 行人檢測算法的發展歷程
行人檢測算法的發展歷程
導言
行人檢測是計算機視覺中的經典問題,也是長期以來難以解決的問題。和人臉檢測問題相比,由于人體的姿態復雜,變形更大,附著物和遮擋等問題更嚴重,因此準確的檢測處于各種場景下的行人具有很大的難度。在本文中,SIGAI將為大家回顧行人檢測算法的發展歷程。
問題描述
行人檢測( Pedestrian Detection)一直是計算機視覺研究中的熱點和難點。行人檢測要解決的問題是:找出圖像或視頻幀中所有的行人,包括位置和大小,一般用矩形框表示,和人臉檢測類似,這也是典型的目標檢測問題。
行人檢測技術有很強的使用價值,它可以與行人跟蹤,行人重識別等技術結合,應用于汽車無人駕駛系統(ADAS),智能機器人,智能視頻監控,人體行為分析,客流統計系統,智能交通等領域。
由于人體具有相當的柔性,因此會有各種姿態和形狀,其外觀受穿著,姿態,視角等影響非常大,另外還面臨著遮擋 、光照等因素的影響,這使得行人檢測成為計算機視覺領域中一個極具挑戰性的課題。行人檢測要解決的主要難題是:
外觀差異大。包括視角,姿態,服飾和附著物,光照,成像距離等。從不同的角度看過去,行人的外觀是很不一樣的。處于不同姿態的行人,外觀差異也很大。由于人穿的衣服不同,以及打傘、戴帽子、戴圍巾、提行李等附著物的影響,外觀差異也非常大。光照的差異也導致了一些困難。遠距離的人體和近距離的人體,在外觀上差別也非常大。
遮擋問題。在很多應用場景中,行人非常密集,存在嚴重的遮擋,我們只能看到人體的一部分,這對檢測算法帶來了嚴重的挑戰。
背景復雜。無論是室內還是室外,行人檢測一般面臨的背景都非常復雜,有些物體的外觀和形狀、顏色、紋理很像人體,導致算法無法準確的區分。
檢測速度。行人檢測一般采用了復雜的模型,運算量相當大,要達到實時非常困難,一般需要大量的優化。
從下面這張圖就可以看出行人檢測算法所面臨的挑戰:
早期的算法使用了圖像處理,模式識別中的一些簡單方法,準確率低。隨著訓練樣本規模的增大,如INRIA數據庫、Caltech數據庫和TUD行人數據庫等的出現,出現了精度越來越高的算法,另一方面,算法的運行速度也被不斷提升。按照實現原理,我們可以將這些算法可以分為基于運動檢測的算法和基于機器學習的算法兩大類,接下來分別進行介紹。
基于運動檢測的算法
