 基于yolo算法進行改進的高效衛星圖像目標檢測算法
基于yolo算法進行改進的高效衛星圖像目標檢測算法
衛星圖像是十分重要的資源,可以通過它計量國土資源,檢測地面情況并且能高瞻遠矚的記錄地表發生的變化。但由于衛星圖像十分巨大而且其中的物體相對較小,利用衛星圖像進行目標檢測是充滿挑戰的工作,本文主要講解了一篇基于yolo算法進行改進的高效衛星圖像目標檢測算法,主要針對高分辨率輸入和密集小物體進行了優化。
在大面積的圖像中識別出一系列小物體是衛星圖像處理的主要任務之一。近年來基于深度學習的目標檢測算法有了很大的效率提升,但基于衛星圖像的處理還存在這一系列問題。為了解決這一系列調整,研究人員在YOLO的基礎上提出了一種兩階段的算法架構,不僅可以適應多尺度的檢測,同時達到了F1>0.8的結果,最后還探究了分辨率和物體大小對于檢測的影響,并發現只需要五個像素的大小就可以實現目標檢測。文章主要從深度學習對于衛星圖像目標檢測的缺陷出發,提出了改進的細粒度的目標檢測網絡結構。同時為了解決檢測不變性的問題進行了大量的數據增強。
1. 衛星圖像目標檢測存在的問題
高分辨率的衛星圖像和相對較小的圖內物體使得衛星圖像處理目前主要面臨以下四個方面的挑戰:
空間范圍較小:在衛星圖像中,感興趣的物體相對尺寸都很小而且常常聚攏在一起,與ImageNet數據集中大范圍的顯著物體大不相同。同時物體的分辨率主要由地面采樣距離決定,它定義了每個像素對應的物理長度。通常情況下衛星運行的高度是350km左右,最清晰的商用衛星圖像可以達到30cm的GSD(每個像素對應30cm),而普通的數字衛星影響只能達到3-4m的分辨率了。所以對于車輛、船只這樣的小物體來說可能只有10多個像素來描述;
衛星圖像中的物體具有各個方位的朝向,而ImageNet數據集中大多是豎直方向的,需要檢測器具有旋轉不變性;
訓練數據的缺乏,對于衛星圖像缺乏高質量的訓練數據,雖然SpaceNet已經進行了一系列有益的工作,但還需要進一步改進;
極高的圖像分辨率,與通常輸入的小圖片不同,衛星圖像動輒上億像素,簡單的將采樣方法對于衛星圖像處理無法適用。
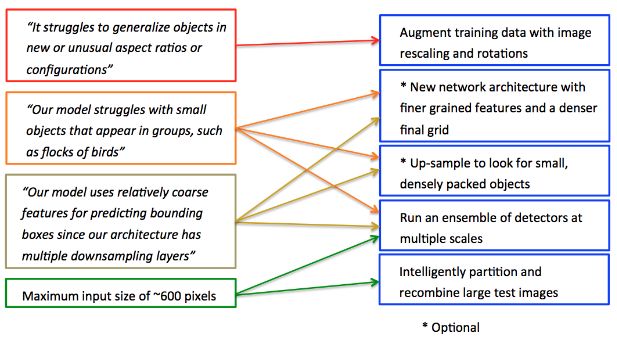
在過去的幾年里深度學習早已成為目標檢測的重要工具,但卻還有一系列問題有待優化。比如像鳥群一樣的密集小物體檢測是目前需要解決的挑戰。這主要是由于卷積神經網絡中一系列降采樣操作造成的,如果目標僅僅包含很少的像素數目,這種方法會造成很大的問題。例如在yolo中降采樣因子是32同時返回13*13的預測柵格,這意味著如果一個某個物體的像素少于32個就會引起嚴重的問題。
研究人員為了解決這個問題對YOLO的網絡架構進行了改造,加密了最后預測輸出的柵格數量,從而提高了網絡對于細粒度特征的檢測結果以及區分不同物體的能力,改善了對于小物體和密集物體群的檢測。
同時目標檢測算法對于不常見的的比例或新的圖像分布缺乏一定的泛化能力。由于物體可能的方向和尺寸比例各不相同,算法有限的比例變化對于特殊目標的檢測就會失效。為了解決這一問題,研究人員對數據進行了旋轉和HSV的隨機增強,是算法對于不同傳感器、大氣條件和光照條件具有更強的魯棒性。
目前先進的目標檢測算法都是對整幅圖像進行處理的,但對于上億像素的衛星圖像來說,很難有硬件顯卡內存可以滿足如此大的需求。為了解決對于多尺度目標的高速檢測,研究人員提出了利用區域圖像作為輸入,利用多尺度檢測其來進性檢測的方法。在實際過程中,大概200m尺度的圖像片作為輸入,并利用一定的上采樣進行處理。
下圖中對比了原始圖像和其中的圖像片輸入網絡后的結果。全尺寸的網絡幾乎無法得到任何結果(下采樣后圖片分辨率損失),而圖像片(像素數小于32)得到的結果也不盡如人意。
