") 回顧和總結(jié)卷積神經(jīng)網(wǎng)絡(luò)的發(fā)展過程
回顧和總結(jié)卷積神經(jīng)網(wǎng)絡(luò)的發(fā)展過程
從1989年LeCun提出第一個(gè)真正意義上的卷積神經(jīng)網(wǎng)絡(luò)到今天為止,它已經(jīng)走過了29個(gè)年頭。自2012年AlexNet網(wǎng)絡(luò)出現(xiàn)之后,最近6年以來,卷積神經(jīng)網(wǎng)絡(luò)得到了急速發(fā)展,在很多問題上取得了當(dāng)前最好的結(jié)果,是各種深度學(xué)習(xí)技術(shù)中用途最廣泛的一種。
早期成果
卷積神經(jīng)網(wǎng)絡(luò)是各種深度神經(jīng)網(wǎng)絡(luò)中應(yīng)用最廣泛的一種,在機(jī)器視覺的很多問題上都取得了當(dāng)前最好的效果,另外它在自然語言處理,計(jì)算機(jī)圖形學(xué)等領(lǐng)域也有成功的應(yīng)用。
第一個(gè)真正意義上的卷積神經(jīng)網(wǎng)絡(luò)由LeCun在1989年提出[1],后來進(jìn)行了改進(jìn),它被用于手寫字符的識(shí)別,是當(dāng)前各種深度卷積神經(jīng)網(wǎng)絡(luò)的鼻祖。接下來我們介紹LeCun在早期提出的3種卷積網(wǎng)絡(luò)結(jié)構(gòu)。
文獻(xiàn)[1]的網(wǎng)絡(luò)由卷積層和全連接層構(gòu)成,網(wǎng)絡(luò)的輸入是16x16的歸一化圖像,輸出為0-9這10個(gè)類,中間是3個(gè)隱含層。這個(gè)網(wǎng)絡(luò)的結(jié)構(gòu)如下圖所示:
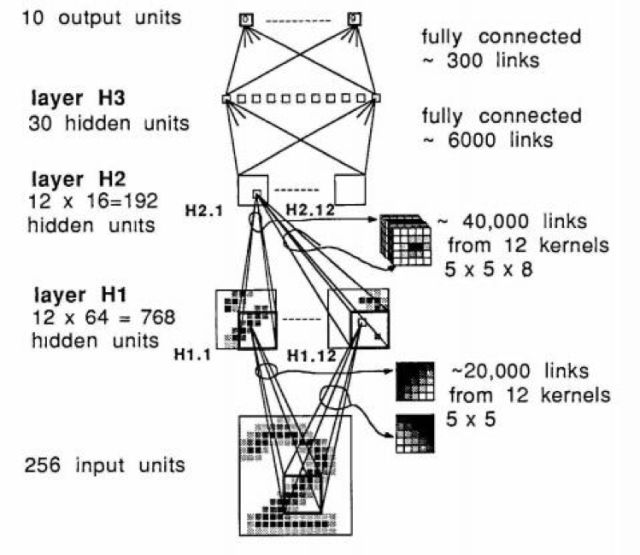
這篇文章提出了權(quán)重共享(weight sharing)和特征圖像(feature map)的概念,這些概念被沿用至今,就是卷積層的原型。網(wǎng)絡(luò)有1個(gè)輸入層,1個(gè)輸出層,3個(gè)隱含層構(gòu)成,其中隱含層H1和H2是卷積層,H3是全連接層。網(wǎng)絡(luò)的激活函數(shù)選用了tanh(雙曲正切)函數(shù),損失函數(shù)選用了均方誤差(mean squared error)函數(shù),即歐氏距離的均值。網(wǎng)絡(luò)的權(quán)重用均勻分布的隨機(jī)數(shù)進(jìn)行初始化,訓(xùn)練時(shí)參數(shù)梯度值的計(jì)算采用了反向傳播算法,梯度值的更新采用了在線(online)的隨機(jī)梯度下降法。
文獻(xiàn)[2]的網(wǎng)絡(luò)結(jié)構(gòu)和文獻(xiàn)[1]類似,用于郵政編碼的識(shí)別,在9%拒識(shí)率的條件下錯(cuò)誤率為1%。網(wǎng)絡(luò)的輸入為28x28的圖像,輸出為0-9這10個(gè)類。整個(gè)網(wǎng)絡(luò)有4個(gè)隱含層,其中H1為4個(gè)5x5的卷積核,輸出為4張24x24的特征圖像。H2為下采樣層,對(duì)H1的輸出結(jié)果進(jìn)行2x2的下采樣,得到4張12x12的圖像。H3有12個(gè)5x5的卷積核,輸出為12張8x8的圖像,這里輸出圖像每個(gè)通道的多通道卷積只作用于前一層輸出圖像的部分通道上,為什么采用這樣方式?有兩個(gè)原因:1.減少參數(shù),2.這種不對(duì)稱的組合連接的方式有利于提取多種組合特征。H2和H3的連接關(guān)系如下圖所示:
H4為下采樣層,對(duì)H3的輸出圖像進(jìn)行2x2的下采樣,得到12張4x4的特征圖像。最后為輸出層,接收H4特特征圖像,輸出10個(gè)類別的概率。
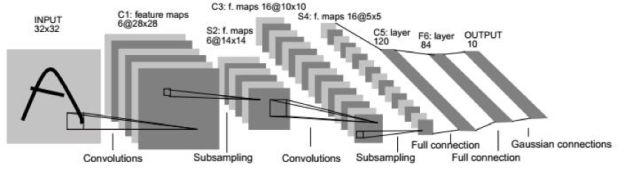
文獻(xiàn)[3]的網(wǎng)絡(luò)即為L(zhǎng)eNet-5網(wǎng)絡(luò),這是第一個(gè)被廣為流傳的卷積網(wǎng)絡(luò),整個(gè)網(wǎng)的結(jié)構(gòu)如下圖所示:
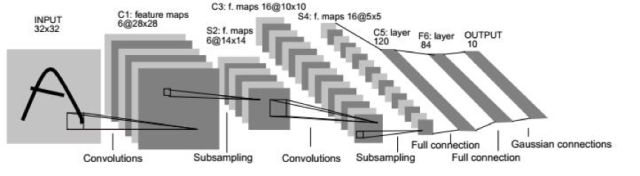
下面是基于LeNet-5的手寫體數(shù)字識(shí)別案例:
這個(gè)網(wǎng)絡(luò)的輸入為32x32的圖像,整個(gè)網(wǎng)絡(luò)有2個(gè)卷層,2個(gè)池化層,2個(gè)全連接層,一個(gè)輸出層,輸出層有10個(gè)神經(jīng)元,代表10個(gè)數(shù)字類。卷積層C1有6個(gè)5x5的卷積核,作用于灰度圖像,產(chǎn)生6張28x28的輸出圖像。池化層S2作用于C1的輸出圖像,執(zhí)行2x2的池化,產(chǎn)生6張14x14的輸出圖像。卷積層C3有16個(gè)5x5的卷積核,每個(gè)卷積核作用于前一層輸出圖像的部分通道上,產(chǎn)生16張10x10的輸出圖像。C3和S2的連接關(guān)系如下圖所示:
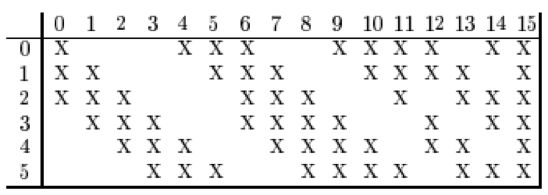
池化層S4對(duì)C3的輸出圖像進(jìn)行2x2的池化,得到16張5x5的輸出圖像。全連接層C5有120個(gè)節(jié)點(diǎn),全連接層F6有64個(gè)節(jié)點(diǎn)。
網(wǎng)絡(luò)的激活函數(shù)選用tanh函數(shù),損失函數(shù)采用均方誤差函數(shù),訓(xùn)練時(shí)采用隨機(jī)梯度下降法和反向傳播算法。
早期的卷積網(wǎng)絡(luò)被用于人臉檢測(cè)[4][5],人臉識(shí)別[6],字符識(shí)別[7]等各種問題。但并沒有成為主流的方法,其原因主要是梯度消失問題、訓(xùn)練樣本數(shù)的限制、計(jì)算能力的限制3方面因素。梯度消失的問題在之前就已經(jīng)被發(fā)現(xiàn),對(duì)于深層神經(jīng)網(wǎng)絡(luò)難以訓(xùn)練的問題,文獻(xiàn)[8]進(jìn)行了分析,但給出的解決方法沒有成為主流。
深度卷積神經(jīng)網(wǎng)絡(luò)
在深入分析比較當(dāng)前主流深度卷積神經(jīng)網(wǎng)絡(luò)的特點(diǎn)之前,我們從各網(wǎng)絡(luò)在ImageNet 2012測(cè)試數(shù)據(jù)集的準(zhǔn)確率以及網(wǎng)絡(luò)的參數(shù)量和計(jì)算復(fù)雜度三個(gè)維度進(jìn)行分析,希望讀者對(duì)當(dāng)前的主流網(wǎng)絡(luò)結(jié)構(gòu)有一個(gè)整體的認(rèn)知。如下圖所示:
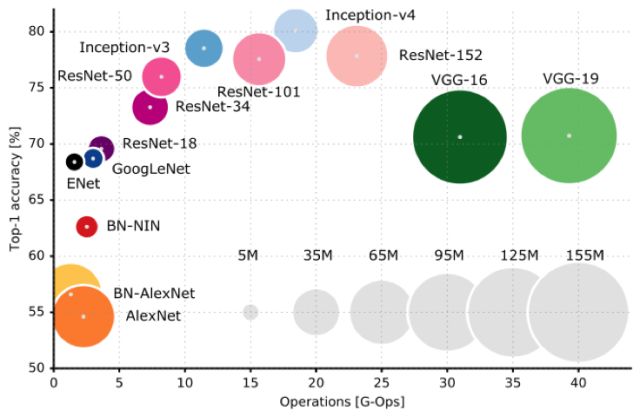
深度卷積網(wǎng)絡(luò)的大發(fā)展起步于2012年的AlexNet網(wǎng)絡(luò),在這之后各種改進(jìn)的網(wǎng)絡(luò)被不斷的提出,接下來我們會(huì)介紹各種典型的網(wǎng)絡(luò)結(jié)構(gòu)。
AlexNet網(wǎng)絡(luò)
現(xiàn)代意義上的深度卷積神經(jīng)網(wǎng)絡(luò)起源于AlexNet網(wǎng)絡(luò)[9],它是深度卷積神經(jīng)網(wǎng)絡(luò)的鼻祖。這個(gè)網(wǎng)絡(luò)相比之前的卷積網(wǎng)絡(luò)最顯著的特點(diǎn)是層次加深,參數(shù)規(guī)模變大。網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示:
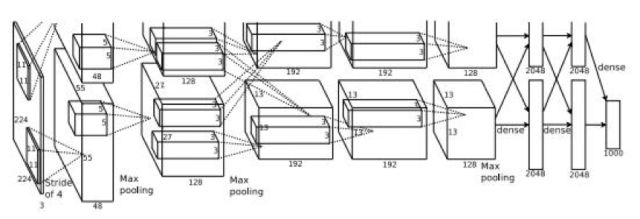
這個(gè)網(wǎng)絡(luò)有5個(gè)卷積層,它們中的一部分后面接著max-pooling層進(jìn)行下采樣;最后跟3個(gè)全連接層。最后一層是softmax輸出層,共有1000個(gè)節(jié)點(diǎn),對(duì)應(yīng)ImageNet圖集中 1000個(gè)圖像分類。網(wǎng)絡(luò)中部分卷基層分成2個(gè)group進(jìn)行獨(dú)立計(jì)算,有利于GPU并行化以及降低計(jì)算量。
這個(gè)網(wǎng)絡(luò)有兩個(gè)主要的創(chuàng)新點(diǎn):1. 新的激活函數(shù)ReLU,2. dropout機(jī)制[10]。dropout的做法是在訓(xùn)練時(shí)隨機(jī)的選擇一部分神經(jīng)元進(jìn)行休眠,另外一些神經(jīng)元參與網(wǎng)絡(luò)的優(yōu)化,起到了正則化的作用以減輕過擬合。
網(wǎng)絡(luò)的輸入圖像為的彩色三通道圖像。第1個(gè)卷積層有96組11x11大小的卷積核,卷積操作的步長(zhǎng)為4。這里的卷積核不是2維而是3維的,每個(gè)通道對(duì)應(yīng)有3個(gè)卷積核(所以是一組卷積核),具體實(shí)現(xiàn)時(shí)是用3個(gè)2維的卷積核分別作用在RGB通道上,然后將三張結(jié)果圖像相加。下圖為輸入為3通道,卷積層參數(shù)為2組每組3個(gè)卷積核,輸出結(jié)果為2通道的動(dòng)態(tài)卷積過程
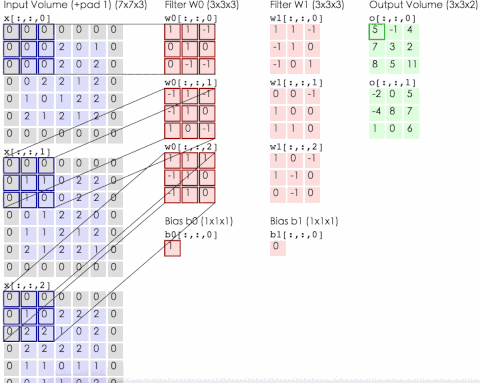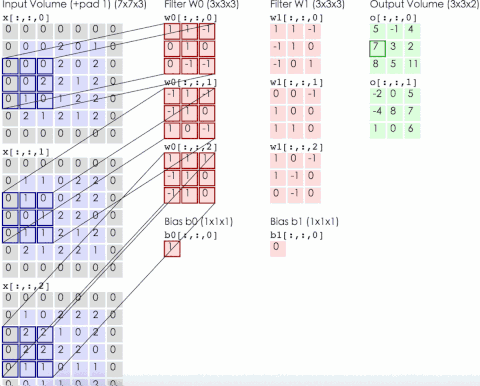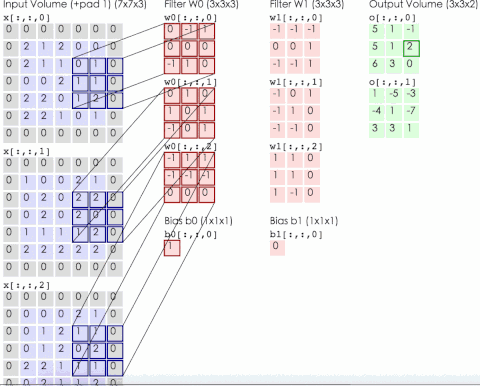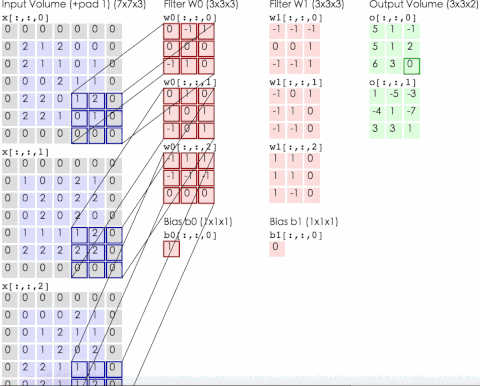
第2個(gè)卷積層有256組5x5大小的卷積核,分為兩個(gè)group,即每個(gè)group通道數(shù)為128組,每組有48個(gè)卷積核。第3個(gè)卷積層有384組3x3大小的卷積核,每組有256個(gè)卷積核。第4個(gè)卷積層有384組3x3大小的卷積核,分為兩個(gè)group,即每個(gè)group通道數(shù)為192組,每組有192個(gè)卷積核。第5個(gè)卷積層有256組,3x3大小的卷積核,分為兩個(gè)group,即每個(gè)group為128組,每組有192個(gè)卷積核。
這個(gè)網(wǎng)絡(luò)沒有使用傳統(tǒng)的sigmoid或tanh函數(shù)作為激活函數(shù),而是使用了新型的ReLU函數(shù)[11]:
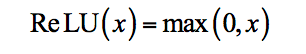
其導(dǎo)數(shù)為符號(hào)函數(shù)sgn。ReLU函數(shù)和它的導(dǎo)數(shù)計(jì)算簡(jiǎn)單,在正向傳播和反向傳播時(shí)都減少了計(jì)算量。由于在時(shí)函數(shù)的導(dǎo)數(shù)值為1,可以在一定程度上解決梯度消失問題,訓(xùn)練時(shí)有更快的收斂速度。當(dāng)時(shí)函數(shù)值為0,這使一些神經(jīng)元的輸出值為0,從而讓網(wǎng)絡(luò)變得更稀疏,起到了類似L1正則化的作用,也可以在一定程度上緩解過擬合。
ZFNet網(wǎng)絡(luò)