如果攝像機靜止不動,則可以利用背景建模算法提取出運動的前景目標,然后利用分類器對運動目標進行分類,判斷是否包含行人。常用的背景建模算法有:
高斯混合模型,Mixture of Gaussian model[1]
ViBe算法[2]
幀差分算法
SACON,樣本一致性建模算法[3]
PBAS算法[4]
這些背景建模算法的思路是通過前面的幀學習得到一個背景模型,然后用當前幀與背景幀進行比較,得到運動的目標,即圖像中變化的區域。

限于篇幅,我們不在這里介紹每一種背景建模算法的原理,如果有機會,SIGAI會在后續的文章中專門介紹這一問題。
背景建模算法實現簡單,速度快,但存在下列問題:
1.只能檢測運動的目標,對于靜止的目標無法處理
2.受光照變化、陰影的影響很大
3.如果目標的顏色和背景很接近,會造成漏檢和斷裂
4.容易受到惡劣天氣如雨雪,以及樹葉晃動等干擾物的影響
5.如果多個目標粘連,重疊,則無法處理
究其原因,是因為這些背景建模算法只利用了像素級的信息,沒有利用圖像中更高層的語義信息。
基于機器學習的方法
基于機器學習的方法是現階段行人檢測算法的主流,在這里我們先介紹人工特征+分類器的方案,基于深度學習的算法在下一節中單獨給出。
人體有自身的外觀特征,我們可以手工設計出特征,然后用這種特征來訓練分類器用于區分行人和背景。這些特征包括顏色,邊緣,紋理等機器學習中常用的特征,采用的分類器有神經網絡,SVM,AdaBoost,隨機森林等計算機視覺領域常用的算法。由于是檢測問題,因此一般采用滑動窗口的技術,這在SIGAI之前的公眾號文章“人臉檢測算法綜述”,“基于深度學習的目標檢測算法綜述”中已經介紹過了。
HOG+SVM
行人檢測第一個有里程碑意義的成果是Navneet Dalal在2005的CVPR中提出的基于HOG + SVM的行人檢測算法[5]。Navneet Dalal是行人檢測中之前經常使用的INRIA數據集的締造者。
梯度方向直方圖(HOG)是一種邊緣特征,它利用了邊緣的朝向和強度信息,后來被廣泛應用于車輛檢測,車牌檢測等視覺目標檢測問題。HOG的做法是固定大小的圖像先計算梯度,然后進行網格劃分,計算每個點處的梯度朝向和強度,然后形成網格內的所有像素的梯度方向分分布直方圖,最后匯總起來,形成整個直方圖特征。
