 機器學習中五種常用的聚類算法
機器學習中五種常用的聚類算法
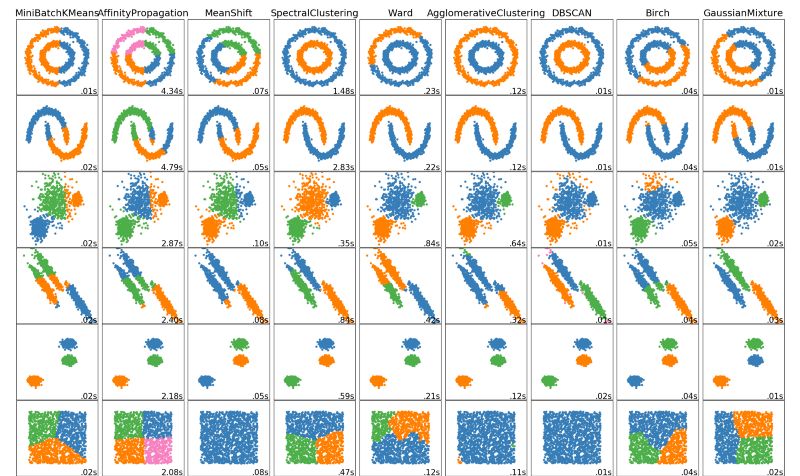
聚類是機器學習中一種重要的無監督算法,它可以將數據點歸結為一系列特定的組合。理論上歸為一類的數據點具有相同的特性,而不同類別的數據點則具有各不相同的屬性。在數據科學中聚類會從數據中發掘出很多分析和理解的視角,讓我們更深入的把握數據資源的價值、并據此指導生產生活。以下是五種常用的聚類算法。
K均值聚類
這一最著名的聚類算法主要基于數據點之間的均值和與聚類中心的聚類迭代而成。它主要的優點是十分的高效,由于只需要計算數據點與劇類中心的距離,其計算復雜度只有O(n)。其工作原理主要分為以下四步:
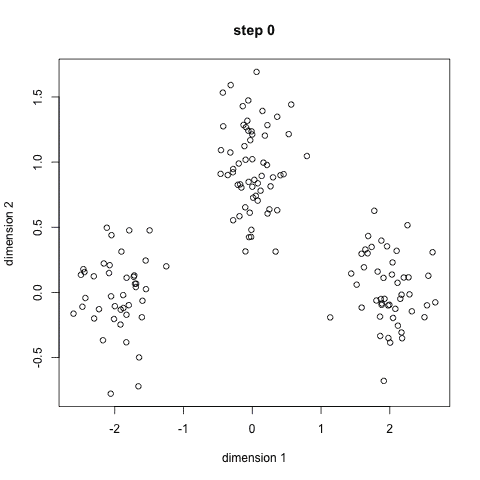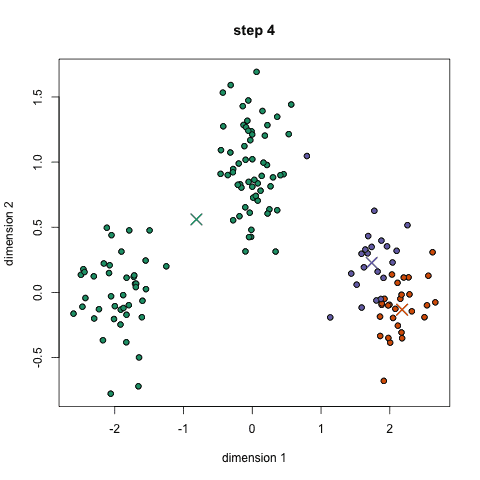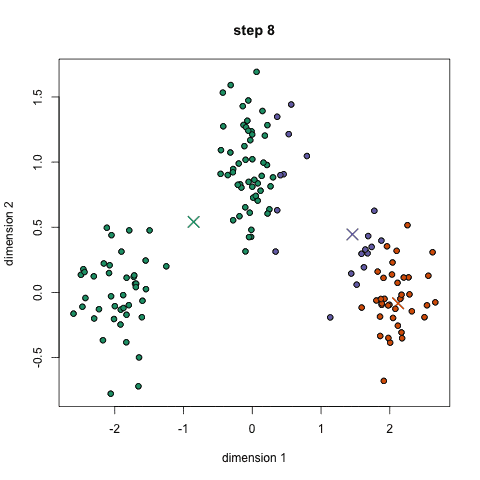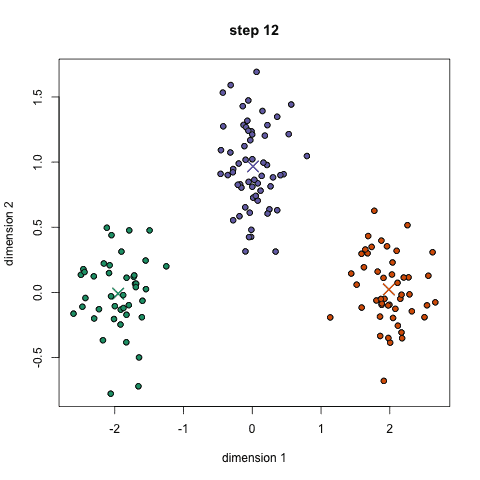
1.首先我們需要預先給定聚類的數目同時隨機初始化聚類中心。我們可以初略的觀察數據并給出較為準確的聚類數目;
2.每一個數據點通過計算與聚類中心的距離了來分類到最鄰近的一類中;
3.根據分類結果,利用分類后的數據點重新計算聚類中心;
4.重復步驟二三直到聚類中心不再變化。(可以隨機初始化不同的聚類中心以選取最好的結果)
這種方法在理解和實現上都十分簡單,但缺點卻也十分明顯,十分依賴于初始給定的聚類數目;同時隨機初始化可能會生成不同的聚類效果,所以它缺乏重復性和連續性。
