 如何用更少的數據自動將文本分類,同時精確度還比原來的方法高
如何用更少的數據自動將文本分類,同時精確度還比原來的方法高
編者按:這篇文章作者是數據科學家Jeremy Howard和自然語言處理專家Sebastian Ruder,目的是幫助新手和外行人更好地了解他們的新論文。該論文展示了如何用更少的數據自動將文本分類,同時精確度還比原來的方法高。本文會用簡單的術語解釋自然語言處理、文本分類、遷移學習、語言建模、以及他們的方法是如何將這幾個概念結合在一起的。如果你已經對NLP和深度學習很熟悉了,可以直接進入項目主頁.
簡介
5月14日,我們發表了論文Universal Language Model Fine-tuning for Text Classification(ULMFiT),這是一個預訓練模型,同時用Python進行了開源。論文已經經過了同行評議,并且將在ACL 2018上作報告。上面的鏈接提供了對論文方法的深度講解視頻,以及所用到的Python模塊、與訓練模型和搭建自己模型的腳本。

這一模型顯著提高了文本分類的效率,同時,代碼和與訓練模型能讓每位用戶用這種新方法更好地解決以下問題:
找到與某一法律案件相關的文件;
對商品積極和消極的評價進行分類;
對文章進行政治傾向分類;
其他
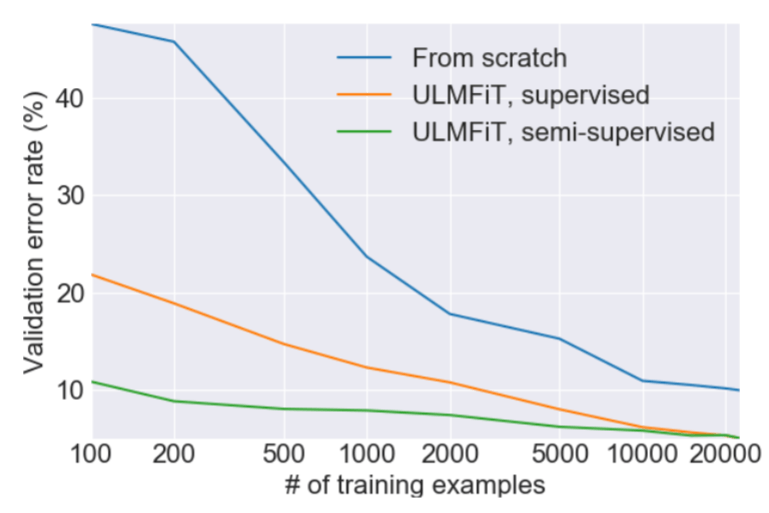
ULMFiT所需的數量比其他方法少
所以,這項新技術到底帶來了哪些改變呢?首先讓我們看看摘要部分講了什么,之后在文章的其他部分我們會展開來講這是什么意思:
遷移學習為計算機視覺帶來了巨大改變,但是現有的NLP技術仍需要針對具體任務改進模型,并且從零開始訓練。我們提出了一種有效的遷移學習方法,可以應用到NLP領域的任何一種任務上,同時提出的技術對調整語言模型來說非常關鍵。我們的方法在六種文本分類任務上比現有的技術都要優秀,除此之外,這種方法僅用100個帶有標簽的樣本進行訓練,最終的性能就達到了從零開始、擁有上萬個訓練數據的模型性能。
NLP、深度學習和分類
自然語言處理是計算機科學和人工智能領域的特殊任務,顧名思義,就是用計算機處理世界上的語言。自然語言指的是我們每天用來交流的話語,例如英語或中文,與專業語言相對(計算機代碼或音符)。NLP的應用范圍十分廣泛,例如搜索、私人助理、總結等等。總的來說,由于編寫的計算機代碼很難表達出語言的不同情感和細微差別,缺少靈活性,就導致自然語言處理是一項非常具有挑戰性的任務。可能你在生活中已經體驗過與NLP打交道的事了,例如與自動回復機器人打電話,或者和Siri對話,但是體驗不太流暢。
過去幾年,我們開始看到深度學習正超越傳統計算機,在NLP領域取得了不錯的成果。與之前需要由程序定義一系列固定規則不同,深度學習使用的是從數據中直接學到豐富的非線性關系的神經網絡進行處理計算。當然,深度學習最顯著的成就還是在計算機視覺(CV)領域,我們可以在之前的ImageNet圖像分類競賽中感受到它快速的進步。
