 如何使用語義分割概率圖作為語義先驗來約束超分辨率的解空間
如何使用語義分割概率圖作為語義先驗來約束超分辨率的解空間
商湯科技在CVPR 2018發表論文44篇,錄取論文在以下領域實現突破:大規模分布式訓練、人體理解與行人再識別、自動駕駛場景理解與分析、底層視覺算法、視覺與自然語言的綜合理解、物體檢測、識別與跟蹤、深度生成式模型、視頻與行為理解等。
以下是在底層視覺算法領域,商湯科技提出的面向生成更自然真實紋理圖像的超分辨率算法。本文為商湯科技CVPR 2018論文解讀第3期。
簡介
單幀圖像超分辨率旨在基于單張低分辨率圖像恢復對應的高分辨率圖像。卷積神經網絡近年在圖像超分辨率任務中表現出了優異的重建效果,但是恢復出自然而真實的紋理依然是超分辨率任務中的一大挑戰。
如何恢復出自然而真實的紋理呢?一個有效的方式是考慮語義類別先驗,即使用圖像中不同區域所屬的語義類別作為圖像超分辨率的先驗條件,比如天空、草地、水、建筑、森林、山、植物等。不同類別下的紋理擁有各自獨特的特性,換句話說,語義類別能夠更好的約束超分辨中同一低分辨率圖存在多個可能解的情況。如圖1中展示的建筑和植物的例子,它們的低分辨率圖像塊非常類似。雖然結合生成對抗式網絡(GAN)進行超分復原,若未考慮圖像區域的類別先驗信息,獲得的結果雖然增加了紋理細節,但是并不符合圖像區域本身應該具有的紋理特點。

圖1:
不同的語義先驗對
建筑和植物區域圖像超分辨率的影響
在結合語義類別先驗的過程中會遇到兩個問題。第一個問題是,如何表達語義類別先驗,特別是當一個圖像中存在多種語義類別時。本文選擇了語義分割概率圖作為先驗條件,其能提供像素級的圖像區域信息,每個像素點的概率向量能夠更精細地調控紋理結果。第二個問題是,如何有效地將語義先驗結合到網絡中去。本文提出了一種新的空間特征調制層(SFT),它能將額外的圖像先驗(比如語義分割概率圖)有效地結合到網絡中去,恢復出與所屬語義類別特征一致的紋理。
最終結果顯示(如圖2所示)和現有的SRGAN模型以及EnhanceNet模型相比,使用空間特征調制層的超分辨率網絡能夠生成更加自然的紋理,恢復出的高分辨率圖像視覺效果更為真實。

