") Python爬蟲速成指南讓你快速的學(xué)會寫一個(gè)最簡單的爬蟲
Python爬蟲速成指南讓你快速的學(xué)會寫一個(gè)最簡單的爬蟲
本文主要內(nèi)容:以最短的時(shí)間寫一個(gè)最簡單的爬蟲,可以抓取論壇的帖子標(biāo)題和帖子內(nèi)容。
本文受眾:沒寫過爬蟲的萌新。
入門
0.準(zhǔn)備工作
需要準(zhǔn)備的東西: Python、scrapy、一個(gè)IDE或者隨便什么文本編輯工具。
1.技術(shù)部已經(jīng)研究決定了,你來寫爬蟲。
隨便建一個(gè)工作目錄,然后用命令行建立一個(gè)工程,工程名為miao,可以替換為你喜歡的名字。
scrapy startproject miao
隨后你會得到如下的一個(gè)由scrapy創(chuàng)建的目錄結(jié)構(gòu)
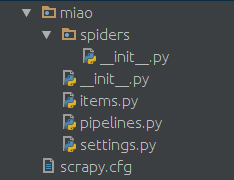
在spiders文件夾中創(chuàng)建一個(gè)python文件,比如miao.py,來作為爬蟲的腳本。
內(nèi)容如下:
import scrapyclass NgaSpider(scrapy.Spider): name = "NgaSpider" host = "http://bbs.ngacn.cc/" # start_urls是我們準(zhǔn)備爬的初始頁 start_urls = [ "http://bbs.ngacn.cc/thread.php?fid=406", ] # 這個(gè)是解析函數(shù),如果不特別指明的話,scrapy抓回來的頁面會由這個(gè)函數(shù)進(jìn)行解析。 # 對頁面的處理和分析工作都在此進(jìn)行,這個(gè)示例里我們只是簡單地把頁面內(nèi)容打印出來。 def parse(self, response): print response.body
2.跑一個(gè)試試?
如果用命令行的話就這樣:
cd miao scrapy crawl NgaSpider
你可以看到爬蟲君已經(jīng)把你壇星際區(qū)第一頁打印出來了,當(dāng)然由于沒有任何處理,所以混雜著html標(biāo)簽和js腳本都一并打印出來了。
解析
接下來我們要把剛剛抓下來的頁面進(jìn)行分析,從這坨html和js堆里把這一頁的帖子標(biāo)題提煉出來。
其實(shí)解析頁面是個(gè)體力活,方法多的是,這里只介紹xpath。
0.為什么不試試神奇的xpath呢
看一下剛才抓下來的那坨東西,或者用chrome瀏覽器手動打開那個(gè)頁面然后按F12可以看到頁面結(jié)構(gòu)。
每個(gè)標(biāo)題其實(shí)都是由這么一個(gè)html標(biāo)簽包裹著的。舉個(gè)例子:
可以看到href就是這個(gè)帖子的地址(當(dāng)然前面要拼上論壇地址),而這個(gè)標(biāo)簽包裹的內(nèi)容就是帖子的標(biāo)題了。
于是我們用xpath的絕對定位方法,把class='topic'的部分摘出來。
1.看看xpath的效果
在最上面加上引用:
from scrapy import Selector
把parse函數(shù)改成:
def parse(self, response): selector = Selector(response) # 在此,xpath會將所有class=topic的標(biāo)簽提取出來,當(dāng)然這是個(gè)list # 這個(gè)list里的每一個(gè)元素都是我們要找的html標(biāo)簽 content_list = selector.xpath("http://*[@class='topic']") # 遍歷這個(gè)list,處理每一個(gè)標(biāo)簽 for content in content_list: # 此處解析標(biāo)簽,提取出我們需要的帖子標(biāo)題。 topic = content.xpath('string(.)').extract_first() print topic # 此處提取出帖子的url地址。 url = self.host + content.xpath('@href').extract_first() print url
再次運(yùn)行就可以看到輸出你壇星際區(qū)第一頁所有帖子的標(biāo)題和url了。
遞歸
接下來我們要抓取每一個(gè)帖子的內(nèi)容。
這里需要用到python的yield。
yield Request(url=url, callback=self.parse_topic)
此處會告訴scrapy去抓取這個(gè)url,然后把抓回來的頁面用指定的parse_topic函數(shù)進(jìn)行解析。
至此我們需要定義一個(gè)新的函數(shù)來分析一個(gè)帖子里的內(nèi)容。
完整的代碼如下:
import scrapyfrom scrapy import Selectorfrom scrapy import Requestclass NgaSpider(scrapy.Spider): name = "NgaSpider" host = "http://bbs.ngacn.cc/" # 這個(gè)例子中只指定了一個(gè)頁面作為爬取的起始url # 當(dāng)然從數(shù)據(jù)庫或者文件或者什么其他地方讀取起始url也是可以的 start_urls = [ "http://bbs.ngacn.cc/thread.php?fid=406", ] # 爬蟲的入口,可以在此進(jìn)行一些初始化工作,比如從某個(gè)文件或者數(shù)據(jù)庫讀入起始url def start_requests(self): for url in self.start_urls: # 此處將起始url加入scrapy的待爬取隊(duì)列,并指定解析函數(shù) # scrapy會自行調(diào)度,并訪問該url然后把內(nèi)容拿回來 yield Request(url=url, callback=self.parse_page) # 版面解析函數(shù),解析一個(gè)版面上的帖子的標(biāo)題和地址 def parse_page(self, response): selector = Selector(response) content_list = selector.xpath("http://*[@class='topic']") for content in content_list: topic = content.xpath('string(.)').extract_first() print topic url = self.host + content.xpath('@href').extract_first() print url # 此處,將解析出的帖子地址加入待爬取隊(duì)列,并指定解析函數(shù) yield Request(url=url, callback=self.parse_topic) # 可以在此處解析翻頁信息,從而實(shí)現(xiàn)爬取版區(qū)的多個(gè)頁面 # 帖子的解析函數(shù),解析一個(gè)帖子的每一樓的內(nèi)容 def parse_topic(self, response): selector = Selector(response) content_list = selector.xpath("http://*[@class='postcontent ubbcode']") for content in content_list: content = content.xpath('string(.)').extract_first() print content # 可以在此處解析翻頁信息,從而實(shí)現(xiàn)爬取帖子的多個(gè)頁面
到此為止,這個(gè)爬蟲可以爬取你壇第一頁所有的帖子的標(biāo)題,并爬取每個(gè)帖子里第一頁的每一層樓的內(nèi)容。
爬取多個(gè)頁面的原理相同,注意解析翻頁的url地址、設(shè)定終止條件、指定好對應(yīng)的頁面解析函數(shù)即可。
Pipelines——管道
此處是對已抓取、解析后的內(nèi)容的處理,可以通過管道寫入本地文件、數(shù)據(jù)庫。
0.定義一個(gè)Item
在miao文件夾中創(chuàng)建一個(gè)items.py文件。
from scrapy import Item, Fieldclass TopicItem(Item): url = Field() title = Field() author = Field() class ContentItem(Item): url = Field() content = Field() author = Field()
此處我們定義了兩個(gè)簡單的class來描述我們爬取的結(jié)果。
1. 寫一個(gè)處理方法
在miao文件夾下面找到那個(gè)pipelines.py文件,scrapy之前應(yīng)該已經(jīng)自動生成好了。
我們可以在此建一個(gè)處理方法。
from scrapy import Item, Fieldclass TopicItem(Item): url = Field() title = Field() author = Field() class ContentItem(Item): url = Field() content = Field() author = Field()
2.在爬蟲中調(diào)用這個(gè)處理方法。
要調(diào)用這個(gè)方法我們只需在爬蟲中調(diào)用即可,例如原先的內(nèi)容處理函數(shù)可改為:
def parse_topic(self, response): selector = Selector(response) content_list = selector.xpath("http://*[@class='postcontent ubbcode']") for content in content_list: content = content.xpath('string(.)').extract_first() ## 以上是原內(nèi)容 ## 創(chuàng)建個(gè)ContentItem對象把我們爬取的東西放進(jìn)去 item = ContentItem() item["url"] = response.url item["content"] = content item["author"] = "" ## 略 ## 這樣調(diào)用就可以了 ## scrapy會把這個(gè)item交給我們剛剛寫的FilePipeline來處理 yield item
3.在配置文件里指定這個(gè)pipeline
找到settings.py文件,在里面加入
ITEM_PIPELINES = { 'miao.pipelines.FilePipeline': 400, }
這樣在爬蟲里調(diào)用
yield item
的時(shí)候都會由經(jīng)這個(gè)FilePipeline來處理。后面的數(shù)字400表示的是優(yōu)先級。
可以在此配置多個(gè)Pipeline,scrapy會根據(jù)優(yōu)先級,把item依次交給各個(gè)item來處理,每個(gè)處理完的結(jié)果會傳遞給下一個(gè)pipeline來處理。
可以這樣配置多個(gè)pipeline:
ITEM_PIPELINES = { 'miao.pipelines.Pipeline00': 400, 'miao.pipelines.Pipeline01': 401, 'miao.pipelines.Pipeline02': 402, 'miao.pipelines.Pipeline03': 403, ## ... }
Middleware——中間件
通過Middleware我們可以對請求信息作出一些修改,比如常用的設(shè)置UA、代理、登錄信息等等都可以通過Middleware來配置。
0.Middleware的配置
與pipeline的配置類似,在setting.py中加入Middleware的名字,例如
DOWNLOADER_MIDDLEWARES = { "miao.middleware.UserAgentMiddleware": 401, "miao.middleware.ProxyMiddleware": 402, }
1.破網(wǎng)站查UA, 我要換UA
某些網(wǎng)站不帶UA是不讓訪問的。
在miao文件夾下面建立一個(gè)middleware.py
