") 深度神經(jīng)網(wǎng)絡(luò)加速和壓縮方面所取得的進(jìn)展報告
深度神經(jīng)網(wǎng)絡(luò)加速和壓縮方面所取得的進(jìn)展報告
鄭板橋在《贈君謀父子》一詩中曾寫道,
“刪繁就簡三秋樹;領(lǐng)異標(biāo)新二月花。”
這句詩講的是,在畫作最易流于枝蔓的蘭竹時,要去掉其繁雜使之趨于簡明如“三秋之樹”;而針對不同的意境要有發(fā)散的引申,從而使每幅作品都如“二月之花”般新穎。
其實在人工智能領(lǐng)域,深度神經(jīng)網(wǎng)絡(luò)的設(shè)計,便如同繪制枝蔓繁復(fù)的蘭竹,需在底層對其刪繁就簡;而將其拓展至不同場景的應(yīng)用,則如同面向不同意境的引申,需要創(chuàng)新算法的支撐。
1946年,世界上第一臺通用計算機(jī)“恩尼亞克”誕生,經(jīng)過七十年余的發(fā)展,計算機(jī)從最初的龐然大物發(fā)展到今天的可作“掌上舞”,在體積逐步縮小的同時算力也有了很大提升。然而隨著深度學(xué)習(xí)的崛起,在計算設(shè)備上可集成算法的能力邊界也在不斷拓展,我們?nèi)匀幻媾R著巨大計算量和資源消耗的壓力。
深度神經(jīng)網(wǎng)絡(luò),作為目前人工智能的基石之一,其復(fù)雜性及可移植性將直接影響人工智能在生活中的應(yīng)用。因此,在學(xué)術(shù)界誕生了深度網(wǎng)絡(luò)加速與壓縮領(lǐng)域的研究。
今天,來自中國科學(xué)院自動化研究所的程健研究員,將向大家介紹過去一年中,深度神經(jīng)網(wǎng)絡(luò)加速和壓縮方面所取得的進(jìn)展。
首先我們來了解一下常用卷積神經(jīng)網(wǎng)絡(luò)的計算復(fù)雜度情況。
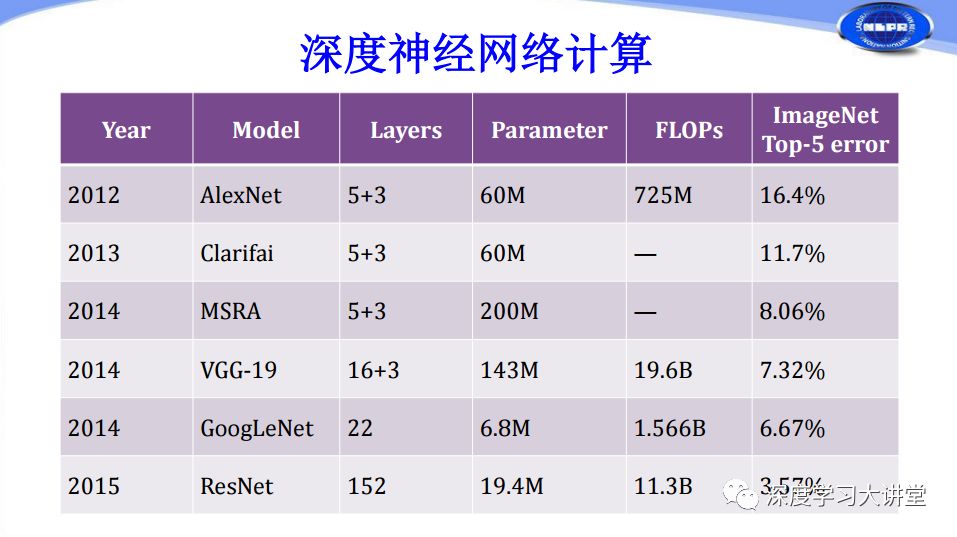
從上表可以看出近年來網(wǎng)絡(luò)層數(shù)越來越多,計算復(fù)雜度越來越高。而過高的計算復(fù)雜度通常要求我們使用GPU或者高性能的CPU對神經(jīng)網(wǎng)絡(luò)進(jìn)行運(yùn)算。實際上在深度學(xué)習(xí)應(yīng)用過程中,我們還面臨很多諸如移動設(shè)備、嵌入式設(shè)備這樣存在計算、體積、功耗等方面受限的設(shè)備,它們也需要應(yīng)用深度學(xué)習(xí)技術(shù)。由于這些設(shè)備存在的約束,導(dǎo)致現(xiàn)有的高性能深度神經(jīng)網(wǎng)絡(luò)無法在上面進(jìn)行有效的計算和應(yīng)用。

這種情況給我們提出了新的挑戰(zhàn):我們?nèi)绾卧诒3脂F(xiàn)有神經(jīng)網(wǎng)絡(luò)性能基本不變的情況下,通過將網(wǎng)絡(luò)的計算量大幅減小,以及對網(wǎng)絡(luò)模型存儲做大幅的削減,使得網(wǎng)絡(luò)模型能在資源受限的設(shè)備上高效運(yùn)行。這正是我們做深度神經(jīng)網(wǎng)絡(luò)加速、壓縮的基本動機(jī)。
從加速和壓縮本身來說,兩者不是同一件事,但通常情況下我們往往會同時做加速和壓縮,兩者都會給網(wǎng)絡(luò)的計算帶來收益,所以我們今天把它們放在一起來講。