文獻(xiàn)[12]提出通過反卷積(轉(zhuǎn)置卷積)進(jìn)行卷積網(wǎng)絡(luò)層可視化的方法,以此分析卷積網(wǎng)絡(luò)的效果,并指導(dǎo)網(wǎng)絡(luò)的改進(jìn),在AlexNet網(wǎng)絡(luò)的基礎(chǔ)上得到了效果更好的ZFNet網(wǎng)絡(luò)。
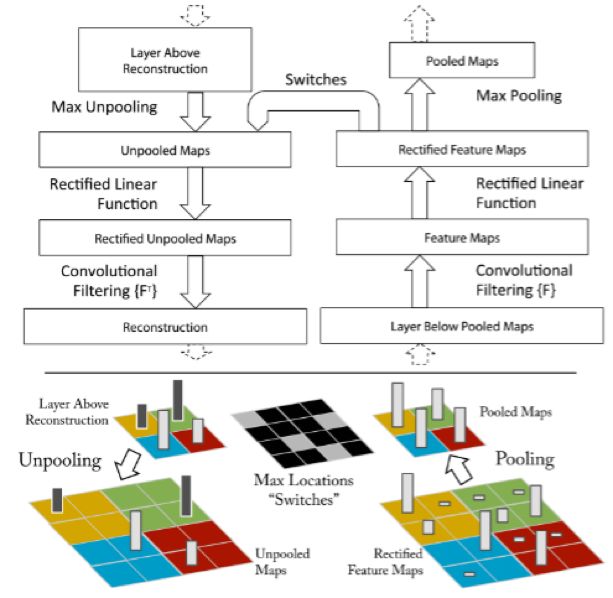
該論文是在AlexNet基礎(chǔ)上進(jìn)行了一些細(xì)節(jié)的改動(dòng),網(wǎng)絡(luò)結(jié)構(gòu)上并沒有太大的突破。該論文最大的貢獻(xiàn)在于通過使用可視化技術(shù)揭示了神經(jīng)網(wǎng)絡(luò)各層到底在干什么,起到了什么作用。如果不知道神經(jīng)網(wǎng)絡(luò)為什么取得了如此好的效果,那么只能靠不停的實(shí)驗(yàn)來尋找更好的模型。使用一個(gè)多層的反卷積網(wǎng)絡(luò)來可視化訓(xùn)練過程中特征的演化及發(fā)現(xiàn)潛在的問題;同時(shí)根據(jù)遮擋圖像局部對(duì)分類結(jié)果的影響來探討對(duì)分類任務(wù)而言到底那部分輸入信息更重要。下圖為典型反卷積網(wǎng)絡(luò)示意圖:
ZFNet網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示:
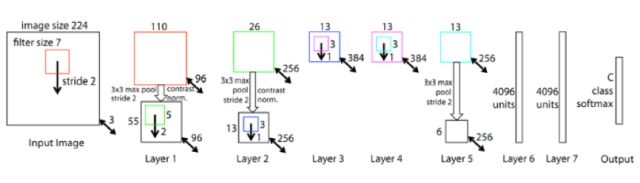
ZFNet在保留AlexNet的基本結(jié)構(gòu)的同時(shí)利用反卷積網(wǎng)絡(luò)可視化的技術(shù)對(duì)特定卷積層的卷積核尺寸進(jìn)行了調(diào)整,第一層的卷積核從11*11減小到7*7,將stride從4減小到2,Top5的錯(cuò)誤率比AlexNet比降低了1.7%。
GoogLeNet網(wǎng)絡(luò)
文獻(xiàn)[13]提出了一種稱為GoogLeNet網(wǎng)絡(luò)的結(jié)構(gòu)(Inception-V1)。在AlexNet出現(xiàn)之后,針對(duì)圖像類任務(wù)出現(xiàn)了大量改進(jìn)的網(wǎng)絡(luò)結(jié)構(gòu),總體來說改進(jìn)的思路主要是增大網(wǎng)絡(luò)的規(guī)模,包括深度和寬度。但是直接增加網(wǎng)絡(luò)的規(guī)模將面臨兩個(gè)問題,首先,網(wǎng)絡(luò)參數(shù)增加之后更容易出現(xiàn)過擬合,在訓(xùn)練樣本有限的情況下這一問題更為突出。另一個(gè)問題是計(jì)算量的增加。GoogLeNet致力于解決上面兩個(gè)問題。
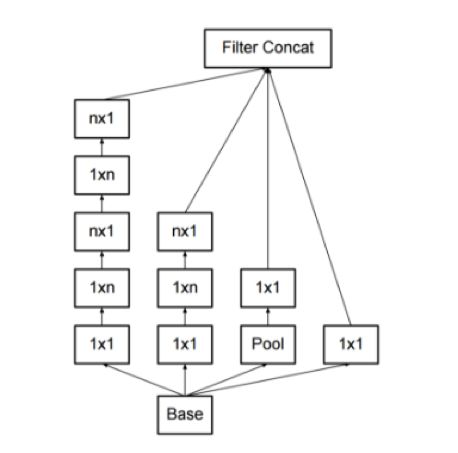
GoogLeNet由Google在2014年提出,其主要?jiǎng)?chuàng)新是Inception機(jī)制,即對(duì)圖像進(jìn)行多尺度處理。這種機(jī)制帶來的一個(gè)好處是大幅度減少了模型的參數(shù)數(shù)量,其做法是將多個(gè)不同尺度的卷積核,池化層進(jìn)行整合,形成一個(gè)Inception模塊。典型的Inception模塊結(jié)構(gòu)如下圖所示:
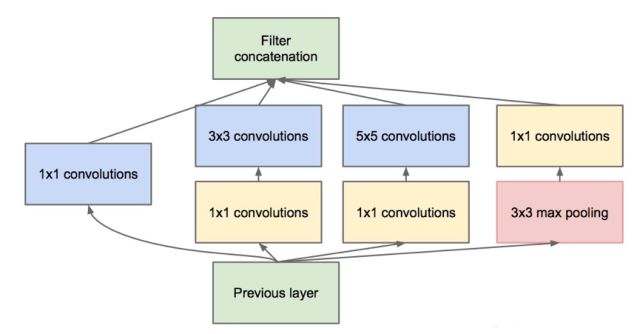
上圖的模塊由3組卷積核以及一個(gè)池化單元組成,它們共同接受來自前一層的輸入圖像,有三種尺寸的卷積核,以及一個(gè)max pooling操作,它們并行的對(duì)輸入圖像進(jìn)行處理,然后將輸出結(jié)果按照通道拼接起來。因?yàn)榫矸e操作接受的輸入圖像大小相等,而且卷積進(jìn)行了padding操作,因此輸出圖像的大小也相同,可以直接按照通道進(jìn)行拼接。
從理論上看,Inception模塊的目標(biāo)是用尺寸更小的矩陣來替代大尺寸的稀疏矩陣。即用一系列小的卷積核來替代大的卷積核,而保證二者有近似的性能。
上圖的卷積操作中,如果輸入圖像的通道數(shù)太多,則運(yùn)算量太大,而且卷積核的參數(shù)太多,因此有必要進(jìn)行數(shù)據(jù)降維。所有的卷積和池化操作都使用了1x1卷積進(jìn)行降維,即降低圖像的通道數(shù)。因?yàn)?x1卷積不會(huì)改變圖像的高度和寬度,只會(huì)改變通道數(shù)。
GoogleNet網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示:
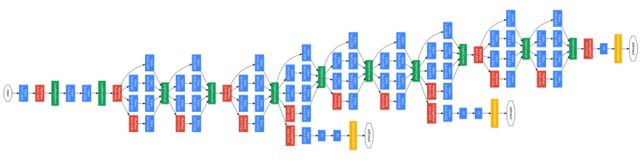
GoogleNet在ILSVRC 2014的比賽中取得分類任務(wù)的第一名,top-5錯(cuò)誤率6.67%。相較于之前的AlexNet-like網(wǎng)絡(luò),GoogleNet的網(wǎng)絡(luò)深度達(dá)到了22層,參數(shù)量減少到AlexNet的1/12,可以說是非常優(yōu)秀且非常實(shí)用的模型。
為了降低網(wǎng)絡(luò)參數(shù)作者做了2點(diǎn)嘗試,一是去除了最后的全連接層,用全局平均池化替代。全連接層幾乎占據(jù)了AlexNet中90%的參數(shù)量,而且會(huì)引起過擬合,去除全連接層后模型訓(xùn)練更快并且減輕了過擬合。用全局平均池化層取代全連接層的做法借鑒了Network In Network(以下簡(jiǎn)稱NIN)論文[16]。二是GoogleNet中精心設(shè)計(jì)的Inception模塊提高了參數(shù)的利用效率,這一部分也借鑒了NIN的思想,形象的解釋就是Inception模塊本身如同大網(wǎng)絡(luò)中的一個(gè)小網(wǎng)絡(luò),其結(jié)構(gòu)可以反復(fù)堆疊在一起形成大網(wǎng)絡(luò)。不過GoogleNet比NIN更進(jìn)一步的是增加了分支網(wǎng)絡(luò)。
VGG網(wǎng)絡(luò)
VGG網(wǎng)絡(luò)由著名的牛津大學(xué)視覺組(Visual Geometry Group)2014年提出[14],并取得了ILSVRC 2014比賽分類任務(wù)的第2名(GoogleNet第一名)和定位任務(wù)的第1名。同時(shí)VGGNet的拓展性很強(qiáng),遷移到其他圖片數(shù)據(jù)上的泛化性非常好。VGGNet的結(jié)構(gòu)非常簡(jiǎn)潔,整個(gè)網(wǎng)絡(luò)都使用了同樣大小的卷積核尺寸(3x3)和池化尺寸(2x2)。到目前為止,VGGNet依然經(jīng)常被用來提取圖像特征,被廣泛應(yīng)用于視覺領(lǐng)域的各類任務(wù)。
VGG網(wǎng)絡(luò)的主要?jiǎng)?chuàng)新是采用了小尺寸的卷積核。所有卷積層都使用3x3卷積核,并且卷積的步長(zhǎng)為1。為了保證卷積后的圖像大小不變,對(duì)圖像進(jìn)行了填充,四周各填充1個(gè)像素。所有池化層都采用2x2的核,步長(zhǎng)為2。全連接層有3層,分別包括4096,4096,1000個(gè)節(jié)點(diǎn)。除了最后一個(gè)全連接層之外,所有層都采用了ReLU激活函數(shù)。下圖為VGG16結(jié)構(gòu)圖:
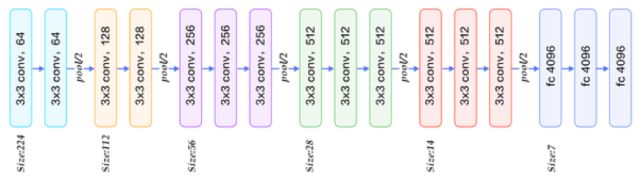
VGG與Alexnet相比,做了以下改進(jìn):
1.去掉了LRN層,作者實(shí)驗(yàn)中發(fā)現(xiàn)深度卷積網(wǎng)絡(luò)中LRN的作用并不明顯
2.采用更小的連續(xù)3x3卷積核來模擬更大尺寸的卷積核,例如2層連續(xù)的3x3卷積層可以達(dá)到一層5x5卷積層的感受野,但是所需的參數(shù)量會(huì)更少,兩個(gè)3x3卷積核有18個(gè)參數(shù)(不考慮偏置項(xiàng)),而一個(gè)5x5卷積核有25個(gè)參數(shù)。后續(xù)的殘差網(wǎng)絡(luò)等都延續(xù)了這一特點(diǎn)。
殘差網(wǎng)絡(luò)
殘差網(wǎng)絡(luò)(Residual Network)[15]用跨層連接(Shortcut Connections)擬合殘差項(xiàng)(Residual Representations)的手段來解決深層網(wǎng)絡(luò)難以訓(xùn)練的問題,將網(wǎng)絡(luò)的層數(shù)推廣到了前所未有的規(guī)模,作者在ImageNet數(shù)據(jù)集上使用了一個(gè)152層的殘差網(wǎng)絡(luò),深度是VGG網(wǎng)絡(luò)的8倍但復(fù)雜度卻更低,在ImageNet測(cè)試集上達(dá)到3.57%的top-5錯(cuò)誤率,這個(gè)結(jié)果贏得了ILSVRC2015分類任務(wù)的第一名,另外作者還在CIFAR-10數(shù)據(jù)集上對(duì)100層和1000層的殘差網(wǎng)絡(luò)進(jìn)行了分析。VGG19網(wǎng)絡(luò)和ResNet34-plain及ResNet34-redisual網(wǎng)絡(luò)對(duì)比如下:
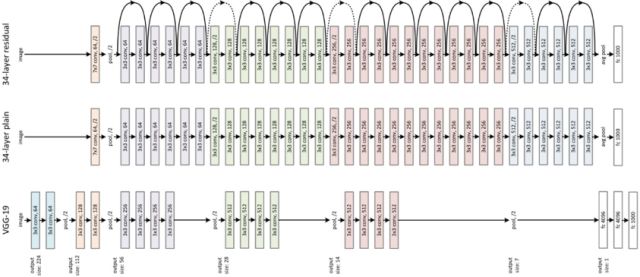
之前的經(jīng)驗(yàn)已經(jīng)證明,增加網(wǎng)絡(luò)的層數(shù)會(huì)提高網(wǎng)絡(luò)的性能,但增加到一定程度之后,隨著層次的增加,神經(jīng)網(wǎng)絡(luò)的訓(xùn)練誤差和測(cè)試誤差會(huì)增大,這和過擬合還不一樣,過擬合只是在測(cè)試集上的誤差大,這個(gè)問題稱為退化。
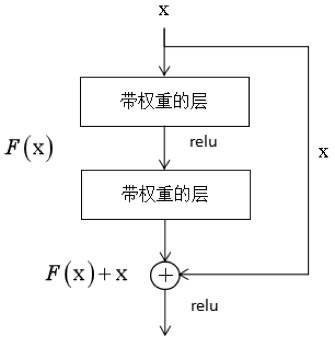
為了解決這個(gè)問題,作者設(shè)計(jì)了一種稱為深度殘差網(wǎng)絡(luò)的結(jié)構(gòu),這種網(wǎng)絡(luò)通過跳層連接和擬合殘差來解決層次過多帶來的問題,這種做法借鑒了高速公路網(wǎng)絡(luò)(Highway Networks)的設(shè)計(jì)思想,與LSTM有異曲同工之妙。這一結(jié)構(gòu)的原理如下圖所示:
后面有文獻(xiàn)對(duì)殘差網(wǎng)絡(luò)的機(jī)制進(jìn)行了分析。得出了以下結(jié)論:殘差網(wǎng)絡(luò)并不是一個(gè)單一的超深網(wǎng)絡(luò),而是多個(gè)網(wǎng)絡(luò)指數(shù)級(jí)的隱式集成,由此引入了多樣性的概念,它用來描述隱式集成的網(wǎng)絡(luò)的數(shù)量;在預(yù)測(cè)時(shí),殘差網(wǎng)絡(luò)的行為類似于集成學(xué)習(xí);對(duì)訓(xùn)練時(shí)的梯度流向進(jìn)行了分析,發(fā)現(xiàn)隱式集成大多由一些相對(duì)淺層的網(wǎng)絡(luò)組成,因此,殘差網(wǎng)絡(luò)并不能解決梯度消失問題。