這一特征很好的描述了行人的形狀、外觀信息,比Haar特征更為強大,另外,該特征對光照變化和小量的空間平移不敏感。下圖為用HOG特征進行行人檢測的流程:

得到候選區域的HOG特征后,需要利用分類器對該區域進行分類,確定是行人還是背景區域。在實現時,使用了線性支持向量機,這是因為采用非線性核的支持向量機在預測時的計算量太大,與支持向量的個數成正比。如果讀者對這一問題感興趣,可以閱讀SIGAI之前關于SVM的文章。
目前OpenCV中的行人檢測算法支持HOG+SVM以及HOG+Cascade兩種,二者都采用了滑動窗口技術,用固定大小的窗口掃描整個圖像,然后對每一個窗口進行前景和背景的二分類。為了檢測不同大小的行人,還需要對圖像進行縮放。
下面是提取出的行人的HOG特征:
HOG+AdaBoost
由于HOG + SVM的方案計算量太大,為了提高速度,后面有研究者參考了VJ[6]在人臉檢測中的分類器設計思路,將AdaBoost分類器級聯的策略應用到了人體檢測中,只是將Haar特征替換成HOG特征,因為Haar特征過于簡單,無法描述人體這種復雜形狀的目標。下圖為基于級聯Cascade分類器的檢測流程:
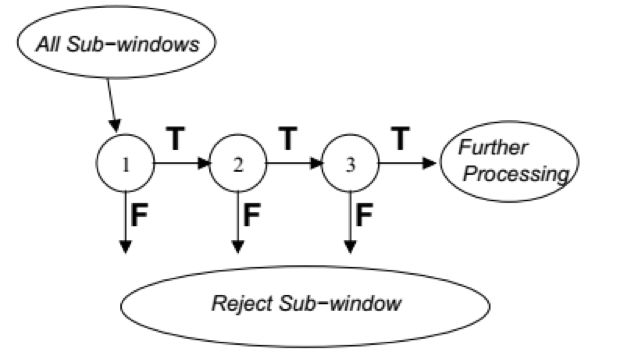
圖中每一級中的分類器都是利用AdaBoost算法學習到的一個強分類器,處于前面的幾個強分類器由于在分類器訓練的時候會優先選擇弱分類器,可以把最好的幾個弱分類器進行集成,所有只需要很少的幾個就可以達到預期效果,計算會非常簡單,速度很快,大部分背景窗口很快會被排除掉,剩下很少一部分候選區域或通過后續的幾級分類器進行判別,最終整體的檢測速度有了很大的提升,相同條件下的預測時間只有基于SVM方法的十分之一。
ICF+AdaBoost
HOG特征只關注了物體的邊緣和形狀信息,對目標的表觀信息并沒有有效利用,所以很難處理遮擋問題,而且由于梯度的性質,該特征對噪點敏感。針對這些問題后面有人提出了積分通道特征(ICF)[7],積分通道特征包括10個通道:
6 個方向的梯度直方圖,3 個LUV 顏色通道和1 梯度幅值,見下圖,這些通道可以高效計算并且捕獲輸入圖像不同的信息。