和K均值類似的K中值算法,在計算過程中利用中值來計算聚類中心,使得局外點對它的影響大大減弱;但每一次循環計算中值矢量帶來了計算速度的大大下降。
均值漂移算法
這是一種基于滑動窗口的均值算法,用于尋找數據點中密度最大的區域。其目標是找出每一個類的中心點,并通過計算滑窗內點的均值更新滑窗的中心點。最終消除臨近重復值的影響并形成中心點,找到其對應的類別。
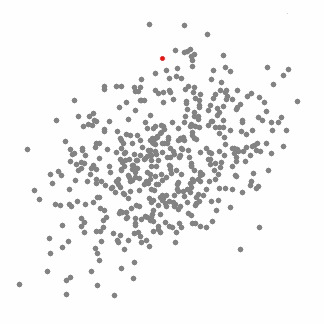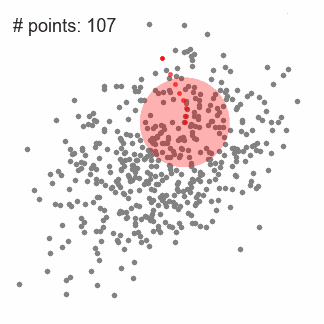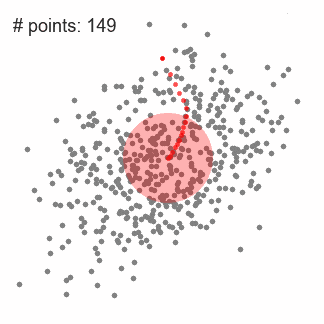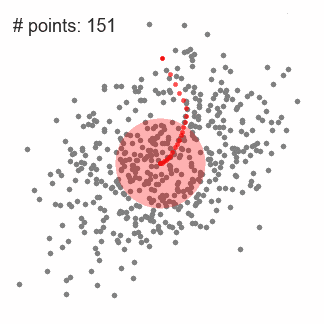
1.首先以隨機選取的點為圓心r為半徑做一個圓形的滑窗。其目標是找出數據點中密度最高點并作為中心;
2.在每個迭代后滑動窗口的中心將為想著較高密度的方向移動;
3.連續移動,直到任何方向的移動都不能增加滑窗中點的數量,此時滑窗收斂;
4.將上述步驟在多個滑窗上進行以覆蓋所有的點。當過個滑窗收斂重疊時,其經過的點將會通過其滑窗聚類為一個類;
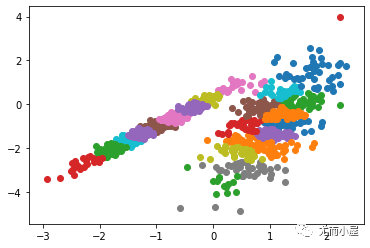
下圖中每一個黑點都代表一個滑窗的中心,他們最終重疊在每一類的中心;

與K均值相比最大的優點是我們無需指定指定聚類數目,聚類中心處于最高密度處也是符合直覺認知的結果。但其最大的缺點在于滑窗大小r的選取,對于結果有著很大的影響。
基于密度的聚類算法(DBSCAN)
DBSCAN同樣是基于密度的聚類算法,但其原理卻與均值漂移大不相同:
