 基于trendline濾波的評估模型
基于trendline濾波的評估模型
網絡的波動帶來的卡頓直接影響著用戶的體驗,在WebRTC中設計了一套基于延遲和丟包反饋的擁塞機制(GCC)和帶寬調節策略來保證延遲、質量和網路速度之間平衡。
在視頻通信的技術領域WebRTC已成為主流的技術標準,WebRTC包涵了諸多優秀的技術,譬如:音頻數字信號處理技術(AEC, NS, AGC)、編解碼技術、實時傳輸技術、P2P技術等,這些技術目的都是為了實現更好實時音視頻方案。但是在高分辨率視頻通信過程中,通信時延、圖像質量下降和丟包卡頓是經常發生的事,甚至在WiFi環境下,一次視頻重發的網絡風暴可以引起WiFi網絡間歇性中斷,通信延遲和圖像質量之間存在的排斥關系是實時視頻過程中的主要矛盾。
分析WebRTC是如何解決這個矛盾之前,先來看看我們在在線教育互動的生產環境統計到的視頻延遲和人感官的關系,大致如下:
| 0 ~ 400毫秒 | 人感覺不到視頻在通信過程中的延遲 |
| 400 ~ 800毫秒 | 人能感覺到輕微延遲,但不影響通信互動 |
| 800毫秒以上 | 人能感覺到延遲而且影響通信互動 |
也就是說,通信過程中最好將視頻延遲控制在800毫秒以內。除了延遲,視頻圖像質量也是個對人感官產生差異的關鍵因素,我們以640x480分辨率每秒24幀的H264編碼情況下視頻碼率和人感官之間的關系(這組數據是我們通過小范圍線上用戶投票打分的數據):
| 800kbps以上 | 人對視頻清晰度滿意,感覺不到視頻圖像中的信息丟失 |
| 480 ~ 800kbps | 人對視頻清晰度基本滿意,有時能感覺到視頻圖像中的信息丟失 |
| 480kbps以下 | 人對視頻清晰度不滿意,大部分時候無法辨認圖像中的細節信息 |
從上面的描述可以知道視頻質量保持在一個可讓人接受的質量范圍是需要比較大的帶寬碼率支持的,如果加上控制延遲,則更需要網絡有很好速度和穩定性。但是很不幸,我們現階段的移動網絡和家用WiFi并不是我們想象中的那么好,很難做到在實時視頻通信中一個讓人非常滿意的程度。為了解決以上幾個問題,WebRTC設計了一套基于延遲和丟包反饋的擁塞機制(GCC)和帶寬調節策略來保證延遲、質量和網路速度之間平衡,這是一個持續循環過程,如下圖:
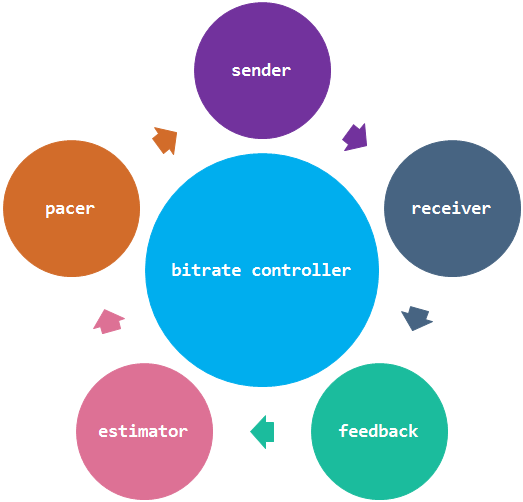
圖1:擁塞控制循環示意圖
1)estimator通過RTCP的feedback反饋過來的包到達延遲增量和丟包率信息計算出網絡擁塞狀態并評估出適合當前網絡傳輸的碼率,根據這個碼率改變視頻編碼器碼率,然后改變pacer的碼率
2)pacer會根據這個碼率改變pacer的網絡發送速度和padding比例,并用新的網絡發送速度來定時觸發發包事件。
3)sender收到pacer的發送事件,進行RTP報文發送。
4)receiver接收到RTP報文,進行arrival time統計和丟包統計
5)feedback定時對receiver統計的信息進行RTCP編碼,并反饋到發送端的estimator進行新一輪的碼率評估。
以上是整個WebRTC擁塞控制和帶寬調節過程,下面這個示意圖是這個過程涉及到WebRTC內部模塊關系。
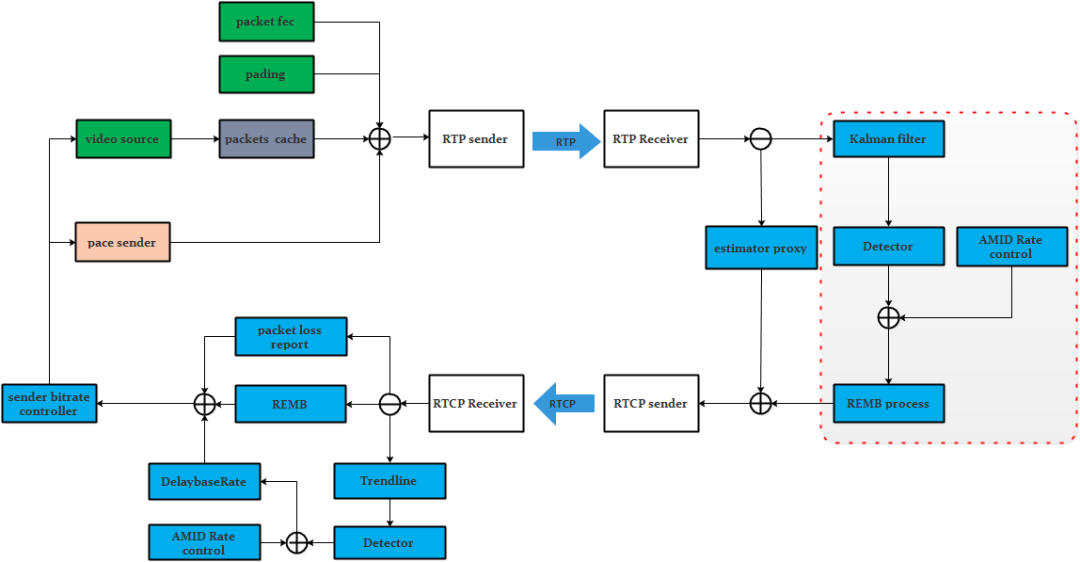
