 計算機視覺零基礎入門
計算機視覺零基礎入門
剛剛過去的五四青年節,你的朋友圈是否被這樣的民國風照片刷屏?用戶只需要在 H5 頁面上提交自己的頭像照片,就可以自動生成諸如此類風格的人臉比對照片,簡潔操作的背后離不開計算機視覺技術和騰訊云技術的支持。
那么這個爆款應用的背后用到了哪些計算機視覺技術?掌握這些技術需要通過哪些學習路徑?
5 月 17 日,人工智能頭條邀請到騰訊云 AI 和大數據中心高級研發工程師葉聰,他以直播公開課的形式為大家解答了這些問題,
▌一、朋友圈爆款活動介紹
大家經常在朋友圈看到一些很有趣的跟圖像相關的小游戲,包括以前的軍裝照以及今年五四青年節的活動。這個活動非常有意思,大家可以選擇一張自己覺得拍的最美的照片,然后上傳到 H5 的應用里面,我們就會幫你匹配一張近現代比較優秀的青年照片。那張照片是老照片,而大家上傳的是新照片,這就產生了一些比較有意思的對比,這個活動今年也是得到了強烈的反響,大家非常喜歡。
所有的這些算法構建完以后,我們把它上傳到了騰訊云的 AI 大平臺上去。因為我們參照了去年軍裝照的流量,所以這次活動我們預估了 5 萬 QPS,這其實是很高的一個要求。該活動 5 月 4 日上線,截止 5 月 5 日下線,在短短兩天內,在線 H5 頁面的 PV 達到了 252.6 萬,UV 111.3 萬,服務調用量 420 萬,還是比較驚人的。
▌二、計算機視覺基礎知識

首先計算機視覺是什么?計算機視覺研究如何讓計算機從圖像和視頻中獲取高級和抽象信息。從工程角度來講,計算機視覺可以使模仿視覺任務自動化。
一般來說計算機視覺包含以下分支:
物體識別
對象檢測
語義分割
運動和跟蹤
三維重建
視覺問答
動作識別
這邊額外提一下語義分割,為什么要提這個呢?因為語義分割這個詞也會在包括 NLP、語音等領域里出現,但是實際上在圖像里面分割的意思跟在語音和 NLP 里面都很不一樣,它其實是對圖像中間的不同的元素進行像素級別的分割。比如最右下角這張圖片,我們可以看到行人、車輛、路,還有后面的樹,他們都用不同的顏色標注,其實每一種顏色就代表了一種語義。左邊和中間的兩幅圖,可能我不用介紹,大家也應該能猜到了,一個是人臉識別,一個是無人駕駛,都是現在使用非常廣泛和熱門的應用。
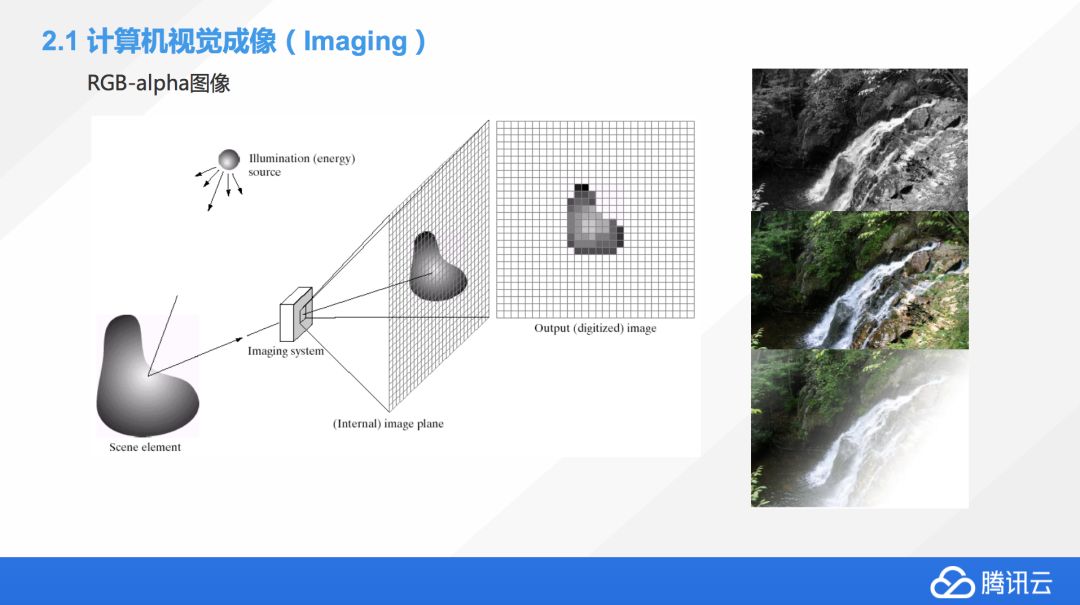
如何讓機器可以像人一樣讀懂圖片?人在處理圖像的時候,我們是按照生物學的角度,從圖像到視網膜然后再存儲到大腦。但機器沒有這套機制,那機器如何把圖片裝載到內存里面?這個就牽扯到一個叫 RGB-alpha 的格式。
顧名思義,就是紅綠藍三色,然后,alpha 是什么?如果大家在早期的時候玩過一些電腦硬件,你可能會發現,最早期的顯卡是 24 位彩色,后來出現一個叫 32 位真彩色,都是彩色的,有什么不同嗎?因為在計算機領域,我們用 8 位的二進制去表示一種顏色,紅綠藍加在一起就是 24 位,基本上我們把所有顏色都表示出來了。
為什么還出現 alpha?alpha 是用來表示一個像素點是不是透明的,但并不是說 alpha 是 1 的時候它就是透明,是 0 的時候就不透明。只是說阿爾法通道相當于也是一個矩陣,這個矩陣會跟 RGB 的其他的矩陣進行一種運算,如果 alpha 的這個點上是 1,它就不會影響 RGB 矩陣上那個點的數值,它就是以前原來的顏色,如果是 0,這個點就變成透明的。這也是我們怎么用 RGB 加 alpha 通道去描述世界上所有的圖片的原理。
比如右上角,這張圖片是黑白圖,中間是彩色圖,下面一張是有些透明效果,右下角基本上沒有像素點,這就是一個很好的例子,去理解 RGB 是怎么一回事。
除了 RGB-alpha 這種表達方式,我們還有很多不同的顏色表達方式。包括如果我們搞印刷的話,大家可能接觸到另外一種色系,叫 CMYK,這個也是一種顏色的表示方式。這邊還會有一些其他類型的圖片,包括紅外線圖片,X 光拍攝的圖片,紅外熱成像圖,還有顯微鏡拍攝的細胞圖,這些加在一起都是我們計算機可以處理的圖像的范圍,不僅僅是我們之前看到,用手機、攝像機拍攝的圖片。
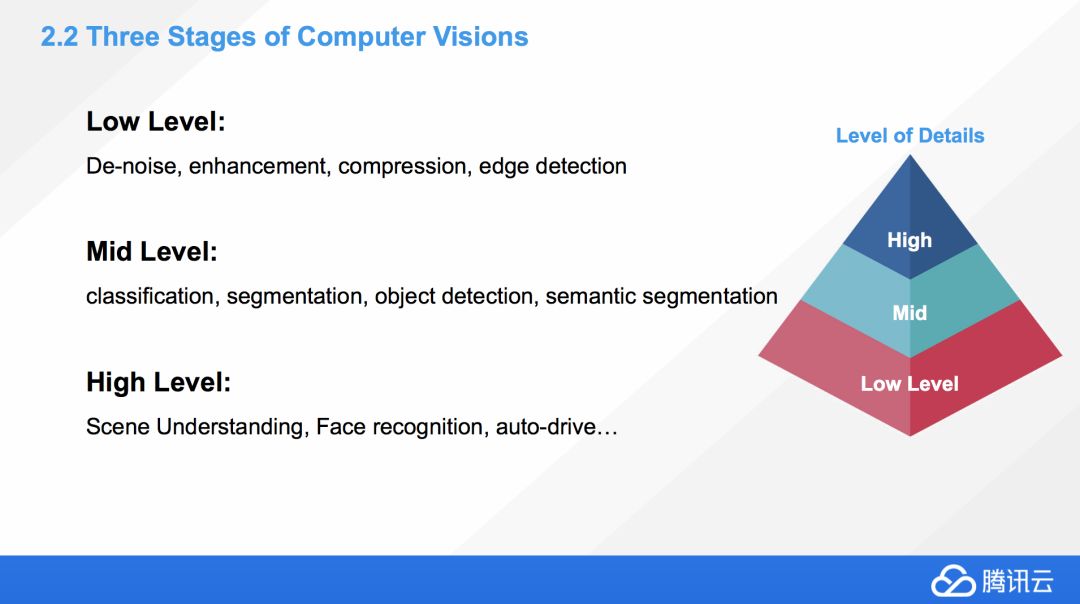
我們在計算機視覺中經常會提到 stages,為什么叫 stages?