1.首先從沒有被遍歷的任一點開始,利用鄰域距離epsilon來獲取周圍點;
2.如果鄰域內點的數量滿足閾值則此點成為核心點并以此開始新一類的聚類。(如果不是則標記為噪聲);
3.其鄰域內的所有點也屬于同一類,將所有的鄰域內點以epsilon為半徑進行步驟二的計算;
4.重復步驟二、三直到變量完所有核心點的鄰域點;
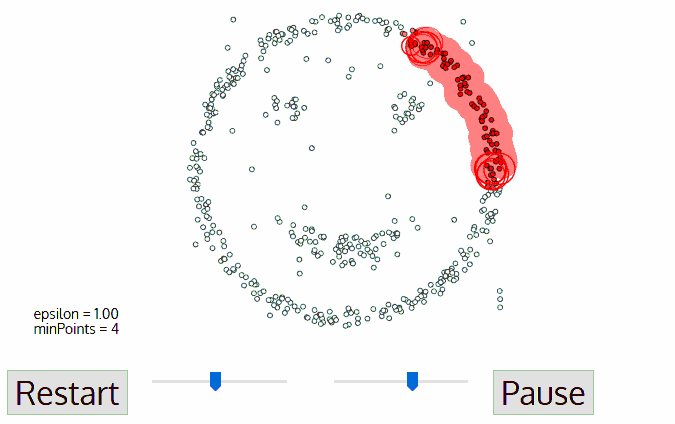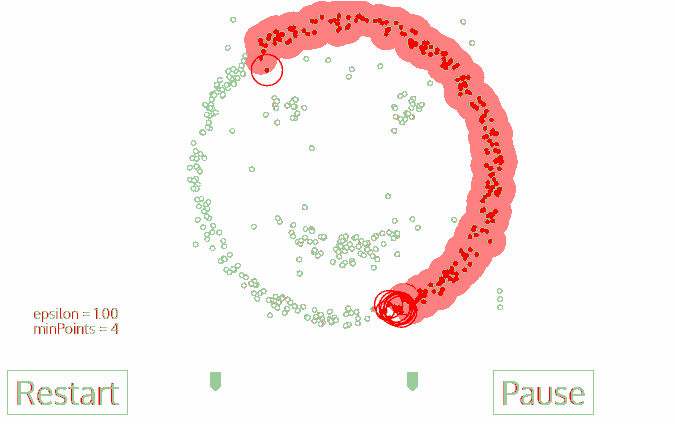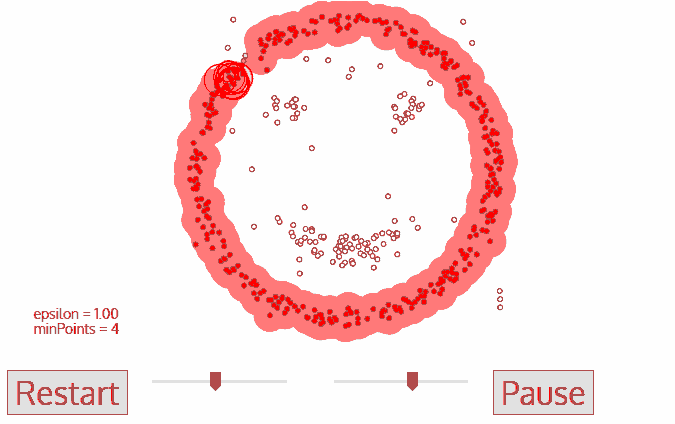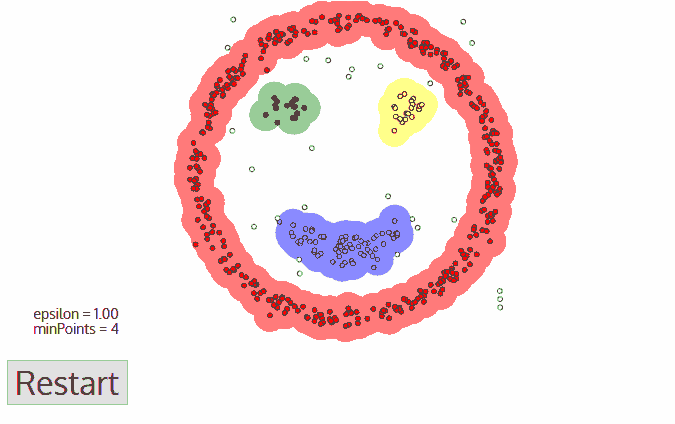
5.此類聚類完成,同時又以任意未遍歷點開始步驟一到四直到所有數據點都被處理;最終每個數據點都有自己的歸屬類別或者屬于噪聲。
這種方法最大的優點在于無需定義類的數量,其次可以識別出局外點和噪聲點、并且可以對任意形狀的數據進行聚類。
但也存在不可回避的缺點,當數據密度變化劇烈時,不同類別的密度閾值點和領域半徑會產生很大的變化。同時在高維空間中準確估計領域半徑也是不小的挑戰。
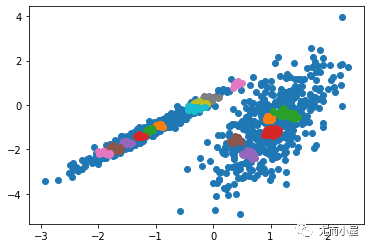
利用高斯混合模型進行最大期望估計
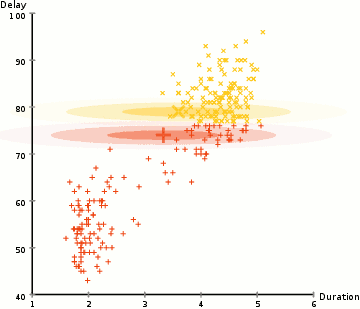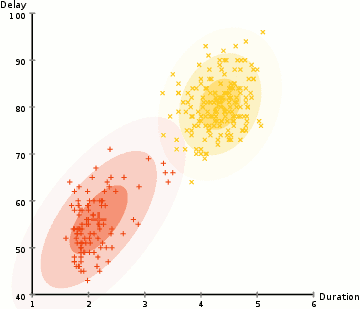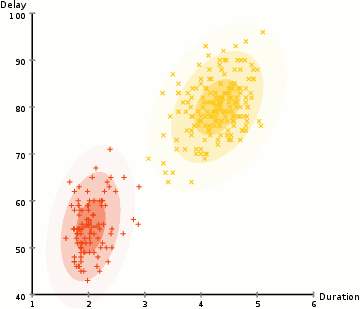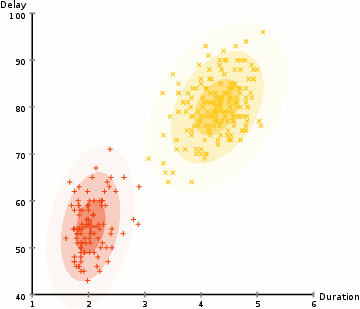
