 Linux進程的概念及進程通信的應用場景
Linux進程的概念及進程通信的應用場景
進程的概念
·進程是操作系統的概念,每當我們執行一個程序時,對于操作系統來講就創建了一個進程,在這個過程中,伴隨著資源的分配和釋放。可以認為進程是一個程序的一次執行過程。
進程通信的概念
·進程用戶空間是相互獨立的,一般而言是不能相互訪問的。但很多情況下進程間需要互相通信,來完成系統的某項功能。進程通過與內核及其它進程之間的互相通信來協調它們的行為。
進程通信的應用場景
數據傳輸:一個進程需要將它的數據發送給另一個進程,發送的數據量在一個字節到幾兆字節之間。
共享數據:多個進程想要操作共享數據,一個進程對共享數據的修改,別的進程應該立刻看到。
通知事件:一個進程需要向另一個或一組進程發送消息,通知它(它們)發生了某種事件(如進程終止時要通知父進程)。
資源共享:多個進程之間共享同樣的資源。為了作到這一點,需要內核提供鎖和同步機制。
進程控制:有些進程希望完全控制另一個進程的執行(如Debug進程),此時控制進程希望能夠攔截另一個進程的所有陷入和異常,并能夠及時知道它的狀態改變。
進程通信的方式
管道( pipe ):
管道包括三種:
·普通管道PIPE: 通常有兩種限制,一是單工,只能單向傳輸;二是只能在父子或者兄弟進程間使用.
·流管道s_pipe: 去除了第一種限制,為半雙工,只能在父子或兄弟進程間使用,可以雙向傳輸.
·命名管道:name_pipe:去除了第二種限制,可以在許多并不相關的進程之間進行通訊.
信號量( semophore ) :
·信號量是一個計數器,可以用來控制多個進程對共享資源的訪問。它常作為一種鎖機制,防止某進程正在訪問共享資源時,其他進程也訪問該資源。因此,主要作為進程間以及同一進程內不同線程之間的同步手段。
消息隊列( message queue ) :
·消息隊列是由消息的鏈表,存放在內核中并由消息隊列標識符標識。消息隊列克服了信號傳遞信息少、管道只能承載無格式字節流以及緩沖區大小受限等缺點。
信號 ( sinal ) :
·信號是一種比較復雜的通信方式,用于通知接收進程某個事件已經發生。
共享內存( shared memory ) :
·共享內存就是映射一段能被其他進程所訪問的內存,這段共享內存由一個進程創建,但多個進程都可以訪問。共享內存是最快的 IPC 方式,它是針對其他進程間通信方式運行效率低而專門設計的。它往往與其他通信機制,如信號兩,配合使用,來實現進程間的同步和通信。
套接字( socket ) :
·套解口也是一種進程間通信機制,與其他通信機制不同的是,它可用于不同機器間的進程通信。
各進程間通信的原理
管道
管道是如何通信的
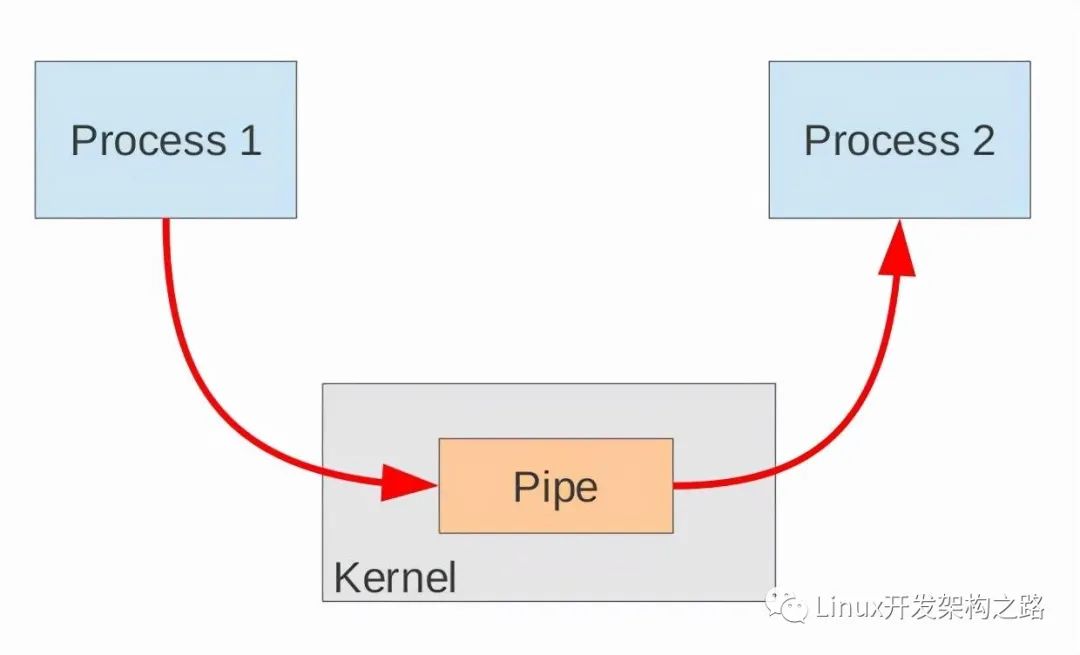
管道是由內核管理的一個緩沖區,相當于我們放入內存中的一個紙條。管道的一端連接一個進程的輸出。這個進程會向管道中放入信息。管道的另一端連接一個進程的輸入,這個進程取出被放入管道的信息。一個緩沖區不需要很大,它被設計成為環形的數據結構,以便管道可以被循環利用。當管道中沒有信息的話,從管道中讀取的進程會等待,直到另一端的進程放入信息。當管道被放滿信息的時候,嘗試放入信息的進程會等待,直到另一端的進程取出信息。當兩個進程都終結的時候,管道也自動消失。