這邊我們看到,有 Lowlevel,Midlevel,Highlevel,這里澄清一下,并不是說 LowLevel 這些應用就比較低級,Highlevel 就比較高端,這個描述的維度其實是從我們看問題的視野上來說的,Low level 代表我們離這個問題非常近,Highlevel 代表比較遠。
舉一個簡單例子,比如 LowLevel 上面我們可以做圖像的降噪、優化、壓縮、包括邊緣檢測,不管是哪一條,我們都是可以想象一下,我們是離這個圖片非常近的去看這個細節。Highlevel 是什么?包括情景理解、人臉識別、自動駕駛,它基本上是從一個比較遠的角度來看這個大局。
所以其實大家可以這么想,在解決問題的時候,我們要離圖片的視覺大概保持多遠的距離,High 代表比較遠,Low 代表比較近,并不是說 High 比 Low 要難,或者說要高端。
Midlevel 介于 High 跟 Low 之間的,包括分類、分割、對象檢測,后面還有情景分割,這邊的情境分割跟分割還不太一樣,應該說是更深度的分割問題,后面我會詳細解釋。
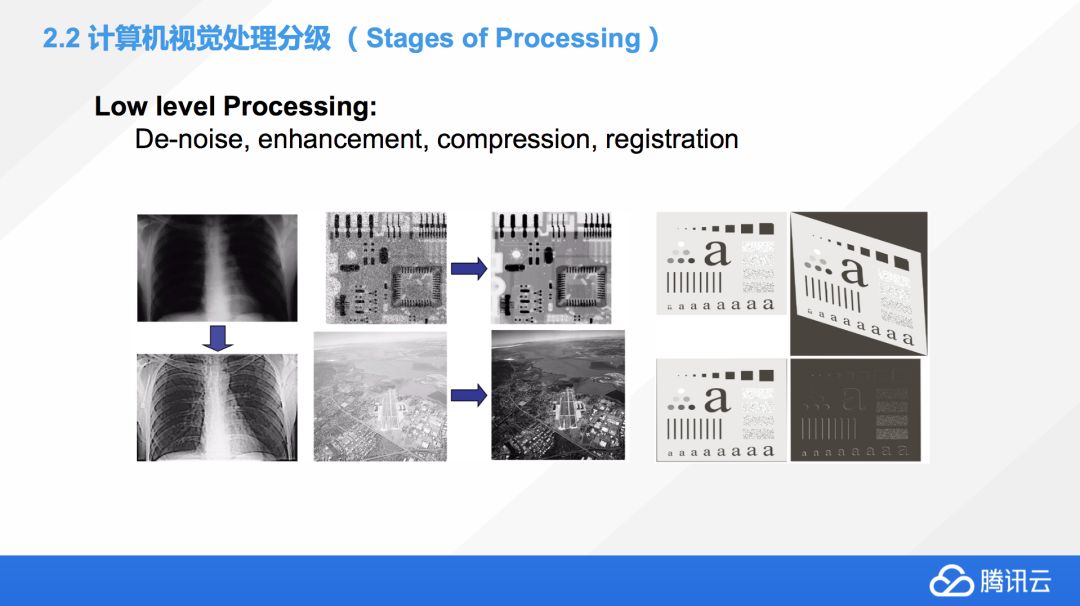
這邊有一些例子是幫大家去理解 Lowlevel Processing。比如左上那張是我們拍 X 光會看到的圖,上面那張圖是原始的 X 光的圖片,大家可以看到,非常的不清晰,很難去理解到里面的骨骼,血管在什么位置。但通過 LowLevel Processing 的降噪和優化,就能非常清晰的看到這個病人的所有的骨骼及內臟的位置。
中間這個是一個 PCB 板,一些工業領域為了檢測 PCB 板就會拍攝照片,做圖像處理,并用這種方式去找到板上的一些問題,然后去修復它。有的時候也為了質量品控,看到中間這張的 PCB 板原始的圖片上面充滿了噪音,經過優化、降噪以后就得到一張很清晰的照片。
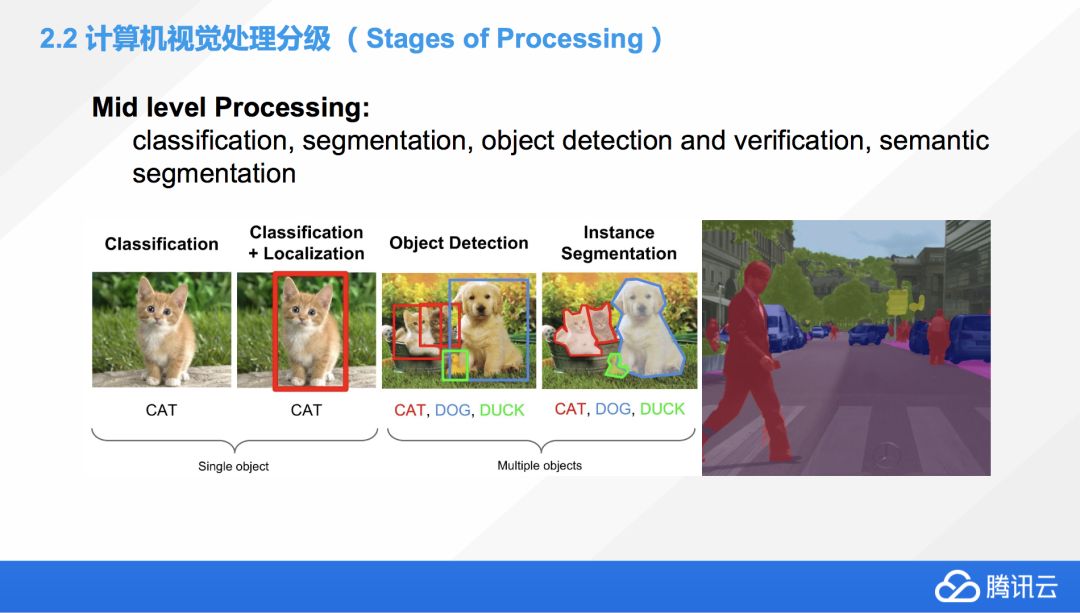
這個是 Mid level Processing,目前這塊的技術比較成熟。這塊的應用包括分類、分割、目標檢測,也包括情景檢測、情景分割,甚至還有意圖檢測,就是通過看圖片里面的一些物體和他們目前在做的一些行為來判斷他們的意圖。
底下有幾張小貓咪和小狗的圖,從左到右是一個進階的方向。首先最容易想到的一個應用,就是怎么能用機器學習的方法讀懂一張圖片里面的內容,那這個方法如何去實現它呢?其實就是用了一個分類,因為左邊那張圖片如果給了機器,分類算法會告訴你里面有一只貓,但是僅此而已。
那如果我們想知道,這里面有只貓,但這只貓在哪里呢?這個問題,我們就需要在這個基礎上加上定位,也就是第二張圖片,那我們就可以定位到,原來這里是貓咪所在的范圍,只是在這個方框范圍內,并沒有精確到像素級別。
再進一步,如果這張圖片里面不僅僅有貓,可能會有很多其他的東西,我希望把所有的東西都標識出來,應該怎么辦?這個任務叫做叫對象檢測,就是把圖片里面所有的這些對象全部標注檢測出來。
再進一步,我不但想把里面的對象全部標注出來,我還要精確的知道,它們在圖像的什么位置,這種情況下我可能想把它們剝離出來,把背景去掉。一般情況下,這種被我們框出來的對象叫做前景,其他的這些部分叫做后景。我們如果想把前景弄出來,那我們就需要這種對象分割的技術,從左到右,我們就完成了分類、定位、檢測、對象分割的全部流程,從頭到尾也是一個慢慢晉升的過程。因為定位是需要分類的基礎的,對象檢測是需要有分類基礎的,情景分割也需要有檢測的基礎,它是一個由淺入深的一個過程。