為了進(jìn)一步證明殘差網(wǎng)絡(luò)的這種集成特性,并確定刪除掉一部分跨層結(jié)構(gòu)對(duì)網(wǎng)絡(luò)精度的影響,作者進(jìn)行了刪除層的實(shí)驗(yàn),在這里有兩組實(shí)驗(yàn),第一組是刪除單個(gè)層,第二組是同時(shí)刪除多個(gè)層。為了進(jìn)行比較,作者使用了殘差網(wǎng)絡(luò)和VGG網(wǎng)絡(luò)。實(shí)驗(yàn)結(jié)果證明,除了個(gè)別的層之外,刪掉單個(gè)層對(duì)殘差網(wǎng)絡(luò)的精度影響非常小。相比之下,刪掉VGG網(wǎng)絡(luò)的單個(gè)層會(huì)導(dǎo)致精度的急劇下降。這個(gè)結(jié)果驗(yàn)證了殘差網(wǎng)絡(luò)是多個(gè)網(wǎng)絡(luò)的集成這一結(jié)論。
第三組實(shí)驗(yàn)是對(duì)網(wǎng)絡(luò)的結(jié)構(gòu)進(jìn)行變動(dòng),集調(diào)整層的順序。在實(shí)驗(yàn)中,作者打亂某些層的順序,這樣會(huì)影響一部分路徑。具體做法是,隨機(jī)的交換多對(duì)層的位置,這些層接受的輸入和產(chǎn)生的輸出數(shù)據(jù)尺寸相同。同樣的,隨著調(diào)整的層的數(shù)量增加,錯(cuò)誤率也平滑的上升,這和第二組實(shí)驗(yàn)的結(jié)果一致。
但是筆者認(rèn)為作者的這種解釋有些牽強(qiáng)。普通意義上的集成學(xué)習(xí)算法,其各個(gè)弱學(xué)習(xí)器之間是相互獨(dú)立的,而這里的各個(gè)網(wǎng)絡(luò)之間共享了一些層,極端情況下,除了一層不同之外,另外的層都相同。另外,這些網(wǎng)絡(luò)是同時(shí)訓(xùn)練出來的,而且使用了相同的樣本。
GoogleNet-Inception-Like網(wǎng)絡(luò)改進(jìn)系列
Inception-V2(GoogleNet-BN)
作者基于GoogleNet的基本結(jié)構(gòu)進(jìn)行了改進(jìn),Top1錯(cuò)誤率相較減少了2個(gè)百分點(diǎn),主要做了以下的改進(jìn):
1.加入了BN層,減少了Internal Covariate Shift(內(nèi)部neuron的數(shù)據(jù)分布發(fā)生變化),使每一層的輸出都規(guī)范化到一個(gè)N(0, 1)的高斯。
2.學(xué)習(xí)VGG用2個(gè)3x3的conv替代Inception模塊中的5x5,既降低了參數(shù)數(shù)量,也加快了計(jì)算速度。
Inception-V3
Inception-V3一個(gè)最重要的改進(jìn)是卷積核分解(Factorization),將7x7的卷積核分解成兩個(gè)一維的卷積(1x7,7x1),3x3也是一樣(1x3,3x1),我們稱為非對(duì)稱分解,如下圖所示。這樣做既可以加速計(jì)算減少參數(shù)規(guī)模,又可以將1個(gè)卷積拆成2個(gè)卷積,使得網(wǎng)絡(luò)深度進(jìn)一步增加,增加了網(wǎng)絡(luò)的非線性。
除此以外作者對(duì)這個(gè)訓(xùn)練優(yōu)化的算法也做了改進(jìn):
1.通過改進(jìn)AdaGrad提出了RMSProp一種新的參數(shù)優(yōu)化的方式。RMSprop是Geoff Hinton提出的一種自適應(yīng)學(xué)習(xí)率方法。AdaGrad會(huì)累加之前所有的梯度平方,而RMSprop僅僅是計(jì)算對(duì)應(yīng)的平均值,因此可緩解AdaGrad算法學(xué)習(xí)率下降較快的問題。實(shí)驗(yàn)證明RMSProp在非凸條件下優(yōu)化結(jié)果更好。
AdaGrad的迭代公式為:
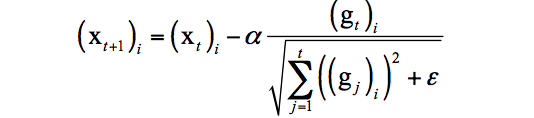
RMSProp的迭代公式為:
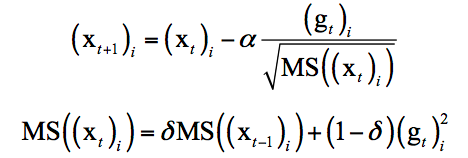
2.采用了Label Smoothing的策略,該方法是一種通過在輸出標(biāo)簽中添加噪聲,實(shí)現(xiàn)對(duì)模型進(jìn)行約束,降低模型過擬合程度的一種正則化方法。
Inception-V4
Inception-v4相較于v3版本增加了Inception模塊的數(shù)量,整個(gè)網(wǎng)絡(luò)變得更深了。
Xception
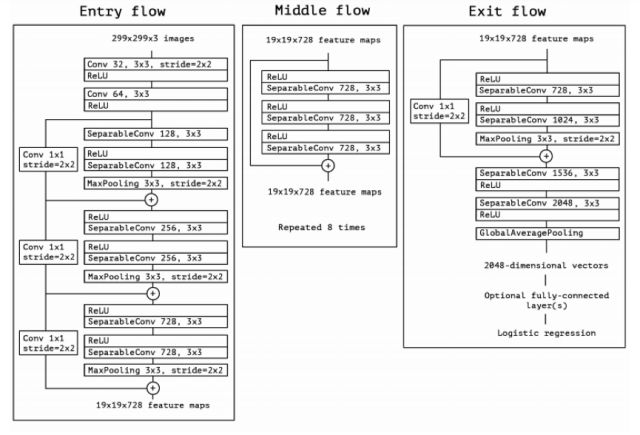
Xception是Google針對(duì)Inception v3的另一種改進(jìn),主要是采用Depthwise Separable Convolution來替換原來Inception v3中的卷積操作, 在基本不增加網(wǎng)絡(luò)復(fù)雜度的前提下提高了模型的效果。什么是Depthwise Separable Convolution? 通常,在一組特征圖上進(jìn)行卷積需要三維的卷積核,也即卷積核需要同時(shí)學(xué)習(xí)空間上的相關(guān)性和通道間的相關(guān)性。Xception通過在卷基層加入group的策略將學(xué)習(xí)空間相關(guān)性和學(xué)習(xí)通道間相關(guān)性的任務(wù)分離,大幅降低了模型的理論計(jì)算量且損失較少的準(zhǔn)確度。
Xception網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示:
Inception-ResNet v1/v2
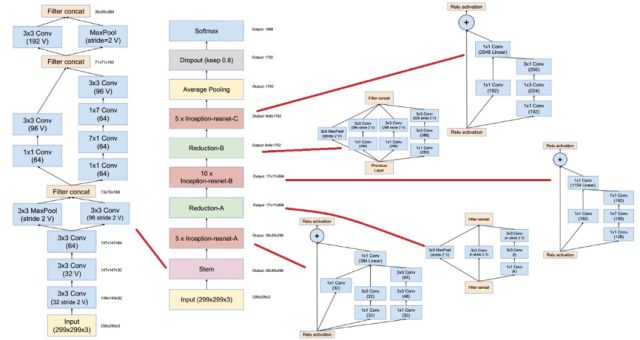
作者基于Inception-v3和Inception-v4將殘差網(wǎng)絡(luò)的思想進(jìn)行融合,分別得到了Inception-ResNet-v1和Inception-ResNet-v2兩個(gè)模型。不僅提高了分類精度而且訓(xùn)練的穩(wěn)定性也得到增強(qiáng)。
Inception-ResNet-v2 網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示:
NASNet
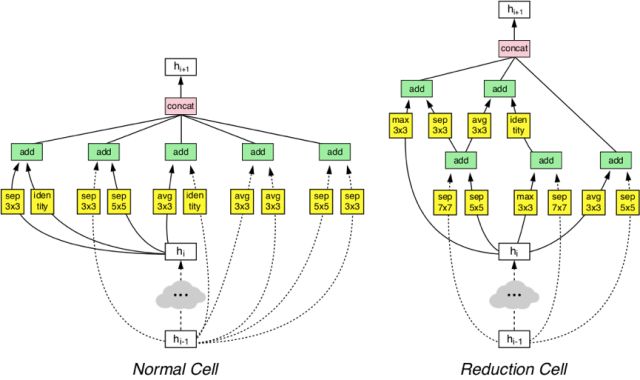
此論文由Google brain出品,是在之前的一篇論文NAS-Neural Architecture Search With Reinforcement Learning的基礎(chǔ)做了突破性的改進(jìn),使得能讓機(jī)器在小數(shù)據(jù)集(CIFAR-10數(shù)據(jù)集)上自動(dòng)設(shè)計(jì)出CNN網(wǎng)絡(luò),并利用遷移學(xué)習(xí)技術(shù)使得設(shè)計(jì)的網(wǎng)絡(luò)能夠被很好的遷移到ImageNet數(shù)據(jù)集,驗(yàn)證集上達(dá)到了82.7%的預(yù)測(cè)精度,同時(shí)也可以遷移到其他的計(jì)算機(jī)視覺任務(wù)上(如目標(biāo)檢測(cè))。該網(wǎng)絡(luò)的特點(diǎn)為:
1.延續(xù)NAS論文的核心機(jī)制,通過強(qiáng)化學(xué)習(xí)自動(dòng)產(chǎn)生網(wǎng)絡(luò)結(jié)構(gòu)。
2.采用ResNet和Inception等成熟的網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)減少了網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化的搜索空間,大型網(wǎng)絡(luò)直接由大量的同構(gòu)模塊堆疊而成,提高學(xué)習(xí)效率。
3.在CIFAR-10上進(jìn)行了架構(gòu)搜索,并將最好的架構(gòu)遷移到ImageNet圖像分類和COCO物體檢測(cè)上。
下圖為采用AutoML設(shè)計(jì)的Block結(jié)構(gòu):
VGG-Residual-Like網(wǎng)絡(luò)改進(jìn)系列
WRN(wide residual network)
作者認(rèn)為,隨著模型深度的加深,梯度反向傳播時(shí),并不能保證能夠流經(jīng)每一個(gè)殘差模塊(residual block)的權(quán)重,以至于它很難學(xué)到東西,因此在整個(gè)訓(xùn)練過程中,只有很少的幾個(gè)殘差模塊能夠?qū)W到有用的表達(dá),而絕大多數(shù)的殘差模塊起到的作用并不大。因此作者希望使用一種較淺的,但是寬度更寬的模型,來更加有效的提升模型的性能。
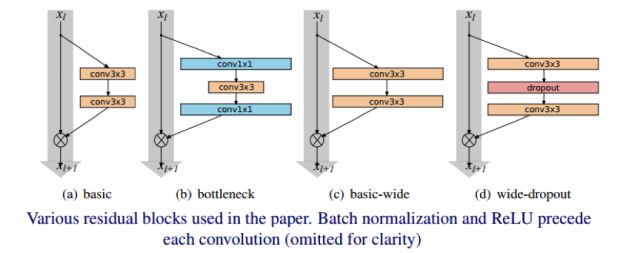
ResNet原作者針對(duì)CIFAR-10所使用的的網(wǎng)絡(luò),包含三種Residual Block,卷積通道數(shù)量分別是16、32、64,網(wǎng)絡(luò)的深度為6*N+2。而在這里,WRN作者給16、32、64之后都加了一個(gè)系數(shù)k,也就是說,作者是通過增加Residual Block卷積通道的數(shù)量來使模型變得更寬,從而N可以保持很小的值,就可以是網(wǎng)絡(luò)達(dá)到很好的效果。
CIFAR-10和CIFAR -100性能對(duì)比:
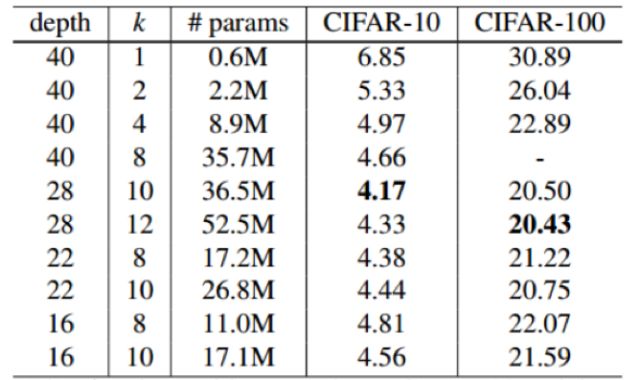
上述實(shí)驗(yàn)表明單獨(dú)增加模型的寬度是對(duì)模型的性能是有提升的。不過也不能完全的就認(rèn)為寬度比深度更好,兩者只有相互搭配,才能取得更好的效果。
ResNeXt
作者提出 ResNeXt 的主要原因在于:傳統(tǒng)的提高模型準(zhǔn)確率的做法,都是加深或加寬網(wǎng)絡(luò),但是隨著超參數(shù)數(shù)量的增加(比如通道數(shù),卷積核大小等),網(wǎng)絡(luò)設(shè)計(jì)的難度和計(jì)算開銷也會(huì)增加。因此本文提出的 ResNeXt 結(jié)構(gòu)可以在不增加參數(shù)復(fù)雜度的前提下提高準(zhǔn)確率。
這篇論文提出了ResNeXt網(wǎng)絡(luò),同時(shí)采用了VGG堆疊的思想和Inception 的 split-transform-merge 思想,但是可擴(kuò)展性比較強(qiáng),可以認(rèn)為是在增加準(zhǔn)確率的同時(shí)基本不改變或降低模型的復(fù)雜度。這里提到一個(gè)名詞cardinality,原文的解釋是the size of the set of transformations,如下圖(a)(b) cardinality=32所示:
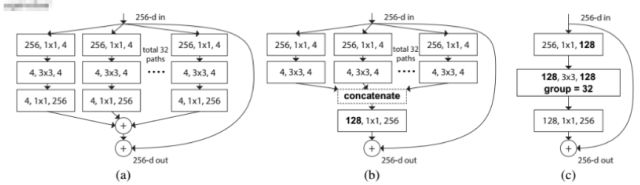
通過實(shí)驗(yàn)給出了下面的結(jié)論:
1.證明ResNeXt比ResNet更好,而且Cardinality越大效果越好
2.增大Cardinality比增大模型的width或者depth效果更好
當(dāng)時(shí)取得了state-of-art的結(jié)果,雖然后來被其它的網(wǎng)絡(luò)結(jié)構(gòu)超越,但就在最近Facebook 在圖像識(shí)別技術(shù)上又有了新突破,基于ResNeXt 101-32x48d在ImageNet測(cè)試中準(zhǔn)確度達(dá)到創(chuàng)紀(jì)錄的 85.4%!(使用了35億張圖像,1.7萬主題標(biāo)簽進(jìn)行模型訓(xùn)練,規(guī)模史無前例!!!筆者這里不下什么結(jié)論,各位看官自行體會(huì)...)