網(wǎng)絡(luò)加速和壓縮技術(shù)根據(jù)采用的方法不同大概可以分為Low-Rank、Pruning、Quantization、Knowledge Distillation等。目前存在很多體積比較小,性能還不錯的緊致網(wǎng)絡(luò),在其架構(gòu)設(shè)計過程中也含有很多網(wǎng)絡(luò)加速壓縮的基本思想,所以我們今天也把Compact Network Design也作為網(wǎng)絡(luò)加速和壓縮方法的一種來介紹。
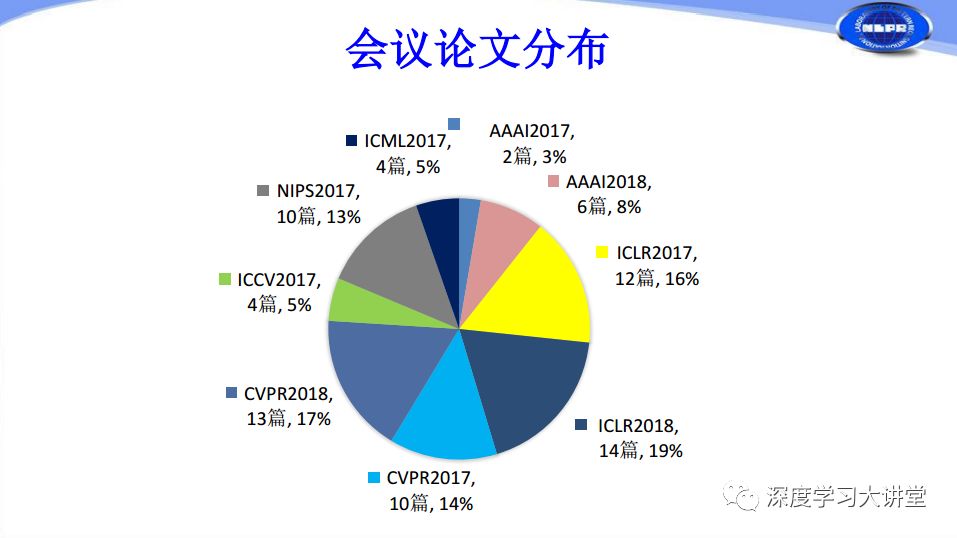
我們對過去一年和2018年目前發(fā)表在國際頂會上的有關(guān)網(wǎng)絡(luò)加速和壓縮的論文做了統(tǒng)計。由上圖可以看出在CVPR2017有10篇關(guān)于網(wǎng)絡(luò)加速和壓縮的文章,到CVPR2018年增加到13篇文章,ICLR2017有12篇,ICLR2018增加到14篇,這是兩個與深度學(xué)習(xí)應(yīng)用相關(guān)的主要會議。但奇怪的一點(diǎn)是我們看到也有很多文章在NIPS、ICML等相對傳統(tǒng)、比較注重理論的會議上發(fā)表,其中NIPS2017有10篇,ICMI2017有4篇。可以說在過去一年多的時間里,深度神經(jīng)網(wǎng)絡(luò)加速和壓縮不僅僅在應(yīng)用方面有所突破,還在理論方面有所進(jìn)展。
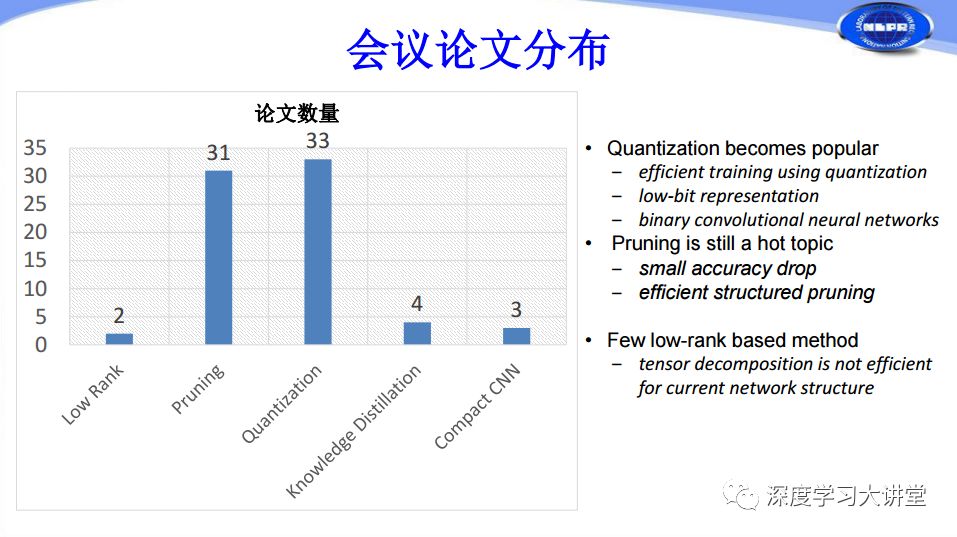
根據(jù)我們剛才對網(wǎng)絡(luò)加速和壓縮方法的分類來看,Low-Rank只有兩篇,Pruning、Quantization都有三十多篇,這兩個是研究的絕對熱點(diǎn)問題。Knowledge Distillation有4篇,Compact CNN Design有3篇。下面分別從這幾個方面進(jìn)行簡單介紹。

