") 機(jī)器學(xué)習(xí)中的特征選擇的5點(diǎn)詳細(xì)資料概述
機(jī)器學(xué)習(xí)中的特征選擇的5點(diǎn)詳細(xì)資料概述
1 特征選擇問(wèn)題的概念
我們能用很多屬性描述一個(gè)客觀世界中的對(duì)象,例如對(duì)于描述一個(gè)人來(lái)說(shuō),可以獲取到身高、體重、年齡、性別、學(xué)歷、收入等等,但對(duì)于評(píng)判一個(gè)人的信用級(jí)別來(lái)說(shuō),往往只需要獲取他的年齡、學(xué)歷、收入這些信息。換言之,對(duì)一個(gè)學(xué)習(xí)任務(wù)來(lái)說(shuō),給定屬性集,其中有些屬性可能很關(guān)鍵、很有用,另一些屬性則可能沒(méi)什么用。我們將屬性稱為“特征” (feature),對(duì)當(dāng)前學(xué)習(xí)任務(wù)有用的屬性稱為“相關(guān)特征” (relevant feature)、沒(méi)什么用的屬性稱為“無(wú)關(guān)特征” (irrelevant feature)。從給定的特征集合中選擇出相關(guān)特征子集的過(guò)程,稱為“特征選擇” (feature selection)。
特征選擇是一個(gè)重要的“數(shù)據(jù)預(yù)處理” (data preprocessing) 過(guò)程,在現(xiàn)實(shí)機(jī)器學(xué)習(xí)任務(wù)中,獲得數(shù)據(jù)之后通常先進(jìn)行特征選擇,此后再訓(xùn)練學(xué)習(xí)器。那么,為什么要進(jìn)行特征選擇呢?
有兩個(gè)很重要的原因:
我們?cè)诂F(xiàn)實(shí)任務(wù)中經(jīng)常會(huì)遇到維數(shù)災(zāi)難問(wèn)題,這是由于屬性過(guò)多造成的,若能從中選擇出重要的特征,使得后續(xù)學(xué)習(xí)過(guò)程僅需在一部分特征上構(gòu)建模型,則維數(shù)災(zāi)難問(wèn)題會(huì)大為減輕。
去除不相關(guān)特征往往會(huì)降低學(xué)習(xí)任務(wù)的難度,這就像偵探破案一樣,若將紛繁復(fù)雜的因素抽絲剝繭,只留下關(guān)鍵因素,則真相往往更易看清。
需要注意的是,特征選擇過(guò)程必須確保不丟失重要特征,否則后續(xù)學(xué)習(xí)過(guò)程會(huì)因?yàn)橹匾畔⒌娜笔Ф鵁o(wú)法獲得更好的性能。給定數(shù)據(jù)集,若學(xué)習(xí)任務(wù)不同,則相關(guān)特征很可能不同,因此,特征選擇中所謂的“無(wú)關(guān)特征”是指與當(dāng)前學(xué)習(xí)任務(wù)無(wú)關(guān)。有一類特征稱為“冗余特征” (redundant feature),它們所包含的信息能從其他特征中推演出來(lái)。例如,考慮立方體對(duì)象,若已有特征“底面長(zhǎng)”和“底面寬”,則“底面積”是冗余特征,因?yàn)樗軓那岸叩玫健H哂嗵卣髟诤芏鄷r(shí)候不起作用,去除它們會(huì)減輕學(xué)習(xí)過(guò)程的負(fù)擔(dān)。但有時(shí)冗余特征會(huì)降低學(xué)習(xí)任務(wù)的難度,例如若學(xué)習(xí)目標(biāo)是估算立方體的體積,則“底面積”這個(gè)冗余特征的存在將使得體積的估算更容易;更確切地說(shuō),若某個(gè)冗余特征恰好對(duì)應(yīng)了完成學(xué)習(xí)任務(wù)所需的“中間概念”,則該冗余特征是有益的。
2 子集搜索與評(píng)價(jià)
欲從初始的特征集合中選取一個(gè)包含了所有重要信息的特征子集,若沒(méi)有任何領(lǐng)域知識(shí)作為先驗(yàn)假設(shè),那就只好遍歷所有可能的子集了;然而這在計(jì)算上卻是不可行的,因?yàn)檫@樣做會(huì)遭遇組合爆炸,特征個(gè)數(shù)稍多就無(wú)法進(jìn)行。可行的做法是產(chǎn)生一個(gè)“候選子集”,評(píng)價(jià)出它的好壞,基于評(píng)價(jià)結(jié)果產(chǎn)生下一個(gè)候選子集,在對(duì)其進(jìn)行評(píng)價(jià),…… 這個(gè)過(guò)程持續(xù)進(jìn)行下去,直至無(wú)法找到更好的候選子集為止。顯然,這里涉及兩個(gè)關(guān)鍵環(huán)節(jié):如何根據(jù)評(píng)價(jià)結(jié)果獲取下一個(gè)候選特征子集?如何評(píng)價(jià)候選特征子集的好壞?