在這篇文章里,AdaBoost分類器采用了soft cascade的級聯方式。為了檢測不同大小的行人,作者并沒有進行圖像縮放然后用固定大小的分類器掃描,而是訓練了幾個典型尺度大小的分類器,對于其他尺度大小的行人,采用這些典型尺度分類器的預測結果進行插值來逼近,這樣就不用對圖像進行縮放。因為近處的行人和遠處的行人在外觀上有很大的差異,因此這樣做比直接對圖像進行縮放精度更高。這一思想在后面的文章中還得到了借鑒。通過用GPU加速,這一算法達到了實時,并且有很高的精度,是當時的巔峰之作。

DPM+ latent SVM
行人檢測中的一大難題是遮擋問題,為了解決這一問題,出現了采用部件檢測的方法,把人體分為頭肩,軀干,四肢等部分,對這些部分分別進行檢測,然后將結果組合起來,使用的典型特征依然是HOG,采用的分類器有SVM和AdaBoost。針對密集和遮擋場景下的行人檢測算法可以閱讀文獻[15]。
DPM(Deformable Parts Models)算法在SIGAI在之前的文章“基于深度學習的目標檢測算法綜述”已經提到過。這是是一種基于組件的檢測算法,DPM檢測中使用的特征是HOG,針對目標物不同部位的組建進行獨立建模。DPM中根模型和部分模型的作用,根模型(Root-Filter)主要是對物體潛在區域進行定位,獲取可能存在物體的位置,但是是否真的存在我們期望的物體,還需要結合組件模型(Part-Filter)進行計算后進一步確認,DPM的算法流程如下:
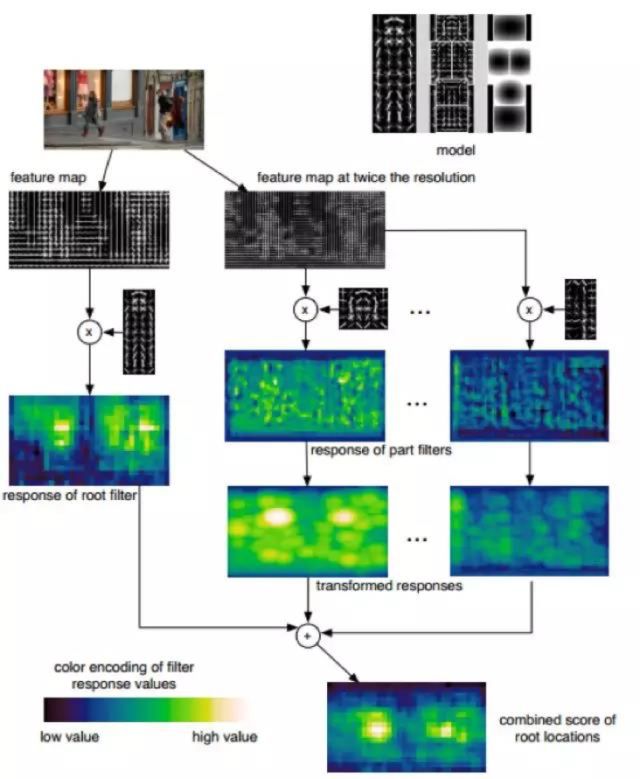
DPM算法在人體檢測中取得取得了很好的效果,主要得益于以下幾個原因:
1.基于方向梯度直方圖(HOG)的低級特征(具有較強的描述能力)
2.基于可變形組件模型的高效匹配算法
3.采用了鑒別能力很強的latent-SVM分類器
DPM算法同時存在明顯的局限性,首先,DPM特征計算復雜,計算速度慢(論文[8]中針對DPM提出了多個加速的策略,有興趣的讀者可以參考);其次,人工特征對于旋轉、拉伸、視角變化的物體檢測效果差。這些弊端很大程度上限制了算法的應用場景,這一點也是基于人工特征+分類器的通病。
采用經典機器學習的算法雖然取得了不錯的成績,但依然存在下面的問題:
1.對于外觀,視角,姿態各異的行人檢測精度還是不高
2.提取的特征在特征空間中的分布不夠緊湊
3.分類器的性能受訓練樣本的影響較大
4.離線訓練時的負樣本無法涵蓋所有真實應用場景的情況