深度網(wǎng)絡(luò)加速和壓縮的第一種方法是Low-Rank低秩分解。由于卷積神經(jīng)網(wǎng)絡(luò)中的主要計算量在于卷積計算,而卷積計算本質(zhì)上是矩陣分析的問題,通過在大學(xué)對矩陣分析、高等數(shù)學(xué)的學(xué)習(xí)我們知道通過SVD奇異值分解等矩陣分析方法可以有效減少矩陣運(yùn)算的計算量。對于二維矩陣運(yùn)算來說SVD是非常好的簡化方法,所以在早期的時候,微軟研究院就做過相關(guān)的工作來對網(wǎng)絡(luò)實現(xiàn)加速。后面對于高維矩陣的運(yùn)算往往會涉及到Tensor分解方法來做加速和壓縮,主要是CP分解、Tucker分解、Tensor Train分解和Block Term分解這些在2015年和2016年所做的工作。

應(yīng)該說矩陣分解方法經(jīng)過過去的發(fā)展已經(jīng)非常成熟了,所以在2017、2018年的工作就只有Tensor Ring和Block Term分解在RNN的應(yīng)用兩篇相關(guān)文章了。那么為什么Low-Rank不再流行了呢?除了剛才提及的分解方法顯而易見、比較容易實現(xiàn)之外,另外一個比較重要的原因是現(xiàn)在越來越多網(wǎng)絡(luò)中采用1×1的卷積,而這種小的卷積使用矩陣分解的方法很難實現(xiàn)網(wǎng)絡(luò)加速和壓縮。