import randomagents = [ "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5", "Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7", "Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1",]class UserAgentMiddleware(object): def process_request(self, request, spider): agent = random.choice(agents) request.headers["User-Agent"] = agent
這里就是一個(gè)簡單的隨機(jī)更換UA的中間件,agents的內(nèi)容可以自行擴(kuò)充。
2.破網(wǎng)站封IP,我要用代理
比如本地127.0.0.1開啟了一個(gè)8123端口的代理,同樣可以通過中間件配置讓爬蟲通過這個(gè)代理來對目標(biāo)網(wǎng)站進(jìn)行爬取。
同樣在middleware.py中加入:
class ProxyMiddleware(object): def process_request(self, request, spider): # 此處填寫你自己的代理 # 如果是買的代理的話可以去用API獲取代理列表然后隨機(jī)選擇一個(gè) proxy = "http://127.0.0.1:8123" request.meta["proxy"] = proxy
很多網(wǎng)站會對訪問次數(shù)進(jìn)行限制,如果訪問頻率過高的話會臨時(shí)禁封IP。
如果需要的話可以從網(wǎng)上購買IP,一般服務(wù)商會提供一個(gè)API來獲取當(dāng)前可用的IP池,選一個(gè)填到這里就好。
一些常用配置
在settings.py中的一些常用配置
# 間隔時(shí)間,單位秒。指明scrapy每兩個(gè)請求之間的間隔。DOWNLOAD_DELAY = 5# 當(dāng)訪問異常時(shí)是否進(jìn)行重試RETRY_ENABLED = True# 當(dāng)遇到以下http狀態(tài)碼時(shí)進(jìn)行重試RETRY_HTTP_CODES = [500, 502, 503, 504, 400, 403, 404, 408]# 重試次數(shù)RETRY_TIMES = 5# Pipeline的并發(fā)數(shù)。同時(shí)最多可以有多少個(gè)Pipeline來處理itemCONCURRENT_ITEMS = 200# 并發(fā)請求的最大數(shù)CONCURRENT_REQUESTS = 100# 對一個(gè)網(wǎng)站的最大并發(fā)數(shù)CONCURRENT_REQUESTS_PER_DOMAIN = 50# 對一個(gè)IP的最大并發(fā)數(shù)CONCURRENT_REQUESTS_PER_IP = 50
我就是要用Pycharm
如果非要用Pycharm作為開發(fā)調(diào)試工具的話可以在運(yùn)行配置里進(jìn)行如下配置:
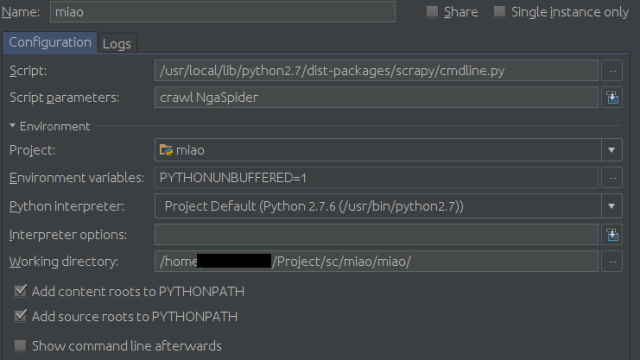
Configuration頁面:
Script填你的scrapy的cmdline.py路徑,比如我的是
/usr/local/lib/python2.7/dist-packages/scrapy/cmdline.py
然后在Scrpit parameters中填爬蟲的名字,本例中即為:
crawl NgaSpider
最后是Working diretory,找到你的settings.py文件,填這個(gè)文件所在的目錄。
示例:
按小綠箭頭就可以愉快地調(diào)試了。
參考
這里提供了對scrapy非常詳細(xì)的介紹。
http://scrapy-chs.readthedocs.io/zh_CN/0.24/
以下是幾個(gè)比較重要的地方:
scrapy的架構(gòu):
http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/architecture.html
xpath語法:
http://www.w3school.com.cn/xpath/xpath_syntax.asp
Pipeline管道配置:
http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/item-pipeline.html
Middleware中間件的配置:
http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/downloader-middleware.html
settings.py的配置:
http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/settings.html
-
IDE
+關(guān)注
關(guān)注
0文章
335瀏覽量
46678 -
python
+關(guān)注
關(guān)注
56文章
4782瀏覽量
84453 -
爬蟲
+關(guān)注
關(guān)注
0文章
82瀏覽量
6839
原文標(biāo)題:從零開始的 Python 爬蟲速成指南
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Python數(shù)據(jù)爬蟲學(xué)習(xí)內(nèi)容
Python爬蟲與Web開發(fā)庫盤點(diǎn)
Python爬蟲初學(xué)者需要準(zhǔn)備什么?
Python 爬蟲:8 個(gè)常用的爬蟲技巧總結(jié)!
0基礎(chǔ)入門Python爬蟲實(shí)戰(zhàn)課
Python爬蟲簡介與軟件配置
python網(wǎng)絡(luò)爬蟲概述

Python爬蟲8個(gè)常用的爬蟲技巧分析總結(jié)
python爬蟲入門教程之python爬蟲視頻教程分布式爬蟲打造搜索引擎
python實(shí)現(xiàn)簡單爬蟲的資料說明






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論