 使用更“時尚”的數據開啟機器學習的 Hello World 之門
使用更“時尚”的數據開啟機器學習的 Hello World 之門
本期 AI Adventure 中,Yufeng 會帶領我們會按照之前分享的最佳實踐來試著完整走一遍機器學習的整個流程。工作量有點大,但是聰明的你應該沒問題。
使用 MNIST 數據* 來訓練模型常常被看作是機器學習界的「Hello World」例子(使用標準的 MNIST 數據訓練手寫字符的識別模型),今天我們跟著 Yufeng 一起,使用更“時尚”的數據開啟機器學習的 Hello World 之門。
* 段注:MNIST 是一個手寫數字圖像的數據集,每幅圖像都由一個整數標記。它主要用于機器學習算法的性能對標。
“潮”起來的 Machine Learning
Zalando(來自德國的電子商務公司)決意要讓 MNIST 再“火”一把,前段時間 Zalando 旗下的研究部門發布了叫做 Fashion-MNIST 的一個數據集。這是一個和 MNIST 具有相同格式的數據集,唯一的不同在于手寫字符被替換成了服飾、鞋子、挎包等等內容。它仍然有 10 個種類,圖像也仍然是 28x28 像素。
在 GitHub 查看更多對Fashion-MNIST數據集的介紹(中文):
https://github.com/zalandoresearch/fashion-mnist/blob/master/README.zh-CN.md
我們一起訓練一個模型,然后用它來甄別所屬的服飾品類吧!
線性 Classifier
我們先從構建一個線性的 classifier 開始,來看看怎么操作。同以往一樣,我們用 TensorFlow 的評估器框架(鏈接參見段后) 來簡化編程和維護。回憶一下,我們會經歷加載數據、創建 classifier,然后運行訓練和評估等操作。另外還會用本地模型直接做一些預測,官方文檔參考:
https://tensorflow.google.cn/get_started/get_started_for_beginners?hl=zh-CN
下面從創建模型開始,我們首先把數據集中的圖像從 28x28 的像素排布轉為 1x784 的形式,然后將之稱為特征列 pixels。此操作類似于 AIA 第三期:無需數學知識,輕松搞定鳶尾花辨識模型中出現的 flower_features。
feature_columns = [ tf.feature_column.numeric_column( "pixels", shape=784)]classifier = tf.estimator.LinearClassifier( feature_columns=feature_columns, n_classes=10, model_dir=logdir)
下一步創建線性的 classifier。我們有 10 種品類需要做標記,而不是之前鳶尾花案例中的三種。
要開始訓練,我們需要配置數據集和輸入函數。TensorFlow 有內置的函數接受一個 NumPy 型的數組用于生成輸入函數,此處我們就用它來簡化一下。