最右邊就是一個情景分割的例子,之前我也簡單介紹過,現在的技術已經可以精確的把我們這張圖片上的幾乎所有的元素很精確的給分出來,包括什么是人、車、路、景色、植物、大樓等全部都能分出來,我們的技術目前在 Mid level Processing 這塊已經很成熟了。
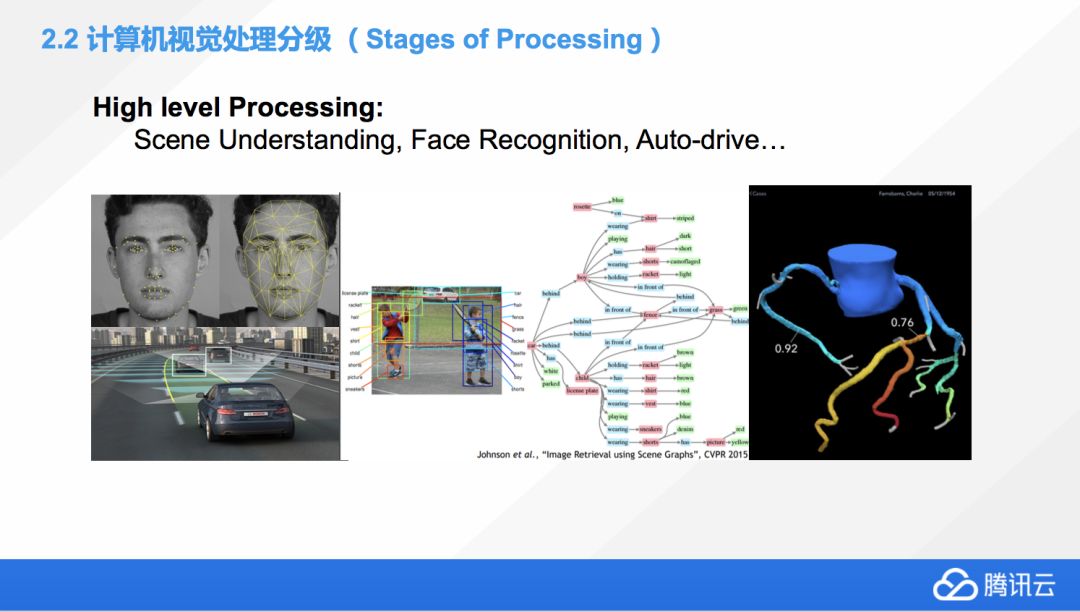
接下來簡單介紹一下 High level Processing,也是目前非常熱門和有前景,但是應該說遠遠還未達到成熟的技術。可能目前,大家做最好的 High level Processing 就是人臉檢測。
左下角那張是無人駕駛,也可以叫做高智能的輔助駕駛,不同的車廠,不同的定義,基本上就是對象檢測的一個復雜應用,包括檢測到路上的所有情況,包括不同的地上標識,周圍的建筑,還有在你前面的所有車輛,甚至行人,各種信息,還包括跟他們的距離,它是一個相對來說多維度的,是個復雜的對象檢測的應用。
中間的是兩個小朋友在打網球,這張圖片也是兩個人物,跟之前Mid level Processing有什么區別嗎?其實從右邊那個對象樹上,我們就能判斷,它是對這個圖片理解的深度有了非常本質的區別。前一個那個例子,我們知道圖片上有貓有狗,僅此而已。而這張圖片上,我們除了判斷到,圖片上有兩個孩子以外,還對他們的各種穿著,都進行了精確的分割和定義,包括他們手上的這些持有的球拍,我們都有個非常詳細的描述,所以Highlevel圖像的理解并不是簡單的說有哪些東西,而是他們之間的聯系、細節。Highlevel本身不僅能識別我們的圖上有什么東西,它還能識別,應該做什么,他們的關系是什么。
右邊那張圖片是一個醫學的應用,一個心血管的虛擬圖。它是英國皇家醫學院跟某個大學合作的一個項目,我們通過計算機視覺去模擬一個病人的心血管,幫助醫生做判斷,是否要做手術,應該怎么去做手術方案,這個應該是計算機視覺在醫學上的很好的一個應用的例子。

這里有一些比較常見的計算機視覺的應用,平時我們也會用到,包括多重的人臉識別,現在有些比較流行的照片應用,不知道大家平時會不會用到,包括比如像 Google photos,基本上傳一張照片上去,它就會對同樣的照片同樣的人物進行歸類,這個也是目前非常常見的一個應用。
中間那個叫 OCR,就是對文本進行掃描和識別,這個技術目前已經比較成熟了。照片上這張是比較老的技術,當時我記得有公司做這個應用,有個掃描筆,掃描一下就變成文字,現在的話,基本上已經不需要這么近的去掃描了,大家只要拍一張照片,如果這張照片是比較清晰的,經過一兩秒鐘,一般我們現在算法就可以直接把它轉換成文字,而且準確率相當高,所以圖片上的這種 OCR 是一個過時的技術。
右下角是車牌檢測,開車的時候不小心壓到線了,闖紅燈了,收到一張罰單,這個怎么做到呢?也是計算機視覺的功勞,它們可以很容易的就去識別這個照片里的車牌,甚至車牌有一定的污損,經過計算機視覺的增強都是可以把它給可以優化回來的,所以這個技術也是比較實用的。

下面聊幾個比較有挑戰性的計算機視覺的任務。首先是目標跟蹤,目標跟蹤就是我們在連續的圖片或者視頻流里面,想要去追蹤某一個指定的對象,這個聽起來對人來說是一個非常容易的任務,大家只要目不轉睛盯著一個東西,沒有人能逃脫我們的視野。
實際上對機器來說,這是一個很有挑戰性的任務,為什么呢?因為機器在追蹤對象的時候,大部分會使用最原始的一些方法,采取一些對目標圖片進行形變的匹配,就是比較早期的計算機識別的方法,而這個方法在實際應用中間是非常難以實現的,為什么?因為需要跟蹤的對象,它由于角度、光照、遮擋的原因包括運動的時候,它會變得模糊,還有相似背景的干擾,所以我們很難利用模板匹配這種方法去追蹤這個對象。一個人他面對你、背對你、側對你,可能景象完全不一樣,這種情況下,同樣一個模板是無法匹配的,所以說,很有潛力但也很有挑戰性,因為目前對象追蹤的算法完全沒有達到人臉識別的準確率,還有很多的人在不斷的努力去尋找新的方法去提升。