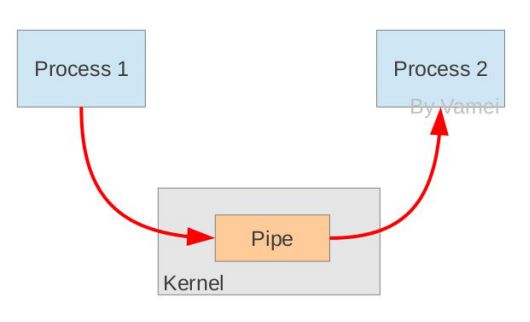
管道是如何創建的
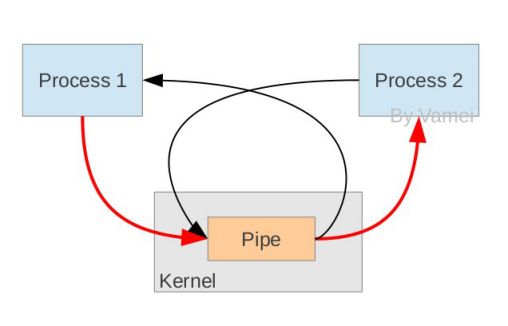
從原理上,管道利用fork機制建立,從而讓兩個進程可以連接到同一個PIPE上。最開始的時候,上面的兩個箭頭都連接在同一個進程Process 1上(連接在Process 1上的兩個箭頭)。當fork復制進程的時候,會將這兩個連接也復制到新的進程(Process 2)。隨后,每個進程關閉自己不需要的一個連接 (兩個黑色的箭頭被關閉; Process 1關閉從PIPE來的輸入連接,Process 2關閉輸出到PIPE的連接),這樣,剩下的紅色連接就構成了如上圖的PIPE。
·管道通信的實現細節在 Linux 中,管道的實現并沒有使用專門的數據結構,而是借助了文件系統的file結構和VFS的索引節點inode。通過將兩個 file 結構指向同一個臨時的 VFS 索引節點,而這個 VFS 索引節點又指向一個物理頁面而實現的。如下圖
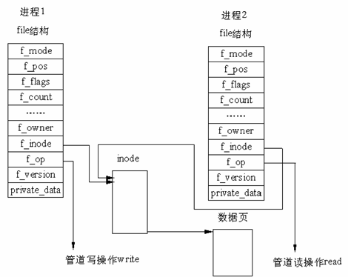
有兩個 file 數據結構,但它們定義文件操作進程地址是不同的,其中一個是向管道中寫入數據的進程地址,而另一個是從管道中讀出數據的進程地址。這樣,用戶程序的系統調用仍然是通常的文件操作,而內核卻利用這種抽象機制實現了管道這一特殊操作。
關于管道的讀寫
管道實現的源代碼在fs/pipe.c中,在pipe.c中有很多函數,其中有兩個函數比較重要,即管道讀函數pipe_read()和管道寫函數pipe_wrtie()。管道寫函數通過將字節復制到 VFS 索引節點指向的物理內存而寫入數據,而管道讀函數則通過復制物理內存中的字節而讀出數據。當然,內核必須利用一定的機制同步對管道的訪問,為此,內核使用了鎖、等待隊列和信號。
當寫進程向管道中寫入時,它利用標準的庫函數write(),系統根據庫函數傳遞的文件描述符,可找到該文件的 file 結構。file 結構中指定了用來進行寫操作的函數(即寫入函數)地址,于是,內核調用該函數完成寫操作。寫入函數在向內存中寫入數據之前,必須首先檢查 VFS 索引節點中的信息,同時滿足如下條件時,才能進行實際的內存復制工作:
·內存中有足夠的空間可容納所有要寫入的數據;
·內存沒有被讀程序鎖定。
如果同時滿足上述條件,寫入函數首先鎖定內存,然后從寫進程的地址空間中復制數據到內存。否則,寫入進程就休眠在 VFS 索引節點的等待隊列中,接下來,內核將調用調度程序,而調度程序會選擇其他進程運行。寫入進程實際處于可中斷的等待狀態,當內存中有足夠的空間可以容納寫入數據,或內存被解鎖時,讀取進程會喚醒寫入進程,這時,寫入進程將接收到信號。當數據寫入內存之后,內存被解鎖,而所有休眠在索引節點的讀取進程會被喚醒。