圖2:WebRTC的擁塞控制模塊關系圖
需要說明的是紅框中基于接收端的kalman filter帶寬評估模型已經在新版本的WebRTC中不采用了,只做了向前版本兼容,新版本的WebRTC都是采用發送端的trendline濾波器來做延遲帶寬評估,本文中重點是介紹基于trendline濾波的評估模型,下面依次來分析WebRTC的這五個過程。
1 estimator
estimator的功能就是通過接收端反饋過來的包到達時刻信息、丟包信息和REMB信息進行當前網絡狀態的碼率評估,WebRTC擁塞控制有兩部分:基于延遲的擁塞控制和基于丟包的擁塞控制,它是一個盡力而為的擁塞控制算法,犧牲了擁塞控制的公平性換取盡量大的吞吐量。從設計結構來描述向它輸入延遲和丟包信息,它就會輸出一個適應當前網絡狀態的碼率值。示意圖如下:
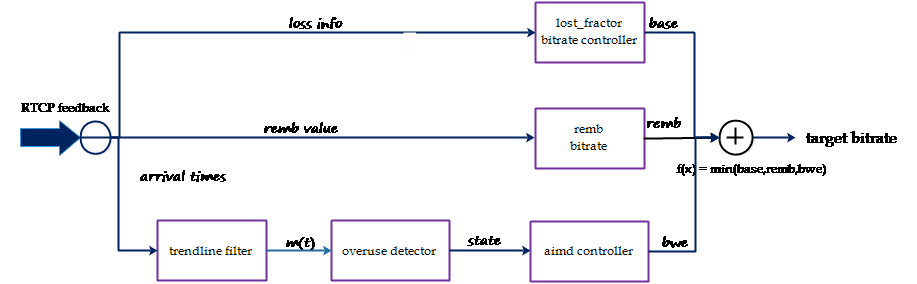
圖3:WebRTC的CC estimator輸入與輸出
從上圖可以看出,estimator基于延遲的擁塞控制是通過trendline濾波再進行過載判斷,最后根據過載情況進行aimd碼率調控評估出一個bwe bitrate碼率,這個碼率會合丟包評估出來的碼率和remb來決定最后的碼率。
1.1 基于延遲的擁塞控制
基于延遲的擁塞控制是通過每組包的到達時間的延遲差(delta delay)的增長趨勢來判斷網絡是否過載,如果過載進行碼率下調,如果處于平衡范圍維持當前碼率,如果是網絡承載不飽滿進行碼率上調。這里有幾個關鍵技術:包組延遲評估、濾波器趨勢判斷、過載檢測和碼率調節。
1.1.1 包組與延遲
WebRTC在評估延遲差的時候不是對每個包進行估算,而是采用了包組間進行延遲評估,這符合視頻傳輸(視頻幀是需要切分成多個UDP包)的特點,也減少了頻繁計算帶來的誤差。那么什么是包組呢?就是距包組中第一個包的發送時刻t0小于5毫秒發送的所有的包成為一組,第一個超過5毫秒的包作為下一個包組第一個包。為了更好的說明包組和延遲間的關系,先來看示意圖:
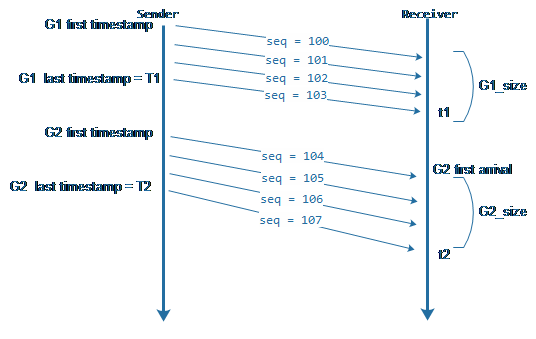
圖4:包組與延遲示意圖
上圖中有兩個包組G1和G2, 其中第100號包與103號包的時間差小于5毫秒,那么100 ~ 103被劃作一個包組。104與100之間時間超過5毫秒,那么104就是G2的第一個包,它與105、106、107劃作一個包組。知道了包組的概念,那么我們怎么通過包組的延遲信息得到濾波器要的評估參數呢?濾波器需要的三個參數:發送時刻差值(delta_timestamp)、到達時刻差值(delta_arrival)和包組數據大小差值(delta_size)。從上圖可以得出:
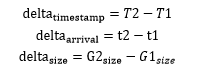
1.1.2 濾波器
我們通過包組信息計算到了delta_timestamp、delta_arrival和delta_size,那么下一步就是進行數據濾波來評估延遲增長趨勢。在WebRTC實現了兩種濾波器來進行延遲增長趨勢的評估,分別是:kalman filter和trendline filter, 從圖2中我們知道kalman filter是運行在接收端的,我在這里以不做介紹,有興趣的可以參考https://www.jianshu.com/p/bb34995c549a。