第一個(gè)環(huán)節(jié)是“子集搜索” (subset search) 問(wèn)題。給定特征集合{a1,a2,…,ad},我們可將每個(gè)特征看作一個(gè)候選子集,對(duì)這d個(gè)候選單特征子集進(jìn)行評(píng)價(jià),假定{a2}最優(yōu),于是將{a2}作為第一輪的選定集;然后,在上一輪的選定集中加入一個(gè)特征,構(gòu)成包含兩個(gè)特征的候選子集,假定在這d?1個(gè)候選兩特征子集中{a2,a4}最優(yōu),且優(yōu)于{a2},于是將{a2,a4}作為本輪的選定集;…… 假定在第k+1輪時(shí),最優(yōu)的候選(k+1)特征子集不如上一輪的選定集,則停止生成候選子集,并將上一輪選定的k特征集合作為特征選擇結(jié)果。這樣逐漸增加相關(guān)特征的策略稱為“前向” (forward) 搜索。類似的,若我們從完整的特征集合開(kāi)始,每次嘗試去掉一個(gè)無(wú)關(guān)特征,這樣逐漸減少特征的策略稱為“后向” (backward) 搜索。還可將前向與后向搜索結(jié)合起來(lái),每一輪逐漸增加選定相關(guān)特征 (這些特征在后續(xù)輪中將確定不會(huì)被去除)、同時(shí)減少無(wú)關(guān)特征,這樣的策略稱為“雙向” (bidirectional) 搜索。
顯然,上述策略都是貪心的,因?yàn)樗鼈儍H考慮了使本輪選定集最優(yōu),例如在第三輪假定選擇a5優(yōu)于a6,于是選定集為{a2,a4,a5},然而在第四輪中卻可能是{a2,a4,a6,a8}比所有的{a2,a4,a5,ai}都更優(yōu)。遺憾的是,若不進(jìn)行窮舉搜索,則這樣的問(wèn)題無(wú)法避免。
第二個(gè)環(huán)節(jié)是“子集評(píng)價(jià)” (subset evaluation) 問(wèn)題。給定數(shù)據(jù)集DD,假定D中第i類樣本所占的比例為pi(i=1,2,…,∣Y∣)。為便于討論,假定樣本屬性均為離散型。對(duì)于屬性子集A,假定根據(jù)其取值將D分成了V個(gè)子集{D1,D1,…,DV},每個(gè)子集中的樣本在A上取值相同,于是我們可計(jì)算屬性子集A的信息增益:
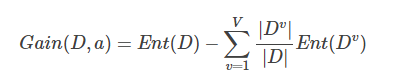
其中信息熵定義為:
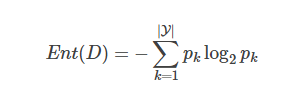
信息增益越大,意味著特征子集A包含的有助于分類的信息越多。于是,對(duì)每個(gè)候選特征子集,我們可基于訓(xùn)練數(shù)據(jù)集D來(lái)計(jì)算其信息增益,以此作為評(píng)價(jià)準(zhǔn)則。
更一般的,特征子集A實(shí)際上確定了對(duì)數(shù)據(jù)集D的一個(gè)劃分,每個(gè)劃分區(qū)域?qū)?yīng)著A上的一個(gè)取值,而樣本標(biāo)記信息Y則對(duì)應(yīng)著對(duì)D的真是劃分,通過(guò)估算這兩個(gè)劃分的差異,就能對(duì)A進(jìn)行評(píng)價(jià)。與Y對(duì)應(yīng)的劃分的差異越小,則說(shuō)明A越好。信息熵僅是判斷這個(gè)差異的一種途徑,其他能判斷兩個(gè)劃分差異的機(jī)制都能用于特征子集評(píng)價(jià)。
將特征子集搜索機(jī)制與子集評(píng)價(jià)機(jī)制相結(jié)合,即可得到特征選擇方法。例如將前向搜索與信息熵結(jié)合,這顯然與決策樹(shù)算法非常相似。事實(shí)上,決策樹(shù)可用于特征選擇,樹(shù)節(jié)點(diǎn)的劃分屬性所組成的集合就是選擇出的特征子集。其他的特征選擇方法未必像決策樹(shù)特征選擇這么明顯,但它們?cè)诒举|(zhì)上都是顯式或隱式地結(jié)合了某種 (或多種) 子集搜索機(jī)制和子集評(píng)價(jià)機(jī)制。
常見(jiàn)的特征選擇方法大致可分為三類:過(guò)濾式 (filter)、包裹式 (wrapper) 和嵌入式 (embedding)。