基于機器學習的更多方法以參考綜述文章[10][18][19]。文獻[10]對常見的16種行人檢測算法進行了簡單描述,并在6個公開測試庫上進行測試,給出了各種方法的優缺點及適用情況。
文獻[18]提出了Caltech數據集,相比之前的數據集,它的規模大了2個數量級。作者在這個數據集上比較了當時的主要算法,分析了一些失敗的的原因,為后續的研究指出了方向。
文獻[19]也比較了10年以來的行人檢測算法,總結了各種改進措施,并支持了以后的研究方向。
基于深度學習的算法
基于背景建模和機器學習的方法在特定條件下可能取得較好的行人檢測效率或精確度,但還不能滿足實際應用中的要求。自從2012年深度學習技術被應用到大規模圖像分類以來[9],研究人員發現基于深度學習學到的特征具有很強層次表達能力和很好的魯棒性,可以更好的解決一些視覺問題。因此,深度卷積神經網絡被用于行人檢測問題是順理成章的事情。
SIGAI之前的文章“基于深度學習的目標檢測算法綜述”全面介紹了基于深度學習的通用目標檢測框架,如Faster-RCNN、SSD、FPN、YOLO等,這些方法都可以直接應用到行人檢測的任務中,以作者實際經驗,相比之前的SVM和AdaBoost分類器,精度有顯著的提升。小編根據Caltech行人數據集的測評指標[11],選取了幾種專門針對行人問題的深度學習解決方案進行介紹。

從上圖可以看出,行人檢測主要的方法是使用人工特征+分類器的方案,以及深度學習方案兩種類型。使用的分類器有線性支持向量機,AdaBoost,隨機森林。接下來我們重點介紹基于卷積網絡的方案。
Cascade CNN
如果直接用卷積網絡進行滑動窗口檢測,將面臨計算量太大的問題,因此必須采用優化策略。文獻[22]提出了一種用級聯的卷積網絡進行行人檢測的方案,這借鑒了AdaBoost分類器級聯的思想。前面的卷積網絡簡單,可以快速排除掉大部分背景區域:

后面的卷積網絡更復雜,用于精確的判斷一個候選窗口是否為行人,網絡結構如下圖所示:

通過這種組合,在保證檢測精度的同時極大的提高了檢測速度。這種做法和人臉檢測中的Cascade CNN類似。
JointDeep
在文獻[12]中,作者使用了一種混合的策略,以Caltech行人數據庫訓練一個卷積神經網絡的行人分類器。該分類器是作用在行人檢測的最后的一級,即對最終的候選區域做最后一關的篩選,因為這個過程的效率不足以支撐滑動窗口這樣的窮舉遍歷檢測。