這里介紹trendline filter,我們知道如果平穩網速下傳輸數據的延遲時間就是數據大小除以速度,如果這數據塊很大,超過恒定網速下延遲上限,這意味著要它要占用其他后續數據塊的傳輸時間,那么如此往復,網絡就產生了延遲和擁塞。Trendline filter通過到達時間差、發送時間差和數據大小來得到一個趨勢增長值,如果這個值越大說明網絡延遲越來越嚴重,如果這個值越小,說明延遲逐步下降。以下是計算這個值的過程。
先計算單個包組傳輸增長的延遲,可以記作:
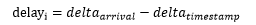
然后做每個包組的疊加延遲,可以記作:
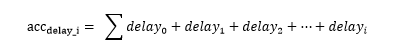
在通過累積延遲計算一個均衡平滑延遲值,alpha=0.9可以記作:
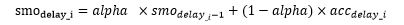
然后統一對累計延遲和均衡平滑延遲再求平均,分別記作:
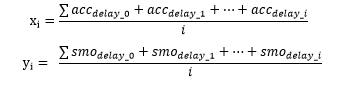
我們將第i個包組的傳輸持續時間記作:
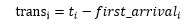
趨勢斜率分子值為:
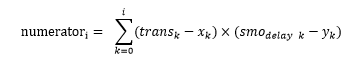
趨勢斜率分母值為:
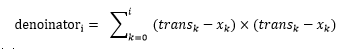
最終的趨勢值為:
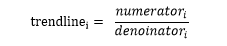
1.1.3過載檢測
在計算得到trendline值后WebRTC通過動態閾值gamma_1進行判斷擁塞程度,trendline乘以周期包組個數就是m_i,以下是判斷擁塞程度的偽代碼:

通過以上偽代碼就可以判斷出當前網絡負載狀態是否發生了過載,如果發生過載,WebRTC是通過一個有限狀態機來進行網絡狀態遷徙,關于狀態機細節可以參看下圖:
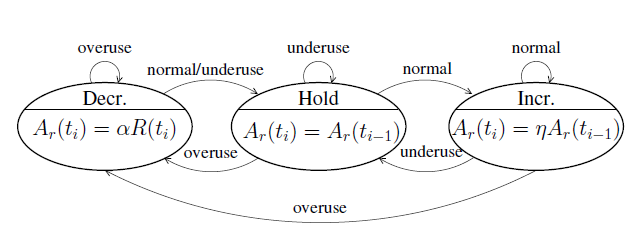
圖5:過載檢測狀態機
從上圖可以看出,網絡狀態機的狀態遷徙是由于網絡過載狀態發生了變化,所以狀態遷徙作為了aimd帶寬調節的觸發事件,aimd根據當前所處的網絡狀態進行帶寬調節,其過程是處于Hold狀態表示維持當前碼率,處于Decr狀態表示需要進行碼率遞減,處于Incr狀態需要進行碼率遞增。那他們是怎么遞增和遞減的呢?WebRTC引入了aimd算法解決這個問題。
1.1.4 AIMD碼率調節
aimd的全稱是Additive Increase Multiplicative Decrease,意思是:和式增加,積式減少。aimd controller是TCP底層的碼率調節概念,但是WebRTC并沒有完全照搬TCP的機制,而是設計了套自己的算法,用公式表示為:
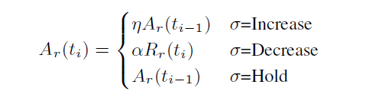
如果處于Incr狀態,增加碼率的方式分為兩種:一種是通信會話剛剛開始,相當于TCP慢啟動,它會進行一個倍數增加,當前使用的碼率乘以系數,系數是1.08;如果是持續在通信狀態,其增加的碼率值是當前碼率在一個RTT時間周期所能傳輸的數據速率。