右邊也是一個例子,就是簡單的一個對我們頭部的追蹤,也是非常有挑戰性的,因為我們頭可以旋轉,尺度也可能發生變化,用手去遮擋,這都給匹配造成很大的難度。

后面還有一些比較有挑戰性的計算機視覺任務,我們歸類把它們叫做多模態問題,其中包括 VQA,這是什么意思?這個就是說給定一張圖片,我們可以任意的去問它一些問題,一般是比較直接的一些問題,Who、Where、How,類似這些問題,或者這個多模態的模型,要能夠根據圖片的真實信息去回答我們的問題。
舉個例子,比如底下圖片中間有兩張是小朋友的,計算機視覺看到這張圖片的時候它要把其中所有的對象全部分割出來,要了解每個對象是什么,知道它們其中的聯系。比如左邊的小朋友在喝奶,如果把他的奶瓶分出來以后,它必須要知道這個小朋友在喝奶,這個關系也是很重要的。
屏幕上的問題是“Where is the child sitting?”,這個問題的復雜度就比單純的只是解析圖像要復雜的多。他需要把里面所有信息的全部解析出來,并且能準確的去關聯他們的關系,同時這個模型還要能夠理解我們問這個問題到底是什么個用意,他要知道問的是位置,而且這個對象是這個小孩,所以這個是包含著計算機視覺加上自然語言識別,兩種這種技術的相結合,所以才叫多模態問題,模態指的是像語音,文字,圖像,語音,這種幾種模態放在一起就叫多模態問題。
右邊一個例子是 Caption Generation,現在非常流行的研究的領域,給定一張圖片,然后對圖片里面的東西進行描述,這個還有一些更有趣的應用,待會我會詳細介紹一下。
▌三、曾經的圖像處理——傳統方法

接下來我們聊一聊,過去了很多年,大家積累的傳統的計算機視覺的圖像處理的方法。
首先提到幾個濾波器,包括空間濾波器,傅里葉、小波濾波器等等,這些都是我們經常對圖像進行初期的處理使用的濾波器。一般情況下,經過濾波以后,我們會對圖像進行 Feature Design,就是我們要從圖片中提取一些我們覺得比較重要的,可以用來做進一步的處理的一些參照的一個信息,然后利用信息進行分類,或者分割等等,這些應用,其中一些比較經典的一些方法,包括 SIFT、Symmetry、HOG,還有一些就是我們分類會經常用到的一個算法,包括 SVM,AdaBoost,還有 Bayesian 等等。
進一步的分割還有對象檢測還有一些經典算法,包括 Water-shed、Level-set、Active shape 等。

首先我們做 Feature Design,提取一個圖片中間對象的特點,最簡單能想到的方法,就是把這個對象的邊緣給分離出來,Edge Detection 也確實是很早期的圖像信息提取方法。
舉個例子,硬幣包括上面的圖案,都會經過簡單的 Edge Detection 全部提取出來,但實際上Edge Detection 在一些比較復雜的情況上面,包括背景復雜的情況下,它是會損失很多信息的,很多情況下我們看不到邊緣。
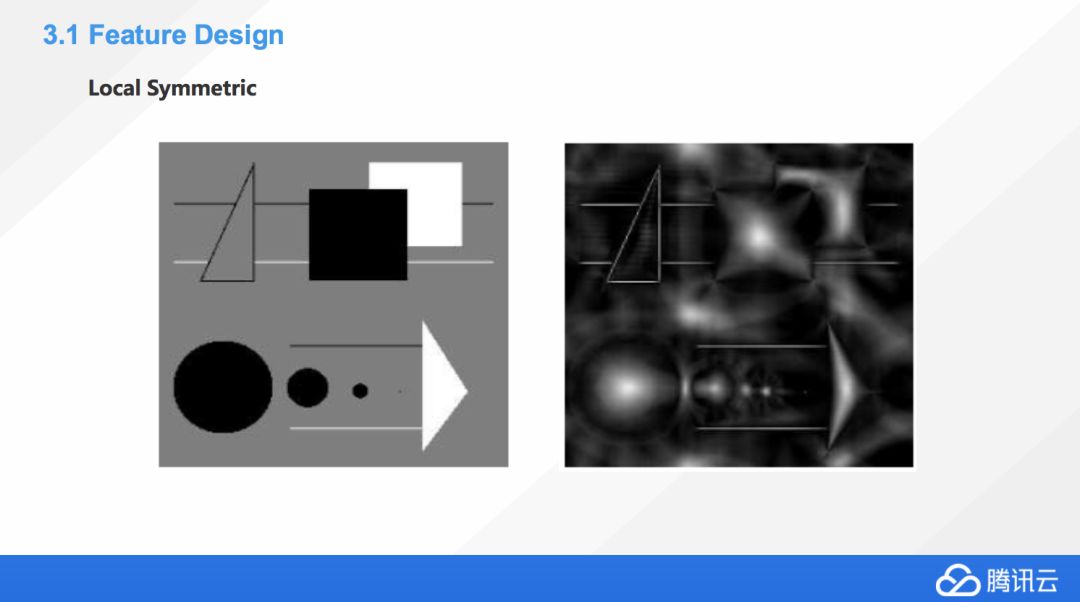
這樣情況下大家還想出另外一個方法叫 Local Symmetry,這種方法是看對象重心點,利用重心點去代表著這個圖像的一些特征。
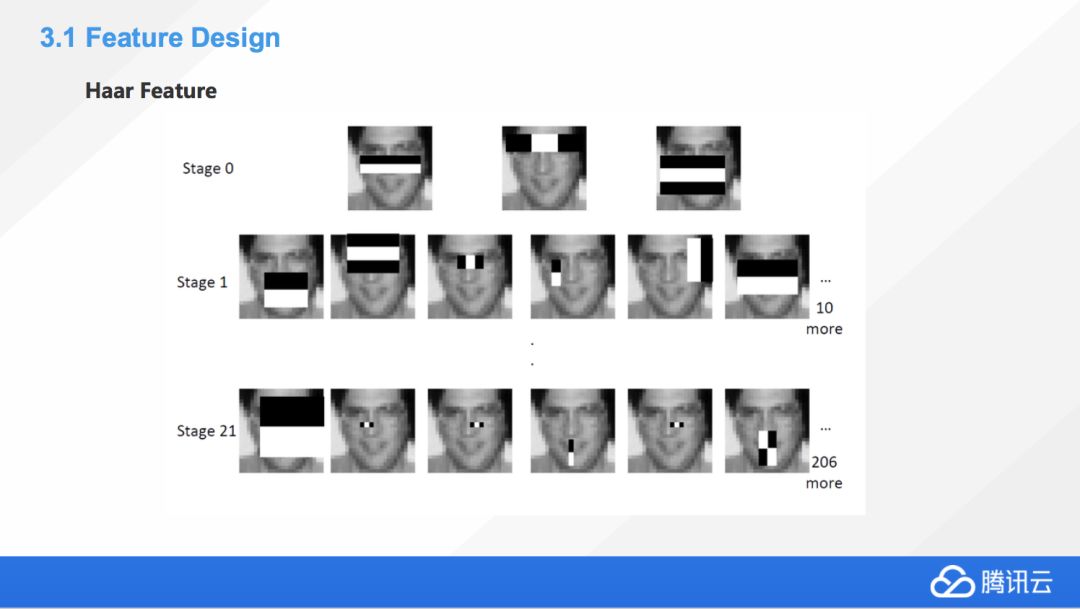