深度網(wǎng)絡(luò)加速和壓縮的第二種方法是Pruning,簡單來說就是把神經(jīng)網(wǎng)絡(luò)中的連接剪掉,剪掉以后整個網(wǎng)絡(luò)復(fù)雜度特別是網(wǎng)絡(luò)模型大小要減小很多。最早在ICLR2016上斯坦福大學(xué)提出了一種稱為Deep Compression的隨機(jī)剪枝方法。由于隨機(jī)剪枝方法對硬件非常不友好,往往在硬件實現(xiàn)的過程中不一定能夠很好地對網(wǎng)絡(luò)起到加速和壓縮的效果。后來大家就想到使用成塊出現(xiàn)的結(jié)構(gòu)化Pruning,F(xiàn)ilter Pruning,梯度Pruning等方法。
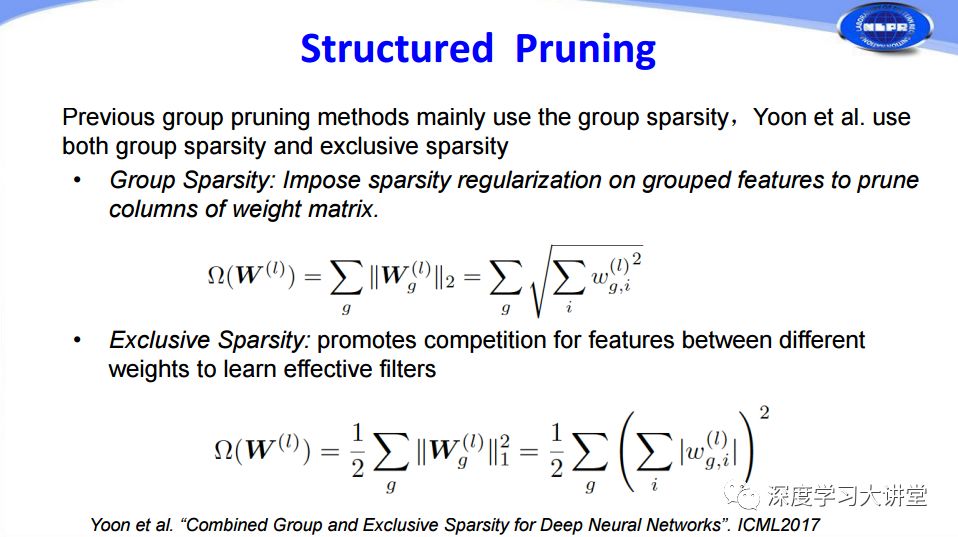
對于結(jié)構(gòu)化Pruning,在ICML2017中有一篇對于權(quán)重進(jìn)行分析剪枝的文章。具體方法是:首先使用Group Sparsity組稀疏的方法對分組特征添加稀疏正則來修剪掉權(quán)重矩陣的一些列,然后通過Exclusive Sparsity增強(qiáng)不同權(quán)重之間特征的競爭力來學(xué)習(xí)更有效的filters,兩者共同作用取得了很好的Pruning結(jié)果。
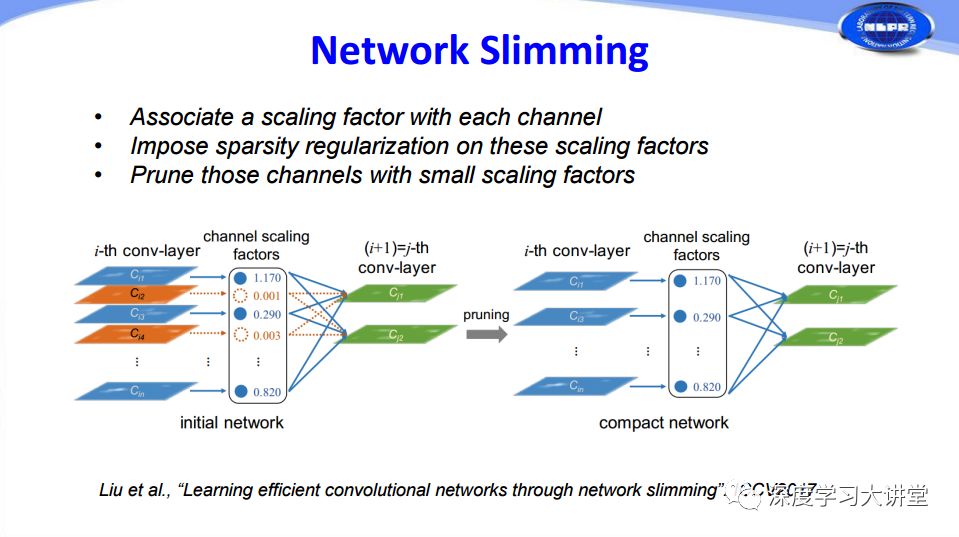
從另一方面考慮,我們能否對feature map和activation也做一些pruning的工作呢?在ICCV2017的工作中有人通過給每個通道channel添加一個尺度因子scaling factor,然后對這些尺度因子scaling factor添加sparsity regularization,最后根據(jù)尺度因子大小對相應(yīng)的通道channels進(jìn)行修剪,將一些尺度因子比較小的通道剪掉,實現(xiàn)對整個網(wǎng)絡(luò)的瘦身效果。
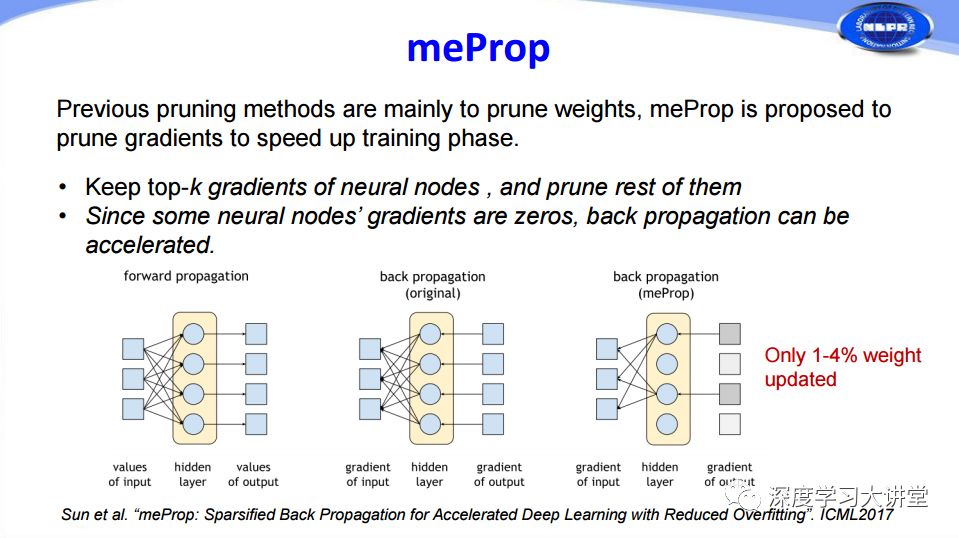
剛才所講的都是在網(wǎng)絡(luò)前向傳播過程中所做的Pruning,那么我們能否在網(wǎng)絡(luò)訓(xùn)練的過程中也加入Pruning來加快網(wǎng)絡(luò)訓(xùn)練的過程呢?ICML2017有一篇文章對網(wǎng)絡(luò)訓(xùn)練過程中的梯度信息做了分析,通過去掉幅值比較小的梯度來簡化網(wǎng)絡(luò)的反向傳播過程,從而加快網(wǎng)絡(luò)的訓(xùn)練過程。從結(jié)果來看,這種方法可以通過僅僅更新1%-4%的權(quán)重來實現(xiàn)和原有網(wǎng)絡(luò)相當(dāng)?shù)男Ч?/p>