管道的讀取過程和寫入過程類似。但是,進程可以在沒有數據或內存被鎖定時立即返回錯誤信息,而不是阻塞該進程,這依賴于文件或管道的打開模式。反之,進程可以休眠在索引節點的等待隊列中等待寫入進程寫入數據。當所有的進程完成了管道操作之后,管道的索引節點被丟棄,而共享數據頁也被釋放。
Linux函數原型
#include
intpipe(intfiledes[2]);
filedes[0]用于讀出數據,讀取時必須關閉寫入端,即close(filedes[1]);
filedes[1]用于寫入數據,寫入時必須關閉讀取端,即close(filedes[0])。
程序實例:
intmain(void)
{
intn;
intfd[2];
pid_t pid;
charline[MAXLINE];
if(pipe(fd) 0){ /* 先建立管道得到一對文件描述符 */
exit(0);
}
if((pid = fork()) 0) /* 父進程把文件描述符復制給子進程 */
exit(1);
elseif(pid > 0){ /* 父進程寫 */
close(fd[0]); /* 關閉讀描述符 */
write(fd[1], "\nhello world\n", 14);
}
else{ /* 子進程讀 */
close(fd[1]); /* 關閉寫端 */
n = read(fd[0], line, MAXLINE);
write(STDOUT_FILENO, line, n);
}
exit(0);
}
命名管道
由于基于fork機制,所以管道只能用于父進程和子進程之間,或者擁有相同祖先的兩個子進程之間 (有親緣關系的進程之間)。為了解決這一問題,Linux提供了FIFO方式連接進程。FIFO又叫做命名管道(named PIPE)。
實現原理
FIFO (First in, First out)為一種特殊的文件類型,它在文件系統中有對應的路徑。當一個進程以讀(r)的方式打開該文件,而另一個進程以寫(w)的方式打開該文件,那么內核就會在這兩個進程之間建立管道,所以FIFO實際上也由內核管理,不與硬盤打交道。之所以叫FIFO,是因為管道本質上是一個先進先出的隊列數據結構,最早放入的數據被最先讀出來,從而保證信息交流的順序。FIFO只是借用了文件系統(file system,命名管道是一種特殊類型的文件,因為Linux中所有事物都是文件,它在文件系統中以文件名的形式存在。)來為管道命名。寫模式的進程向FIFO文件中寫入,而讀模式的進程從FIFO文件中讀出。當刪除FIFO文件時,管道連接也隨之消失。FIFO的好處在于我們可以通過文件的路徑來識別管道,從而讓沒有親緣關系的進程之間建立連接
函數原型:
#include #include
intmkfifo(constchar*filename, mode_t mode);intmknode(constchar*filename, mode_t mode | S_IFIFO, (dev_t) 0);
其中filename是被創建的文件名稱,mode表示將在該文件上設置的權限位和將被創建的文件類型(在此情況下為S_IFIFO),dev是當創建設備特殊文件時使用的一個值。因此,對于先進先出文件它的值為0。
程序實例:
#include #include #include #include