如果處于Decrease狀態,遞減原則是:過去500ms時間窗內的最大acked bitrate乘上系數0.85,acked bitrate通過feedback反饋過來的報文序號查找本地發送列表就可以得到。
aimd根據上面的規則最終計算到的碼率就是基于延遲擁塞評估到的bwe bitrate碼率。
1.2基于丟包的擁塞控制
除了延遲因素外,WebRTC還會根據網絡的丟包率進行擁塞控制碼率調節,描述如下:
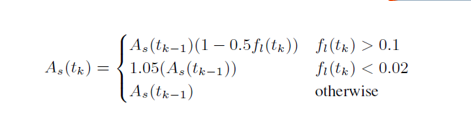
解釋下上面的公式:
當丟包率>2%時,這個時候會將碼率(base bitrate)增長5%,這個碼率(base bitrate)并不是當前及時碼率,而是單位時間窗周期內出現的最小碼率,WebRTC將這個時間窗周期設置在1000毫秒內。因為loss fraction是從接收端反饋過來的,中間會有時間差,這樣做的目的是防止網絡間歇性統計造成的網絡碼率增長過快而網絡反復波動。
當 2% < 丟包率 < 10%,維持當前的碼率值
當 丟包率 >= 10%, 按丟包率進行當前碼率遞減,等到新的碼率值
丟包率決策出來的碼率(base bitrate)只是一個參考值,WebRTC實際采用的帶寬是base bitrate、remb bitrate和bwe bitrate中的最小值,這個最小值作為estimator最終評估出來的碼率
2 pacer
在estimator根據網絡狀態決策出新的通信碼率(target bitrate),它會將這個碼率設置到pacer當中,要求pacer按照新的碼率來計算發包頻率。因為在視頻通信中,單幀視頻可能有上百KB,如果是當視頻幀被編碼器編碼出來后,就立即進行RTP打包發送,瞬時會發送大量的數據到網絡上,可能會引起網絡衰減和通信惡化。WebRTC引入pacer,pacer會根據estimator評估出來的碼率,按照最小單位時間(5ms)做時間分片進行遞進發送數據,避免瞬時對網絡的沖擊。pacer的目的就是讓視頻數據按照評估碼率均勻的分布在各個時間片里發送,所以在弱網的WiFi環境,pacer是個非常重要的關鍵步驟。以下WebRTC中pacer的模型關系:
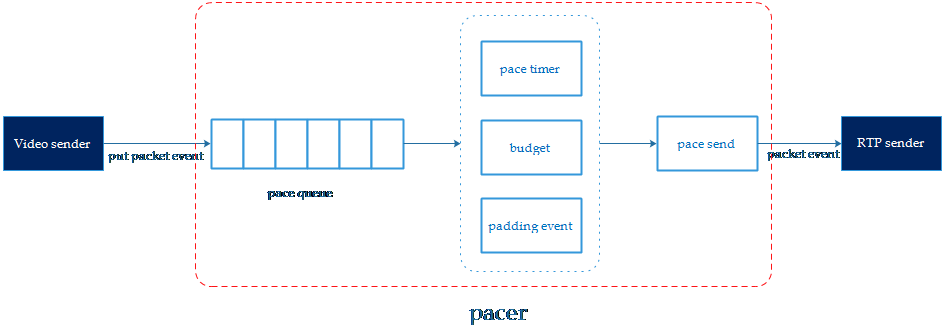
圖6:pacer模型圖
WebRTC中pacer的流程比較清晰,分為三步:
1)如果一幀圖像被編碼和RTP切分打包后,先會將RTP報文存在待發送的隊列中,并將報文元數據(packet id, size, timestamp, 重傳標示)送到pacer queue進行排隊等待發送,插入隊列的元數據會進行優先級排序。
2)pacer timer會觸發一個定時任務事件來計算budget,budget會算出當前時間片網絡可以發送多少數據,然后從pacer queue當中取出報文元數據進行網絡發送。
3)如果pacer queue沒有更多待發送的報文,但budget卻還可以發送更多的數據,這個時候pacer會進行padding報文補充。
從上面的步驟描述中可以看出pacer有幾個關鍵技術:pace queue、padding、budget。
2.1 pace queue與優先級