除了Pruning,還有一種研究較多的方法是Quantization量化。量化可以分為Low-Bit Quantization(低比特量化)、Quantization for General Training Acceleration(總體訓(xùn)練加速量化)和Gradient Quantization for Distributed Training(分布式訓(xùn)練梯度量化)。

由于在量化、特別是低比特量化實現(xiàn)過程中,由于量化函數(shù)的不連續(xù)性,在計算梯度的時候會產(chǎn)生一定的困難。對此,阿里巴巴冷聰?shù)热税训捅忍亓炕D(zhuǎn)化成ADMM可優(yōu)化的目標(biāo)函數(shù),從而由ADMM來優(yōu)化。

我們實驗室從另一個角度思考這個問題,使用哈希把二值權(quán)重量化,再通過哈希求解。
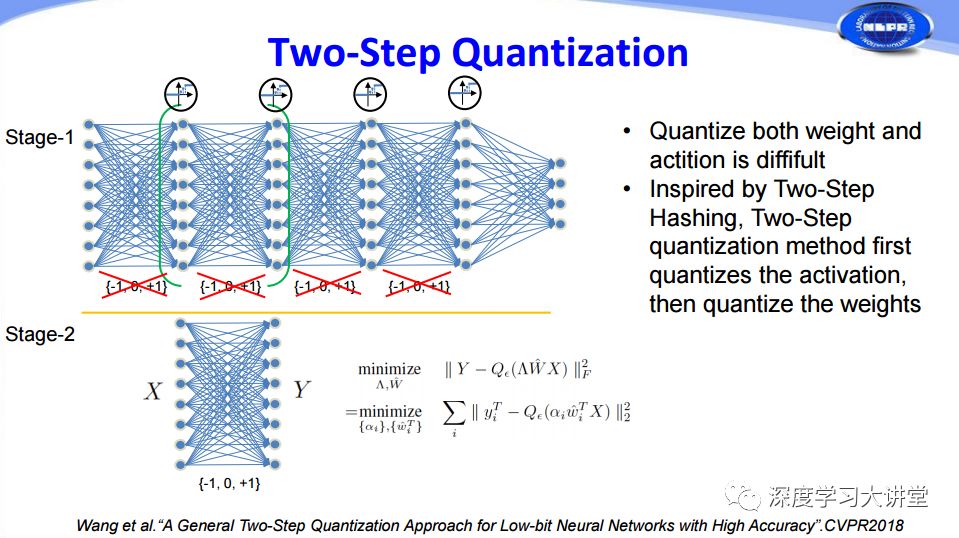
前面兩篇文章都是對權(quán)重進(jìn)行量化,那么feature map能否也可以進(jìn)行量化呢?以前有人考慮過這個問題,將權(quán)重和feature map一起進(jìn)行量化,但在實際過程中非常難以收斂。我們實驗室在CVPR2018上提出一個方法,受到兩步哈希法的啟發(fā),將量化分為兩步,第一步先對feature map進(jìn)行量化,第二步再對權(quán)重量化,從而能夠?qū)蓚€同時進(jìn)行很好的量化。
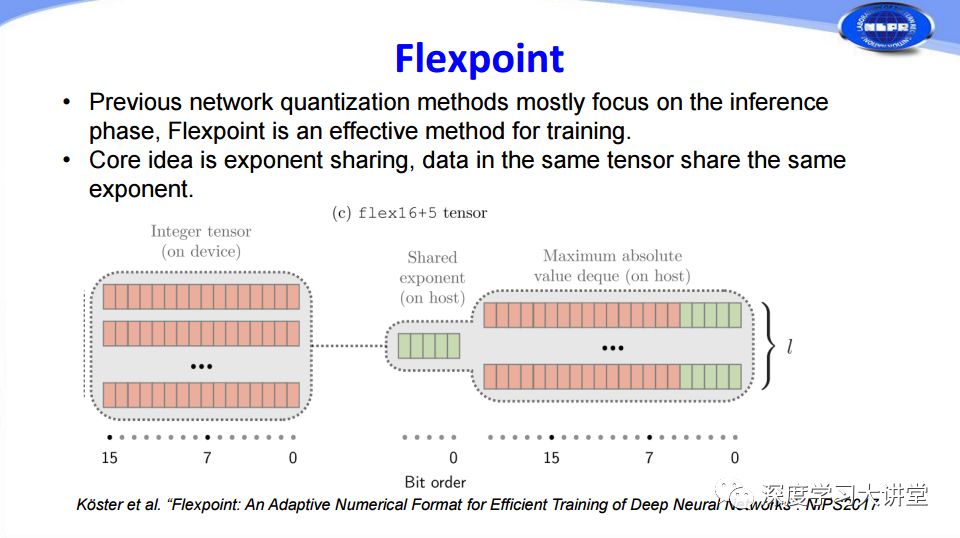
剛才的量化都是在網(wǎng)絡(luò)inference過程中,其實量化也可以在訓(xùn)練過程中使用,這是英特爾在NIPS2017提出的Flexpoint方法。我們知道在32位浮點(diǎn)和16位浮點(diǎn)存儲的時候,第一位是符號位,中間是指數(shù)位,后面是尾數(shù)。他們對此提出了把前面的指數(shù)項共享的方法,這樣可以把浮點(diǎn)運(yùn)算轉(zhuǎn)化為尾數(shù)的整數(shù)定點(diǎn)運(yùn)算,從而加速網(wǎng)絡(luò)訓(xùn)練。