作者用HOG+CSS+SVM作為第一級檢測器,進行預過濾,把它的檢測結果再使用卷積神經網絡來進一步判斷,這是一種由粗到精的策略,下圖將基于JointDeep的方法和DPM方法做了一一對應比較。
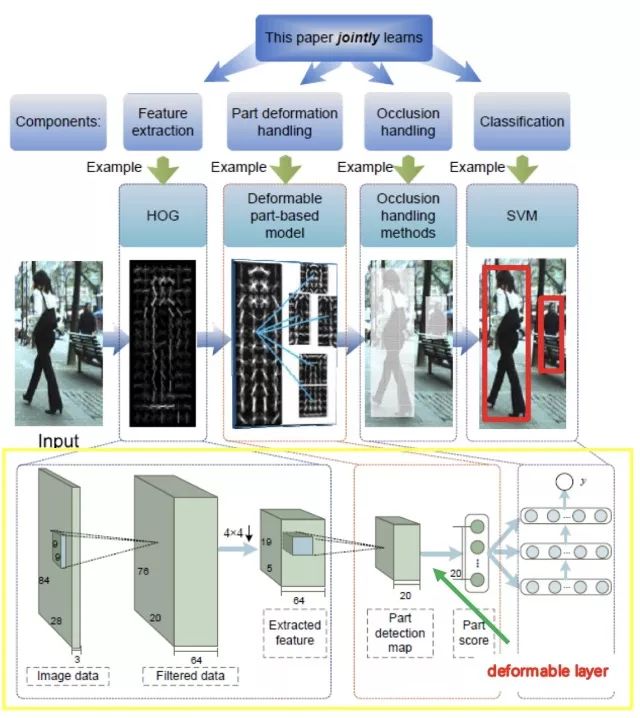
JonitDeep 網絡結構
卷積網絡的輸入并不是RGB通道的圖像,而是作者實驗給出的三個通道,第一個通道是原圖的YUV中的Y通道,第二個通道被均分為四個block,行優先時分別是U通道,V通道,Y通道和全0;第三個通道是利用Sobel算子計算的第二個通道的邊緣。
另外還采用了部件檢測的策略,由于人體的每個部件大小不一,所以作者針對不同的部件設計了大小不一的卷積核尺寸,如下圖a所示,Level1針對比較小的部件,Level2針對中等大小的部件,Level3針對大部件。由于遮擋的存在,作者同時設計了幾種遮擋的模式。
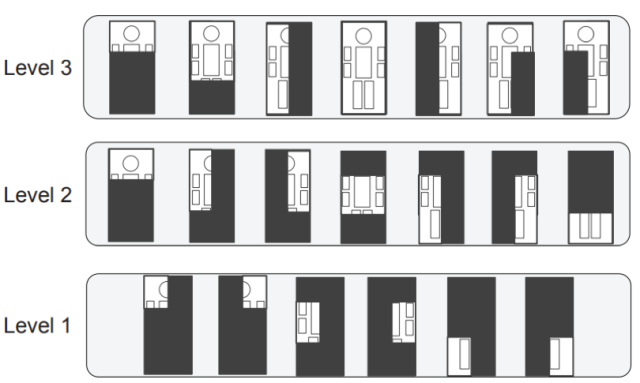
(a)
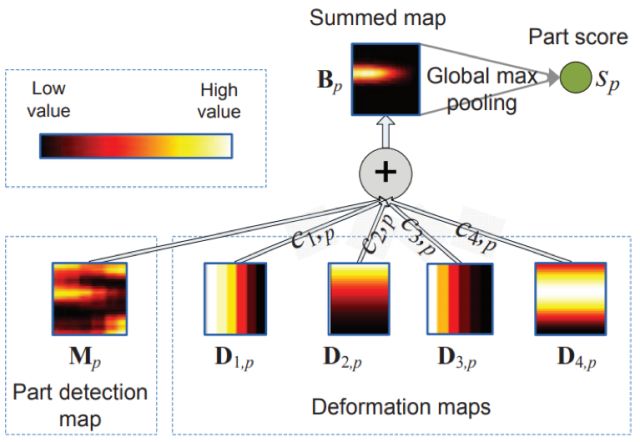
(b)
SA-FastRCNN
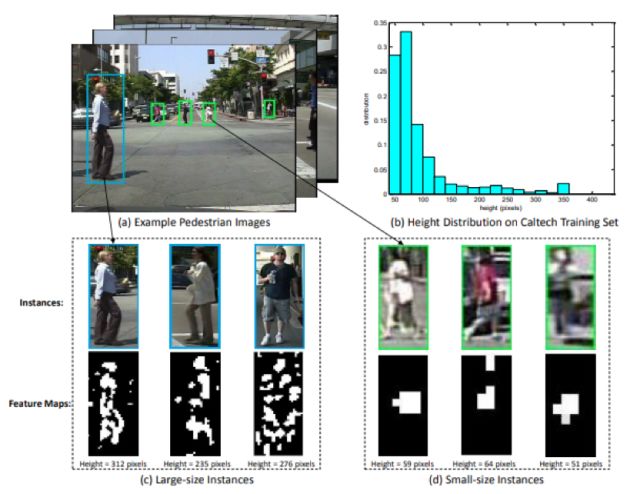
文獻[13]提出了一種稱為SA-FastRCNN的方法,作者分析了Caltech行人檢測數據庫中的數據分布,提出了以下兩個問題:
1.行人尺度問題是待解決的一個問題
2.行人檢測中有許多的小尺度物體, 與大尺度物體實例在外觀特點上非常不同
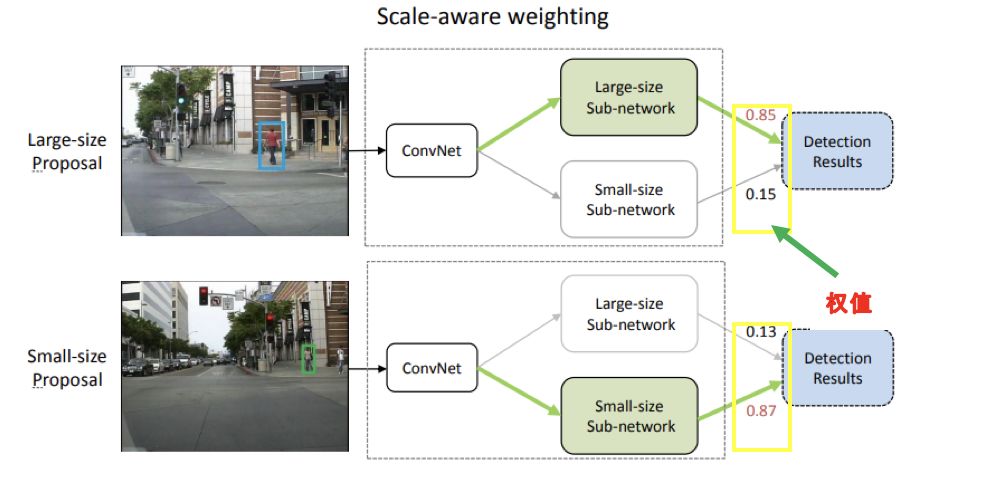
作者針對行人檢測的特點對Fast R-CNN進行了改進,由于大尺寸和小尺寸行人提取的特征顯示出顯著差異,作者分別針對大尺寸和小尺寸行人設計了2個子網絡分別進行檢測。利用訓練階段得到的scale-aware權值將一個大尺度子網絡和小尺度子網絡合并到統一的框架中,利用候選區域高度估計這兩個子網絡的scale-aware權值,論文中使用的候選區域生成方法是利用ACF檢測器提取的候選區域,總體設計思路如下圖所示:
SA-FastRCNN的架構如下圖所示:
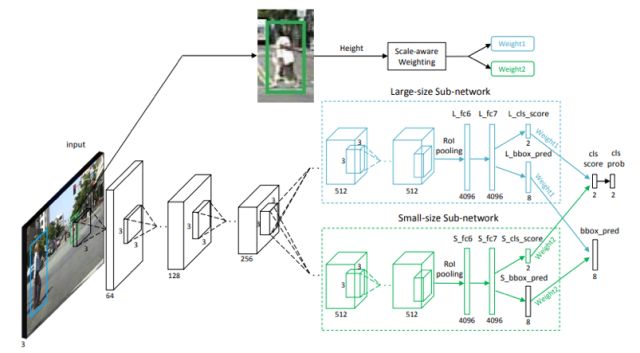
這種scale-aware加權機制可以被認為是兩個子網絡的soft-activation,并且最終結果總是可以通過適合當前輸入尺寸的子網絡提升。
Faster R-CNN
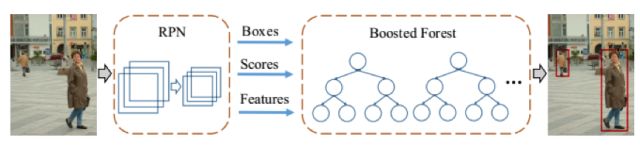
文獻[16]分析了Faster R-CNN在行人檢測問題上的表現,結果表明,直接使用這種算法進行行人檢測效果并不滿意。作者發現,Faster R-CNN中的RPN網絡對提取行人候選區域是相當有效的,而下游的檢測網絡表現的不好。作者指出了其中的兩個原因:對于小目標,卷積層給出的特征圖像太小了,無法有效的描述目標;另外,也缺乏難分的負樣本挖掘機制。作者在這里采用了一種混合的策略,用RPN提取出候選區域,然后用隨機森林對候選區域進行分類。這一結構如下圖所示:
DeepParts
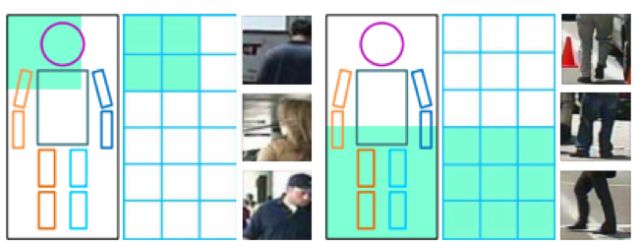
文獻[21]提出了一種基于部件的檢測方案,稱為DeepParts,致力于解決遮擋問題。這種方案將人體劃分成多個部位,分別進行檢測,然后將結果組合起來。部位劃分方案如下圖所示:
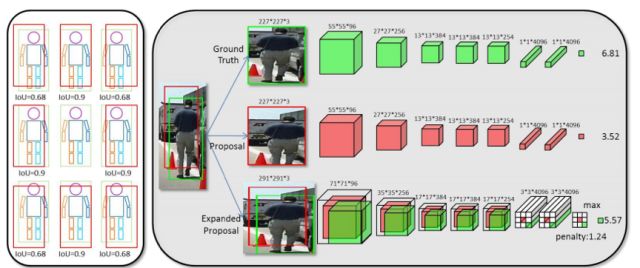
整個系統的結構如下圖所示:
RepLoss
RepLoss[14]由face++提出,主要目標是解決遮擋問題。行人檢測中,密集人群的人體檢測一直是一個難題。物體遮擋問題可以分為類內遮擋和類間遮擋兩類。類內遮擋指同類物體間相互遮擋,在行人檢測中,這種遮擋在所占比例更大,嚴重影響著行人檢測器的性能。
針對這個問題,作者設計也一種稱為RepLoss的損失函數,這是一種具有排斥力的損失函數,下圖為RepLoss示意圖:
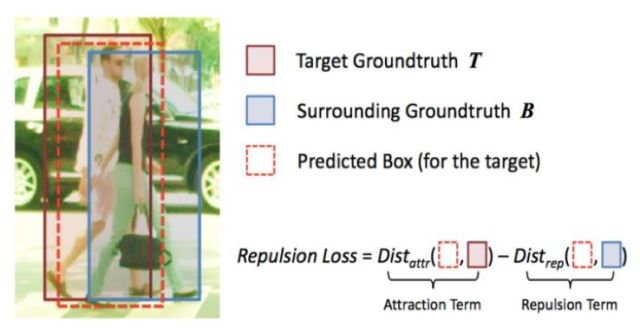
RepLoss 的組成包括 3 部分,表示為:
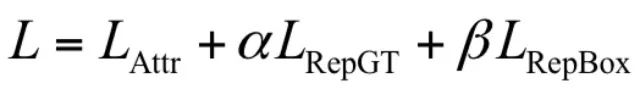
其中L_Attr 是吸引項,需要預測框靠近其指定目標;L_RepGT 和 L_RepBox 是排斥項,分別需要當前預測框遠離周圍其它的真實物體和該目標其它的預測框。系數充當權重以平衡輔助損失。