pace queue是一個基于優先級排序的多維鏈表,它并不是一個先進先出的fifo,而是一個按優先級排序的list。
報文優先級規則
1)優先級高的報文排在fifo的前面,低的排在后面。
2)優先級是最先判斷報文的QoS等級,等級越小的優先級越高
3)其次是判斷重發標示,重發的報文比普通報文的優先級更高
4)再次是判斷視頻幀timestamp,越早的視頻幀優先級更高。
pacer每次觸發發送事件時是先從queue的最前面取出優先級最高的報文進行發送,這樣做的目的是讓視頻在傳輸的過程中延遲盡量小,重傳的報文盡快能到達防止等待卡頓。pace queue還可以設置最大延遲,如果超過最大延遲,會計算queue中數據發送所需要的碼率,并且會把這個碼率替代target bitrate作為budget參考碼率來加速發送。
2.2 budget
budget是個評估單位時間內可以發送多少數據量的一個機制,因為pacer是會根據pace timer定時來觸發發送檢查。Budget會根據評估出來的參考碼率計算這次定時事件能發送多少字節,可以表示為:
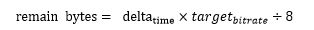
delta time是上次檢查時間點和這次檢查時間點的時間差。
target bitrate是pacer的參考碼率,是由estimator根據網絡狀態評估出來的。
remain_bytes每次觸發發包時會減去發送報文的長度size,如果remain_bytes > 0,繼續從pace queue中取下一個報文進行發送,直到remain_bytes <=0 或者 pace queue沒有更多的報文。
2.3 pacer延遲
那么肯定有人會有疑問pacer queue和budget進定量計算來發送網絡報文,相當于cache等待發送,難道不會引起延遲嗎?可以肯定的說會引起延遲,但延遲不嚴重。pacer產生的延遲可以表示為:
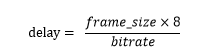
假如評估出來的碼率是10mbps, 一個視頻關鍵幀的大小是300KB,那么這個關鍵幀造成的pacer delay是240毫秒。從實際應用觀察到的關鍵幀引起的pace delay在200 ~ 400毫秒之間,這個值相對于視頻傳輸來說是比較大的,但是不嚴重。WebRTC為了減少這個延遲,會評估出盡量大的bitrate。那么怎么評估出盡量大的碼率呢?從前面的estimator描述中我們知道要發送出盡量多的數據才能評估盡量大的碼率,但是視頻編碼器不會發送多余的數據,所以WebRTC引入了padding機制來保障發送盡量大的數據來探測網絡帶寬上限。
2.4 padding
pace padding除了保障能pace delay盡量小外,它可以讓有限的帶寬獲得盡可能好的視頻質量。padding的工作原理很簡單,就是在單位時間片內把budget還剩余的空閑用padding數據填滿。我個人認為padding只是適合點對點通信,一旦涉及到多點分發,會因為padding占用很多服務轉發帶寬,這并不是一件好事情。
3 sender
WebRTC的發送模塊和擁塞控制控制相關的主要是增加了附加的RTP擴展來攜帶便宜接收端統計丟包率和延遲間隔的信息、配合pacer的發包策略、帶寬分配和FEC策略的信息。
3.1 RTP擴展
