jù)點(diǎn)看作一個(gè)請(qǐng)求,輪詢地分配給不同的線程,對(duì)非中心點(diǎn)和每一個(gè)中心點(diǎn)的距離進(jìn)行計(jì)算,找出最小的距離,然后把該非中心點(diǎn)指派給最小距離所對(duì)應(yīng)的中心點(diǎn)。
因?yàn)檩喸冋{(diào)度算法是假設(shè)所有服務(wù)器中的處理性能都是相同,并不關(guān)心每臺(tái)服務(wù)器當(dāng)前的計(jì)算速度和響應(yīng)速度。因此當(dāng)用戶發(fā)出請(qǐng)求時(shí),如果服務(wù)間隔的時(shí)間變化較大的時(shí)候,那么Round-Robin調(diào)度算法是非常容易導(dǎo)致服務(wù)器之間的負(fù)載發(fā)生不平衡表現(xiàn)。而本文中所運(yùn)用的每個(gè)數(shù)據(jù)點(diǎn)都是平等的,所以不會(huì)造成服務(wù)器分配任務(wù)不均的問(wèn)題。因此基于Round-Robin的策略是可行的。
本文算法在實(shí)現(xiàn)聚類的過(guò)程中經(jīng)歷了兩次并行化劃分,分別是非中心點(diǎn)分配和中心點(diǎn)更新過(guò)程。這兩次并行化過(guò)程是周而復(fù)始的,直到滿足程序退出的條件才會(huì)終止循環(huán)。
3 仿真實(shí)驗(yàn)與結(jié)果分析
仿真實(shí)驗(yàn)分別使用本文算法、DBSCAN并行化算法[1]和k-medoids并行化算法[8]進(jìn)行對(duì)比試驗(yàn),證明各個(gè)算法的優(yōu)劣性。為了證明本文算法的有效性,實(shí)驗(yàn)將分析不同算法的聚類時(shí)間、聚類準(zhǔn)確度以及增加線程數(shù)之后的時(shí)間消耗。實(shí)驗(yàn)將在兩種類型的數(shù)據(jù)集上進(jìn)行測(cè)試:
(1)電力數(shù)據(jù)集。電力通信數(shù)據(jù)的屬性有設(shè)備狀態(tài)、設(shè)備資產(chǎn)、網(wǎng)絡(luò)拓?fù)涞龋鋽?shù)據(jù)量約為1 GB。
(2)公有數(shù)據(jù)集。分別為200數(shù)量級(jí)的Northix、1 000數(shù)量級(jí)的DSA、5 000數(shù)量級(jí)的SSC和10 000數(shù)量級(jí)的GPSS。
3.1 電力數(shù)據(jù)集實(shí)驗(yàn)結(jié)果分析
實(shí)驗(yàn)首先設(shè)置6個(gè)線程對(duì)數(shù)據(jù)集進(jìn)行處理,三種算法對(duì)電力數(shù)據(jù)進(jìn)行聚類的結(jié)果見(jiàn)表1。其中k-medoids并行化算法[8]采用標(biāo)簽共現(xiàn)原則對(duì)初始點(diǎn)選取進(jìn)行改進(jìn),但沒(méi)有考慮線程的分配方式,因此其執(zhí)行效率最差;DBSCAN算法考慮到了初始點(diǎn)的選取,并采用動(dòng)態(tài)分配策略實(shí)現(xiàn)并行化,但在計(jì)算動(dòng)態(tài)分配過(guò)程中增加了一定消耗,因此聚類準(zhǔn)確度和執(zhí)行效率都略有提升;本文所提出的算法,既考慮了初始點(diǎn)的合理選取,同時(shí)采用簡(jiǎn)單有效的并行化分配策略,以減少計(jì)算和過(guò)多資源占用,因此相對(duì)于k-medoids并行化算法和DBSCAN并行化算法執(zhí)行效率大幅提升,準(zhǔn)確度也有所提高。
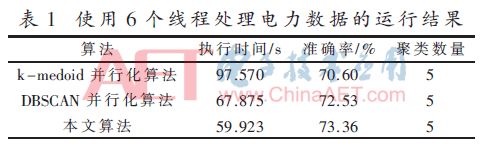
然后增加線程處理器的數(shù)量至8個(gè),得到下表的聚類結(jié)果,見(jiàn)表2。
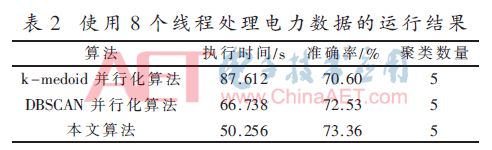
由表2可得,使用8個(gè)線程時(shí),本文算法比k-medoids并行化算法執(zhí)行時(shí)間快了42.64%,比DBSCAN并行化算法快了24.70%。
各類算法增加線程后所用時(shí)間相比原算法減少的百分比如圖1。
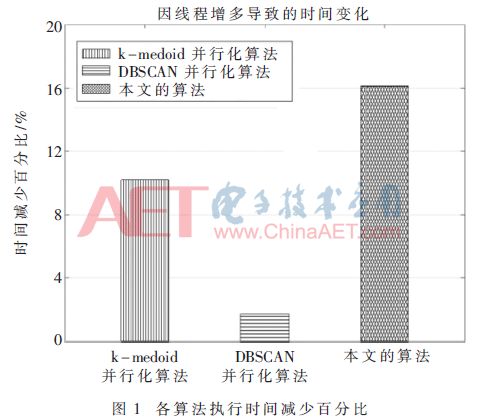