3 過(guò)濾式選擇
過(guò)濾式方法先對(duì)數(shù)據(jù)集進(jìn)行特征選擇,然后再訓(xùn)練學(xué)習(xí)器,特征選擇過(guò)程與后續(xù)學(xué)習(xí)器無(wú)關(guān)。這相當(dāng)于先用特征選擇過(guò)程對(duì)初始特征進(jìn)行“過(guò)濾”,再用過(guò)濾后的特征來(lái)訓(xùn)練模型。
Relief (Relevant Features) [Kira and Rendell, 1992] 是一種著名的過(guò)濾式特征選擇方法,該方法設(shè)計(jì)了一個(gè)“相關(guān)統(tǒng)計(jì)量”來(lái)度量特征的重要性。該統(tǒng)計(jì)量是一個(gè) 向量,其每個(gè)分量分別對(duì)應(yīng)于一個(gè)初始特征,而特征子集的重要性則是由子集中每個(gè)特征所對(duì)應(yīng)的相關(guān)統(tǒng)計(jì)量分量之和來(lái)決定。于是,最終只需指定一個(gè)閾值ττ,然后選擇比ττ大的相關(guān)統(tǒng)計(jì)量分量所對(duì)應(yīng)的特征即可;也可以指定欲選取的特征個(gè)數(shù)k,然后選擇相關(guān)統(tǒng)計(jì)量分量最大的k個(gè)特征。
顯然,Relief 的關(guān)鍵是如何確定相關(guān)統(tǒng)計(jì)量。給定訓(xùn)練集{(x1,y1),(x2,y2),…,(xm,ym)},對(duì)每個(gè)示例xi,Relief 先在xi的同類樣本中尋找其最鄰近xi,nh,稱為“猜中鄰近” (near-hit),在從xi的異類樣本中尋找其最近鄰xi,nm,稱為“猜錯(cuò)鄰近” (near-miss),然后,想干統(tǒng)計(jì)量對(duì)應(yīng)于屬性j的分量為:
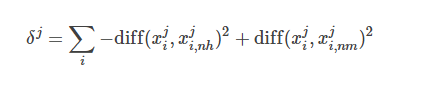

從上式可看出,若樣本與其猜中近鄰在某一屬性上的距離小于該樣本與其猜錯(cuò)近鄰的距離,則說(shuō)明這一屬性對(duì)區(qū)分同類與異類樣本是有益的,于是增大該屬性對(duì)應(yīng)的統(tǒng)計(jì)量分量;反之,則說(shuō)明該屬性起負(fù)面作用,于是減小其對(duì)應(yīng)的統(tǒng)計(jì)量分量。最后,對(duì)基于不同樣本得到的估計(jì)結(jié)果進(jìn)行平均,就得到各屬性的相關(guān)統(tǒng)計(jì)量分量,分量值越大,則對(duì)應(yīng)屬性的分類能力就越強(qiáng)。
4 包裹式選擇
與過(guò)濾式特征選擇不考慮后續(xù)學(xué)習(xí)器不同,包裹式特征選擇直接把最終將要使用的學(xué)習(xí)器的性能作為特征子集的評(píng)價(jià)準(zhǔn)則。換言之,包裹式特征選擇的目的就是為給定學(xué)習(xí)器選擇最有利于其性能、“量身定做”的特征子集。
一般而言,由于包裹式特征選擇方法直接針對(duì)給定學(xué)習(xí)器進(jìn)行優(yōu)化,因此從最終學(xué)習(xí)器性能來(lái)看,包裹式特征選擇比過(guò)濾式特征選擇更好,但另一方面,由于在特征選擇過(guò)程中需多次訓(xùn)練學(xué)習(xí)器,因此包裹式特征選擇的計(jì)算開(kāi)銷通常比過(guò)濾式特征選擇大得多。
LVM (Las Vegas Wrapper) [Liu and Setiono, 1996] 是一個(gè)典型的包裹式特征選擇方法。它在拉斯維加斯方法 (Las Vegas method) 框架下使用隨機(jī)策略來(lái)進(jìn)行子集搜索,并以最終分類器的誤差為特征子集評(píng)價(jià)準(zhǔn)則。該算法是通過(guò)在數(shù)據(jù)集D上,使用交叉驗(yàn)證法來(lái)估計(jì)學(xué)習(xí)器L的誤差,注意這個(gè)誤差是在僅考慮特征子集A′時(shí)得到的,即特征子集A′中包含的特征數(shù)更少,則將A′保留下來(lái)。