tf.estimator.inputs.numpy_input_fn( x={'pixels': X}, y=Y, batch_size=batch_size, num_epochs=epochs, shuffle=shuffle)DATA_SETS = input_data.read_data_sets( "/tmp/fashion-mnist")
接著用 input_data 模塊把數據集載入,將函數參數指向數據集下載的位置。
然后通過調用 classifier.train() 把 classifier、輸入函數和數據集都結合起來。
classifier.train( input_fn=train_input_fn, steps=num_steps)accuracy_score = classifier.evaluate( input_fn=eval_input_fn)['accuracy']
最終,我們進行一次評估來看看模型表現如何。使用經典 MNIST 數據集時,此模型常常得到 91% 左右的準確度。然后,由于時尚版 MNIST 有更復雜的數據集,所以只得到了略高于 80% 的精確度,甚至有時更低一些。
怎樣才能改善呢?如 AIA第六期:通過深度神經網絡再識 Estimator 中提到的那樣進行就好了。
轉為深度模型
切換到 DNNClassifier 就是換一行代碼的功夫,現在重新開始訓練,然后評估看看是否深度模型會比線性的好一些。
classifier = tf.estimator.DNNClassifier( feature_columns=feature_columns, n_classes=10, hidden_units=[100, 75, 50], model_dir=logdir )
正如第五期:通過 TensorBoard 將模型可視化 中討論的那樣,我們應當用 TensorBoard 來橫向并且比較一下兩個模型。
tensorboard --logdir=models/fashion_mnist/
瀏覽器打開 http://localhost:6006
TensorBoard
看看 Tensorboard,似乎深度模型并沒有比線性模型好到哪里去!這很可能是對超參數的微調不到位導致的,參見 AIA 第二期:機器學習常見的七個步驟。
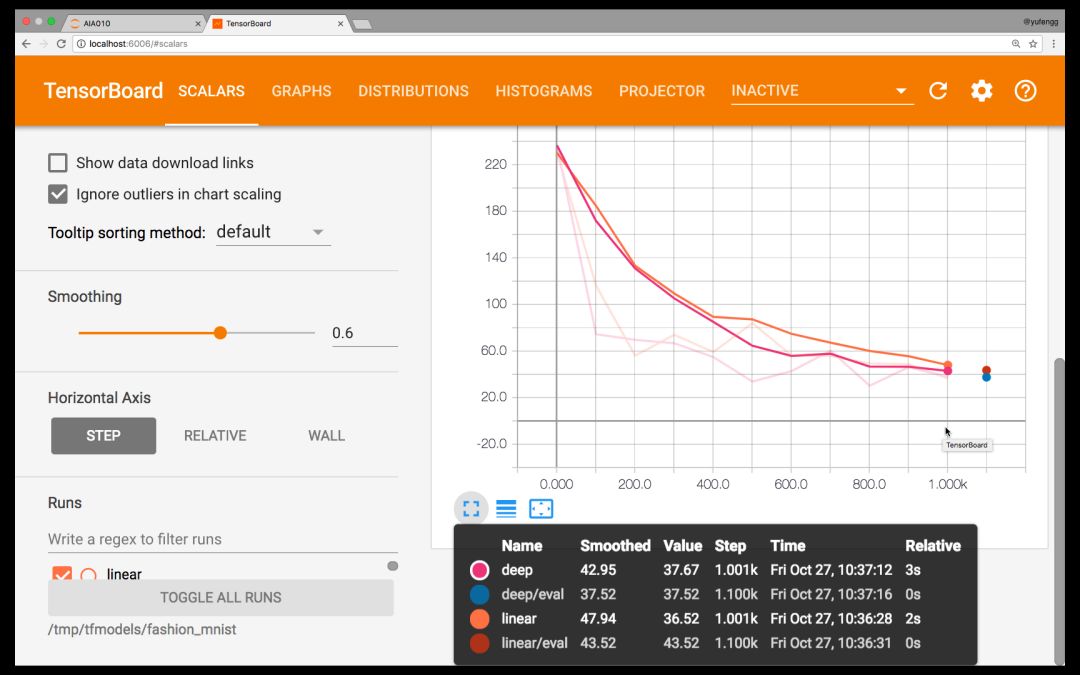
看起來好像是要一路飆到底…
也許是我們的模型需要更大一些來容納如此搞復雜度的模型?抑或訓練應該更少一些?我們來試試看。經過屢次調試微參數,模型的失真度突破性降低了,并且比線性模型得到的精度更高。
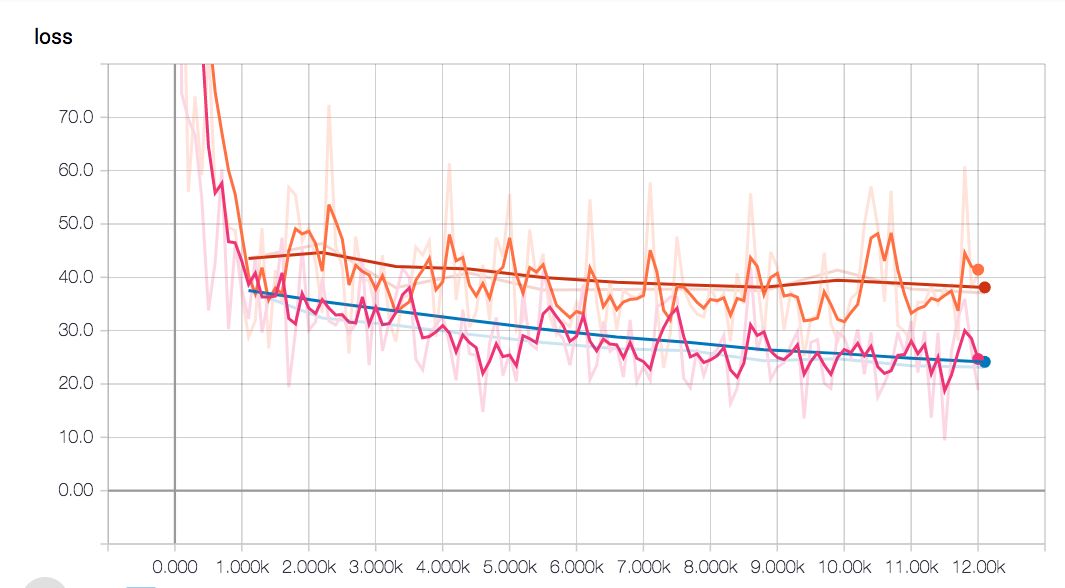
深度模型(藍色對比線性的紅色線)的失真度保持較低狀態
達到這一精度之前在訓練中多了些步驟,但是最終得到更高精度又使得這些付出非常值得。
由圖可見線性模型的平緩期來得比深度網絡要早。這是由于深度模型復雜度更高,它們需要的訓練時間更長。