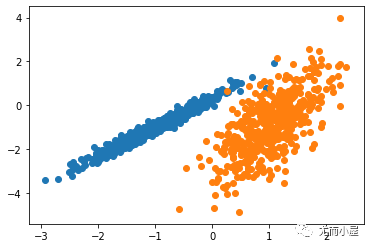
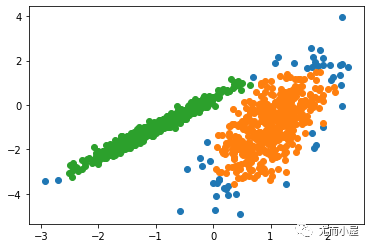
對于較為復雜的分布K均值將會產生如下圖般較為離譜的聚類結果。

而高斯混合模型卻具有更高的靈活性。通過假設數據點符合均值和標準差描述的高斯混合模型來實現的。下圖以二維情況下為例描述了如何利用最大期望優化算法來獲取分布參數的過程:
1.首先確定聚類的數量,并隨機初始化每一個聚類的高斯分布參數;
2.通過計算每一個點屬于高斯分布的概率來進行聚類。與高斯中心越近的點越有可能屬于這個類;
3.基于上一步數據點的概率權重,通過最大似然估計的方法計算出每一類數據點最有可能屬于這一聚類的高斯參數;
4.基于新的高斯參數,重新估計每一點歸屬各類的概率,重復并充分2,3步驟直到參數不再變化收斂為止。
在使用高斯混合模型時有兩個關鍵的地方,首先高斯混合模型十分靈活,可以擬合任意形狀的橢圓;其次這是一種基于概率的算法,每個點可以擁有屬于多類的概率,支持混合屬性。
凝聚層次聚類
層次聚類法主要有自頂向下和自底向上兩種方式。其中自底向上的方式,最初將每個點看做是獨立的類別,隨后通過一步步的凝聚最后形成獨立的一大類,并包含所有的數據點。這會形成一個樹形結構,并在這一過程中形成聚類。
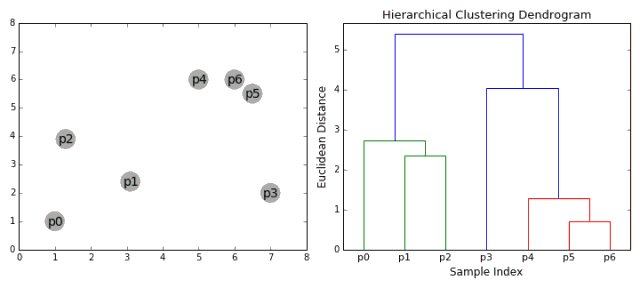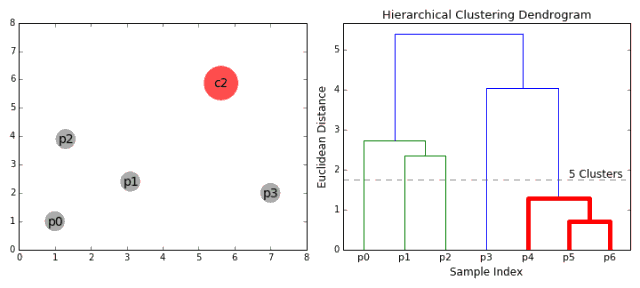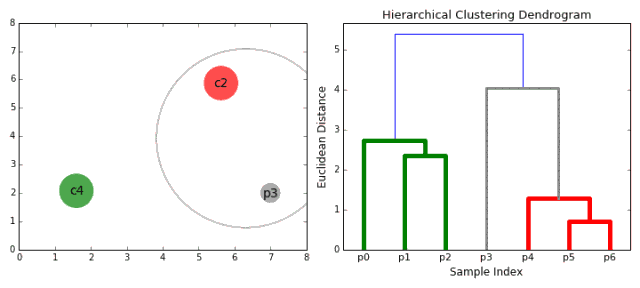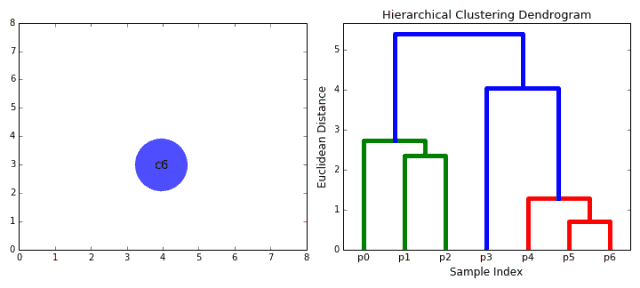