intmain()
{
intres = mkfifo("/tmp/my_fifo", 0777);
if(res == 0)
{
printf("FIFO created/n");
}
exit(EXIT_SUCCESS);
}
信號量
什么是信號量
為了防止出現因多個程序同時訪問一個共享資源而引發的一系列問題,我們需要一種方法。比如在任一時刻只能有一個執行線程訪問代碼的臨界區域。臨界區域是指執行數據更新的代碼需要獨占式地執行。而信號量就可以提供這樣的一種訪問機制,讓一個臨界區同一時間只有一個線程在訪問它,也就是說信號量是用來調協進程對共享資源的訪問的。
信號量是一個特殊的變量,程序對其訪問都是原子操作,且只允許對它進行等待(即P(信號變量))和發送(即V(信號變量))信息操作。最簡單的信號量是只能取0和1的變量,這也是信號量最常見的一種形式,叫做二進制信號量。而可以取多個正整數的信號量被稱為通用信號量。
信號量的工作原理
由于信號量只能進行兩種操作等待和發送信號,即P(sv)和V(sv),他們的行為是這樣的:
·P(sv):如果sv的值大于零,就給它減1;如果它的值為零,就掛起該進程的執行
·V(sv):如果有其他進程因等待sv而被掛起,就讓它恢復運行,如果沒有進程因等待sv而掛起,就給它加1.
舉個例子,就是兩個進程共享信號量sv,一旦其中一個進程執行了P(sv)操作,它將得到信號量,并可以進入臨界區,使sv減1。而第二個進程將被阻止進入臨界區,因為當它試圖執行P(sv)時,sv為0,它會被掛起以等待第一個進程離開臨界區域并執行V(sv)釋放信號量,這時第二個進程就可以恢復執行。
Linux的信號量機制
Linux提供了一組精心設計的信號量接口來對信號進行操作,它們不只是針對二進制信號量,下面將會對這些函數進行介紹,但請注意,這些函數都是用來對成組的信號量值進行操作的。它們聲明在頭文件sys/sem.h中。
semget函數
它的作用是創建一個新信號量或取得一個已有信號量,原型為:
intsemget(key_t key, intnum_sems, intsem_flags);
第一個參數key是整數值(唯一非零),不相關的進程可以通過它訪問一個信號量,它代表程序可能要使用的某個資源,程序對所有信號量的訪問都是間接的,程序先通過調用semget函數并提供一個鍵,再由系統生成一個相應的信號標識符(semget函數的返回值),只有semget函數才直接使用信號量鍵,所有其他的信號量函數使用由semget函數返回的信號量標識符。如果多個程序使用相同的key值,key將負責協調工作。
第二個參數num_sems指定需要的信號量數目,它的值幾乎總是1。
第三個參數sem_flags是一組標志,當想要當信號量不存在時創建一個新的信號量,可以和值IPC_CREAT做按位或操作。設置了IPC_CREAT標志后,即使給出的鍵是一個已有信號量的鍵,也不會產生錯誤。而IPC_CREAT | IPC_EXCL則可以創建一個新的,唯一的信號量,如果信號量已存在,返回一個錯誤。
semget函數成功返回一個相應信號標識符(非零),失敗返回-1.