圖2:
在4倍超分辨率下,
SRCNN、SRGAN、EnhanceNet
和本文提出SFT-GAN算法最終結果的比較
空間特征調制
本文提出的空間特征調制層受到條件BN層的啟發,但是條件BN層以及其他的特征調制層(比如FiLM),往往忽略了網絡提取特征的空間信息,即對于同一個特征圖的不同位置,調制的參數保持一致。但是超分辨率等底層視覺任務往往需要考慮更多的圖像空間信息,并在不同的位置進行不同的處理。基于這個觀點,本文提出了空間特征調制層,其結構如圖3所示。
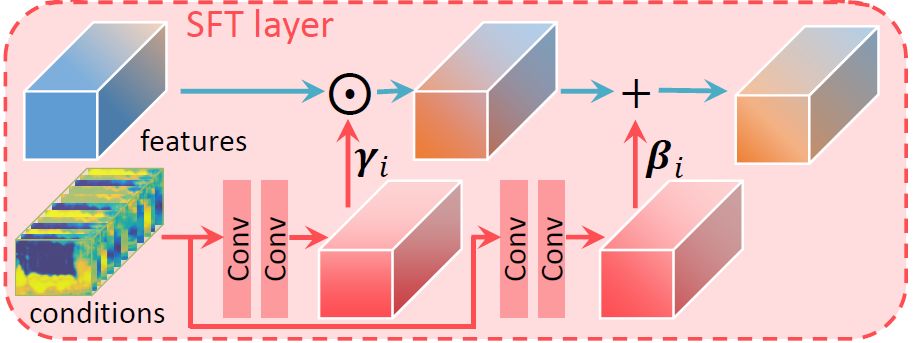
圖3:
空間特征調制層的結構
空間特征調制層對網絡的中間特征進行仿射變換,變換的參數由額外的先驗條件(如本文中考慮的語義分割概率圖)經過若干層神經網絡變換得到。若以F表示網絡的特征,γ和β分別表示得到的仿射變換的尺度和平移參數,那么經過空間特征調制層得到的輸出特征為:
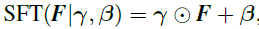
空間特征調制層可以方便地被集成至現有的超分辨率網絡,如SRResNet等。圖4是本文中使用的網絡結構。為了提升算法效率,先將語義分割概率圖經過一個Condition Network得到共享的中間條件,然后把這些條件“廣播”至所有的SFT層。本文算法模型在網絡的訓練中,同時使用了perceptual loss和adversarial loss,被簡稱為SFT-GAN。
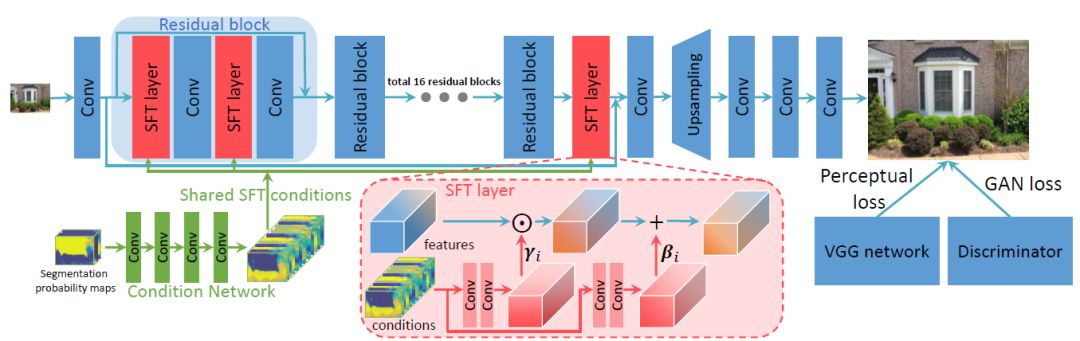
圖4:
網絡框架示意圖
實驗結果
語義分割結果
如圖5所示,當前基于深度學習的語義分割網絡在低分辨率數據集上進行fine-tune后,對于大多數場景能夠生成較為滿意的分割效果。
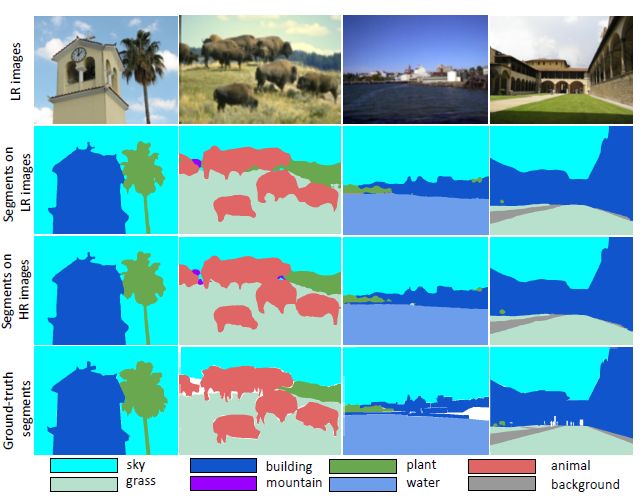
圖5:
語義分割結果
SFT-GAN和其他模型的結果比較
圖6展示了SFT-GAN模型和其他模型結果的比較,可以看到基于GAN的算法模型SRGAN、EnhanceNet以及本文的SFT-GAN在視覺效果上超過了以優化PSNR為目標的模型。SFT-GAN在紋理的恢復上能夠生成比SRGAN和EnhanceNet更自然真實的結果(圖中的動物毛發、建筑物的磚塊、以及水的波紋)。