在很多深度學(xué)習(xí)訓(xùn)練過程中,為了讓訓(xùn)練更快往往會用到分布式計算。在分布式計算過程中有一個很大問題,每一個分布式服務(wù)器都和中心服務(wù)器節(jié)點(diǎn)有大量的梯度信息傳輸過程,從而造成帶寬限制。這篇文章采取把要傳輸?shù)奶荻刃畔⒘炕癁槿档姆椒▉碛行Ъ铀俜植际接嬎恪?/p>

第四種方法是Knowledge Distillation。這方面早期有兩個工作,Knowledge Distillation最早由Hinton在2015年提出,隨后Romero提出了FitNets。在Knowledge Distillation中有兩個關(guān)鍵的問題,一是如何定義知識,二是使用什么損失函數(shù)來度量student網(wǎng)絡(luò)和teacher 網(wǎng)絡(luò)之間的相似度。

這里主要介紹2017年的兩個相關(guān)工作。一是FSP方法,它實際上將原始網(wǎng)絡(luò)中feature map之間的相關(guān)度作為知識transfer到student network中,同時使用了L2損失函數(shù)。
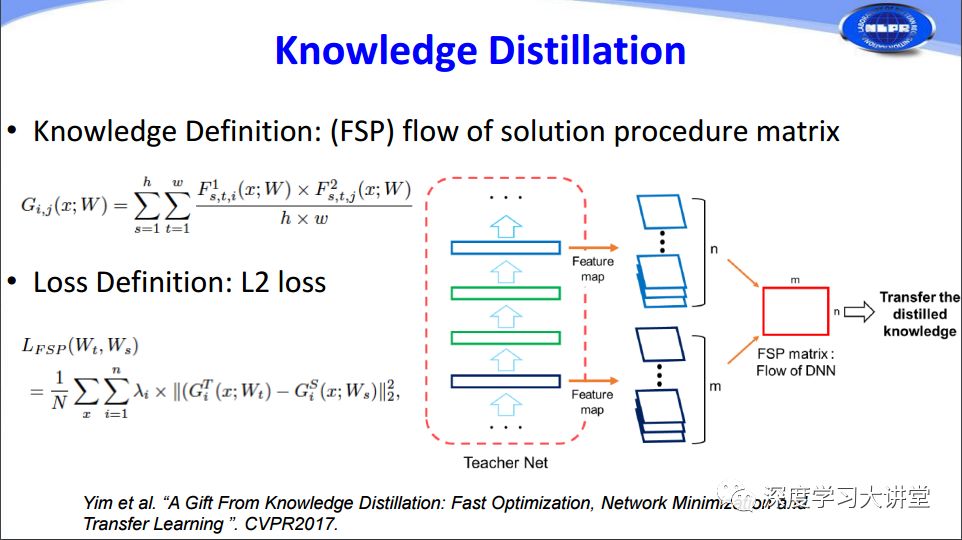
另一個ICLR2017的工作在feature map中定義了attention,使用了三種不同的定義方法,將attention作為知識transfer到student network中。
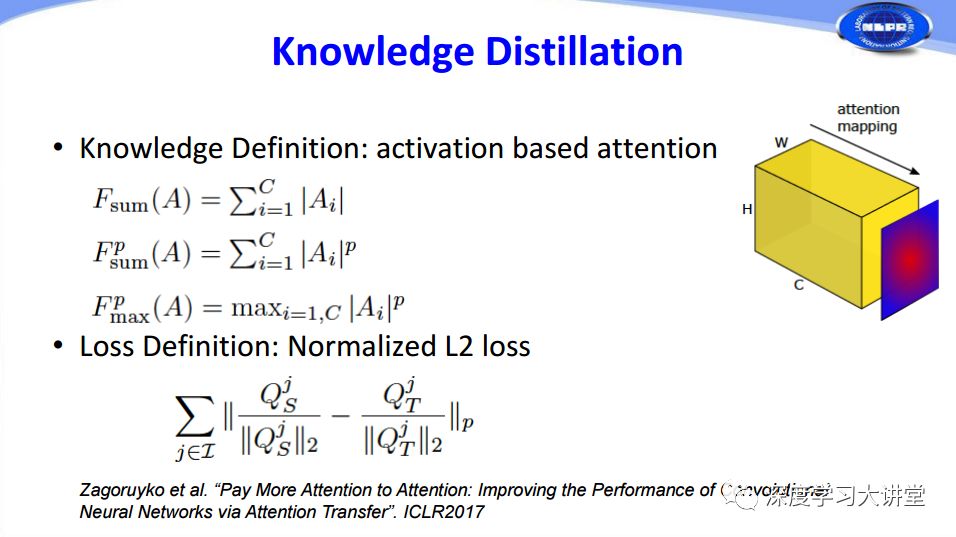
下面是幾種主流方法在知識定義和損失函數(shù)選擇方面的對比。
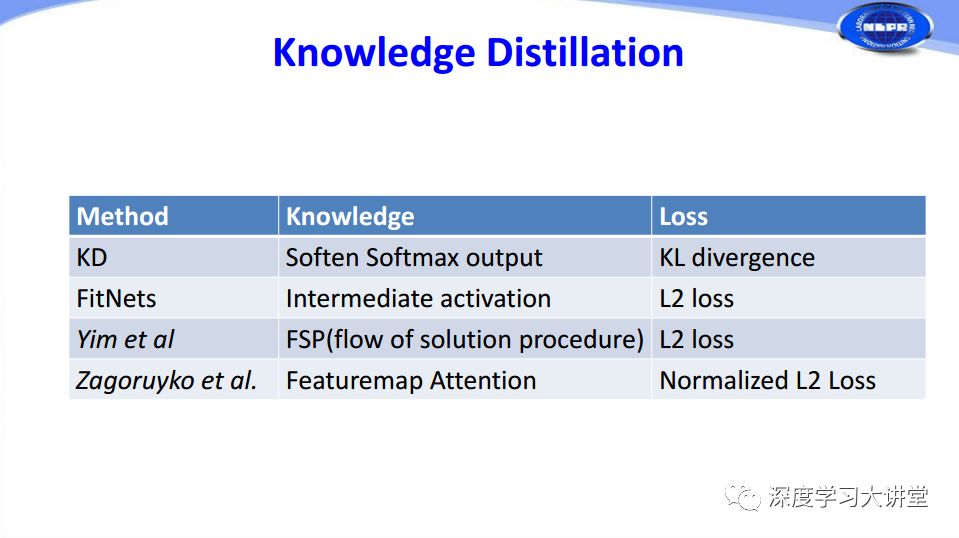
最后簡單講一下緊致網(wǎng)絡(luò)設(shè)計。我們剛才講到的幾種網(wǎng)絡(luò)加速和壓縮方法都是在原有非常復(fù)雜的網(wǎng)絡(luò)基礎(chǔ)上,對它進(jìn)行量化、剪枝,讓網(wǎng)絡(luò)規(guī)模變小、計算變快。我們可以考慮直接設(shè)計又小又快又好的網(wǎng)絡(luò),這就是緊致網(wǎng)絡(luò)設(shè)計的方法。我們主要講三個相關(guān)的工作。