這個叫 Haar Feature,相當于結合了前面邊緣特征,還有一些其他的一些特征的信息。Haar Feature 一般分為三類
邊緣特征
線性特征
中心對角線特征
通過處理,把圖片中所有的邊緣信息提取出來以后,就會對圖片整理獲得一個特征模板,這個特征模板由白色和黑色兩種矩形組成,一般情況下定義模板的特征值為白色的矩形像素和減去黑色像素矩形像素和。Haar Feature 其實是反映了圖像的一個灰度變化的情況,所以臉部的一些特征,就可以用矩形的模板來進行表述,比如眼睛要比臉頰顏色要深,鼻梁兩側比鼻梁顏色要深,嘴巴比周圍顏色深等等。我們利用這些矩形就對圖像的一些細節進行了提取。

SIFT 尺度不變特征變換,當對象有角度、特征位置的變化時,我們如何去持續的能夠知道它們是同樣的一個東西,這個就要利用到 SIFT。SIFT 是一種局部檢測的特征算法,這個算法是通過求圖片中的一些特征點,對圖像進行匹配,這是非常老的一個算法,大概在 2000 年時候就提出來了,目前已經是一個常用的非深度學習的一個圖像的一種匹配的算法。

另外一個比較流行的方法叫 HOG 方向梯度直方圖,比如像這張圖片上顯示,在圖像中間,局部目標的表象和形狀能夠對灰度的梯度、還有邊緣方向的密度有很好的表示。比如像這張圖像,人身上的梯度就是向著上下方向。而對于背景,由于背景光的原因,如果我們做灰度的分析,會發現它的梯度是偏水平方向的,利用這種方式我們就很容易的可以把背景跟前景進行分割。另外如果很多小框里的梯度方向幾乎一致的話,我們就可以認為它是一個對象,這個方法是很好的可以塑造一個分割的效果。實際上很早期的目標檢測就是 Feature Design,所以說檢測是基于分類的,也是這個意思。現在深度學習引入以后,很多理論也發生了一些變化,待會詳細介紹一下。
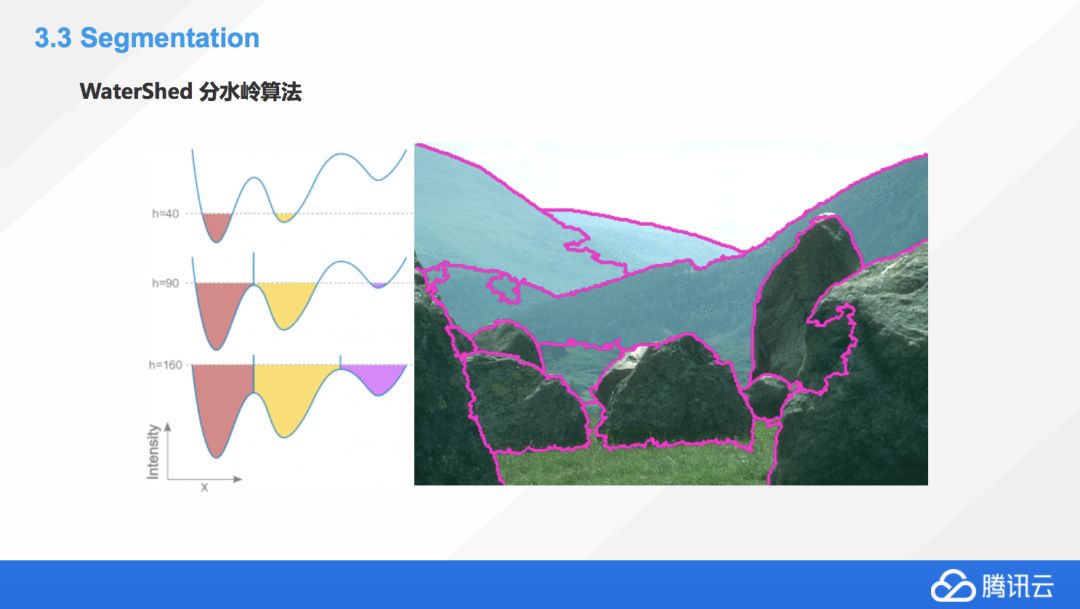
這個也是一個非常經典的分割方法,叫分水嶺算法,就是把這個圖像想象成一個地理上的地形圖,然后我們對其中的各個山谷非常無差別的統一往里面放水,總會有一些山谷先被填滿漫出來,那我們為了阻隔他們水流的流動就要建一些這種堤壩,這也是分水嶺算法的名字的由來。利用這種方式,我們建壩的地方就是很好的一個圖像的分割的這種界線,大家可以想象一下,把左邊這張圖和右邊的邊界聯系起來,就會理解到這個算法是個非常巧妙的事。
常規的分水嶺算法還是有些缺點的,比如由于圖像上的一個噪音,經常會造成局部的一些過度分割,也會有一些圖像中的部分元素因為顏色相近不會被分割出來,所以經常會出現一些誤判,這也是分水嶺算法的一些局限性。

ASM,中文名叫可變模板匹配,或者叫主觀形狀模型。這個翻譯聽起來都怪怪的,其實很好理解,它是對人臉上的一些特征進行提取,采用的方式是在人臉上尋找一些邊角的地方進行繪點,一般繪制大概 68 個關鍵特征點。然后利用這些特征點,我們去抽取一個原始的模型出來。
原始的模型抽出來之后,是不是能直接用呢?沒有那么簡單,因為人臉有可能會由于角度變化會發生一些形變,如果只是單純的對比這 68 個點,是不是在新的圖片上面還有同樣的位置,大部分情況都是 No。這時我們要對這些特征點進行一些向量的構建,我們把那 68 個點提取出來,把它向量化,同時我們對我們需要比對的點,比對的那個臉部也進行同樣的工作,也把它向量化。然后我們對原始圖片上的這種向量點和新圖片上的點進行簡單化匹配,可以通過旋轉縮放水平位移,還有垂直位移這種方式,尋找到一個等式,讓它們盡量的相等,最后優化的不能再優化的時候,就去比較閾值的大小,如果它小于某個閾值,這樣人臉就能匹配上,這個想法還是比較有意思的。
