 使用強化學習從數據本身中找出最佳圖像轉換策略
使用強化學習從數據本身中找出最佳圖像轉換策略
谷歌研究人員最新提出了一種自動數據增強方法,受AutoML的啟發,他們嘗試將數據增強的過程也實現自動化,使用強化學習從數據本身中找出最佳圖像轉換策略,在不依賴于生成新的和不斷擴展的數據集的情況下,提高了計算機視覺模型的性能。
計算機視覺深度學習的成功,可部分歸因于擁有大量帶標記的訓練數據——數據的質、量和多樣性提高,模型的性能也通常會增強。但是,要收集足夠多的高質量數據訓練模型來實現良好的性能,通常非常困難。
解決這個問題的一種方法,是將圖像對稱(image symmetries)硬編碼為神經網絡結構,或者,讓專家手動設計數據增強方法,比如旋轉和翻轉圖像,這些都是訓練性能良好的視覺模型常會用到的方法。
但是,直到最近,人們很少關注如何利用機器學習來自動增強現有數據。谷歌此前推出了AutoML,代替人為設計的系統組件,讓神經網絡自動設計神經網絡和優化器,得到了良好的結果。受此啟發,谷歌研究人員不禁問自己:是否也可以讓數據增強過程自動完成?
在最新公布的論文《AutoAugment:從數據學習增強策略》(AutoAugment: Learning Augmentation Policies from Data)中,谷歌的研究人員探索了一種強化學習算法,增加了現有訓練數據集中數據的數量和多樣性。直觀地說,數據增強用于教會模型有關數據域中的圖像不變性(image invariances),讓神經網絡對這些重要的對稱性保持不變(invariant),從而改善其性能。
研究人員表示,與以前使用手工設計數據增強策略的先進深度學習模型不同,他們使用強化學習從數據本身中找出最佳圖像轉換策略。結果在不依賴于生成新的和不斷擴展的數據集的情況下,提高了計算機視覺模型的性能。
訓練數據的增強
數據增強的思路很簡單:圖像具有許多對稱性,這些對稱性不會改變圖像中存在的信息。例如,狗的鏡面反射仍然是狗。這些“不變性”中的一些對人類來說顯而易見,但有很多人類很難注意到。例如,mixup方法,通過在訓練期間將圖像置于彼此之上來增強數據,從而產生改善神經網絡性能的數據。
左圖:來自ImageNet數據集的原始圖像。 右圖:通過常用數據增強方法,水平翻轉后的相同的圖像。
AutoAugment是為計算機視覺數據集設計自定義數據增強策略的自動方式,例如,AutoAugment能指導基本圖像轉換操作的選擇,例如水平/垂直翻轉圖像,旋轉圖像,更改圖像顏色等。AutoAugment不僅可以預測要合并的圖像轉換,還可以預測所使用轉換的每個圖像的概率和大小,從而不總是以相同的方式操作圖像。AutoAugment能夠從2.9 x 10^32大的搜索空間中,選擇出圖像轉換的最佳策略。
AutoAugment 根據所運行的數據集學習不同的轉換。例如,對于包含數字自然場景的街景(SVHN)圖像,AutoAugment 的重點是像剪切和平移這樣的幾何變換,它們代表了數據集中常見的失真現象。此外,由于世界上不同的建筑和房屋編號材料的多樣性,AutoAugment機構已經學會了完全反轉原始SVHN數據集中自然出現的顏色。
左:來自SVHN數據集的原始圖像。右:相同的圖像AutoAugment。在這種情況下,最優轉換是剪切圖像并反轉像素顏色的結果。
在CIFAR-10和ImageNet上,AutoAugment 不使用剪切,因為這些數據集通常不包含剪切對象的圖像,也不完全反轉顏色,因為這些轉換將導致不真實的圖像。相反,AutoAugment r的重點是稍微調整顏色和色調分布,同時保持一般的色彩屬性。這說明在CIFAR-10和ImageNet中對象的實際顏色是重要的,而在SVHN中只有相對的顏色是重要的。
結果
我們的AutoAugment 算法發現了一些最著名的計算機視覺數據集的增強策略,這些數據集被納入到神經網絡的訓練中,會產生最先進的精確性。通過增強ImageNet數據,我們獲得了83.54% top1精度的新的最新精度,在CIFAR10上我們獲得了1.48%的錯誤率,這比科學家設計的默認數據增強提高了0.83%。在SVHN上,我們將最先進的誤差從1.30%提高到1.02%。重要的是,AutoAugment策略被發現是可轉移的——為ImageNet數據集找到的策略也可以應用于其他視覺數據集(斯坦福汽車、FGVC-Aircraft等),從而改善神經網絡的性能。
我們很高興地看到,我們的AutoAugment算法在許多不同的競爭性計算機視覺數據集上都達到了這樣的性能水平,并期待著未來在更多的計算機視覺任務中,甚至在音頻處理或語言模型等其他領域,都能應用這種技術。在本文的附錄中包含了性能最好的策略,以便研究人員可以使用它們來改進他們在相關視覺任務上的模型。
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100550 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45929 -
機器學習
+關注
關注
66文章
8381瀏覽量
132428
原文標題:谷歌放大招!數據增強實現自動化
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度強化學習實戰
將深度學習和強化學習相結合的深度強化學習DRL
基于強化學習的IEEE 802.15.4網絡區分服務策略
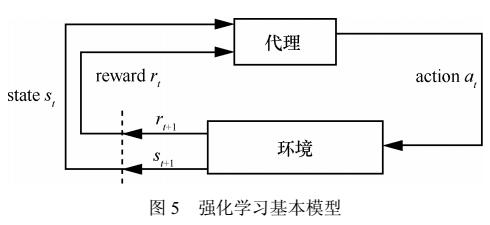
什么是強化學習?純強化學習有意義嗎?強化學習有什么的致命缺陷?

如何使用深度強化學習進行機械臂視覺抓取控制的優化方法概述
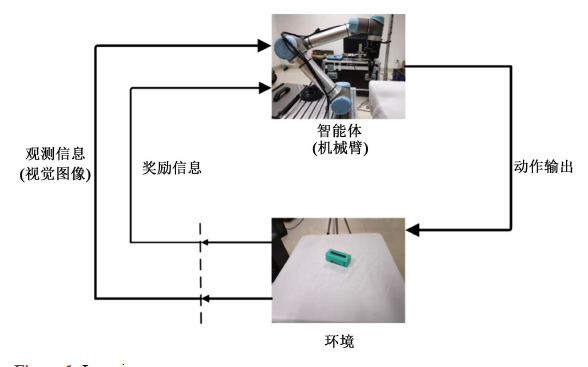
對NAS任務中強化學習的效率進行深入思考
強化學習在智能對話上的應用介紹
機器學習中的無模型強化學習算法及研究綜述

《自動化學報》—多Agent深度強化學習綜述

模擬矩陣在深度強化學習智能控制系統中的應用

通過強化學習策略進行特征選擇






 工商網監
工商網監
評論