semop函數
它的作用是改變信號量的值,原型為:
intsemop(intsem_id, structsembuf *sem_opa, size_t num_sem_ops);
·1
sem_id是由semget返回的信號量標識符,sembuf結構的定義如下:
structsembuf{
shortsem_num;//除非使用一組信號量,否則它為0
shortsem_op;//信號量在一次操作中需要改變的數據,通常是兩個數,一個是-1,即P(等待)操作,
//一個是+1,即V(發送信號)操作。
shortsem_flg;//通常為SEM_UNDO,使操作系統跟蹤信號,
//并在進程沒有釋放該信號量而終止時,操作系統釋放信號量
};
semctl函數
intsemctl(intsem_id, intsem_num, intcommand, ...);
·1
如果有第四個參數,它通常是一個union semum結構,定義如下:
unionsemun{
intval;
structsemid_ds *buf;
unsignedshort*arry;
};
前兩個參數與前面一個函數中的一樣,command通常是下面兩個值中的其中一個SETVAL:用來把信號量初始化為一個已知的值。p 這個值通過union semun中的val成員設置,其作用是在信號量第一次使用前對它進行設置。
IPC_RMID:用于刪除一個已經無需繼續使用的信號量標識符。
消息隊列
什么是消息隊列
消息隊列是消息的鏈接表,包括Posix消息隊列system V消息隊列。有足夠權限的進程可以向隊列中添加消息,被賦予讀權限的進程則可以讀走隊列中的消息。消息隊列克服了信號承載信息量少,管道只能承載無格式字節流以及緩沖區大小受限等缺點。消息隊列是隨內核持續的。
每個消息隊列都有一個隊列頭,用結構struct msg_queue來描述。隊列頭中包含了該消息隊列的大量信息,包括消息隊列鍵值、用戶ID、組ID、消息隊列中消息數目等等,甚至記錄了最近對消息隊列讀寫進程的ID。讀者可以訪問這些信息,也可以設置其中的某些信息。
結構msg_queue用來描述消息隊列頭,存在于系統空間:
structmsg_queue {
structkern_ipc_perm q_perm;
time_t q_stime; /* last msgsnd time */
time_t q_rtime; /* last msgrcv time */
time_t q_ctime; /* last change time */
unsignedlongq_cbytes; /* current number of bytes on queue */
unsignedlongq_qnum; /* number of messages in queue */
unsignedlongq_qbytes; /* max number of bytes on queue */
pid_t q_lspid; /* pid of last msgsnd */
pid_t q_lrpid; /* last receive pid */
structlist_head q_messages;
structlist_head q_receivers;
structlist_head q_senders;
};
結構msqid_ds用來設置或返回消息隊列的信息,存在于用戶空間:
structmsqid_ds {
structipc_perm msg_perm;
structmsg *msg_first; /* first message on queue,unused */
structmsg *msg_last; /* last message in queue,unused */