WebRTC為了配合接收端進行延遲包序列和丟包統計做了下列擴展:
transport sequence傳輸通道的只增sequence,每次發送報文時自增長,配合接收端統計丟包、通過反饋這個sequence可以計算得到發包的時刻。
TransmissionOffset 發送報文的相對時刻,這個相對時刻值t是發送報文的絕對時刻T1和視頻幀時間戳T0差值。早期的WebRTC是在接收端進行estimate bitrate,所以過載判斷是在接收端完成的,這個值就是為了kalman filter計算發包造成的延遲用的,新版本還攜帶這個值以便低版本的WebRTC能兼容。
3.2 packet cache
packet cache是一個key/value結構的包緩沖池,視頻幀在進行RTP分片打包后不會立即發送出去,而是要等待pacer的發送信號進行發送。所以打包后會按[id,packet]鍵值對插入到packet cache中。一般packet cache會保存600個分片報文,最大9600個,插入新的會將最舊的報文刪除,packet cache這樣做的目的除了配合pacer發送外,也為了后面響應nack的丟包重傳。
3.3 NACK與丟包重傳
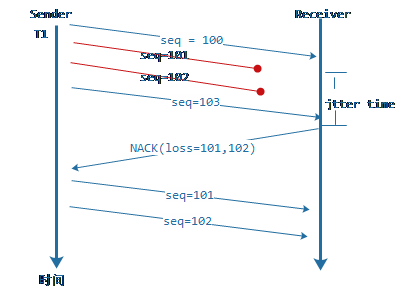
圖7:RTP NACK過程的示意圖
WebRTC在評估到收發端之間RTT延遲比較小的時候會采用NACK來進行丟包補償,NACK是一個請求重發過程,其流程如上圖所示。這個過程有一個問題是在網絡抖動和丟包很厲害的情況下有可能造成同一時刻收到很多NACK的重傳請求,發送端瞬間把這些重傳請求放入pacer中進行重發,這樣pacer的延遲會增大,而且pace的參考碼率會隨著pace queue的延遲控制變的很大而出現間歇性網絡風暴。WebRTC在處理NACK重傳時設計了一個重傳碼率控制器,其設計原理是通過統計單位時間窗口周期中發送的字節數據來限流,如果這個時間窗內發送的數據的碼率大于estimator評估的碼率,不進行當前NACK請求的重傳,等待下一個NACK。
3.4 FEC與碼率分配
WebRTC應對丟包時除了NACK方式,在收發端之間RTT很大時候會開啟FEC來進行丟包補償,我們在這里不介紹FEC具體算法,只介紹FEC的碼率分配策略。從整個通信機制我們很容易得出這樣一個共識:
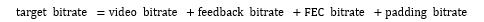
FEC bitrate到底應該設置多大呢?它先根據feedback中反饋過來的丟包率(loss fraction)來確定使用哪一種FEC,在根據每中FEC和丟包率來確定FEC使用的碼率,但需要滿足一下條件:
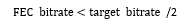
feedback的碼率被設定為target bitrate的5%,WebRTC是通過控制feekback的頻率來進行調控分配的。padding bitrate是通過pacer queue和budget來控制的。Target bitrate減去這些碼率之和就是給視頻編碼器的碼率。每次estimator評估出來碼率后,會先進行這些計算得到最后的video bitrate,并將這個值作為編碼器的編碼碼率,以此來達到防止擁塞的目的。