DenseNet
DenseNet 是一種具有密集連接的卷積神經(jīng)網(wǎng)絡(luò)。在該網(wǎng)絡(luò)中,任何兩層之間都有直接的連接,也就是說,網(wǎng)絡(luò)每一層的輸入都是前面所有層輸出的并集,而該層所學(xué)習(xí)的特征圖也會(huì)被直接傳給其后面所有層作為輸入。DenseNet的一個(gè)優(yōu)點(diǎn)是網(wǎng)絡(luò)更窄,參數(shù)更少,很大一部分原因得益于dense block的設(shè)計(jì),后面有提到在dense block中每個(gè)卷積層的輸出feature map的數(shù)量都很小(小于100),而不是像其他網(wǎng)絡(luò)一樣動(dòng)不動(dòng)就幾百上千的寬度。同時(shí)這種連接方式使得特征和梯度的傳遞更加有效,網(wǎng)絡(luò)也就更加容易訓(xùn)練。下面是DenseNet 的一個(gè)示意圖:
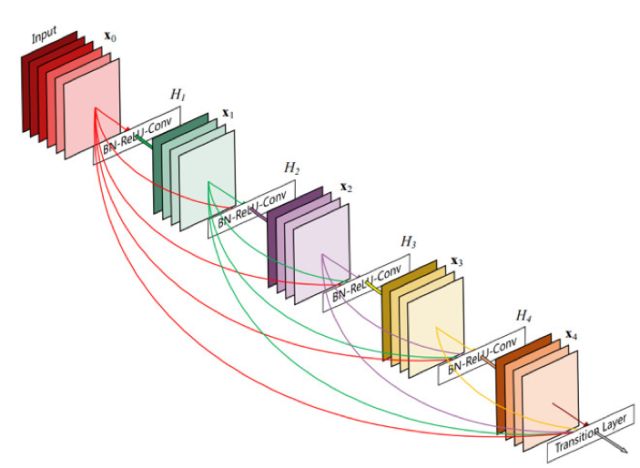
DenseNet可以有效地減少網(wǎng)絡(luò)參數(shù)規(guī)模,達(dá)到減輕過擬合的效果,對(duì)小數(shù)據(jù)集合的學(xué)習(xí)很有效果。但是由于中間輸出的feature map數(shù)量是多層Concat的結(jié)果,導(dǎo)致網(wǎng)絡(luò)在訓(xùn)練和測(cè)試的時(shí)候顯存占用并沒有明顯的優(yōu)勢(shì),計(jì)算量也沒有明顯的減少!
MobileNet
MobileNets是Google針對(duì)手機(jī)等嵌入式設(shè)備提出的一種輕量級(jí)的深層神經(jīng)網(wǎng)絡(luò),網(wǎng)絡(luò)設(shè)計(jì)的核心Separable Convolution可以在犧牲較小性能的前提下有效的減少參數(shù)量和計(jì)算量。Separable Convolution將傳統(tǒng)的卷積運(yùn)算用兩步卷積運(yùn)算代替:Depthwise convolution與Pointwise convolution,如下圖所示:
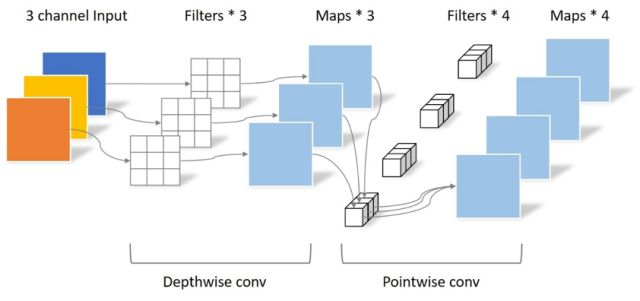
從圖中可以明確的看出,由于輸入圖片為三通道,Depthwise conv的filter數(shù)量只能為3,而傳統(tǒng)的卷積方法會(huì)有3x3總共9個(gè)filter。
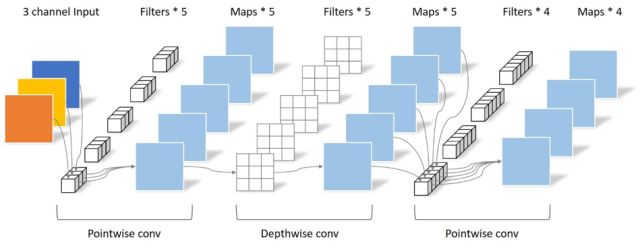
后續(xù)的MobileNet-v2主要增加了殘差結(jié)構(gòu),同時(shí)在Depthwise convolution之前添加一層Pointwise convolution,優(yōu)化了帶寬的使用,進(jìn)一步提高了在嵌入式設(shè)備上的性能。可分離卷積如下圖所示:
深度神經(jīng)網(wǎng)絡(luò)優(yōu)化策略匯總
接下來介紹卷積神經(jīng)網(wǎng)絡(luò)的各種改進(jìn)措施,其中經(jīng)典網(wǎng)絡(luò)的改進(jìn)措施已經(jīng)在前面各個(gè)網(wǎng)絡(luò)中介紹。針對(duì)卷積神經(jīng)網(wǎng)絡(luò)的改進(jìn)措施主要在以下幾個(gè)方面:卷積層,池化層,激活函數(shù),損失函數(shù),網(wǎng)絡(luò)結(jié)構(gòu),正則化技術(shù)等方面。優(yōu)化算法對(duì)網(wǎng)絡(luò)的訓(xùn)練至關(guān)重要,在這里我們單獨(dú)列出來了。
卷積層
卷積層的改進(jìn)有以下幾種:卷積核小型化,1x1卷積,Network In Network,Inception機(jī)制,卷積分解(Factorization),反卷積運(yùn)算等,下面分別介紹。
Network In Network[16]的主要思想是用一個(gè)小規(guī)模的神經(jīng)網(wǎng)絡(luò)來替代卷積層的線性濾波器,在這篇文獻(xiàn)中,小型網(wǎng)絡(luò)是一個(gè)多層感知器卷積網(wǎng)絡(luò)。顯這種小型網(wǎng)絡(luò)比線性的卷積運(yùn)算有更強(qiáng)的的描述能力。
卷積核小型化是現(xiàn)在普遍接受的觀點(diǎn),在VGG網(wǎng)絡(luò)中已經(jīng)介紹了。1x1卷積可以用于通道降維,也可以用于全卷積網(wǎng)絡(luò),保證卷積網(wǎng)絡(luò)能接受任意尺寸的輸入圖像,并能做逐像素的預(yù)測(cè)。Inception機(jī)制在GoogLeNet網(wǎng)絡(luò)中已經(jīng)介紹,這里也不在重復(fù)。
卷積操作可以轉(zhuǎn)化為圖像與一個(gè)矩陣的乘積來實(shí)現(xiàn),反卷積[17]也稱為轉(zhuǎn)置卷積,它的操作剛好和這個(gè)過程相反,正向傳播時(shí)左乘矩陣的轉(zhuǎn)置,反向傳播時(shí)左乘矩陣。注意這里的反卷積和信號(hào)處理里的反卷積不是一回事,它只能得到和原始輸出圖像尺寸相同的圖像,并不是卷積運(yùn)算的逆運(yùn)算。反卷積運(yùn)算有一些實(shí)際的用途,包括接下來要介紹的卷積網(wǎng)絡(luò)的可視化;全卷積網(wǎng)絡(luò)中的上采樣,圖像生成等。反卷積運(yùn)算通過對(duì)卷積運(yùn)算得到的輸出圖像左乘卷積矩陣的轉(zhuǎn)置,可以得到和原始圖像尺寸相同的一張圖像。
池化層
池化層的改進(jìn)主要有以下幾種:L-P池化,混合池化,隨機(jī)池化,Spatial pyramid pooling,ROI pooling。
激活函數(shù)
除了傳統(tǒng)的sigmoid,tanh函數(shù),深度卷積神經(jīng)網(wǎng)絡(luò)中出現(xiàn)了各種新的激活函數(shù),主要的有:ReLU,ELU,PReLU等,它們?nèi)〉昧瞬诲e(cuò)的效果,其中ReLU以及它的改進(jìn)型在卷積網(wǎng)絡(luò)中被普遍采用。
損失函數(shù)
損失函數(shù)也是一個(gè)重要的改進(jìn)點(diǎn)。除了歐氏距離損失之外,交叉熵,對(duì)比損失,合頁損失等相繼被使用。
在一些復(fù)雜的任務(wù)上,出現(xiàn)了多任務(wù)損失損失函數(shù)。典型的有目標(biāo)檢測(cè)算法,人臉識(shí)別算法,圖像分割算法等,這些損失函數(shù)在人臉識(shí)別、目標(biāo)檢測(cè)系列綜述文章中已經(jīng)進(jìn)行介紹,在這里不再重復(fù)。
網(wǎng)絡(luò)結(jié)構(gòu)
這里的網(wǎng)絡(luò)結(jié)構(gòu)指拓?fù)浣Y(jié)構(gòu)以及層的使用上。連接關(guān)系的改進(jìn)如殘差網(wǎng)絡(luò)和DenseNet等結(jié)構(gòu)在前面已經(jīng)做了介紹。
全卷積網(wǎng)絡(luò)Fully Convolutional Networks[31],簡(jiǎn)稱FCN,是在標(biāo)準(zhǔn)卷積網(wǎng)絡(luò)基礎(chǔ)上所做的改變,它將標(biāo)準(zhǔn)卷積網(wǎng)絡(luò)的全連接層替換成卷積層,以適應(yīng)圖像分割、深度估計(jì)等需要對(duì)原始圖像每個(gè)像素點(diǎn)進(jìn)行預(yù)測(cè)的情況。一般情況下,全卷積網(wǎng)絡(luò)最后幾個(gè)卷積層采用1x1的卷積核。由于卷積和下采樣層導(dǎo)致了圖像尺寸的減小,為了得到與原始輸入圖像尺寸相同的圖像,使用了反卷積層實(shí)現(xiàn)上采樣以得到和輸入圖像尺寸相等的預(yù)測(cè)圖像。
不同層的卷積核有不同的感受野,描述了圖像在不同尺度的信息。多尺度處理也是卷積網(wǎng)絡(luò)的一種常用手段,將不同卷積層輸出圖像匯總到一個(gè)層中進(jìn)行處理可以提取圖像多尺度的信息,典型的做法包括GoogLeNet,SSD,Cascade CNN,DenseBox。
歸一化技術(shù)
神經(jīng)網(wǎng)絡(luò)在訓(xùn)練過程中每一層的參數(shù)會(huì)隨著迭代的進(jìn)行而不斷變化,這會(huì)導(dǎo)致它后面一層的輸入數(shù)據(jù)的分布不斷發(fā)生變化,這種問題稱為internal covariate shift。在訓(xùn)練時(shí),每一層要適應(yīng)輸入數(shù)據(jù)的分布,這需要我們?cè)诘^程中調(diào)整學(xué)習(xí)率,以及精細(xì)的初始化權(quán)重參數(shù)。為了解決這個(gè)問題,我們需要對(duì)神經(jīng)網(wǎng)絡(luò)每一層的輸入數(shù)據(jù)進(jìn)行歸一化。其中一種解決方案為批量歸一化Batch Normalization[66],它是網(wǎng)絡(luò)中一種特殊的層,用于對(duì)前一層的輸入數(shù)據(jù)進(jìn)行批量歸一化,然后送入下一層進(jìn)行處理,這種做法可以加速神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過程。
優(yōu)化算法
除了標(biāo)準(zhǔn)的mini-batch隨機(jī)梯度下降法之外,還有一些改進(jìn)版本的梯度下降法,它們?cè)诤芏鄬?shí)驗(yàn)和實(shí)際應(yīng)用中取得了更好的效果,下面分別進(jìn)行介紹。
AdaGrad[67]為自適應(yīng)梯度,即adaptive gradient算法,是梯度下降法最直接的改進(jìn)。唯一不同的是,AdaGrad根據(jù)前幾輪迭代時(shí)的歷史梯度值來調(diào)整學(xué)習(xí)率。AdaDelta算法[70]也是梯度下降法的變種,在每次迭代時(shí)也利用梯度值構(gòu)造參數(shù)的更新值。Adam算法[68]全稱為adaptive moment estimation,它由梯度項(xiàng)構(gòu)造了兩個(gè)向量m和v,它們的初始值為0。NAG算法是一種凸優(yōu)化方法,由Nesterov提出。和標(biāo)準(zhǔn)梯度下降法的權(quán)重更新公式類似,NAG算法構(gòu)造一個(gè)向量v,初始值為0。RMSProp算法[69]也是標(biāo)準(zhǔn)梯度下降法的變種,它由梯度值構(gòu)造一個(gè)向量,初始化為0,
參數(shù)初始化和動(dòng)量項(xiàng)對(duì)算法的收斂都至關(guān)重要,文獻(xiàn)[32]對(duì)這兩方面的因素進(jìn)行了分析。它的觀點(diǎn)認(rèn)為,對(duì)于深度神經(jīng)網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò)的訓(xùn)練優(yōu)化問題求解,權(quán)重初始值和動(dòng)量項(xiàng)都很重要,二者缺一不可。如果初始值設(shè)置不當(dāng),即使使用動(dòng)量項(xiàng)也很難收斂到好的效果;另一方面,如果初始值設(shè)置的很好,但不使用動(dòng)量項(xiàng),收斂效果也打折扣。
理論解釋