圖6:
本文SFT-GAN模型
和現有超分辨率模型的結果對比
在進行的人類用戶評價中,SFT-GAN模型在各個語義類別上也比之前的基于GAN的方法有著顯著的提升(如圖7所示)。
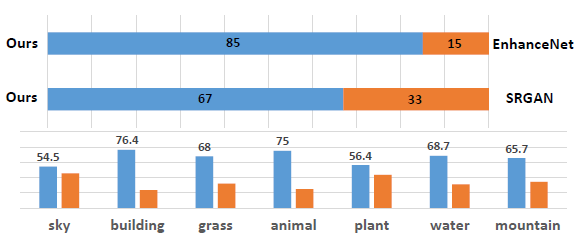
圖7:
人類用戶評價不同算法效果
其他實驗探究
本文還可視化了語義分割概率圖和特征調制層參數的關系。圖8中展示了建筑和草地類別的概率圖以及網絡中某一層的調制參數的聯系。可以看到,調制參數和語義分割概率圖有著緊密的聯系,同時在調制參數中不同類別的界限依舊比較清晰。
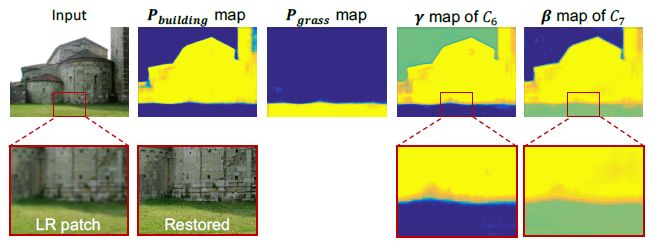
圖8:
語義分割概率圖和特征調制層參數的聯系
實際場景中,物體類別的分隔界限通常并不十分明顯,比如圖9中的植物和草的區域,它們之間的過渡是“無縫”且連續的,而本文中使用的語義分割概率圖以及調制層的參數也是連續變化的。因此,SFT-GAN可以更為精細地調制紋理的生成。

圖9:
SFT層能夠更為精細地調制參數
本文還比較了其他結合先驗條件的方式:
將圖像和得到的語義分割概率圖級聯起來共同輸入;
通過不同的分支處理不同的場景類別,然后利用語義分割概率圖融合起來;
不考慮空間關系的特征調制方法FiLM。
從圖10中可以看到:
方法1)的結果沒有SFT層有效(SFT-GAN模型中有多個SFT層能將先驗條件更為緊密地結合);
方法2)的效率不夠高(SFT-GAN只需要進行一次前向運算);
方法3)由于沒有空間位置的關系,導致不同類別之間的紋理相互干擾。
圖10:
不同先驗條件結合方式的結果比較
結論
本文深入探討了如何使用語義分割概率圖作為語義先驗來約束超分辨率的解空間,使生成的圖像紋理更符合真實而自然的紋理特性。還提出了一種新穎的空間特征調制層(SFT)來有效地將先驗條件結合到現有網絡中。空間特征調制層可以和現有的超分辨率網絡使用同樣的損失函數,端到端地進行訓練。測試時,整個網絡可以接受任意大小尺寸的圖像作為輸入,只需要一次前向傳播,就能夠輸出結合語義類別先驗的高分辨率圖像。實驗結果顯示,相較于現有超分辨率算法,本文SFT-GAN模型生成的圖像具有更加真實自然的紋理。
-
圖像
+關注
關注
2文章
1083瀏覽量
40418 -
分辨率
+關注
關注
2文章
1051瀏覽量
41888
原文標題:CVPR 2018 | 商湯科技論文詳解:基于空間特征調制的圖像超分辨率
文章出處:【微信號:SenseTime2017,微信公眾號:商湯科技SenseTime】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
van-自然和醫學圖像的深度語義分割:網絡結構
van-自然和醫學圖像的深度語義分割:網絡結構
李飛飛等人提出Auto-DeepLab:自動搜索圖像語義分割架構
語義分割算法系統介紹
RGPNET:復雜環境下實時通用語義分割網絡
分析總結基于深度神經網絡的圖像語義分割方法

CVPR2020 | 即插即用!將雙邊超分辨率用于語義分割網絡,提升圖像分辨率的有效策略

PyTorch教程-14.9. 語義分割和數據集


實時語義建圖與潛在先驗網絡和準平面分割






 工商網監
工商網監
評論