4 receiver
receiver模塊的工作相對來說比較簡單,它就做三件事情:記錄每個報文的到達時刻(arrival timestamp)、丟包率(lost fraction)和receiver bitrate。早期的WebRTC提供了圖2紅框當中kalman filter評估碼率的評估器,因為kalman filter怕抖動特性且需要借助remb心跳進行反饋,remb的反饋周期是1秒,在收發端網絡間歇性斷開或者大抖動下,容易失效,所以WebRTC采用了在發送端進行估算,整個邏輯也更加簡便。
4.1 報文到達時間
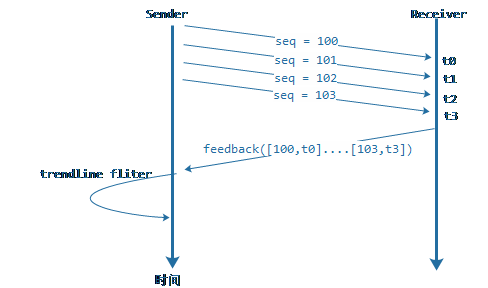
圖8:到達報文統計圖
上圖是一個統計RTP報文到達時刻的序列圖,圖中的seq是RTP擴展中的transport sequence,接收端用一個k/v([seq,arrival timestamp])鍵值對數據結構來保存最近500毫秒未反饋的到達時刻信息,通過時間窗口周期來進行淘汰老的到達時刻記錄。
4.2 丟包率計算
丟包率計算過程是這樣的,我們把上次統計丟包率時刻的最大sequence記著prev_seq, 把當前收到的最大sequence記著cur_seq,當前統計丟失的報文記著count,WebRTC在RTCP中描述丟包率采用的是uint8,為了保證精確度將256記著100%的丟包率,那么很容易得:
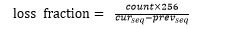
這里需要提的是WebRTC在統計報文是否丟失是通過sequence的連續性和網絡的jitter時間來確定的,只有落在jitter抖動范圍之外的丟包才是算是作丟包。
4.3 接收碼率統計
接收端碼率統計采用的是最近單位時間窗(1000毫秒)周期內收到的的字節數來計算,WebRTC設計了一個1毫秒為最小單位的窗口數組來進行統計,每個最小單位是數字,這個數字是在這個時刻收到的網絡數據大小,大致的示意圖如下:
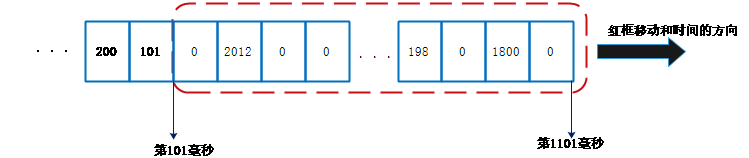
圖9:接收碼率統計示意圖
計算碼率只需要將紅框中所有的數字加起來,當時間發生改變后,就紅框就向右移動并且填寫新時刻接收到的數據大小,等下一個統計時刻既可。
5 feedback
前面介紹的estimator依賴于feedback反饋的報文到達時刻和丟包率來進評估碼率的,也就是說feedback需要將這些信息及時反饋給接收端,主要是記錄的報文到達時刻、通道丟包率和remb帶寬。因為報文到達時刻和丟包率統計都是多個數據項,WebRTC利用了report block來進行編碼存放。為了有效的利用RTCP的report block空間,WebRTC采用了相對時間轉換和位壓縮算法來對到達時間序列做編碼壓縮。
除了report編碼,feedback的周期也很重要,如果是單純的remb反饋,一般是1秒一次反饋。但如果是需要反饋報文的到達時間,它會根據占用5%的target bitrate來計算發送feedback的時間間隔,計算流程如下:

feedback interval需要滿足一個條件:50ms < interval < 250ms,這個條件中的 50ms< internal是為了防止interval太小造成發送feedback太過頻繁而消耗網絡性能,而interval < 250ms是為了防止feedback頻次太低造成estimator反應遲鈍。