卷積網(wǎng)絡(luò)一般有很深的層次,要對(duì)它進(jìn)行嚴(yán)格而細(xì)致的分析比較困難。與網(wǎng)絡(luò)的應(yīng)用和設(shè)計(jì)相比,對(duì)它的理論和運(yùn)行機(jī)理分析與解釋相對(duì)較少。如果我們能分析清楚卷積網(wǎng)絡(luò)的運(yùn)行機(jī)理,把卷積操作可視化的顯示出來,無論是對(duì)于理解卷積網(wǎng)絡(luò),還是對(duì)于網(wǎng)絡(luò)的設(shè)計(jì)都具有重要的意義。
對(duì)多層卷積神經(jīng)網(wǎng)絡(luò)的理論解釋和分析來自兩個(gè)方面。第一個(gè)方面是從數(shù)學(xué)角度的分析,對(duì)網(wǎng)絡(luò)的表示能力、映射特性的數(shù)學(xué)分析;第二個(gè)方面是多層卷積網(wǎng)絡(luò)和人腦視覺系統(tǒng)關(guān)系的研究,分析二者的關(guān)系有助于理解、設(shè)計(jì)更好的方法,同時(shí)也促進(jìn)了神經(jīng)科學(xué)的進(jìn)步。
典型應(yīng)用
卷積神經(jīng)網(wǎng)絡(luò)在諸多領(lǐng)域得到了成功的應(yīng)用。接下來我們將介紹它在機(jī)器視覺,計(jì)算機(jī)圖形學(xué),自然語言處理這些典型領(lǐng)域的應(yīng)用。對(duì)于這些應(yīng)用問題和為它們?cè)O(shè)計(jì)的網(wǎng)絡(luò)結(jié)構(gòu)和算法,理解的關(guān)鍵點(diǎn)是:
1.網(wǎng)絡(luò)的結(jié)構(gòu)。即網(wǎng)絡(luò)由那些層組成,各個(gè)層的作用是什么,它們的輸入數(shù)據(jù)是什么,輸出數(shù)據(jù)是什么。
2.訓(xùn)練目標(biāo)即損失函數(shù),這直接取決于要解決的問題。
機(jī)器視覺
卷積神經(jīng)網(wǎng)絡(luò)在圖像分類問題上取得成功之后很快被用于人臉檢測(cè)問題,在精度上大幅度超越之前的AdaBoost框架,當(dāng)前已經(jīng)有一些高精度、高效的算法。直接用滑動(dòng)窗口加卷積網(wǎng)絡(luò)對(duì)窗口圖像進(jìn)行分類的方案計(jì)算量太大很難達(dá)到實(shí)時(shí),使用卷積網(wǎng)絡(luò)進(jìn)行人臉檢測(cè)的方法采用各種手段解決或者避免這個(gè)問題。在這些方法中,Cascade CNN,DenseBox,F(xiàn)emaleness-Net,MT-CNN是其中的代表。
和人臉、行人等特定目標(biāo)檢測(cè)不同,通用目標(biāo)檢測(cè)的任務(wù)是同時(shí)檢測(cè)圖像中多種類型的目標(biāo)。各類目標(biāo)的形狀不同,因此目標(biāo)矩形的寬高比不同,難度更大。典型的算法是R-CNN,SPP網(wǎng)絡(luò),F(xiàn)ast R-CNN,F(xiàn)aster R-CNN,YOLO,SSD,R-FCN,F(xiàn)PN等。
人臉關(guān)鍵點(diǎn)定位的目標(biāo)是確定關(guān)鍵位置的坐標(biāo),如眼睛的中點(diǎn),鼻尖和嘴尖等。它在人臉識(shí)別、美顏等功能中都有應(yīng)用。這個(gè)問題是一個(gè)回歸問題,要實(shí)現(xiàn)的是如下映射:
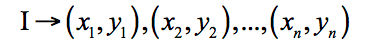
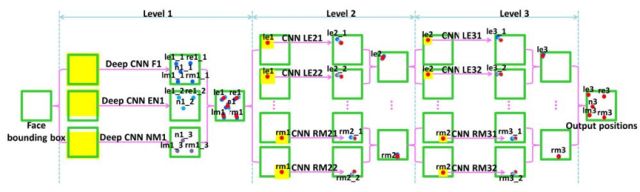
文獻(xiàn)[26]提出了一種用級(jí)聯(lián)的卷積網(wǎng)絡(luò)進(jìn)行人臉關(guān)鍵點(diǎn)檢測(cè)的方法,通過逐級(jí)細(xì)化的思路實(shí)現(xiàn)。本文檢測(cè)5個(gè)關(guān)鍵點(diǎn),分別是左右眼的中心LE和RE,鼻尖N,嘴的左右端LM和RM。采用了3個(gè)層次的卷積網(wǎng)絡(luò)進(jìn)行級(jí)聯(lián),逐步求精。第一個(gè)層次上包含3個(gè)卷積網(wǎng)絡(luò),分別稱為F1,EN1,NM1,輸入分別為整個(gè)人臉圖像,眼睛和鼻子,鼻子和嘴巴。每個(gè)網(wǎng)絡(luò)都同時(shí)預(yù)測(cè)多個(gè)關(guān)鍵點(diǎn)。對(duì)每個(gè)關(guān)鍵點(diǎn),將這些網(wǎng)絡(luò)的預(yù)測(cè)值進(jìn)行平均以減小方差。系統(tǒng)的結(jié)構(gòu)如下圖所示:
人臉識(shí)別也是深度卷積神經(jīng)網(wǎng)絡(luò)成功應(yīng)用的典型領(lǐng)域。
文字定位和識(shí)別也是卷積網(wǎng)絡(luò)成功應(yīng)用的方向[27][28][29][30],后者屬于圖像分類問題。在這里我們不詳細(xì)介紹。除了圖像分類,目標(biāo)檢測(cè)等大類任務(wù)之后,接下來我們重點(diǎn)介紹卷積網(wǎng)絡(luò)在機(jī)器視覺其他問題上的應(yīng)用。
圖像語義分割和圖像識(shí)別是密切相關(guān)的問題。分割可看做對(duì)每個(gè)像素的分類問題。卷積網(wǎng)絡(luò)在進(jìn)行多次卷積和池化后會(huì)縮小圖像的尺寸,最后的輸出結(jié)果無法對(duì)應(yīng)到原始圖像中的單一像素,卷積層后面接的全連接層將圖像映射成固定長(zhǎng)度的向量,這也與分割任務(wù)不符。針對(duì)這兩個(gè)問題有幾種解決方案,最簡(jiǎn)單的做法是對(duì)一個(gè)像素為中心的一塊區(qū)域進(jìn)行卷積,對(duì)每個(gè)像素都這樣的操作。這種方法有兩個(gè)缺點(diǎn):計(jì)算量大,利用的信息只是本像素周圍的一小片區(qū)域。更好的方法是全卷積網(wǎng)絡(luò),這是我們接下來要介紹的重點(diǎn)。
文獻(xiàn)[31]提出了一種稱為全卷積網(wǎng)絡(luò)FCN的結(jié)構(gòu)來實(shí)現(xiàn)圖像的語義分割,這種模型從卷積特征圖像恢復(fù)出原始圖像每個(gè)像素的類別。網(wǎng)絡(luò)能夠接受任意尺寸的輸入圖像,并產(chǎn)生相同尺寸的輸出圖像,輸入圖像和輸出圖像的像素一一對(duì)應(yīng)。這種網(wǎng)絡(luò)支持端到端、像素到像素的訓(xùn)練。
最簡(jiǎn)單的FCN的前半部分改裝自AlexNet網(wǎng)絡(luò),將最后兩個(gè)全連接層和一個(gè)輸出層改成3個(gè)卷積層,卷積核均為1x1大小。解決卷積和池化帶來的圖像分辨率縮小的問題的思路是上采樣。
網(wǎng)絡(luò)的最后是上采樣層,在這里用反卷積操作實(shí)現(xiàn)上采樣,反卷積的卷積核通過訓(xùn)練得到。在實(shí)現(xiàn)時(shí),在最后一個(gè)卷積層后面接上一個(gè)反卷積層,將卷積結(jié)果映射回和輸入圖像相等的尺寸。為了得到更精細(xì)的結(jié)果,可以將不同卷積層的反卷積結(jié)果組合起來。系統(tǒng)結(jié)構(gòu)如下圖所示:
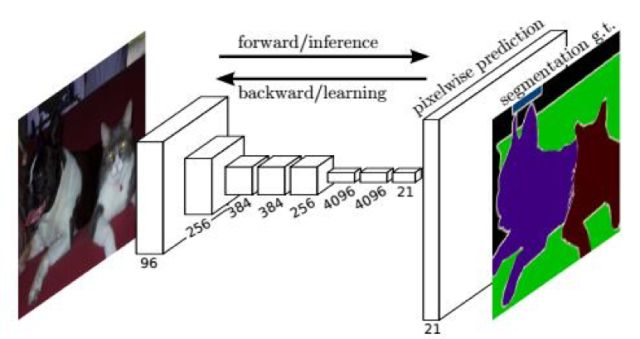
文獻(xiàn)[34]提出了一種稱為DeepLab的圖像分割方法。這個(gè)方法的創(chuàng)新有3點(diǎn):用上采樣的濾波器進(jìn)行卷積,稱為atrous卷積,以實(shí)現(xiàn)密集的、對(duì)像素級(jí)的預(yù)測(cè);采用了atrous空間金字塔下采樣技術(shù),以實(shí)現(xiàn)對(duì)物體的多尺度分割;第三點(diǎn)是使用了概率圖模型,實(shí)現(xiàn)更精確的目標(biāo)邊界定位,通過將卷積網(wǎng)絡(luò)最后一層的輸出值與一個(gè)全連接的條件隨機(jī)場(chǎng)相結(jié)合得到。算法運(yùn)行結(jié)果如下圖所示:
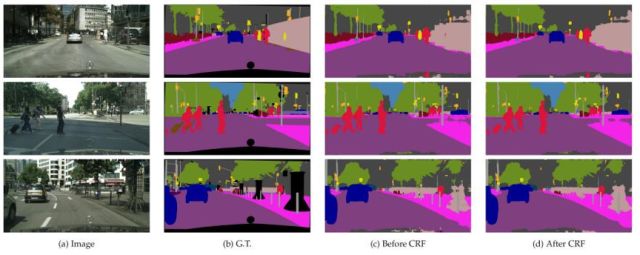
文獻(xiàn)[35]提出了一種稱為SegNet的圖像語義分割網(wǎng)絡(luò),這也是一個(gè)全卷積網(wǎng)絡(luò),其主要特點(diǎn)是整個(gè)網(wǎng)絡(luò)由編碼器和解碼器構(gòu)成。網(wǎng)絡(luò)的前半部分是編碼器,由多個(gè)卷積層和池化層組成。網(wǎng)絡(luò)的后半部分為解碼器,由多個(gè)上采樣層和卷積層構(gòu)成。解碼器的最后一層是softmax層,用于對(duì)像素進(jìn)行分類。
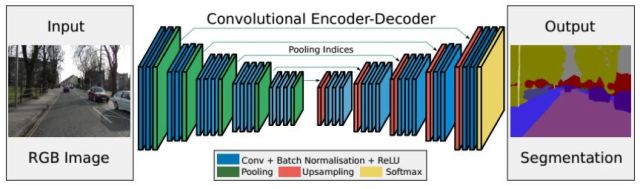
編碼器網(wǎng)絡(luò)的作用是產(chǎn)生有語義信息的特征圖像;解碼器網(wǎng)絡(luò)的作用是將編碼器網(wǎng)絡(luò)輸出的低分辨率特征圖像映射回輸入圖像的尺寸,以進(jìn)行逐像素的分類。解碼器用編碼器max池化時(shí)記住的最大元素下標(biāo)值執(zhí)行非線性上采樣,這樣上采樣的參數(shù)不用通過學(xué)習(xí)得到。上采樣得到的特征圖像通過卷積之后產(chǎn)生密集的特征圖像。整個(gè)框架實(shí)現(xiàn)了完全端到端的訓(xùn)練。
邊緣檢測(cè)的目標(biāo)是找出圖像中所有的邊緣像素點(diǎn)。Sobel算子和拉普拉斯算子都可以通過卷積和閾值化的方式提取出圖像的邊緣。更復(fù)雜的方法有Canny算子,它首先用Sobel算子得到梯度圖像,在進(jìn)行閾值化之后進(jìn)行非最大抑制,最后得到更為干凈的邊緣圖。和圖像分割一樣,純圖像處理的方法只在像素一級(jí)進(jìn)行操作,沒有利用圖像語義和結(jié)構(gòu)信息。邊緣和輪廓檢測(cè)可以看做是二分類問題,正樣本為邊緣點(diǎn)的像素,負(fù)樣本為非邊緣像素。
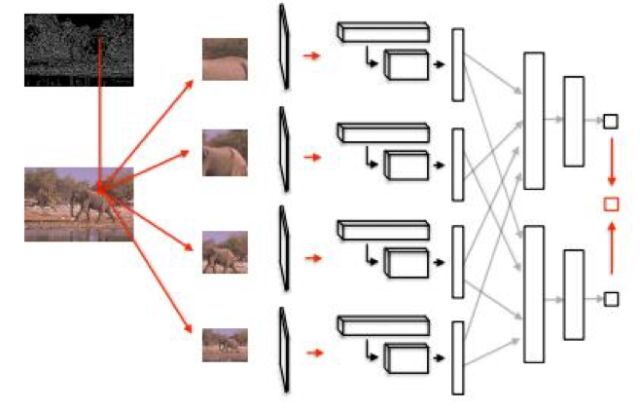
文獻(xiàn)[39]提出了一種稱為DeepEdge的邊緣提取方法,這是一種基于圖像塊的方法,卷積網(wǎng)絡(luò)作用于原始圖像中以每個(gè)像素為中心的小圖像塊,判斷該像素是否為邊緣像素。輪廓檢測(cè)流程分為如下幾步:
1.用Canny算子提取候選輪廓點(diǎn),它輸出的邊緣圖像中所有的邊界點(diǎn)作為候選輪廓點(diǎn)。
2.為所有候選輪廓點(diǎn)提取4個(gè)尺度的子圖像,將它們同時(shí)送入卷積網(wǎng)絡(luò)中進(jìn)行處理。
3.將卷積的結(jié)果送入2個(gè)子網(wǎng)絡(luò)中進(jìn)行處理,第一個(gè)網(wǎng)絡(luò)用于分類,第二個(gè)網(wǎng)絡(luò)用于回歸。
4.將這兩個(gè)網(wǎng)絡(luò)的輸出值進(jìn)行加權(quán)平均,得到最后的分?jǐn)?shù)值,這個(gè)分?jǐn)?shù)值表示該候選輪廓點(diǎn)是否真的是輪廓點(diǎn)。
5.對(duì)上一步的輸出分?jǐn)?shù)進(jìn)行閾值化,得到最終的輪廓圖像。
邊緣檢測(cè)的結(jié)果如下圖所示:
文獻(xiàn)[37]提出了一種稱為DeepContour的物體輪廓提取算法,這也是一種基于圖像塊的方法。在這里將正樣本即輪廓?jiǎng)澐譃槎鄠€(gè)子類,并且用不同的模型擬合這些子類。作者設(shè)計(jì)了一種新的損失函數(shù),稱為positive-sharing loss,各個(gè)子類共享正樣本類的損失。在這里用卷積網(wǎng)絡(luò)對(duì)小的圖像塊進(jìn)行分類,這些圖像塊從整個(gè)圖像中切分出來,可能包括輪廓,也可能不包括輪廓。

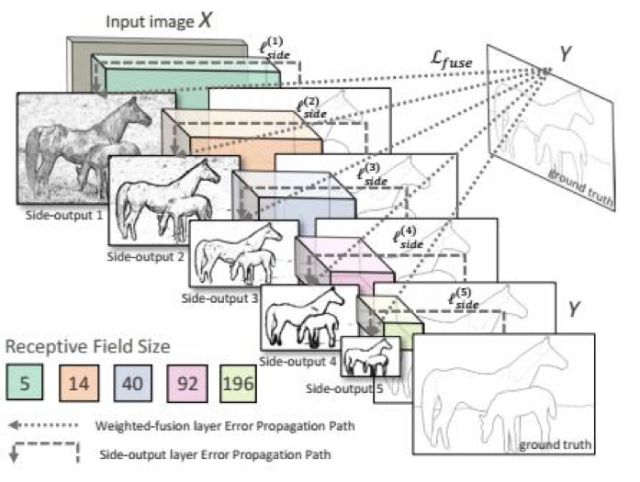
文獻(xiàn)[38]提出了一種稱為整體式嵌套(Holistically-Nested)的邊緣檢測(cè)算法。整體式是指整個(gè)算法是端到端的,嵌套式指在整個(gè)邊緣檢測(cè)的過程中通過不斷的細(xì)化求解,得到精確的邊界圖像。網(wǎng)絡(luò)對(duì)輸入圖像進(jìn)行了多尺度的處理,這通過卷積網(wǎng)絡(luò)運(yùn)行過程中得到的多個(gè)尺度的特征圖像進(jìn)行處理融合而實(shí)現(xiàn)。
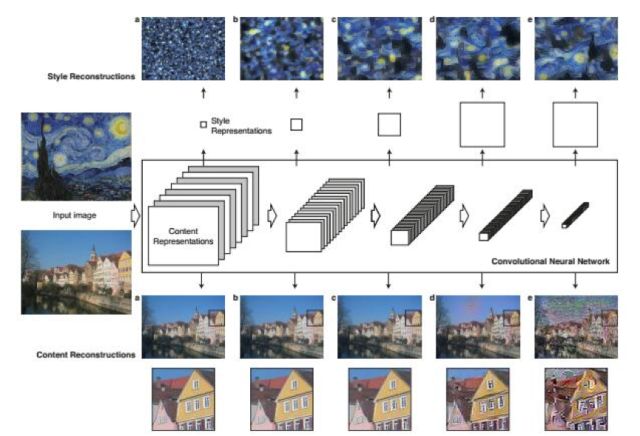
風(fēng)格遷移的任務(wù)是把輸入圖像變成另一種風(fēng)格,如油畫風(fēng)格,但要保持和輸入圖像的內(nèi)容相同,這是一個(gè)根據(jù)兩張圖像生成一張圖像的問題。
文獻(xiàn)[40]提出了一種用卷積網(wǎng)絡(luò)進(jìn)行風(fēng)格遷移的方法。在這里將風(fēng)格看成是紋理特征,風(fēng)格遷移看成是提取待遷移圖像的語義及內(nèi)容信息,然后將紋理風(fēng)格作用于該圖像,得到想要的風(fēng)格的輸出圖像。
算法的輸入包括一張風(fēng)格圖像和一張要進(jìn)行風(fēng)格遷移的內(nèi)容圖像,輸出的新圖像內(nèi)容和內(nèi)容圖像保持一致,風(fēng)格和風(fēng)格圖像保持一致。處理流程為:
1.用卷積網(wǎng)絡(luò)提取風(fēng)格圖像的風(fēng)格特征,內(nèi)容圖像的內(nèi)容特征。
2.從一張白噪聲圖像開始迭代生成目標(biāo)圖像,優(yōu)化的目標(biāo)是使得目標(biāo)圖像的風(fēng)格特征與風(fēng)格圖像相似,內(nèi)容特征與內(nèi)容圖像相似。
圖像增強(qiáng)的任務(wù)是提升圖像的對(duì)比度。文獻(xiàn)[90]提出了一種用卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行圖像增強(qiáng)的方法。其基本思想是學(xué)習(xí)人工對(duì)圖像進(jìn)行增強(qiáng)調(diào)整的模型。這種方法達(dá)到了非常好的效果,而且可以在移動(dòng)設(shè)備上做到實(shí)時(shí)處理。
在進(jìn)行圖像增強(qiáng)時(shí),卷積網(wǎng)絡(luò)輸出的是原始圖像的低分辨版本,進(jìn)行雙邊空間中的一系列仿射變換,然后對(duì)這些仿射變換進(jìn)行保邊緣的上采樣。然后將上采樣后的變換作用于原始輸出圖像,得到增強(qiáng)后的圖像。
卷積神經(jīng)網(wǎng)絡(luò)被成功的用于根據(jù)單張圖像估計(jì)深度信息。文獻(xiàn)[41]提出了一種用多尺度的卷積網(wǎng)絡(luò)從單張圖像估計(jì)深度的方法,在這里,深度信息只是相對(duì)數(shù)據(jù),即圖像中每個(gè)像素離攝像機(jī)的遠(yuǎn)近關(guān)系,而不是真實(shí)的物理距離。由于每個(gè)像素點(diǎn)都會(huì)預(yù)測(cè)出一個(gè)深度值,因此這是一個(gè)逐像素的回歸問題。
系統(tǒng)的輸入是單張RGB圖像,輸出是深度圖,和輸入圖像尺寸相同。系統(tǒng)由兩個(gè)卷積網(wǎng)絡(luò)層疊組成,第一個(gè)網(wǎng)絡(luò)對(duì)整個(gè)圖像進(jìn)行粗的全局深度預(yù)測(cè),第二個(gè)卷積網(wǎng)絡(luò)用局部信息對(duì)全局預(yù)測(cè)結(jié)果進(jìn)行求精。
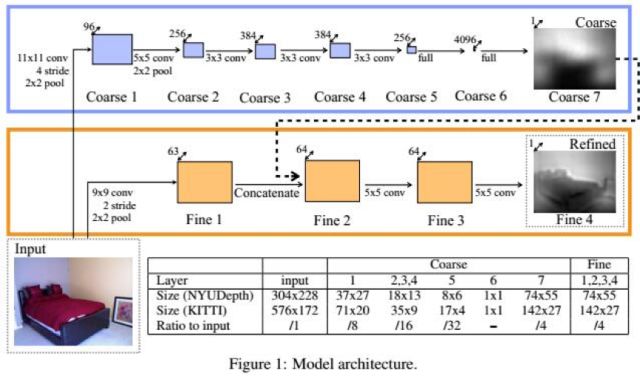
算法運(yùn)行的結(jié)果如下圖所示:
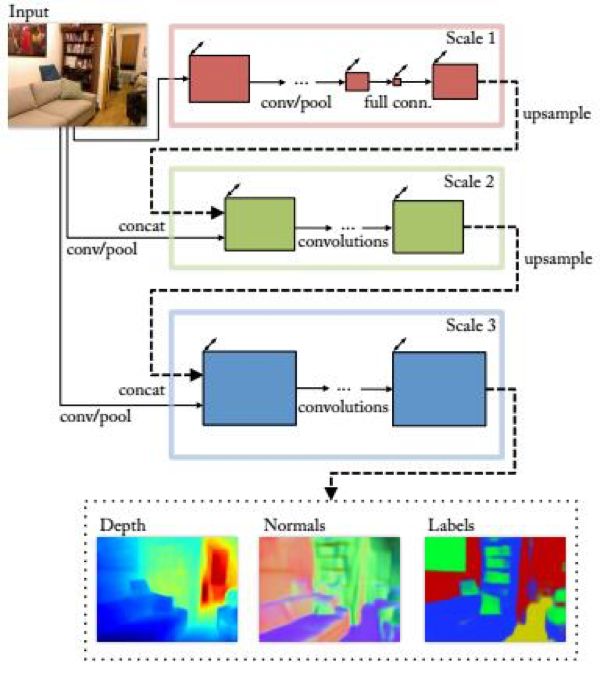
更進(jìn)一步,文獻(xiàn)[42]提出了一種用多尺度卷積神經(jīng)網(wǎng)絡(luò)從單張圖像估計(jì)深度信息、法向量的方法。這個(gè)卷積網(wǎng)絡(luò)的輸入為單張RGB圖像,輸出為三張圖像,分別為深度圖,法向量圖,以及物體分割標(biāo)記圖。
這個(gè)卷積網(wǎng)絡(luò)包括三個(gè)尺度,形成級(jí)聯(lián)結(jié)構(gòu)。每個(gè)尺度的第一個(gè)層都接受原始RGB圖像作為輸入,另外還接受上一個(gè)級(jí)卷積網(wǎng)絡(luò)的輸出作為輸入,這個(gè)輸出是經(jīng)過上采樣的。
目標(biāo)跟蹤是機(jī)器視覺領(lǐng)域中的一個(gè)重要問題,它分為單目標(biāo)跟蹤與多目標(biāo)跟蹤兩種問題。前者只跟蹤單個(gè)目標(biāo),后者要對(duì)多個(gè)目標(biāo)同時(shí)進(jìn)行跟蹤。單目標(biāo)跟蹤是一個(gè)狀態(tài)預(yù)測(cè)問題,它根據(jù)目標(biāo)在之前幀中的位置、大小、外觀和運(yùn)動(dòng)信息估計(jì)在當(dāng)前幀中的位置、大小等狀態(tài)。
文獻(xiàn)[44]用卷積神經(jīng)網(wǎng)絡(luò)來實(shí)現(xiàn)目標(biāo)的檢測(cè)以用于目標(biāo)跟蹤。網(wǎng)絡(luò)的輸入為固定尺寸的圖像,包含3個(gè)卷積層,輸出為概率圖像,表示該位置為目標(biāo)的概率。在卷積層和全連接層之間加入了SPP網(wǎng)絡(luò)中的SPP池化層,以提高目標(biāo)定位的精度。整個(gè)網(wǎng)絡(luò)先用ImageNet的目標(biāo)檢測(cè)數(shù)據(jù)集進(jìn)行離線訓(xùn)練,這樣就具有區(qū)分目標(biāo)和背景的能力。
文獻(xiàn)[46]提出了一種用全卷積網(wǎng)絡(luò)進(jìn)行目標(biāo)跟蹤的方法,卷積網(wǎng)絡(luò)的作用是目標(biāo)檢測(cè)。這種方法用一個(gè)在ImageNet數(shù)據(jù)集上預(yù)先訓(xùn)練好的卷積網(wǎng)絡(luò)提取圖像的特征,用于區(qū)分目標(biāo)和背景,卷積網(wǎng)絡(luò)采用VGG結(jié)構(gòu)。另外也用卷積網(wǎng)絡(luò)的特征生成熱度圖,表示每個(gè)位置處是目標(biāo)的概率。
文獻(xiàn)[45]提出了一種稱為Multi-Domain的卷積網(wǎng)絡(luò)結(jié)構(gòu)實(shí)現(xiàn)目標(biāo)跟蹤。這個(gè)網(wǎng)絡(luò)的前半部分是卷積層和全連接層,后面是多個(gè)domain-specific層, 它們用于實(shí)現(xiàn)目標(biāo)的精確定位。
其他的目標(biāo)跟蹤文章見參考文獻(xiàn),在此不一一列舉。
圖形學(xué)
計(jì)算機(jī)圖形學(xué)是計(jì)算機(jī)科學(xué)的一個(gè)重要分支,它的任務(wù)是用計(jì)算機(jī)程序生成圖像,尤其是真實(shí)感圖像。圖形學(xué)中有3個(gè)主要的問題:幾何模型的建立,物理模型的建立包括光照模型,渲染即由幾何和物理模型生成最終的圖像。
機(jī)器學(xué)習(xí)技術(shù)在圖形學(xué)中的應(yīng)用代表了數(shù)據(jù)驅(qū)動(dòng)這類方法,它通過大量的訓(xùn)練樣本得到要建立的模型的參數(shù),或者直接由訓(xùn)練的模型生成圖像。卷積網(wǎng)絡(luò)適合處理圖像、2D或者3D空間中的網(wǎng)格數(shù)據(jù)這里具有空間結(jié)構(gòu)的數(shù)據(jù),在圖形學(xué)的很多問題上也取得了很好的效果。
文獻(xiàn)[51]提出了一種用基于八叉樹的卷積網(wǎng)絡(luò)進(jìn)行3D形狀分析的方法,稱為O-CNN。在這里用八叉樹表示3D物體,將八叉樹最精細(xì)葉子節(jié)點(diǎn)的法向量均值作為卷積網(wǎng)絡(luò)的輸入,執(zhí)行3D卷積運(yùn)算。這種卷積網(wǎng)絡(luò)能對(duì)3D形狀進(jìn)行分類,檢索和分割。
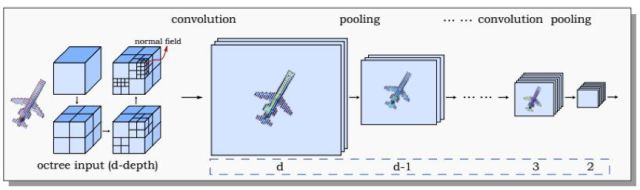
在圖形學(xué)中,物理模型包括對(duì)要繪制的物體進(jìn)行力學(xué)和光學(xué)建模。前者主要針對(duì)運(yùn)動(dòng)的物體,包括剛體和流體。對(duì)所有要渲染的物體,都需要建立光學(xué)模型,包括物體表面材質(zhì)的光學(xué)特征,以及光照模型。
文獻(xiàn)[53]提出了一種使用單張圖片估計(jì)物體表面反射函數(shù)的方法,該算法用卷積網(wǎng)絡(luò)表示表面反射函數(shù)。表面反射函數(shù)定義了物體表面的光學(xué)反射特性,它決定了給定光照條件下物體表面的顏色和紋理,這對(duì)繪制物體至關(guān)重要。
流體模擬是圖形學(xué)中一個(gè)重要的問題,它對(duì)液體、氣體如煙霧等物體的運(yùn)動(dòng)進(jìn)行建模和繪制。在仿真、游戲與動(dòng)畫、電影特技里都有這種技術(shù)的應(yīng)用。經(jīng)典的方法是基于物理的流體模擬。它主要由兩步構(gòu)成:對(duì)流體的運(yùn)動(dòng)進(jìn)行建模,及對(duì)流體的表面進(jìn)行繪制,前者的基礎(chǔ)是流體力學(xué)。在流體力學(xué)領(lǐng)域,描述流體運(yùn)動(dòng)使用的是Navier-Stokes方程,這是一個(gè)復(fù)雜的偏微分方程組。用離散化的數(shù)值方法計(jì)算需要求解大規(guī)模的方程組,非常耗時(shí),使得高精度的流體模擬很難實(shí)時(shí)進(jìn)行。
文獻(xiàn)[58]提出了一種用卷積網(wǎng)絡(luò)加速流體模擬的方法,這種方法不再求解大規(guī)模的線性方程組,而是直接用卷積網(wǎng)絡(luò)進(jìn)行預(yù)測(cè)。這個(gè)網(wǎng)絡(luò)用大量的仿真數(shù)據(jù)作為訓(xùn)練集,采用半監(jiān)督的方法進(jìn)行訓(xùn)練,目標(biāo)是最小化長(zhǎng)期速度散度。
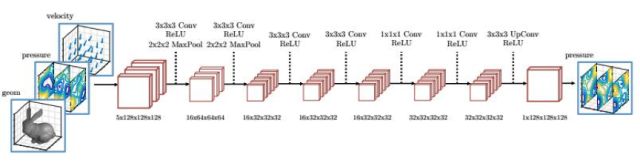
文獻(xiàn)[52]提出了一種用卷積網(wǎng)絡(luò)進(jìn)行煙霧合成的方法,其關(guān)鍵是用卷積網(wǎng)絡(luò)建立煙霧運(yùn)動(dòng)的力學(xué)模型。在這里采用了一個(gè)有4個(gè)卷積層和2個(gè)全連接層的卷積網(wǎng)絡(luò)。卷積網(wǎng)絡(luò)的作用是學(xué)習(xí)描述粗糙尺度煙霧模擬局部和精細(xì)尺度煙霧模擬局部對(duì)應(yīng)關(guān)系的映射。在新場(chǎng)景中生成精細(xì)的煙霧特效時(shí),只需進(jìn)行快速的粗糙模擬,并根據(jù)卷積網(wǎng)絡(luò)建立的映射得到與各局部相對(duì)應(yīng)的精細(xì)模擬局部,然后將其細(xì)節(jié)形體信息轉(zhuǎn)移過來即可。