另外,在這里由于 68 個點可能比較多,很久以前我們的這種計算機的性能可能沒有那么好,也沒有 GPU,我們如果寫的時候為了提高匹配的速度,就要想個辦法去降低需要比對特征點的量,這個時候引出一個比較著名的算法叫主成分分析,利用這個 PC,我們會做降維,比如一些沒有太大意義的點可以去掉,減少數據量,減少運算量,提高效果,當然這并不是必須的,它只是一個提升 ASM 實際效能的加分辦法。
▌四、圖像處理的爆發——深度學習方法
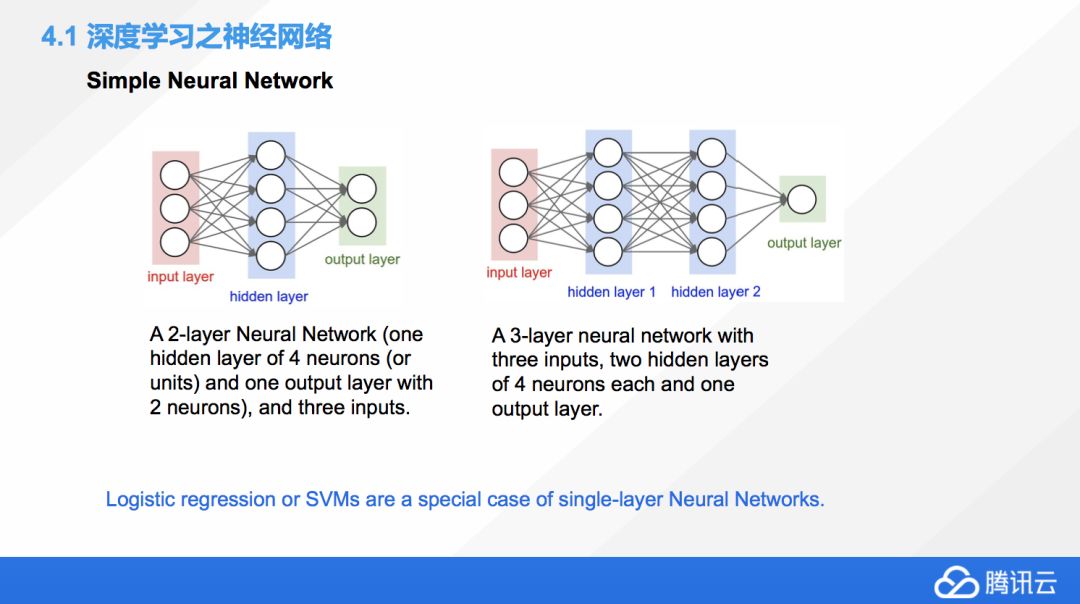
然后接下來我們就聊一聊現在非常熱門,未來也會更加熱門的圖形學的深度學習方法。下面有兩個深度學習的網絡,所謂的深度學習實際就是深度神經網絡,叫深度神經網絡大家更容易理解。左邊那個是一個兩層的神經網絡,這里要解釋一下,我們一般說神經網絡的層數是不算輸入層的,兩層就是包括一個輸入層,一個隱層,和一個輸出層。所以有的時候,如果我們提到了一個單層網絡,其實就是只有輸入層和輸出層,大家知道這種情況下面的淺度神經網絡是什么?它就是我們傳統的機器學習里非常經典的邏輯回歸和支持向量機。
這時候你會發現,深度學習并沒有那么遙不可及,它其實跟我們傳統的一些方法是有聯系的。它只是多重的一種包裝,或者組合強化,然后反復利用,最后打包成了一個新的機器學習的方法。
圖上有兩個神經網絡,其中有些共同點,首先他們都有一個輸入層,一個輸出層。這個就是所有的神經網絡必須的,中間的隱層才是真正的不同的地方,不同的網絡為了解決不同的問題,它就會有不同的隱層。
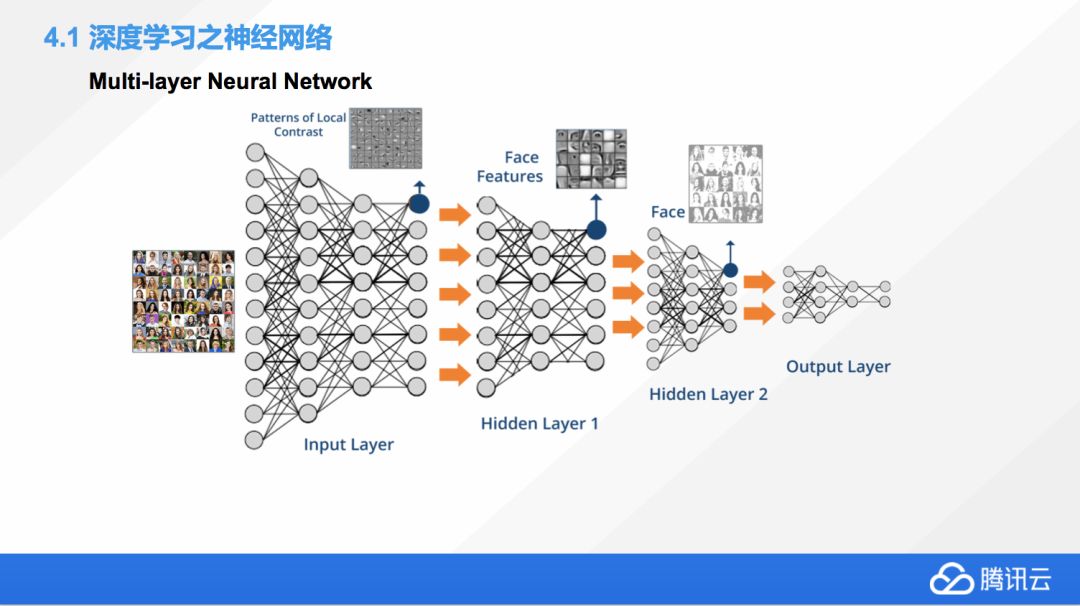
這個是對多重人臉識別設計的一個深度神經網絡,我們可以看到輸入層中間會做一些預處理,包括把圖片轉換成一些對比度圖。第一個隱層是 Face Features,從人臉上提取關鍵的特征值。第二個隱層就是開始做特征值匹配,最后的輸出層就是對結果進行輸出,一般就是分類。
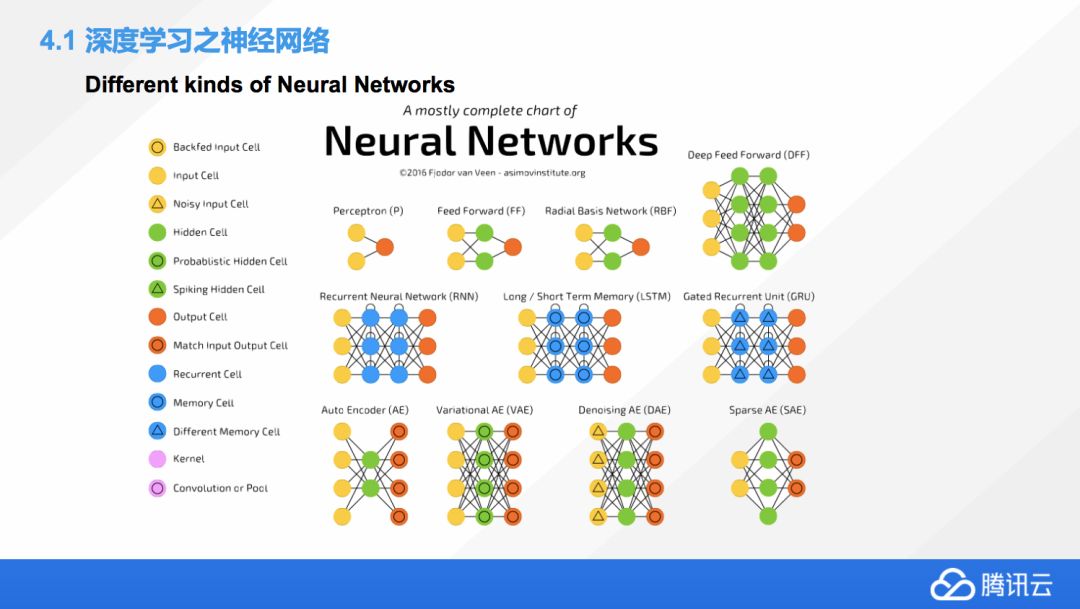
除了剛才我們看到的典型神經網絡,還會有其他各式各樣的網絡?有三角形,也有矩形的,矩形中間還有菱形的。神經網絡出現了以后,改變了大家的一些工作方式。之前,大部分機器學習的科學家是去選擇模型,然后選擇模型優化的方式。到了深度學習領域,大家考慮的是我們使用什么網絡來實現我們的目的,實際上還是區別比較大的。
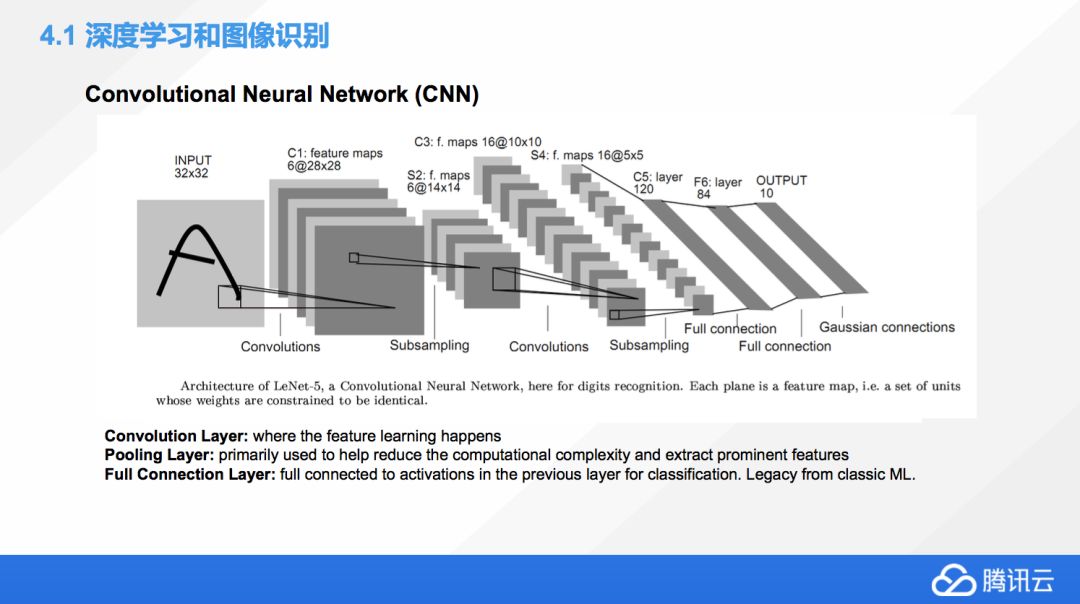
CNN,也就是卷積神經網絡,它是目前應用最廣泛的圖像識別網絡,了解 CNN 會對了解其他網絡有很大的幫助,所以把這個作為例子。
這個例子中我們做了一個手寫識別,這里包含輸入層、輸出層,還有卷積層、池化層。一般情況下,不僅僅做一次卷積,我們還會多次的做卷積,池化然后再卷積,利用這種方式去多次的降維,池化層其實在這個卷積神經網絡中起一個作用,就是降低我們數據的維度。
最后會有一個叫全連接層,它是個歷史遺留物,現在大家其實慢慢的也在減少使用全連接層,全連接層一般情況下,它的作用就是對前面的各種池化卷積最后的結果進行一個歸類。而實際上現在深度學習比較講究端對端學習,又講究效率比較高,這種情況下面,有的時候全連接層的意義就不是那么大,因為這個分類有可能在卷積的時候就把它做了,其實這個里面還是有很多的可以提升的地方。
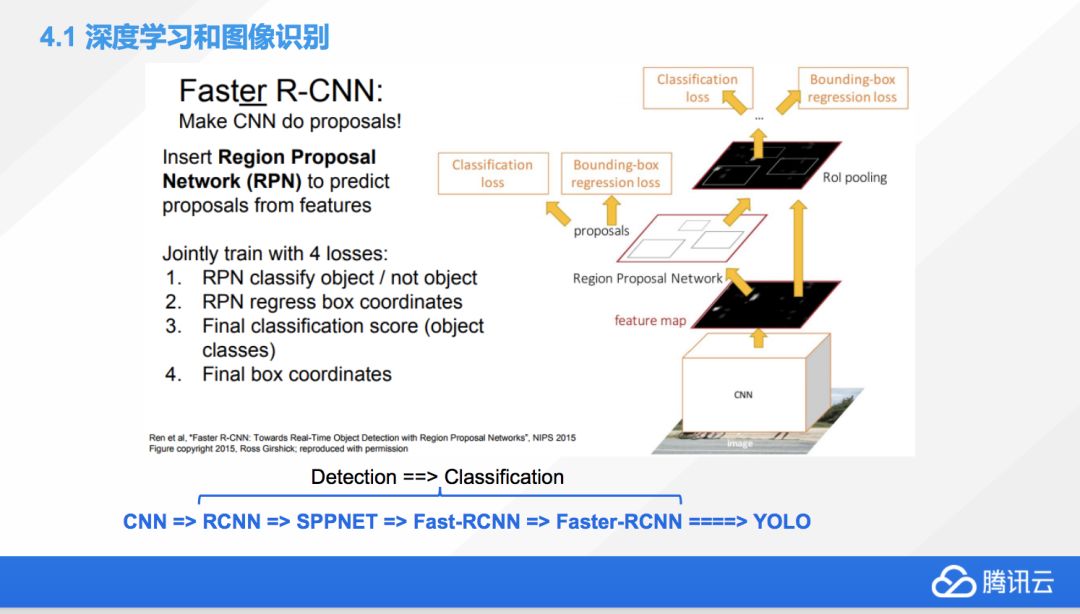