先介紹谷歌在2017年和2018年連續(xù)推出的MobileNets V1和MobileNets V2,其中使用了depthwise的1x1卷積。MobileNets V1是一個在網(wǎng)絡(luò)非常精簡情況下比較高性能的網(wǎng)絡(luò),MobileNets V2開始于通道比較少的1×1的網(wǎng)絡(luò),然后映射到通道比較多的層,隨后做一個depthwise,最后再通過1x1卷積將它映射回去,這樣可以大幅減少1×1卷積計算量。
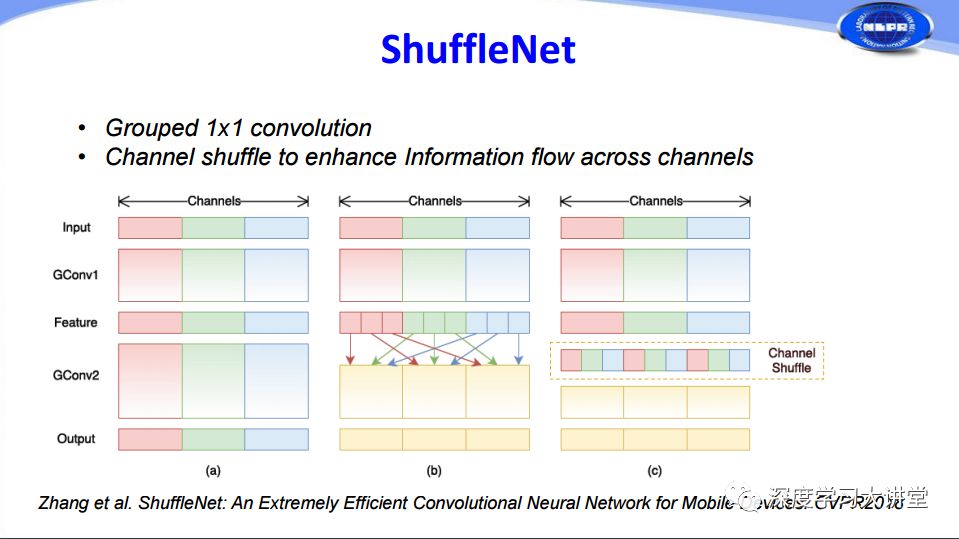
實際上MobileNets中1x1的卷積占有很大的比重,基于這樣的原則,曠視科技在CVPR2018提出把1×1的卷積通過分組來減少計算的方法,由于分組以后存在不同通道之間信息交流非常少的問題,他們又在卷積層之間增加channel shuffle過程進(jìn)行隨機(jī)擾亂,增加了不同通道之間的信息交流。這是ShuffleNet所做的工作。
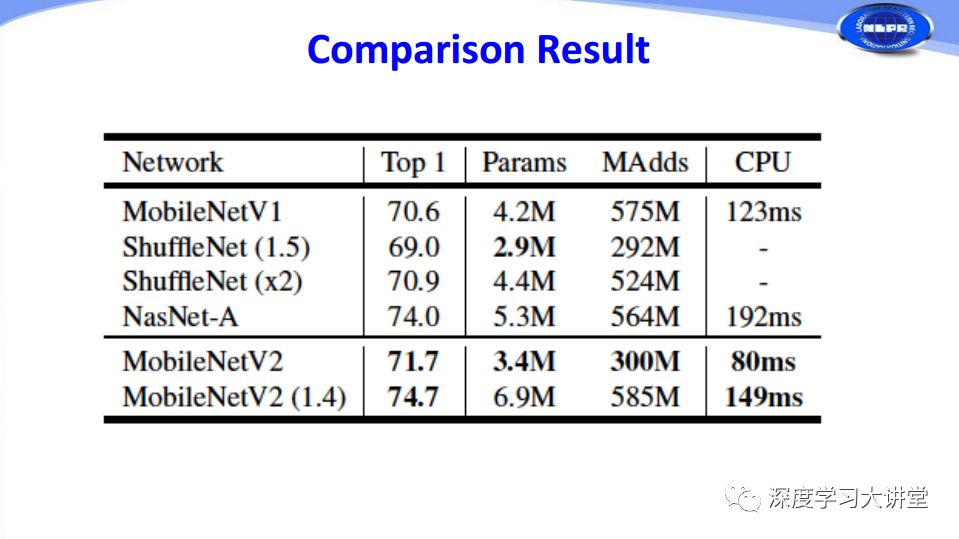
下面是緊致網(wǎng)絡(luò)設(shè)計幾種方法的比較。
最后簡單講一下深度神經(jīng)網(wǎng)絡(luò)加速和壓縮的發(fā)展趨勢。第一,我們發(fā)現(xiàn)實際上現(xiàn)在絕大部分加速和壓縮的方法,都需要有一個fine-tuning的過程,這個過程需要有一定量的含有標(biāo)簽的原始訓(xùn)練樣本,這在實際應(yīng)用過程中可能會有一定的限制。會有一些Non-fine-tuning或者Unsupervised Compression方法的出現(xiàn)。實際上現(xiàn)在已經(jīng)有人在研究這方面的東西。第二,在加速和壓縮過程中會涉及到很多參數(shù),甚至還包含很多經(jīng)驗性東西,將來能不能做到盡可能少需要、不需要經(jīng)驗或者參數(shù)越少越好的self-adaptive方法。第三,現(xiàn)在很多加速壓縮方法往往都是針對分類問題,未來在目標(biāo)檢測、語義分割方面也會出現(xiàn)類似的工作。第四,現(xiàn)在很多方法與硬件的結(jié)合越來越緊密,對于加速和壓縮方面來說也是如此,未來肯定是之間的結(jié)合越來越多。最后是二值網(wǎng)絡(luò)越來越成熟,未來研究的人會越來越多。由于時間的關(guān)系只能簡單介紹,可以參考我們最近剛發(fā)表在FITEE 2018上的綜述論文了解更多詳細(xì)的信息。