__kernel_time_t msg_stime; /* last msgsnd time */
__kernel_time_t msg_rtime; /* last msgrcv time */
__kernel_time_t msg_ctime; /* last change time */
unsignedlongmsg_lcbytes; /* Reuse junk fields for 32 bit */
unsignedlongmsg_lqbytes; /* ditto */
unsignedshortmsg_cbytes; /* current number of bytes on queue */
unsignedshortmsg_qnum; /* number of messages in queue */
unsignedshortmsg_qbytes; /* max number of bytes on queue */
__kernel_ipc_pid_t msg_lspid; /* pid of last msgsnd */
__kernel_ipc_pid_t msg_lrpid; /* last receive pid */
};
消息隊列與內核的聯系
下圖說明了內核與消息隊列是怎樣建立起聯系的:
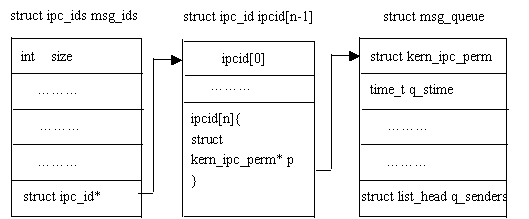
從上圖可以看出,全局數據結構 struct ipc_ids msg_ids 可以訪問到每個消息隊列頭的第一個成員:struct kern_ipc_perm;而每個struct kern_ipc_perm能夠與具體的消息隊列對應起來是因為在該結構中,有一個key_t類型成員key,而key則唯一確定一個消息隊列。 kern_ipc_perm結構如下:
structkern_ipc_perm{ //內核中記錄消息隊列的全局數據結構msg_ids能夠訪問到該結構;
key_t key; //該鍵值則唯一對應一個消息隊列
uid_t uid;
gid_t gid;
uid_t cuid;
gid_t cgid;
mode_t mode;unsignedlongseq;
}
消息隊列的操作
打開或創建消息隊列息隊列的內核持續性要求每個消息隊列都在系統范圍內對應唯一的鍵值,所以,要獲得一個消息隊列的描述字,只需提供該消息隊列的鍵值即可;
注:消息隊列描述字是由在系統范圍內唯一的鍵值生成的,而鍵值可以看作對應系統內的一條路經。
讀寫的操作
消息讀寫操作非常簡單,對開發人員來說,每個消息都類似如下的數據結構:
structmsgbuf{longmtype;charmtext[1];
};
mtype成員代表消息類型,從消息隊列中讀取消息的一個重要依據就是消息的類型;mtext是消息內容,當然長度不一定為1。因此,對于發送消息來說, 首先預置一個msgbuf緩沖區并寫入消息類型和內容,調用相應的發送函數即可;對讀取消息來說,首先分配這樣一個msgbuf緩沖區,然后把消息讀入該緩沖區即可。
·獲得或設置消息隊列屬性:
消息隊列的信息基本上都保存在消息隊列頭中,因此,可以分配一個類似于消息隊列頭的結構,來返回消息隊列的屬性;同樣可以設置該數據結構。
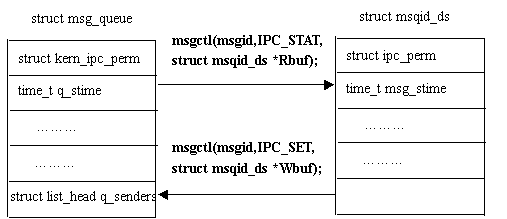
信號
信號本質
·信號是在軟件層次上對中斷機制的一種模擬,在原理上,一個進程收到一個信號與處理器收到一個中斷請求可以說是一樣的。信號是異步的,一個進程不必通過任何操作來等待信號的到達,事實上,進程也不知道信號到底什么時候到達。
·信號是進程間通信機制中唯一的異步通信機制,可以看作是異步通知,通知接收信號的進程有哪些事情發生了。信號機制經過POSIX實時擴展后,功能更加強大,除了基本通知功能外,還可以傳遞附加信息。
信號來源