再舉一個例子,目前比較流行的做圖像分割的還有很多基于 CNN 的新網絡。比如在 CNN 基礎上大家又加入了一個叫 Region Proposal Network 的東西,利用它們可以去優化傳統 CNN 中間的一些數據的走向。Faster-RCNN 不是一蹴而就的,它是從RCNN中借鑒了 SPPNET 的一些特性,然后發明了 Fast-RCNN,又在 Fast-RCNN 的基礎上進一步的優化變成了 Faster-RCNN。
大家能看到,神經網絡也不是一成不變的,它也是不斷在進化的,而我們最開始想到用神經網絡去解決圖像問題的時候,是由于什么原因?是由于當時我們在嘗試去用 CNN 去做圖像檢測的時候發現了很大的困難,效果不好,這時就有非常厲害的科學家想了,我們可不可以把一個非常典型的檢測問題變為分類問題,因為 CNN 用來解決分類問題是非常有效的,所以就會出現很多的這樣的轉換應用。我上面寫的每一個網絡都是一篇非常偉大的論文,所以大家如果有興趣,我課后可以分享一下。
目前除了 Faster-RCNN,還有一個應用效果非常好的一個網絡結構,叫 YOLO,它也是在 Faster-RCNN 上面,已經不僅僅是進行了優化,而是改變了它的思維模式。最開始,我們覺得檢測如果轉化成分類會效果更好,后來發明 Faster-RCNN 的這個科學家覺得,有的時候可能還是用回歸的方式去解決目標檢測的問題效果會更好,他最后就搬出了 YOLO 這種新的神經網絡框架,從而重新返回到了用回歸的方式去解決目標檢測問題的方式上來。
有的時候也并不是說解決同樣一個問題是有不同方法,也并不是說在一條路上一直走到黑是最好,換個思維方式,在硬件和軟件條件達到一個新的層次的時候,有些已經用不了的技術現在就能用了,深度學習就是這么來的。
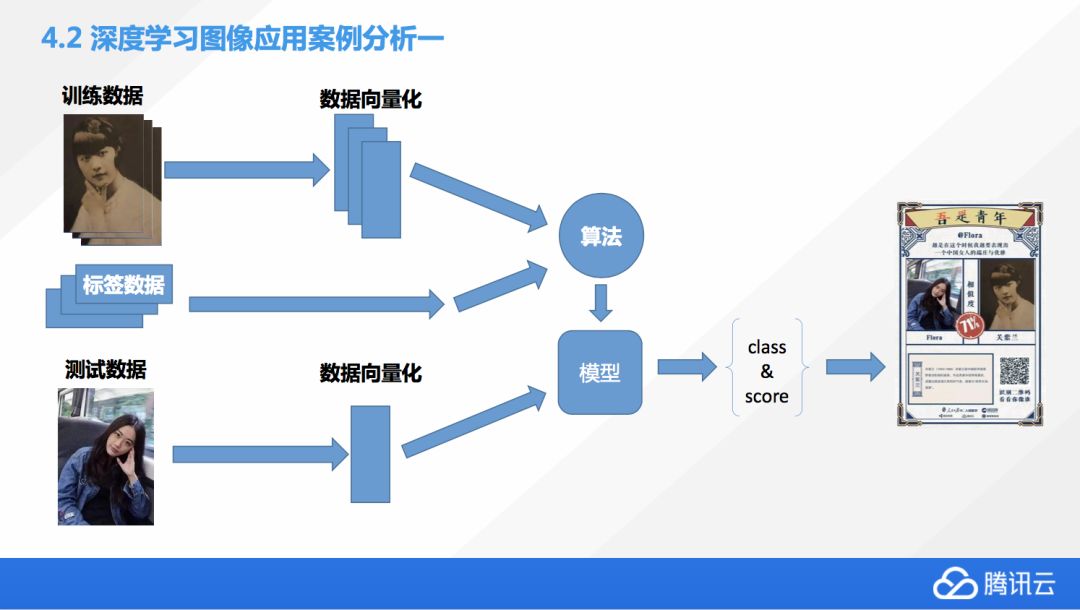
我們再聊一聊深度學習圖像應用的案例,比如說我們提到的這個五四青年節活動,它是怎么樣去設計的。首先呢,我們會有一些圖片的訓練數據,然后在進入模型之前,我們會對數據進行向量化,通過數據向量化,我們就可以得到一個模型,然后得到一個分類,和一個 score,這邊的 score 只是模型對這種結果一個相對的分析,一般我們會選擇 score 最高的一個分類,然后前端會從這個分類中間選擇圖片,生成H5的這個結果,大家就可以看到跟哪位歷史上的有名的青年相似了。

第二個也是多模態的例子,根據一張圖片去講一個浪漫的故事,當時我們有這個想法的原因是,我們知道現在已經有看圖出文字描述的技術,那我們能不能進一步的,讓圖片可以講故事。這樣的話,這個應用就可以幫助家里有小寶寶的人群。除了圖像識別以外,我們還進行了一些意圖的分析。

在另一方面,我們會使用一個浪漫小說的數據庫,對另外一個模型進行訓練。最后,我們根據這個圖片里面這些關健詞和它的意圖去匹配浪漫小說中間的文段,把有關的文段全部拿出來,拿出來這些文段有的是不成文章的,所以要進行下一輪的匹配,把這些文段中間的關鍵詞再去進一步的在小說庫里面去匹配,成段的文字,這就實現了一個 storyteller。
這個項目除了最先我們對圖像里面的對象識別過程使用的是監督學習,其他的都是非監督學習。這個系統是可以自然的去套用到很多不同的地方,只要換個不同的文章數據庫,它就可以講不同的故事。一些例子就是根據不同的圖片,比如左上角這張是我覺得分數最高的:有一個女性在沙灘上面走路,經過我們的模型就輸出了一個非常浪漫的故事,基本上符合這個情景。
▌五、解析云端AI能力支撐
我們聊了很多計算機視覺圖像處理的一些算法,我們是不是下一步還要考慮怎么樣把這個算法落地,變成一個有趣的產品或者活動呢?如果是這樣,我們需要一些什么樣的能力呢?