深度學習同樣在NLP領域取得了很多成功,例如《紐約時報》曾報道過的自動翻譯已經有了許多應用。這些成功的NLP任務都有一個共同特征,即它們在訓練模型時都有大量標記過的數據可用。然而,直到現在,這些應用也只能用于能夠收集到大量帶標記的數據集的模型上,同時還要求有計算機群組能長時間計算。
深度學習在NLP領域最具挑戰性的問題正是CV領域最成功的問題:分類。這指的是將任意物品歸類到某一群組中,例如將文件或圖像歸類到狗或貓的數據集中,或者判斷是積極還是消極的等等。現實中的很多問題都能看作是分類問題,這也是為什么深度學習在ImageNet上分類的成功催生了各類相關的商業應用。在NLP領域,目前的技術能很好地做出“識別”,例如,想要知道一篇影評是積極還是消極,要做的就是“情感分析”。但是隨著文章的情感越來越模糊,模型就難以判斷,因為沒有足夠可學的標簽數據。
遷移學習
我們的目標就是解決這兩個問題:
在NLP問題中,當我們沒有大規模數據和計算資源時,怎么辦?
讓NLP的分類變得簡單
研究的參與者(Jeremy Howard和Sebastian Ruder)所從事的領域恰好能解決這一問題,即遷移學習。遷移學習指的是用某種解決特定問題的模型(例如對ImageNet的圖像進行分類)作為基礎,去解決與之類似的問題。常見方法是對原始模型進行微調,例如Jeremy Howard曾經將上述分類模型遷移到CT圖像分類以檢測是否有癌癥。由于調整后的模型無需從零開始學習,它所能達到的精度要比數據較少、計算時間較短的模型更高。
許多年來,只使用單一權重層的簡單遷移學習非常受歡迎,例如谷歌的word2vec嵌入。然而,實際中的完全神經網絡包含很多層,所以只在單一層運用遷移學習僅僅解決了表面問題。
重點是,想要解決NLP問題,我們應該從哪里遷移學習?這一問題困擾了Jeremy Howard很久,然而當他的朋友Stephen Merity宣布開發出AWD LSTM語言模型,這對語言建模是重大進步。一個語言模型是一個NLP模型,它可以預測一句話中下一個單詞是什么。例如,手機內置的語言模型可以猜到發信息時下一步你會打哪個字。這項成果之所以非常重要,是因為一個語言模型要想正確猜測接下來你要說什么,它就要具備很多知識,同時對語法、語義及其他自然語言的元素有著非常全面的了解。我們在閱讀或分類文本時也具備這種能力,只是我們對此并不自知。
我們發現,將這種方法應用于遷移學習,有助于成為NLP遷移學習的通用方法:
不論文件大小、數量多少以及標簽類型,該方法都適用
它只有一種結構和訓練過程
它無需定制特殊的工程和預處理
它無需額外的相關文件或標簽
開始工作
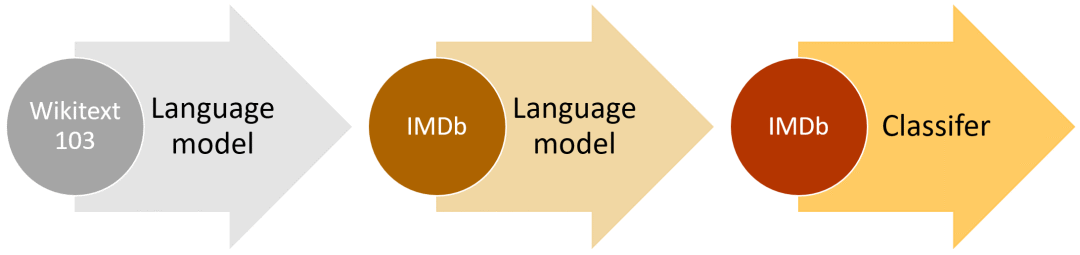
ULMFiT的高層次方法(以IMDb為例)