HyperLearner
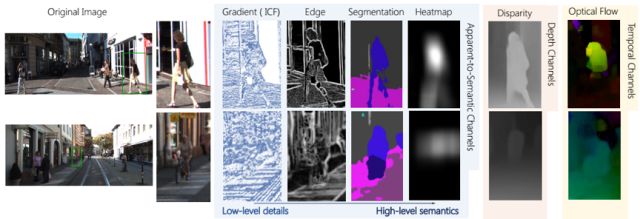
文獻[25]提出了一種稱為HyperLearner的行人檢測算法,改進自Faster R-CNN。在文中,作者分析了行人檢測的困難之處:行人與背景的區分度低,在擁擠的場景中,準確的定義一個行人非常困難。
作者使用了一些額外的特征來解決這些問題。這些特征包括:
apparent-to-semantic channels
temporal channels
depth channels
為了將這些額外的特征也送入卷積網絡進行處理,作者在VGG網絡的基礎上增加了一個分支網絡,與主體網絡的特征一起送入RPN進行處理:
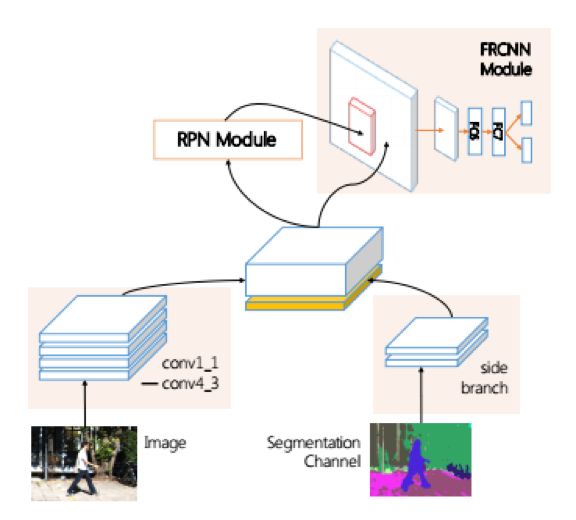
其他的基本上遵循了Faster R-CNN框架的處理流程,只是將anchor參數做了改動。在實驗中,這種算法相比Faster R-CNN有了精度上的提升。
從上面的回顧也可以看出,與人臉檢測相比,行人檢測難度要大很多,目前還遠稱不上已經解決,遮擋、復雜背景下的檢測問題還沒有解決,要因此還需要學術界和工業界的持續努力。
-
算法
+關注
關注
23文章
4601瀏覽量
92671 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45930
原文標題:行人檢測算法
文章出處:【微信號:gh_ecbcc3b6eabf,微信公眾號:人工智能和機器人研究院】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于深度學習的目標檢測算法解析
人臉檢測算法及新的快速算法
分享一款高速人臉檢測算法
基于YOLOX目標檢測算法的改進
基于多特征的紅外行人檢測算法
基于分層稀疏編碼的行人檢測算法
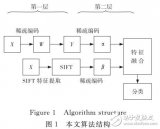
紋理與輪廓結合的行人檢測
SIGAI將為大家回顧行人檢測算法的發展歷程
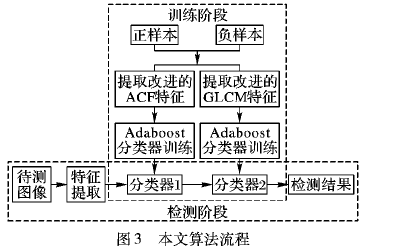
使用結合改進聚合通道特征和灰度共生矩陣設計的俯視行人檢測算法介紹
基于深度學習的目標檢測算法





 工商網監
工商網監
評論