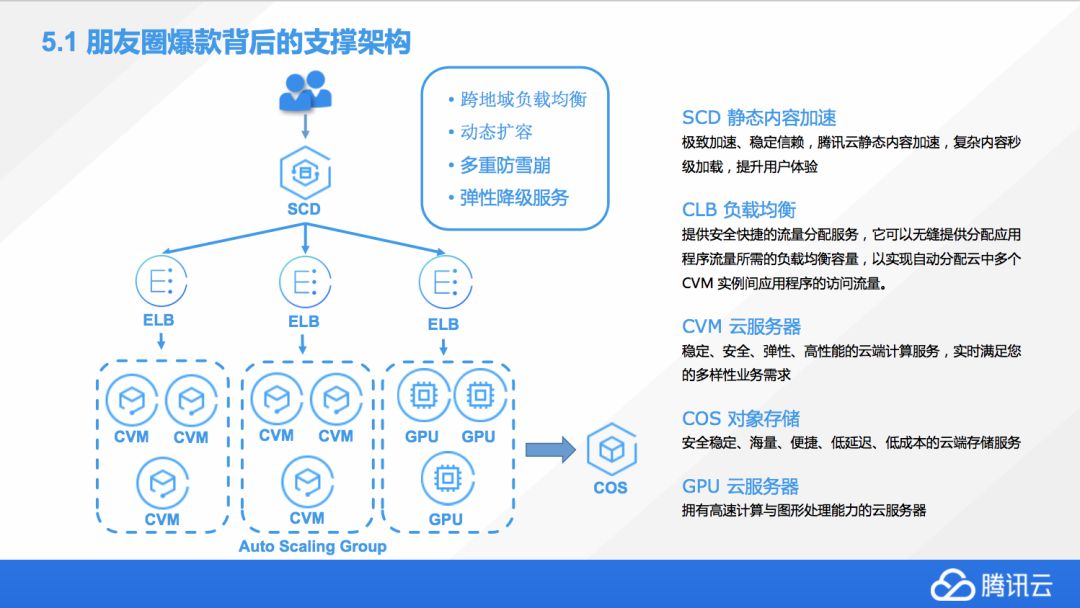
我們需要一個這樣的架構,比如像這次軍裝照活動,我們會有非常高的訪問量,同時呢,它會有遍布全國的用戶,整體上來說,我們首先要保證這個系統能穩定和彈性伸縮,然而由于所有的機器都是有成本的,這里我們就要考慮到一個平衡,如何很好的高效承載服務的同時,又要保證這個系統能夠足夠的穩定?
在這個活動背后,我們使用了很多的騰訊云的一些服務,包括靜態加速、負載均衡、云服務器、對象存儲,還有一些 GPU 計算。后來發現 CPU 的性能是能夠滿足我們的需求的,所以之后我們 GPU 就沒有上,因為 CPU 的承載還是比較高的,但實際上這一套流程是完全都是可以這么運行的。一般情況下,我們會先用 SCD,里面的 CDM 去做一個靜態的緩存,到離用戶最近的節點,這樣大家在訪問 H5 頁面的時候就不會等著圖片慢慢加載,因為它會在離你家最近的某一個數據中心里一次性的把它給到手機的客戶端上。
然后就到負載均衡器,就是把流量負載到背后海量的虛擬機上面。在不同的區域,比如北京會有,成都會有多個 ELB……這個 ELB 會掛載著很多個不同的 CVM,就是虛擬機,所有這些大家上傳的照片,匹配運算都是在每個 CVM 上面去產生結果的,然后有些過程的信息,我們也會存在 COS 上,這個 COS 存儲是沒有大小限制的,這樣多種需求都可以得到滿足。
這套機制目前證明是非常有效的,我們將來的很多的活動會繼續在架構上面做一些優化。如果你有一個很好的想法或模型要去實現,也是可以嘗試使用一下云服務,這樣是最經濟和高效的。
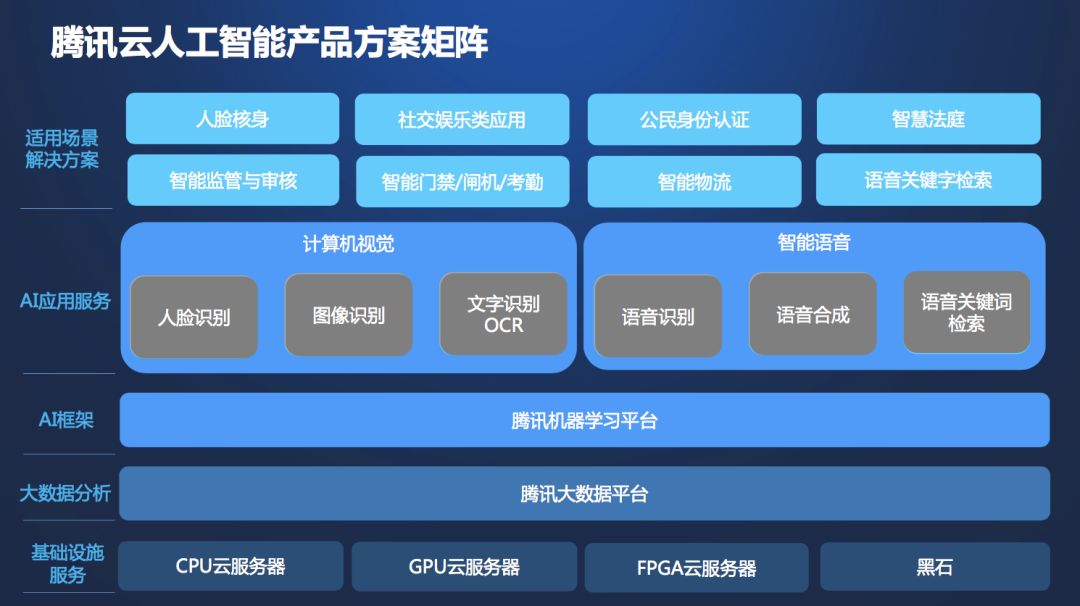
騰訊云人工智能產品方案矩陣
▌六、技能進階建議

最后我們聊一聊技能進階的一些建議,如果我們在 AI 這個方向上想有所進步的話,我們應該怎么做?右邊有個金字塔,它表示我們要完成一個 AI 的產品,我們需要的人力的數量,AI 算法這塊可能是很核心的,但它需要的人數相對來說比較少一點。共同實現是中間的,你需要多一些的底層開發。由于同樣一個算法模型,你可能會海量的應用,產品開發應用這個需要的人力的數量是最大的。
算法研究方面我們要做什么?首先是要打好比較強的數學基礎。因為機器學習中間大量的用到了比大學高等數學更復雜的數學知識,這些知識需要大家早做研究打好基礎,這就需要讀很多論文。同時還要鍛煉自己對新的學術成果的理解和吸收能力,像剛才提到了一個神經網絡圖像的分類問題,實際上,短短的十年時間實現了那么多不同網絡的進化,每一個新的網絡提出了,甚至還沒有發表,只是在預發表庫里面,大家就要很快的去吸收理解它,想把它轉化成可以運行的模型,這個是要反復鍛煉的。
第二塊是工程實現方面,如果想從事這方面首先要加強自己邏輯算法封裝的能力,盡量鍛煉自己對模型的訓練和優化能力,這塊會需要大家把一個設計好的算法給落實到代碼上,不斷的去調整優化實現最好的結果,這個過程也是需要反復磨煉的。
最后一個方向是產品應用,這個首先大家要有一定的開發能力,不管是移動開發還是 Web 開發,同時要提升自己 AI 產品場景的理解和應用。實際上很多AI產品跟傳統的產品是有很大的理解上的區別,大家可能要更新自己的這種想法,多去看一些 AI 產品目前是怎么做的,有沒有好的點子,多去試用體會。同時如果我們想把一個 AI 的模型變成百萬級、千萬級用戶使用的流行產品,我們還需要有系統構建能力和優化能力。

計算機視覺學習資源
-
計算機視覺
+關注
關注
8文章
1696瀏覽量
45930 -
深度學習
+關注
關注
73文章
5493瀏覽量
120999
原文標題:從零到一學習計算機視覺:朋友圈爆款背后的計算機視覺技術與應用 | 公開課筆記
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是計算機視覺?計算機視覺的三種方法








 工商網監
工商網監
評論