紋理合成是渲染時(shí)重要的一步,它從小的紋理樣圖生成大的紋理圖像,然后映射到物體表面的曲面上,要保證生成的圖像沒有縫隙。和風(fēng)格遷移一樣,這也是一個(gè)從圖像生成圖像的問題。卷積神經(jīng)網(wǎng)絡(luò)的卷積輸出值蘊(yùn)含了圖像的信息,因此可以根據(jù)它來計(jì)算紋理特征,用來衡量樣例圖像和生成的圖像的相似度。
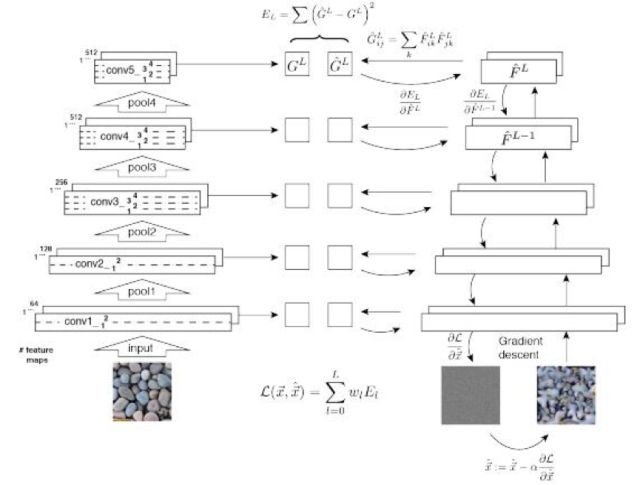
文獻(xiàn)[55]提出了一種用卷積網(wǎng)絡(luò)合成紋理的方案,其思想和前面介紹的風(fēng)格遷移類似。這個(gè)方法分為兩步。首先是紋理分析,它的輸入是紋理樣圖,送入卷積網(wǎng)絡(luò)處理之后,在各個(gè)卷積層的輸出特征圖像上計(jì)算Gram矩陣。第二步是紋理合成,它的輸入是一張白噪聲圖像,送入卷積網(wǎng)絡(luò)進(jìn)行處理,用紋理模型在卷積網(wǎng)絡(luò)的各個(gè)層上計(jì)算損失函數(shù)。然后用梯度下降法迭代更新這張白噪聲圖像,使得損失函數(shù)最小化。對(duì)白噪聲圖像的優(yōu)化結(jié)果就是合成得到的紋理圖像,它與紋理樣例圖像具有相同的Gram矩陣。
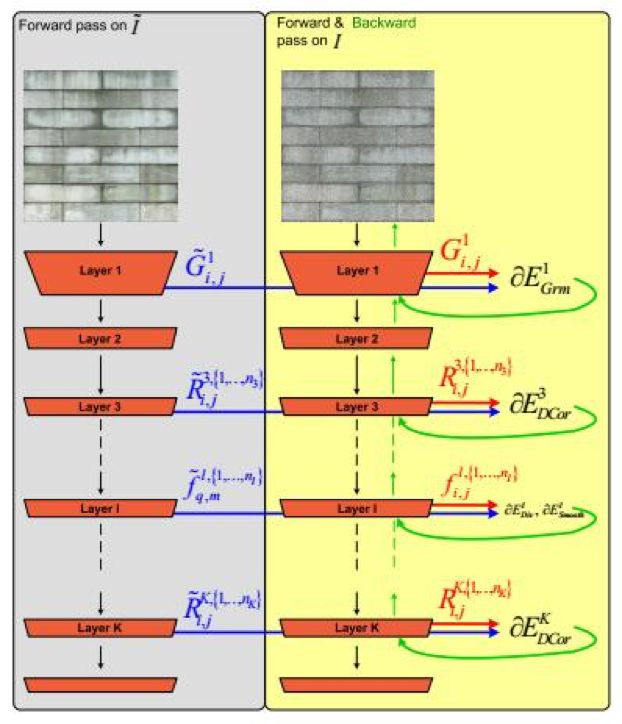
文獻(xiàn)[56]提出了一種用卷積網(wǎng)絡(luò)學(xué)習(xí)紋理的特征,然后合成紋理的方法。它們的方法思路和Leon 的類似,也是用一個(gè)卷積網(wǎng)絡(luò)提取出圖像在各個(gè)層的紋理特征,另外,用同樣的網(wǎng)絡(luò)對(duì)一張白噪聲圖像進(jìn)行處理,提取出相同的紋理特征。然后用梯度下降法更新噪聲圖像,目標(biāo)是使得二者的紋理特征相同。在這里,他們沒有使用Gram矩陣描述紋理特征,而是使用了結(jié)構(gòu)化能量,它基于輸出圖像的相關(guān)系數(shù),捕捉紋理的自相似性和規(guī)則性。
圖像彩色化的目標(biāo)是給定一張黑白圖像,在少量的用戶交互作用下生成對(duì)應(yīng)的彩色圖像。在這里的用戶交互一般是讓用戶在黑白圖像的某些位置設(shè)置顏色。
文獻(xiàn)[60]提出了一種使用卷積網(wǎng)絡(luò)將黑白圖像彩色化的方法。卷積網(wǎng)絡(luò)的輸入是灰度圖像以及少量的用戶提示信息,輸出數(shù)據(jù)是彩色圖像。其目標(biāo)是根據(jù)灰度圖像的結(jié)構(gòu)信息以及用戶在幾個(gè)典型位置的輸入顏色,預(yù)測(cè)出每個(gè)像素的顏色值。系統(tǒng)由兩個(gè)神經(jīng)網(wǎng)絡(luò)構(gòu)成。第一個(gè)為局部提示網(wǎng)絡(luò),它接受稀疏的用戶輸入;第二個(gè)網(wǎng)絡(luò)是全局提示網(wǎng)絡(luò),它使用圖像的全局統(tǒng)計(jì)信息。
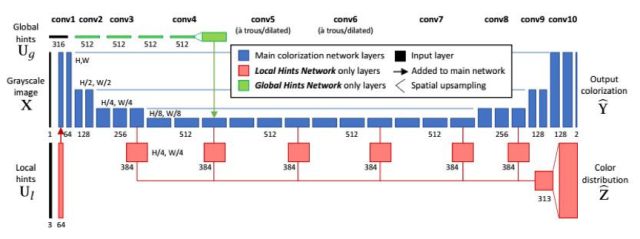
下圖是彩色化的結(jié)果:
High Dynamic Range即高度動(dòng)態(tài)范圍,簡(jiǎn)稱HDR,它確保在某些極端光照條件下,圖像的高光和弱光區(qū)域都很清晰。普通照相機(jī)因?yàn)?a target="_blank">傳感器量化范圍的限制,產(chǎn)生的圖像圖像會(huì)有欠曝光或者過曝光區(qū)域,HDR是解決這個(gè)問題的一種方法。
產(chǎn)生HDR圖像的做法一般是用相機(jī)拍攝多張有不同曝光度的LDR(Low Dynamic Range,低動(dòng)態(tài)范圍)的圖像,然后合并成一張高動(dòng)態(tài)范圍的圖像。生成HDR圖像需要解決兩個(gè)問題:1.需要將多張LDR圖像對(duì)齊,2.將這些圖像進(jìn)行合并,生成HDR圖像。第1個(gè)問題可以用光流法等手段解決,但會(huì)留下人工痕跡。
文獻(xiàn)[54]提出了一種用機(jī)器學(xué)習(xí)的手段進(jìn)行HDR圖像合成的方法。這種方法能夠根據(jù)3張不同曝光的LDR圖像生成HDR圖像。首先用光流法將高曝光與低曝光圖像與中度曝光圖像對(duì)齊,中度曝光圖像為參考圖像。最后生成的HDR圖像與參考圖像對(duì)齊,但包含另外兩張圖像即高曝光與低曝光圖像的信息。然后將3張對(duì)齊的圖像送入卷積網(wǎng)絡(luò)中預(yù)測(cè),生成HDR圖像。
自然語言處理
自然語言處理領(lǐng)域大多數(shù)的問題都是時(shí)間序列問題,這是循環(huán)神經(jīng)網(wǎng)絡(luò)擅長(zhǎng)處理的問題,在下一章中我們將詳細(xì)介紹。但對(duì)于有些問題,使用卷積網(wǎng)絡(luò)也能進(jìn)行建模并且得到了很好的結(jié)果,在這里我們重點(diǎn)介紹文本分類和機(jī)器翻譯。
文獻(xiàn)[64]設(shè)計(jì)了一種用卷積網(wǎng)絡(luò)進(jìn)行句子分類的方案。這個(gè)方法的結(jié)構(gòu)很簡(jiǎn)單,使用不同尺寸的卷積核對(duì)文本矩陣進(jìn)行卷積,卷積核的寬度等于詞向量的長(zhǎng)度,然后使用max池化。對(duì)每一個(gè)卷積核提取的向量進(jìn)行操作,最后每一個(gè)卷積核對(duì)應(yīng)一個(gè)數(shù)字,把這些數(shù)據(jù)拼接起來,得到一個(gè)表征該句子的向量。最后的預(yù)測(cè)都是基于該句子的。
文獻(xiàn)[65]提出了一種用卷積網(wǎng)絡(luò)進(jìn)行機(jī)器翻譯的方法。這篇文章用卷積網(wǎng)絡(luò)實(shí)現(xiàn)了序列到序列的學(xué)習(xí),而之前的經(jīng)典做法是用循環(huán)神經(jīng)網(wǎng)絡(luò)構(gòu)建序列到序列的學(xué)習(xí)框架。在WMT 14的英語-德語,英語-法語數(shù)據(jù)集上,這種方法的精度超越了Google的LSTM循環(huán)神經(jīng)網(wǎng)絡(luò)翻譯系統(tǒng)。
工程優(yōu)化
深度神經(jīng)網(wǎng)絡(luò)的模型需要占用大量的存儲(chǔ)空間,網(wǎng)絡(luò)傳輸時(shí)也會(huì)耗費(fèi)大量的帶寬和時(shí)間,這限制了在移動(dòng)設(shè)備、智能終端上的應(yīng)用。在Caffe中,AlexNet網(wǎng)絡(luò)的模型文件超過200MB,VGG則超過500MB,這樣的模型文件是不適合集成到app安裝包中的。因此需要對(duì)模型進(jìn)行壓縮,在下一節(jié)中我們將介紹解決這一問題的典型方法。
復(fù)雜的模型不僅帶來存儲(chǔ)空間的問題,還有計(jì)算量的增加。運(yùn)行在服務(wù)端的模型可以通過GPU、分布式等并行計(jì)算技術(shù)進(jìn)行加速,運(yùn)行在移動(dòng)端和嵌入式系統(tǒng)中的模型由于成本等因素的限制,除了采用并行計(jì)算等進(jìn)行加速之外,還需要對(duì)算法和模型本身進(jìn)行裁剪或者優(yōu)化以加快速度。在下一節(jié)中,我們將詳細(xì)介紹加快網(wǎng)絡(luò)運(yùn)行速度的方法。
減少存儲(chǔ)空間和計(jì)算量的一種方法是對(duì)神經(jīng)網(wǎng)絡(luò)的模型進(jìn)行壓縮。有多種實(shí)現(xiàn)手段,包括減小網(wǎng)絡(luò)的規(guī)模,對(duì)模型的權(quán)重矩陣進(jìn)行壓縮,對(duì)模型的參數(shù)進(jìn)行編碼,神經(jīng)網(wǎng)絡(luò)二值化等,接下來分別介紹。
權(quán)重剪枝
文獻(xiàn)[71]提出了一種卷積神經(jīng)網(wǎng)絡(luò)模型壓縮方法。在不影響精度的前提下,能夠?qū)lexNet網(wǎng)絡(luò)模型的參數(shù)減少到1/9,VGG-16網(wǎng)絡(luò)模型的參數(shù)減少到1/13。其做法是先按照正常的流程訓(xùn)練神經(jīng)網(wǎng)絡(luò),然后去掉小于指定閾值的權(quán)重,最后對(duì)剪枝后的模型進(jìn)行重新訓(xùn)練,反復(fù)執(zhí)行上面的過程直到完成模型的壓縮。
更進(jìn)一步,文獻(xiàn)[72]提出了一種稱為deep compression的深度模型壓縮技術(shù),通過剪枝、量化和哈夫曼編碼對(duì)模型進(jìn)行壓縮,而且不會(huì)影響網(wǎng)絡(luò)的精度。整個(gè)方法分為3步,第1步對(duì)模型進(jìn)行剪枝,只保留一些重要的連接。第2步通過權(quán)值量化來共享一些權(quán)值。第3步通過哈夫曼編碼來進(jìn)一步壓縮數(shù)據(jù)。
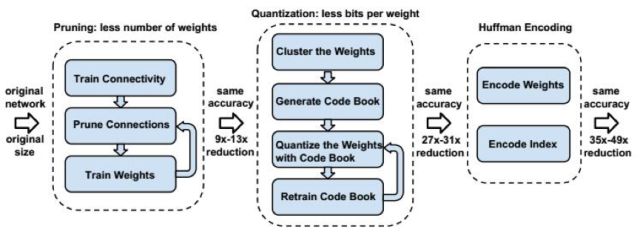
二值化網(wǎng)絡(luò)
將網(wǎng)絡(luò)的權(quán)重由浮點(diǎn)數(shù)轉(zhuǎn)換為定點(diǎn)數(shù)甚至是二值數(shù)據(jù)可以大幅度的提高計(jì)算的速度,減少模型的存儲(chǔ)空間。相比浮點(diǎn)數(shù)的加法和乘法運(yùn)算,定點(diǎn)數(shù)要快很多,而二值化數(shù)據(jù)的運(yùn)算可以直接用位運(yùn)算實(shí)現(xiàn),帶來的加速比更大。
文獻(xiàn)[73]提出了一種稱為二值神經(jīng)網(wǎng)絡(luò)(簡(jiǎn)稱BNN)的模型。二值神經(jīng)網(wǎng)絡(luò)的權(quán)重值和激活函數(shù)都是二值化的數(shù)據(jù),這能顯著減小模型存儲(chǔ)空間,并且加快模型的計(jì)算速度。
文獻(xiàn)[74]提出了一種稱為二值權(quán)重網(wǎng)絡(luò)和XNOR(同或門)網(wǎng)絡(luò)的模型,這是對(duì)卷積神經(jīng)網(wǎng)絡(luò)的二值化逼近,也是對(duì)文獻(xiàn)[17]方法的進(jìn)一步優(yōu)化。
二值權(quán)重網(wǎng)絡(luò)的權(quán)重矩陣是二值化數(shù)據(jù),輸入數(shù)據(jù)是實(shí)數(shù)。XNOR網(wǎng)絡(luò)的卷積核、卷積層、全連接層的輸入數(shù)據(jù)都是二值化的。在不損失精度的前提下,XNOR網(wǎng)絡(luò)能夠把模型的存儲(chǔ)空間壓縮為1/32,速度提升58倍。
參考文獻(xiàn):
[1] .LeCun, B.Boser, J.S.Denker, D.Henderson, R.E.Howard, W.Hubbard, and L.D.Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1989.