2. 算法與網絡架構
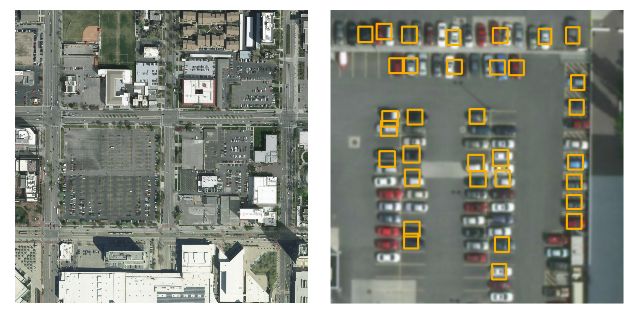
首先研究人員們對算法架構進行了改造,將網絡結構改成了22層和16的降采樣因子,416*416的像素輸入后能得到26*26的輸出柵格,通過這樣的技術來優化網絡對于小物體、密集排布的檢測效果。更密集的預測柵格對于停車場車輛和碼頭船只的檢測十分重要。同時為了提高小物體的保真度,引入了一個直通層將最后52*52的直通層和最后一個卷基層進行組合,使得檢測器可以通過拓展特組圖發現更多細粒度的特征。
卷積網絡中的神經元都使用批量歸一化和LeakyRelu激活,最后一層使用線性激活函數。最后輸出的結果N=Nboxes*(Nclass+5),每一個bbox包含四個坐標和一個包含物體的概率,以及屬于每類物體的概率。
3. 訓練數據
由于在衛星圖像處理中,主要關注飛機、輪船、建筑平面、汽車和機場,它們的尺度各不相同。研究人員訓練了兩個不同尺度的檢測器來進行目標檢測。
- 汽車數據集使用了COWC數據集,基于15cm的GSD尺度。為了與目前商用衛星圖像的30cm尺度一致,利用高斯核對圖像進性了處理,并在30cmGSD的尺度上為每輛車標注3m的邊框,共13303個樣本;
- 建筑平面基于SpaceNet的數據在30cmGSD尺度下標注了221336個樣本;
- 飛機利用八張GigitalGlobe的圖片標注了230個樣本;
- 船只利用三張GigitalGlobe的圖片標注了556個樣本;
- 機場利用37張圖片作為訓練樣本,其中包含機場跑道,并進行4比例的降采樣。
訓練過程中使用了NVIDIA Titan X GPU,學習率0.001,權重衰減0.0005,動量0.9。
4. 測試
為了對測試圖像的結果,研究人員們使用智能圖像分割將原始圖像按照15%的重疊率切分成一系列子圖,并按照如下的格式進行位置標注:
ImageName|row_column_height_width.ext

將每一張圖像送入模型后,得到的結果再更具上面的位置標記恢復到完整的圖像中顯示。
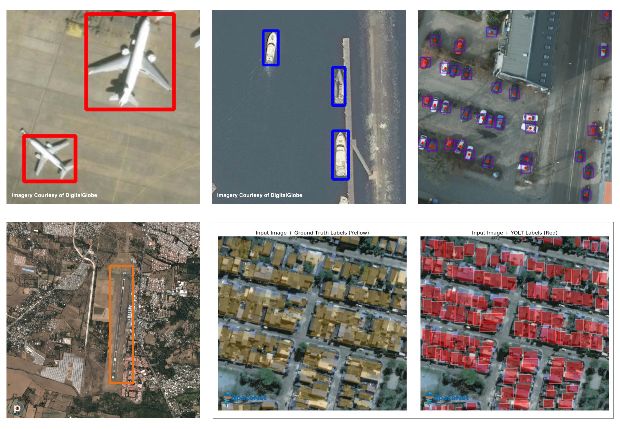
最終的檢測結果如下圖所示:
街區內測車輛檢測結果
飛機和輪船的檢測結果
目前一分鐘可以處理30平方千米的圖像,對于機場這樣的大尺度對象來說可以除了6000平方公里。未來如果用16GPU集群可以實現實時的衛星圖像目標檢測。
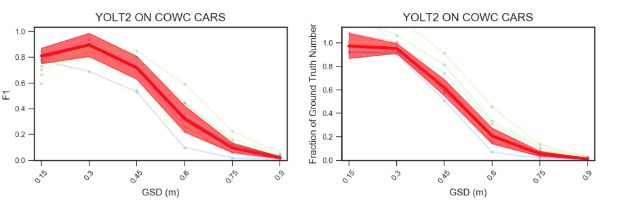
同時研究人員還探索了分辨率隨檢測準確率的關系,發現分辨率越高圖像的準確率越高
想上手嘗試一下的小伙伴,github上有docker封裝好的代碼,上手即用:
https://github.com/CosmiQ/yolt
最后再來欣賞幾幅檢測后的漂亮的衛星圖像:
-
算法
+關注
關注
23文章
4601瀏覽量
92671 -
衛星
+關注
關注
18文章
1703瀏覽量
66913 -
深度學習
+關注
關注
73文章
5493瀏覽量
120998
原文標題:You Only Look Twice:揭秘高速衛星圖像目標檢測系統
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
人臉檢測算法及新的快速算法
基于Canny檢測算法實現的目標跟蹤
基于Surendra改進的運動目標檢測算法
如何使用Zynq SoC硬件加速實現改進TINY YOLO實時車輛檢測的算法
基于深度學習YOLO系列算法的圖像檢測
基于改進YOLOv3的行人車輛目標檢測算法
一種改進的高光譜圖像CEM目標檢測算法






 工商網監
工商網監
評論