6 總結
以上就是WebRTC擁塞控制和碼率調節策略的5個過程,里面涉及到很多傳輸相關的技術,我在這里也是簡單介紹了下其工作原理,很多細節的并沒有描述出來,也很難描述出來,有興趣的同學可以翻看WebRTC的源代碼。如果覺得webRTC代碼費勁,我照虎畫貓將WebRTC的擁塞控制用C重新實現了個簡易版本,但是去掉了padding,可到https://github.com/yuanrongxi/razor下載。
6.1 效果
WebRTC的GCC在網絡適應上表現還是比較良好的,既然兼顧延遲,也能兼顧丟包,網絡發生擁塞時在2 ~ 3秒內能評估出相對的碼率來適應當前的網絡狀態,但是會造成短時間的卡頓。對于網絡發生間歇性丟包,在2秒左右能將傳輸碼率適配到當前網絡狀態。它在網絡相對穩定且延遲較大的網絡進行高分辨率傳輸時,視頻很穩定,適合長距離延遲穩定的網絡環境。在弱網環境下,WebRTC容易將碼率降到很低而造成圖像失真。
6.2 網絡大抖動
對于亂序和抖動WebRTC的擁塞控制顯得有點無力,如果抖動超過rtt*2/3時,基于kalman filter的帶寬評估機制不起作用(不知道是不是我用錯了);基于trendline濾波的評估機制波動很大,敏感度不夠,不能完全反應當前的網絡過載狀態,尤其是在終端Wi-Fi擁擠的情況下,比較容易造成間歇性風暴。
6.3 延遲問題
WebRTC的pacer在傳輸大分辨率視頻時,關鍵幀會引起大約200毫秒的延時,尤其是在移動4G網絡下這個問題更加明顯,海康威視工程師鄭鵬提出了用H.264的intre_refresh模式來應對,在測試過程中確實比較適合WebRTC用來減少關鍵幀造成的延遲,但是intre_refresh是普通模式編碼CPU的3倍左右,而且很多移動設備的編碼器不一定支持。
總之,WebRTC的擁塞控制存在反應慢、怕抖動的特性,但是這塊也是WebRTC改進最為頻繁的模塊,幾乎每個版本都有新的改進。要徹底解決這樣的問題,需要從視頻編碼器和網絡傳輸進行融合來解決,以后我用單獨的篇幅來介紹下這樣的解決方案。
-
擁塞控制
+關注
關注
0文章
14瀏覽量
8472 -
WebRTC
+關注
關注
0文章
56瀏覽量
11216
原文標題:WebRTC的擁塞控制和帶寬策略
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

如何評估AI大模型的效果
Meta推出可自我評估AI模型
【每天學點AI】人工智能大模型評估標準有哪些?

介紹FIR濾波模型的建立,分4個步驟
OpenAI與Anthropic新模型將受美政府評估
華為云盤古汽車大模型通過可信AI汽車大模型評估
神經網絡模型建完了怎么用
esp-dl int8量化模型數據集評估精度下降的疑問求解?
商湯小浣熊榮獲中國信通院代碼大模型能力評估“三好生”

【大語言模型:原理與工程實踐】大語言模型的評測
大模型在戰略評估系統中的應用有哪些
如何測試電源濾波器的性能?
怎么評估ADC的SFDR和中頻濾波器的抑制度呢?

基于YOLOv8實現自定義姿態評估模型訓練






 工商網監
工商網監
評論