此時,模型差不多滿足我們的要求了。我們可以將其導出,然后產生一個可伸縮的時尚版 MNIST classifier API。至于如何導出,可以參照第四期中給出的詳細步驟。
預測
我們快速回顧一下用評估器做預測的方法。很大程度上,它就像是我們訓練和評估的方式;這也是評估器(框架)的極大優勢——通用一致的函數接口。
X = DATA_SETS.test.images[5000:5005]predict_input_fn = tf.estimator.inputs.numpy_input_fn( x={'pixels': X}, batch_size=1, num_epochs=1, shuffle=False)predictions = classifier.predict( input_fn=predict_input_fn)
注意我們這次把 batch_size 指定為 1,num_epochs 指定為 1,shuffle 值為 false。這是因為我們想要按著順序一個一個的預測,一次在所有數據上進行預測。我從評估所用數據集中間挑選了 5 幅圖像用于預測。
我選擇這 5 幅的原因不僅僅是因為它們在正中間,還因為這些模型中有兩個是不正確的。兩個都應該是襯衫,但卻被模型認為第三個是包而第五個是大衣。由此,僅僅考慮圖像的紋理變化這個因素,你能看到這些樣本比起手寫數字來說是多么有挑戰性。
后續步驟
你可以在這個 Gist(鏈接在段后)上看到本次分享中所用來訓練和生成圖像的代碼。你的模型表現如何?你所最終采用的參數又是什么樣的?在評論當中分享一下吧!
https://gist.github.com/yufengg/2b2fd4b81b72f0f9c7b710fa87077145
精彩提要
后續的幾期將會著眼于機器學習生態的工具,從而幫助你創建自己的操作流程和工具鏈。與此同時也會展示更多可以用來解決機器學習問題的模型體系結構。我非常期待能在后面的分享中繼續為你分析解答!在那之前,不要忘了多使用機器學習!
-
線性
+關注
關注
0文章
196瀏覽量
25128 -
機器學習
+關注
關注
66文章
8381瀏覽量
132425 -
數據集
+關注
關注
4文章
1205瀏覽量
24648
原文標題:AIA 系列實戰篇 | 機器學習的「時尚版」Hello World
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
微雪Arduino系列教程五:Hello World
Android開發之“hello World”的實現

MICROCHIP MINUTES 4 - HELLO WORLD
【從零開始走進FPGA】 LCD1602 Hello World
米爾科技Linux簡單Hello World應用程序的教程
教你如何搭建淺層神經網絡"Hello world"
基于Nios 的 hello world

ZYNQ學習筆記_ZYNQ簡介和Hello World
Zynq上使用Vitis的雙ARM Hello World





 工商網監
工商網監
評論