這種方法之前曾嘗試過,但是為了達到合格的性能,需要上百萬個文本。我們發現,通過調整語言模型,就能達到更好的效果。特別是,我們發現如果仔細控制模型的學習速度,并更新預訓練模型以保證它不會遺忘此前所學內容,那么模型可以在新數據集上適應得更好。令人激動的是,我們發現模型能夠在有限的樣本中學得更好。在含有兩種類別的文本分類數據集上,我們發現將我們的模型在100個樣本上訓練達到的效果和從零開始、在10000個標記樣本上訓練的效果相同。
另外一個重要的特點是,我們可以用任何足夠大且通用的語料庫建立一個全球通用的語言模型,從而可以針對任意目標語料進行調整。我們決定用Stephen Merity的WikiText 103數據集來做,其中包含了經過與處理的英文維基百科子集。
NLP領域的許多研究都是在英文環境中的,如果用非英語語言訓練模型,就會帶來一系列難題。通常,公開的非英語語言數據集非常少,如果你想訓練泰語的文本分類模型,你就得自己收集數據。收集非英語文本數據意味著你需要自己標注或者尋找標注者,因為類似亞馬遜的Mechanical Turk這種眾籌服務通常只有英文標注者。
有了ULMFiT,我們可以非常輕松地訓練英語之外的文本分類模型,目前已經支持301種語言。為了讓這一工作變得更容易,我們未來將發布一個模型合集(model zoo),其中內置各種語言的預訓練模型。
ULMFiT的未來
我們已經證明,這項技術在相同配置下的不同任務中表現得都很好。除了文本分類,我們希望ULMFiT未來能解決其他重要的NLP問題,例如序列標簽或自然語言生成等。
計算機視覺領域遷移學習和預訓練ImageNet模型的成功已經轉移到了NLP領域。許多企業家、科學家和工程師目前都用調整過的ImageNet模型解決重要的視覺問題,現在這款工具已經能用于語言處理,我們希望看到這一領域會有更多相關應用產生。
盡管我們已經展示了文本分類的最新進展,為了讓我們的NLP遷移學習發揮最大作用,還需要很多努力。在計算機視覺領域有許多重要的論文分析,深度分析了遷移學習在該領域的成果。Yosinski等人曾試著回答:“深度神經網絡中的特征是如何可遷移的”這一問題,而Huh等人研究了“為什么ImageNet適合遷移學習”。Yosinski甚至創造了豐富的視覺工具包,幫助參與者更好地理解他們計算機視覺模型中的特征。如果你在新的數據集上用ULMFiT解決了新問題,請在論壇里分享反饋!
-
深度學習
+關注
關注
73文章
5493瀏覽量
121000 -
自然語言
+關注
關注
1文章
287瀏覽量
13335 -
nlp
+關注
關注
1文章
487瀏覽量
22015
原文標題:用遷移學習創造的通用語言模型ULMFiT,達到了文本分類的最佳水平
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
準確度、精密度和精確度
pyhanlp文本分類與情感分析
基于文章標題信息的漢語自動文本分類
基于GA和信息熵的文本分類規則抽取方法
融合詞語類別特征和語義的短文本分類方法
如何使用Spark計算框架進行分布式文本分類方法的研究
文本分類的一個大型“真香現場”來了
基于深度神經網絡的文本分類分析






 工商網監
工商網監
評論