信號事件的發生有兩個來源:硬件來源(比如我們按下了鍵盤或者其它硬件故障);軟件來源,最常用發送信號的系統函數是kill, raise, alarm和setitimer以及sigqueue函數,軟件來源還包括一些非法運算等操作。
信號的種類
·可以從兩個不同的分類角度對信號進行分類:(1)可靠性方面:可靠信號與不可靠信號;(2)與時間的關系上:實時信號與非實時信號。
可靠信號和不可靠信號
不可靠信號
Linux信號機制基本上是從Unix系統中繼承過來的。早期Unix系統中的信號機制比較簡單和原始,后來在實踐中暴露出一些問題,因此,把那些建立在早期機制上的信號叫做”不可靠信號”,信號值小于SIGRTMIN(Red hat 7.2中,SIGRTMIN=32,SIGRTMAX=63)的信號都是不可靠信號。這就是”不可靠信號”的來源。它的主要問題是:
·進程每次處理信號后,就將對信號的響應設置為默認動作。在某些情況下,將導致對信號的錯誤處理;因此,用戶如果不希望這樣的操作,那么就要在信號處理函數結尾再一次調用signal(),重新安裝該信號。
·
信號可能丟失因此,早期unix下的不可靠信號主要指的是進程可能對信號做出錯誤的反應以及信號可能丟失。
Linux支持不可靠信號,但是對不可靠信號機制做了改進:在調用完信號處理函數后,不必重新調用該信號的安裝函數(信號安裝函數是在可靠機制上的實現)。因此,Linux下的不可靠信號問題主要指的是信號可能丟失。
可靠信號
·隨著時間的發展,實踐證明了有必要對信號的原始機制加以改進和擴充,力圖實現”可靠信號”。由于原來定義的信號已有許多應用,不好再做改動,最終只好又新增加了一些信號,并在一開始就把它們定義為可靠信號,這些信號支持排隊,不會丟失。
·信號值位于SIGRTMIN和SIGRTMAX之間的信號都是可靠信號,可靠信號克服了信號可能丟失的問題。Linux在支持新版本的信號安裝函數sigation()以及信號發送函數sigqueue()的同時,仍然支持早期的signal()信號安裝函數,支持信號發送函數kill()
注意:可靠信號是指后來添加的新信號(信號值位于SIGRTMIN及SIGRTMAX之間);不可靠信號是信號值小于SIGRTMIN的信號。信號的可靠與不可靠只與信號值有關,與信號的發送及安裝函數無關。
實時信號與非實時信號
·非實時信號都不支持排隊,都是不可靠信號,編號是1-31,0是空信號;實時信號都支持排隊,都是可靠信號。
進程對信號的響應
·忽略信號,即對信號不做任何處理,其中,有兩個信號不能忽略:SIGKILL及SIGSTOP;
·捕捉信號。定義信號處理函數,當信號發生時,執行相應的處理函數;
·執行缺省操作,Linux對每種信號都規定了默認操作
注意:進程對實時信號的缺省反應是進程終止。
信號的發送和安裝
·發送信號的主要函數有:kill()、raise()、 sigqueue()、alarm()、setitimer()以及abort()。
·如果進程要處理某一信號,那么就要在進程中安裝該信號。安裝信號主要用來確定信號值及進程針對該信號值的動作之間的映射關系,即進程將要處理哪個信號;該信號被傳遞給進程時,將執行何種操作。
注意:inux主要有兩個函數實現信號的安裝:signal()、sigaction()。其中signal()在可靠信號系統調用的基礎上實現, 是庫函數。它只有兩個參數,不支持信號傳遞信息,主要是用于前32種非實時信號的安裝;而sigaction()是較新的函數(由兩個系統調用實現:sys_signal以及sys_rt_sigaction),有三個參數,支持信號傳遞信息,主要用來與 sigqueue() 系統調用配合使用,當然,sigaction()同樣支持非實時信號的安裝。sigaction()優于signal()主要體現在支持信號帶有參數。
共享內存