由圖1可知,k-medoids并行化算法減少了10.20%,DBSCAN并行化算法減少了1.68%,本文算法減少了16.13%,說(shuō)明本文算法在線程數(shù)增加時(shí),可以更有效地減少運(yùn)算時(shí)間,提高執(zhí)行效率。
3.2 公有數(shù)據(jù)集實(shí)驗(yàn)結(jié)果分析
基于Northix、DSA、SSC和GPSS數(shù)據(jù)集使用5個(gè)線程實(shí)現(xiàn)算法的聚類準(zhǔn)確度比較見(jiàn)表3。
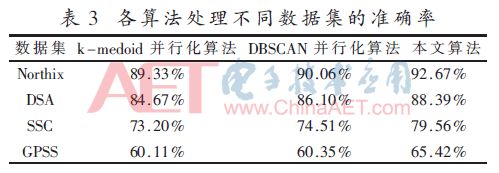
本文算法的聚類準(zhǔn)確度均高于k-medoids并行化算法和DBSCAN并行化算法,并且在處理較大數(shù)量級(jí)的數(shù)據(jù)集時(shí),本文算法準(zhǔn)確度更占優(yōu)勢(shì)。不同數(shù)據(jù)集上各算法的執(zhí)行時(shí)間如圖2。
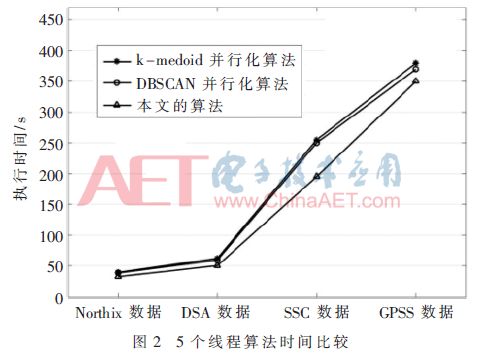
根據(jù)圖2,隨著數(shù)據(jù)量的增大,三種算法執(zhí)行效率差異逐漸增大,本文算法性能明顯優(yōu)于k-medoids并行性算法和DBSCAN并行算法。接著對(duì)三個(gè)算法使用7個(gè)線程時(shí)的執(zhí)行時(shí)間進(jìn)行比較,如圖3所示。
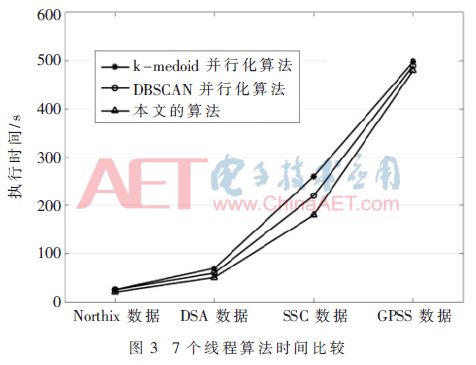
從圖3中可以看出,使用7個(gè)線程在1 000、5 000、10 000數(shù)據(jù)級(jí)時(shí),本文算法執(zhí)行時(shí)間明顯優(yōu)于其他兩個(gè)算法。
3.3 實(shí)驗(yàn)小結(jié)
仿真實(shí)驗(yàn)可知,在同一線程數(shù)時(shí),本文算法比對(duì)比算法聚類準(zhǔn)確率高,執(zhí)行時(shí)間短;在線程數(shù)增加時(shí),本文算法執(zhí)行時(shí)間顯著降低;隨著數(shù)據(jù)量的增長(zhǎng),本文算法在保證更高準(zhǔn)確度的基礎(chǔ)上,執(zhí)行時(shí)間優(yōu)勢(shì)逐漸凸顯。
4 結(jié)論
本文針對(duì)電力通信數(shù)據(jù)的聚類處理問(wèn)題,提出基于密度的聚類思想對(duì)k-medoids算法初始點(diǎn)的選取策略進(jìn)行優(yōu)化,并利用MapReduce編程框架實(shí)現(xiàn)了算法的并行化處理。通過(guò)仿真實(shí)驗(yàn)表明本文提出的優(yōu)化算法可行有效,并具有較好的執(zhí)行效率。在接下來(lái)的研究中可以考慮線程數(shù)小于聚類數(shù)時(shí)的優(yōu)化分配策略,進(jìn)一步提高算法性能。
-
聚類算法
+關(guān)注
關(guān)注
2文章
118瀏覽量
12101 -
MapReduce
+關(guān)注
關(guān)注
0文章
45瀏覽量
6275
原文標(biāo)題:【學(xué)術(shù)論文】電力通信大數(shù)據(jù)并行化聚類算法研究
文章出處:【微信號(hào):ChinaAET,微信公眾號(hào):電子技術(shù)應(yīng)用ChinaAET】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
一種改進(jìn)的聚類算法及其在說(shuō)話人識(shí)別上的應(yīng)用
一種基于隨機(jī)游動(dòng)的聚類算法
一種改進(jìn)的粒子群和K均值混合聚類算法
一種改進(jìn)的BIRCH算法聚類方法
基于Hash改進(jìn)的k-means算法并行化設(shè)計(jì)
基于人群疏散仿真的折半聚類算法
一種新的人工魚群混合聚類算法
一種高效的基于MapReduce分布式蜂群模式挖掘算法

基于Spark框架與聚類優(yōu)化的高效KNN分類算法
一種基于MapReduce的圖結(jié)構(gòu)聚類算法
一種自適應(yīng)的關(guān)聯(lián)融合聚類算法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論