[2] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Handwritten digit recognition with a back-propagation network. In David Touretzky, editor, Advances in Neural Information Processing Systems 2 (NIPS*89), Denver, CO, 1990, Morgan Kaufman.
[3] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, november 1998.
[4] H. Rowley, S. Baluja, and T. Kanade. Neural Network-Based Face Detection. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE Computer Society, 1996. 203-208
[5] H. Rowley, S. Baluja, and T. Kanade. Rotation Invariant Neural Network-Based Face Detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Santa Barbara, CA, USA: IEEE Computer Society, 1998. 38-44
[6] S Lawrence, C L Giles, Ah Chung Tsoi, Andrew D Back.Face recognition: a convolutional neural-network approach.1997, IEEE Transactions on Neural Networks.
[7] P. Y. Simard, D. Steinkraus, and J. C. Platt, Best practices for convolutional neural networks applied to visual document analysis. in null. IEEE, 2003.
[8] X. Glorot, Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. AISTATS, 2010.
[9] Alex Krizhevsky, Ilya Sutskever, Geoffrey E.Hinton. ImageNet Classification with Deep Convolutional Neural Networks.
[10] G.E.Hinton, N.Srivastava, A.Krizhevsky, I.Sutskever, and R.R.Salakhutdinov. Improving neural networks by preventing coadaptation of feature detectors. arXiv:1207.0580, 2012.
[11] Nair, V. and Hinton. Rectified linear units improve restricted Boltzmann machines. In L. Bottou and M. Littman, editors, Proceedings of the Twenty-seventh International Conference on Machine Learning (ICML 2010).
[12] Zeiler M D, Fergus R. Visualizing and Understanding Convolutional Networks. European Conference on Computer Vision, 2013.
[13] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions, Arxiv Link: http://arxiv.org/abs/1409.4842.
[14] K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition.
[15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition. 2015, computer vision and pattern recognition.
[16] Lin, Min, Qiang Chen, and Shuicheng Yan. Network in network. arXiv preprint arXiv:1312.4400
[17] Zeiler M D, Krishnan D, Taylor G W, et al. Deconvolutional networks. Computer Vision and Pattern Recognition, 2010.
[18] Stephane Mallat. Understanding deep convolutional networks. 2016, Philosophical Transactions of the Royal Society A.
[19] Aravindh Mahendran, Andrea Vedaldi. Understanding Deep Image Representations by Inverting Them. CVPR 2015.
[20] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV. 2014.
[21] Ross Girshick. Fast R-CNN. 2015, international conference on computer vision.
[22] Anelia Angelova, Alex Krizhevsky, Vincent Vanhoucke, Abhijit Ogale, Dave Ferguson. Real-Time Pedestrian Detection With Deep Network Cascades.
[23] Haoxiang Li, Zhe Lin, Xiaohui Shen, Jonathan Brandt, Gang Hua. A convolutional neural network cascade for face detection. 2015, computer vision and pattern recognition
[24] Lichao Huang, Yi Yang, Yafeng Deng, Yinan Yu. DenseBox: Unifying Landmark Localization with End to End Object Detection. 2015, arXiv: Computer Vision and Pattern Recognition
[25] Shuo Yang, Ping Luo, Chen Change Loy, Xiaoou Tang. Faceness-Net: Face Detection through Deep Facial Part Responses.
[26] Yi Sun, Xiaogang Wang, Xiaoou Tang. Deep Convolutional Network Cascade for Facial Point Detection. 2013, computer vision and pattern recognition.
[27] Kobchaisawat T, Chalidabhongse T H. Thai text localization in natural scene images using Convolutional Neural Network. Asia-Pacific Signal and Information Processing Association, 2014 Annual Summit and Conference (APSIPA). IEEE, 2014: 1-7.
[28] Guo Q, Lei J, Tu D, et al. Reading numbers in natural scene images with convolutional neural networks. Security, Pattern Analysis, and Cybernetics (SPAC), 2014 International Conference on. IEEE, 2014: 48-53.
[29] Xu H, Su F. A robust hierarchical detection method for scene text based on convolutional neural networks. Multimedia and Expo (ICME), 2015 IEEE International Conference on. IEEE, 2015: 1-6.
[30] Cire?an D C, Meier U, Gambardella L M, et al. Convolutional neural network committees for handwritten character classification. Document Analysis and Recognition (ICDAR), 2011 International Conference on. IEEE, 2011: 1135-1139.
[31] Long J, Shelhamer E, Darrell T, et al. Fully convolutional networks for semantic segmentation. Computer Vision and Pattern Recognition, 2015.
[32] I. Sutskever, J. Martens, G. Dahl, and G. Hinton. On the Importance of Initialization and Momentum in Deep Learning. Proceedings of the 30th International Conference on Machine Learning, 2013.
[33] Hyeonwoo Noh, Seunghoon Hong, Bohyung Han. Learning Deconvolution Network for Semantic Segmentation. 2015, international conference on computer vision.
[34] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L.Yuille. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. 2016.
[35] Vijay Badrinarayanan, Alex Kendall, Roberto Cipolla. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.
[36] R. Girshick, J. Donahue, T. Darrell, J. Malik. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, May. 2015.
[37] Wei Shen, Xinggang Wang, Yan Wang, Xiang Bai, Zhijiang Zhang. DeepContour: A deep convolutional feature learned by positive-sharing loss for contour detection. 2015 computer vision and pattern recognition.
[38] Saining Xie, Zhuowen Tu. Holistically-Nested Edge Detection. 2015. international conference on computer vision.
[39] Gedas Bertasius, Jianbo Shi, Lorenzo Torresani. DeepEdge: A multi-scale bifurcated deep network for top-down contour detection. 2015, computer vision and pattern recognition
[40] Gatys L A, Ecker A S, Bethge M. Image Style Transfer Using Convolutional Neural Networks. CVPR 2016.
[41] David Eigen, Christian Puhrsch, Rob Fergus. Depth Map Prediction from a Single Image using a Multi-Scale Deep Network. 2014, neural information processing systems.
[42] David Eigen, Rob Fergus. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-scale Convolutional Architecture. 2015, international conference on computer vision.
[43] Naiyan Wang, Dityan Yeung. Learning a Deep Compact Image Representation for Visual Tracking. 2013, neural information processing systems.
[44] Naiyan Wang, Siyi Li, Abhinav Gupta, Dityan Yeung. Transferring Rich Feature Hierarchies for Robust Visual Tracking. 2015, arXiv: Computer Vision and Pattern Recognition.
[45] Hyeonseob Nam, Bohyung Han. Learning Multi-domain Convolutional Neural Networks for Visual Tracking. 2016, computer vision and pattern recognition.
[46] Lijun Wang, Wanli Ouyang, Xiaogang Wang, Huchuan Lu. Visual Tracking with Fully Convolutional Networks. 2015, international conference on computer vision.
[47] Chao Ma, Jiabin Huang, Xiaokang Yang, Minghsuan Yang. Hierarchical Convolutional Features for Visual Tracking. 2015, international conference on computer vision.
[48] Yuankai Qi, Shengping Zhang, Lei Qin, Hongxun Yao, Qingming Huang, Jongwoo Lim, Minghsuan. Hedged Deep Tracking. 2016, computer vision and pattern recognition.
[49] Luca Bertinetto, Jack Valmadre, Joao F Henriques, Andrea Vedaldi, Philip H S Torr. Fully-Convolutional Siamese Networks for Object Tracking. 2016, european conference on computer vision.
[50] David Held, Sebastian Thrun, Silvio Savarese. Learning to Track at 100 FPS with Deep Regression Networks. 2016, european conference on computer vision.
[51] Pengshuai Wang, Yang Liu, Yuxiao Guo, Chunyu Sun, Xin Tong. O-CNN: octree-based convolutional neural networks for 3D shape analysis. 2017, ACM Transactions on Graphics.
[52] Mengyu Chu, Nils Thuerey. Data-Driven Synthesis of Smoke Flows with CNN-based Feature Descriptors. 2017, ACM Transactions on Graphics
[53] Xiao Li, Yue Dong, Pieter Peers, Xin Tong. Modeling surface appearance from a single photograph using self-augmented convolutional neural networks. 2017, ACM Transactions on Graphics.
[54] Nima Khademi Kalantari, Ravi Ramamoorthi. Deep high dynamic range imaging of dynamic scenes. 2017, ACM Transactions on Graphics.
[55] Leon A Gatys, Alexander S Ecker, Matthias Bethge. Texture synthesis using convolutional neural networks. 2015, neural information processing systems.
[56] Omry Sendik, Daniel Cohenor. Deep Correlations for Texture Synthesis. 2017, ACM Transactions on Graphics
[57] Michael Gharbi, Jiawen Chen, Jonathan T Barron, Samuel W Hasinoff, Fredo Durand. Deep Bilateral Learning for Real-Time Image Enhancement. 2017, ACM Transactions on Graphics.
[58] Jonathan Tompson, Kristofer Schlachter, Pablo Sprechmann, Ken Perlin. Accelerating Eulerian Fluid Simulation With Convolutional Networks. 2016,international conference on machine learning.
[59] Peiran Ren,Yue Dong,Stephen Lin,Xin Tong,Baining Guo. Image based relighting using neural networks. 2015,international conference on computer graphics and interactive techniques.
[60] Richard zhang, Jun-Yan Zhu, Phillip Isola, XinYang Geng, Angela S. Lin, Tianhe Yu, Alexei A. Efros. Real-Time User-Guided Image Colorization with Learned Deep Priors.
[61] Yoon Kim. Convolutional Neural Networks for Sentence Classification. 2014, empirical methods in natural language processing.
[62] Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification. arXiv preprint arXiv:1509.01626, 2015.
[63] Rie Johnson and Tong Zhang. Effective use of word order for text categorization with convolutional neural networks. arXiv preprint arXiv:1408.5882, 2014.
[64] Phil Blunsom, Edward Grefenstette, Nal Kalchbrenner, et al. A Convolutional neural network for modelling sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. 2015.
[65] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, Yann N. Dauphin. Convolutional Sequence to Sequence Learning. 2017.
[66] S. Ioffe and C. Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv preprint arXiv:1502.03167 (2015).
[67] Duchi, E. Hazan, and Y. Singer. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. The Journal of Machine Learning Research, 2011.
[68] D. Kingma, J. Ba. Adam: A Method for Stochastic Optimization. International Conference for Learning Representations, 2015.
[69] T. Tieleman, and G. Hinton. RMSProp: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning.Technical report, 2012.
[70] M. Zeiler. ADADELTA: An Adaptive Learning Rate Method. arXiv preprint, 2012.
[71] Han, Song, Pool, Jeff, Tran, John, and Dally, William J. Learning both weights and connections for efficient neural networks. In Advances in Neural Information Processing Systems, 2015.
[72] Song Han, Huizi Mao, William J Dally. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. 2016, international conference on learning representations.
[73] Matthieu Courbariaux, Itay Hubara, Daniel Soudry, Ran Elyaniv, Yoshua Bengio. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1. 2016,arXiv: Learning.
[74] Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, Ali Farhadi. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. 2016, european conference on computer vision.
-
卷積神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
4文章
366瀏覽量
11853 -
vgg
+關(guān)注
關(guān)注
1文章
11瀏覽量
5185
原文標(biāo)題:深度卷積神經(jīng)網(wǎng)絡(luò)演化歷史及結(jié)構(gòu)改進(jìn)脈絡(luò)-40頁長(zhǎng)文全面解讀
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論