1.首先將每一個數據點看成一個類別,通過計算點與點之間的距離將距離近的點歸為一個子類,作為下一次聚類的基礎;
2.每一次迭代將兩個元素聚類成一個,上述的子類中距離最近的兩兩又合并為新的子類。最相近的都被合并在一起;
3.重復步驟二直到所有的類別都合并為一個根節點。基于此我們可以選擇我們需要聚類的數目,并根據樹來進行選擇。
層次聚類無需事先指定類的數目,并且對于距離的度量不敏感。這種方法最好的應用在于恢復出數據的層次化結構。但其計算復雜度較高達到了O(n^3).
每個聚類算法都有各自的優缺點,我們需要根據計算需求和應用需求選擇合適的算法來進行處理。隨著深度學習的出現,更多的神經網絡、自編碼器被用來提取數據中的高維特征用于分類,是值得注意的研究熱點。
最后如果想練練手的話,scikit Learn上有很多例子可以操練,實踐才是最好的老師~~http://scikit-learn.org/stable/modules/clustering.html#clustering
-
聚類算法
+關注
關注
2文章
118瀏覽量
12101 -
機器學習
+關注
關注
66文章
8306瀏覽量
131838
原文標題:機器學習中的五種聚類算法了解一下~
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于近鄰傳播的遷移聚類算法
Python無監督學習的幾種聚類算法包括K-Means聚類,分層聚類等詳細概述

金融機構使用案例分析機器學習算法——聚類clustering





 工商網監
工商網監
評論