 Apollo一路走來,正在走出高成本的科研范疇邁向實用領域
Apollo一路走來,正在走出高成本的科研范疇邁向實用領域
百度Apollo目前歷經四代,分別是Apollo1.0、1.5、2.0、2.5。




Apollo一路走來,正在走出高成本的科研范疇,邁向實用領域。在Apollo1.5版上,激光雷達是最核心的,不僅完成傳統的局部導航,還完成通常由攝像頭完成的障礙物識別。2.0版上,增加交通信號燈檢測和障礙物分類。RTK與激光雷達點云融合定位,MPC模型預測法做控制算法,RNN做交通場景預測。Apollo重點模塊集中在障礙物感知、預測、高精度定位、路徑規劃、控制的工作。
這樣一輛車,總成本100多萬人民幣(含改裝成本),顯然只能做科研,即使做共享出行,成本都太高了。
2.5版上,Apollo有了重大改變,從高成本科研階段進入實用化的階段,從以前的低速園區應用,演進到低成本方案的高速公路應用。在Github上Apollo2.5是這樣說的 Vehicles with this version can drive autonomously on highways at higher speed with limited HD map support. The highway needs to have clear white painted lane marks with minimum curvatures. The performance of vision based perception will degrade significantly at night or with strong light flares.Be cautious when driving autonomously, Especially at night or in poor vision environment. Please test Apollo 2.5 with the support from Apollo engineering team. 在高精度地圖支持下,車輛可以在高速公路上以較高的速度自動駕駛,高速公路應該車道線清晰,曲率不高。在強烈陽光和低照度下請謹慎,請在Apollo工程團隊的支持下測試Apollo2.5。
和原來數十萬元的系統成本相比,Apollo2.5僅用一個廣角攝像頭和一個毫米波雷達就完成了高速公路自動駕駛,總體成本下降了90%,已經具備量產條件。
Apollo2.5的基礎是百度的低成本“相對地圖”,這種地圖和凱迪拉克超級巡航上的激光雷達地圖類似。