共享內存可以說是最有用的進程間通信方式,也是最快的IPC形式。是針對其他通信機制運行效率較低而設計的。兩個不同進程A、B共享內存的意思是,同一塊物理內存被映射到進程A、B各自的進程地址空間。進程A可以即時看到進程B對共享內存中數據的更新,反之亦然。由于多個進程共享同一塊內存區域,必然需要某種同步機制,互斥鎖和信號量都可以。
系統V共享內存原理
進程間需要共享的數據被放在一個叫做IPC共享內存區域的地方,所有需要訪問該共享區域的進程都要把該共享區域映射到本進程的地址空間中去。系統V共享內存通過shmget獲得或創建一個IPC共享內存區域,并返回相應的標識符。內核在保證shmget獲得或創建一個共享內存區,初始化該共享內存區相應的shmid_kernel結構體的同時,還將在特殊文件系統shm中,創建并打開一個同名文件,并在內存中建立起該文件的相應dentry及inode結構,新打開的文件不屬于任何一個進程(任何進程都可以訪問該共享內存區)。所有這一切都是系統調用shmget完成的。
系統V共享內存API
shmget()用來獲得共享內存區域的ID,如果不存在指定的共享區域就創建相應的區域。shmat()把共享內存區域映射到調用進程的地址空間中去,這樣,進程就可以方便地對共享區域進行訪問操作。shmdt()調用用來解除進程對共享內存區域的映射。shmctl實現對共享內存區域的控制操作。
套接字(socket)
最早出現在UNIX系統中,是UNIX系統主要的信息傳遞方式。
Socket相關概念
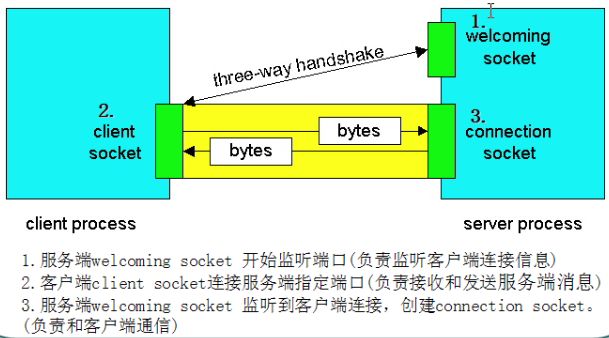
兩個基本概念:客戶方和服務方。當兩個應用之間需要采用SOCKET通信時,首先需要在兩個應用之間(可能位于同一臺機器,也可能位于不同的機器)建立SOCKET連接。
發起呼叫連接請求的一方為客戶方在客戶方呼叫連接請求之前,它必須知道服務方在哪里。所以需要知道服務方所在機器的IP地址或機器名稱,如果客戶方和服務方事前有一個約定就好了,這個約定就是PORT(端口號)。也就是說,客戶方可以通過服務方所在機器的IP地址或機器名稱和端口號唯一的確定方式來呼叫服務方。
接受呼叫連接請求的一方成為服務方。在客戶方呼叫之前,服務方必須處于偵聽狀態,偵聽是否有客戶要求建立連接。一旦接到連接請求,服務方可以根據情況建立或拒絕連接。當客戶方的消息到達服務方端口時,會自動觸發一個事件(event),服務方只要接管該事件,就可以接受來自客戶方的消息了。
Socket類型
·流式Socket(STREAM):是一種面向連接的Socekt,針對面向連接的TCP服務應用,安全,但是效率低;
·數據報式Socket(DATAGAM):是一種無連接的Socket,對應于無連接的UDP服務應用。不安(丟失,順序混亂,在接受端要分析重排及要求重發),但效率高。
Socket一般應用模式(服務端和客戶端)
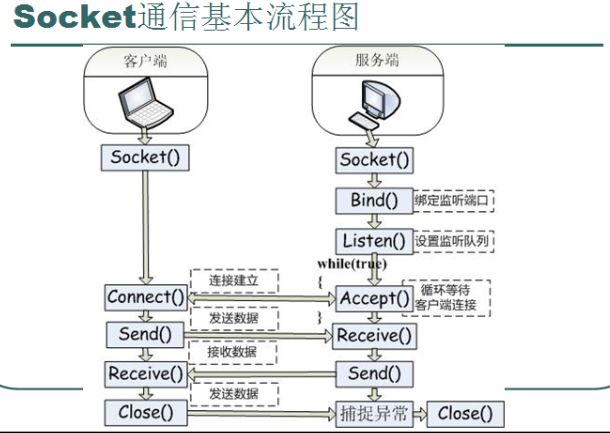
Socket通信基本流程圖
-
Linux
+關注
關注
87文章
11123瀏覽量
207908 -
操作系統
+關注
關注
37文章
6545瀏覽量
122743 -
管道
+關注
關注
3文章
145瀏覽量
17892
原文標題:這可能是介紹Linux進程間通信方式和原理最詳細的文章
文章出處:【微信號:gh_c472c2199c88,微信公眾號:嵌入式微處理器】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

【Linux學習雜談】之進程通信
詳解Linux進程通信概念
linux操作系統下的進程通信設計
進程間通信之Linux下進程間通信概述
Linux進程間通信
Linux系統中的進程之間通信
進程通信的應用場景





 工商網監
工商網監
評論