-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4764瀏覽量
100541 -
人工智能
+關(guān)注
關(guān)注
1791文章
46867瀏覽量
237592
原文標(biāo)題:讓機(jī)器“刪繁就簡”:深度神經(jīng)網(wǎng)絡(luò)加速與壓縮|VALSE2018之六
文章出處:【微信號:deeplearningclass,微信公眾號:深度學(xué)習(xí)大講堂】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于賽靈思FPGA的卷積神經(jīng)網(wǎng)絡(luò)實現(xiàn)設(shè)計
如何設(shè)計BP神經(jīng)網(wǎng)絡(luò)圖像壓縮算法?
深度神經(jīng)網(wǎng)絡(luò)是什么
基于深度神經(jīng)網(wǎng)絡(luò)的激光雷達(dá)物體識別系統(tǒng)
深度神經(jīng)網(wǎng)絡(luò)的壓縮和正則化剖析

NVIDIA深度神經(jīng)網(wǎng)絡(luò)加速庫cuDNN軟件安裝教程
不同神經(jīng)網(wǎng)絡(luò)量子態(tài)的最新進(jìn)展以及面臨的挑戰(zhàn)
基于深度神經(jīng)網(wǎng)絡(luò)的端到端圖像壓縮方法

深度神經(jīng)網(wǎng)絡(luò)模型的壓縮和優(yōu)化綜述

卷積神經(jīng)網(wǎng)絡(luò)和深度神經(jīng)網(wǎng)絡(luò)的優(yōu)缺點(diǎn) 卷積神經(jīng)網(wǎng)絡(luò)和深度神經(jīng)網(wǎng)絡(luò)的區(qū)別
淺析深度神經(jīng)網(wǎng)絡(luò)壓縮與加速技術(shù)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論