由USHR為凱迪拉克制作的激光雷達地圖專為高速公路無人駕駛設計,地圖的內容包括車道數量、車道寬度、水平寬度、速度上限、速度下限、海拔高度、順坡斜率、邊坡斜率、航向角、水平曲率半徑等,精度為10厘米。在凱迪拉克超級巡航里包括6自由度的MEMS IMU,使用天寶的RTX服務和一臺天寶的單頻雙星(GPS/GLONASS)接收機,使用4G通訊來矯正定位,包括精確衛星時鐘,軌道和電離層信息,定位精度可達1.8米。
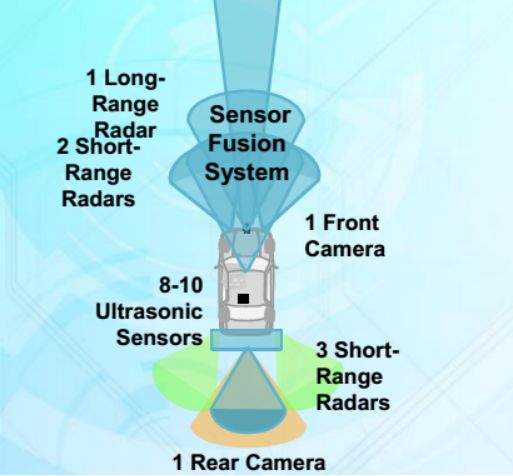
凱迪拉克使用6個毫米波雷達,包括1個長距超聲波雷達,可能是德國大陸汽車的ARS-410,5個短距離毫米波雷達,可能是大陸的SRR520。前后兩個攝像頭也由大陸提供,8-10個超聲波雷達,當然車內還有一個駕駛者狀態監控攝像頭。圖中未標出360環視系統,實際上凱迪拉克超級巡航也有360環視系統。這套系統遠優于特斯拉的Autopilot 2.5輔助駕駛系統。
中國的高速公路路況不同于美國,中國的高速公路有三大殺手,一是大貨車,二是無視交通法規的司機,三是豪車飆車。對這三大殺手,必須做出對應,這就是場景決策或者說行為決策。大貨車由于國情因素,超載是不可避免的,不超載就會虧本。超載情況下,剎車性能大幅度下降,加上大貨車都是氣剎,反應速度遠低于小型車的液壓剎車,此外大貨車在高速上方向打的稍微急一點就可能翻車,會壓垮臨近車道的車。所以高速上盡量不跟大貨車,盡量不與大貨車平行。然而高速上也忌諱隨意變道,或者見大車就超。需要在兩者之間做一個平衡,找一個最優策略。
有些司機,在高速逆行或倒車,如果按照一般無人車的原則是遇到障礙物就減速,而面對逆行或倒車,減速不是最優策略,換道才是,不過也要看是否具備換道條件。最后是那些不在意超速罰款的豪車,四處穿插變道,任意超出,無人車要盡量遠離這些車輛。
如何讓無人車面對這些場景時做出最優選擇?
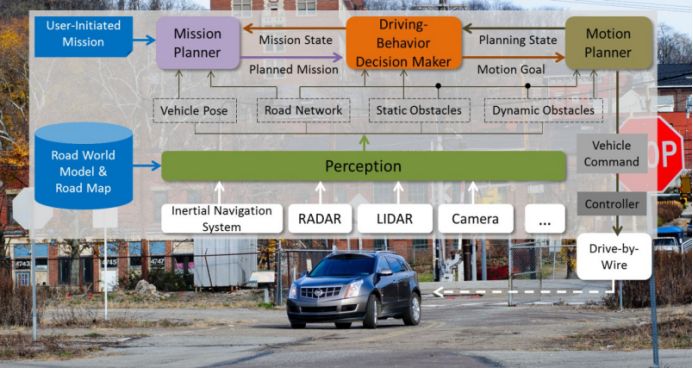
行為決策,第一種方法為人為編程法(Manual Programing),包括FSM(Finite State Machines)有限狀態機、行為樹、目標導向、效用系統、Rule Based、HSM(Hierarachical State Machines)層次狀態機。
FSM有限狀態機,這是目前AI游戲界最常用的方法,也是小公司無人駕駛最常用的,簡單高效,最大的優點是可視化,缺點是無法對應太多的場景,一般不超過10個,在高速上場景比較簡單,尚可使用,低速市區則完全不能用。
第二種是Optimisation最優法,包括CCO(Chance Control Optiminsation)。
第三種是Graph 搜索法,包括A+法(寶馬),RRTS(快速擴展隨機樹法)。
第四種Model Predictive Control (MPC)法,例如Interactive Multi Model-Extended Kalman Filter (IMM-EKF)。
第五種Partially Observable Markov Decision Process (POMDP),部分可觀察馬爾科夫決策過程法,降低對傳感器的依賴性。
Waymo使用POMDP來做行為決策,Waymo的 behavior prediction team由Stephane Ross領導,主要用POMDP來預測行人、車輛和騎自行車者的未來行為。預測行為與行為決策是聯為一體的。
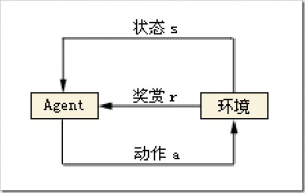
這實際上一種強化學習。深度學習算法一般可分為三大類,即非監督學習(unsupervised learning)、監督學習(supervised leaning)和強化學習。根據Agent當前狀態,選擇了動作a,這時與環境發生了交互,Agent觀測到下一個狀態,并收到了一定的獎賞r(有好有壞)。如此反復的與環境進行交互,在一定條件下,Agent會學習到一個最優/次優的策略。這實際上就是個馬爾科夫決策過程(MDP),也就是阿爾法狗背后的算法。
而無人車的決策都來自傳感器得到的信息,這些信息都不能完整地描述環境,只是環境的一部分,因此需要使用POMDP,即部分觀察馬爾科夫決策過程。強化學習過程可以使用一個馬氏決策過程(M arkov decision process,MDP)表示,MDP由四元組
如果Agent在學習過程中,無需學習MDP的模型知識,直接學習最優策略, 我們稱這類方法為模型無關(Model free) ;如果在學習過程中,先學習MDP的模型知識,然后再根據這些推導、學習出最優策略,我們稱之為模型有關( Model based)。其中前者是研究的重點,因為在實際中主要遇到的問題。是如何在模型不知的情況下學習到最優策略。前者的算法主要有TD(λ), Q—learning 算法,后者主要有Dyna、Prioritized Sweeping、Sarsa 算法等。
無人車的POMDP一般包括狀態建模、行為建模、觀察建模、轉移函數建模、收益建模。狀態建模包括行人、車輛、騎車人可能的行為目標點,映射到POMDP模型的七元組的S。將汽車的行為,恒速、加速、減速、左轉、右轉組合為多種行為。將車輛位置、速度和周圍移動目標的位置集合映射到POMDP模型的七元組的Z。汽車的收益建模包括安全、舒適、高效三個目標。
為了加快測試過程,百度開發了強大的仿真系統。在Apollo 中,對仿真平臺的定位是不僅僅是真實,而是要能夠進一步:能夠發現無人車算法中的問題。因為在整個算法迭代閉環中,光有擬真是不夠的,還需要能夠發掘問題,發現了問題后才能去解決問題,也就是回到了開發過程。如此這樣,從開發到仿真再回到開發,仿真平臺同我們的開發過程串聯成一個閉環。只有閉環的東西才能構成持續迭代和持續優化狀態。所以仿真平臺在整個無人車算法迭代中的地位非常重要。
Apollo 仿真器的靜態世界的表達,正是直接使用了 Apollo 相對地圖數據。所以它是真實的,且是具有足夠低成本的。
相對低速場景,高速公路場景要簡單的多,更容易實現低成本可量產的無人駕駛。未來國內第一輛量產的L4無人車,很有可能是百度Apollo與中國本土車企打造的。
-
激光雷達
+關注
關注
967文章
3938瀏覽量
189595 -
自動駕駛
+關注
關注
783文章
13682瀏覽量
166144 -
Apollo
+關注
關注
5文章
340瀏覽量
18405
原文標題:百度Apollo限定場景低成本方案,邁向可量產之路
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
電子競賽,一路走來
LED驅動電路雙路輸出時,如何解決一路帶載,另外一路空載飄的問題?
“一路帶一路”為什么門檻如此之高!!!
功能模式一路切 2 路、A 路切 B 路LED恒流驅動器
使用AD9643的其中一路,另一路空余,模擬輸入該如何連接?
能源電力“一帶一路”的戰略問題及其教育中的五大建議
“一帶一路”戰略,電線電纜新機遇





 工商網監
工商網監
評論