需注意的是,由于 LVW 算法中特征子集搜索采用了隨機(jī)策略,而每次特征子集評(píng)價(jià)都需要訓(xùn)練學(xué)習(xí)器,計(jì)算開(kāi)銷很大,因此算法設(shè)置了停止條件控制參數(shù)T。然而,整個(gè) LVM 算法是基于拉斯維加斯方法框架,若初始特征數(shù)很多(即∣A∣很大) 、T設(shè)置較大,則算法可能運(yùn)行很長(zhǎng)時(shí)間都達(dá)不到停止條件。換言之,若有運(yùn)行時(shí)間限制,則有可能給不出解。
5 嵌入式選擇與L1正則化
在過(guò)濾式和包裹式特征選擇方法中,特征選擇過(guò)程與學(xué)習(xí)器訓(xùn)練過(guò)程有明顯的分別;與此不同,嵌入式特征選擇是特征選擇過(guò)程與學(xué)習(xí)器訓(xùn)練過(guò)程融為一體,兩者在同一個(gè)優(yōu)化過(guò)程中完成,即在學(xué)習(xí)器訓(xùn)練過(guò)程中自動(dòng)地進(jìn)行了特征選擇。
給定數(shù)據(jù)集D={(x1,y1),(x2,y2),…,(xm,ym)},其中x∈R,y∈R。考慮最簡(jiǎn)單的線性模型回歸模型,以平方誤差為損失函數(shù),則優(yōu)化目標(biāo)為:
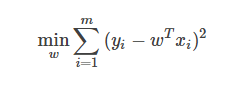
當(dāng)樣本特征很多,而樣本數(shù)相對(duì)較少時(shí),上式很容易陷入過(guò)擬合。為了緩解過(guò)擬合問(wèn)題,可對(duì)上式引入正則化想。若使用L2L2范數(shù)正則化,則有:
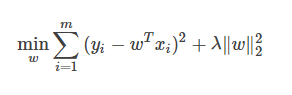
其中正則化參數(shù)λ>0。上式也稱為“嶺回歸” (ridge regression) [Tikhonov and Arsenin, 1977],通過(guò)引入L2范數(shù)正則化,確能顯著降低過(guò)擬合的風(fēng)險(xiǎn)。
那么,能否將正則化項(xiàng)中的L2范數(shù)替換為L(zhǎng)p范數(shù)呢?答案是肯定的。若令p=1,即采用L1范數(shù),則有:
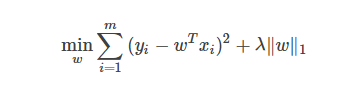
其中正則化參數(shù)λ>0。上式稱為 LASSO (Least Absolute Shrinkage and Selection Operator) [Tibshirani, 1996]。
L1范數(shù)和L2范數(shù)正則化都有助于降低過(guò)擬合風(fēng)險(xiǎn),但L1范數(shù)還會(huì)帶來(lái)一個(gè)額外的好處:它比L2范數(shù)更易于獲得“稀疏” (sparse) 解,即它求得的w會(huì)有更少的非零分量。
注意到w取得稀疏解意味著初始的d個(gè)特征中僅有對(duì)應(yīng)著w的非零分量的特征才會(huì)出現(xiàn)在最終模型中,于是,求解L1范數(shù)正則化的結(jié)果是得到了僅采用一部分初始特征的模型;換言之,基于L1正則化的學(xué)習(xí)方法就是一種嵌入式特征選擇方法,其特征選擇過(guò)程與學(xué)習(xí)器訓(xùn)練過(guò)程融為一體,同時(shí)完成。
-
嵌入式
+關(guān)注
關(guān)注
5072文章
19026瀏覽量
303516 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8382瀏覽量
132444 -
特征選擇
+關(guān)注
關(guān)注
0文章
12瀏覽量
7171
原文標(biāo)題:機(jī)器學(xué)習(xí)中的特征選擇
文章出處:【微信號(hào):AI_shequ,微信公眾號(hào):人工智能愛(ài)好者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Stellaris系列產(chǎn)品的選擇詳細(xì)資料概述
工業(yè)機(jī)器人配件選型手冊(cè)的詳細(xì)資料概述(免費(fèi)下載)
C語(yǔ)言教程之如何選擇結(jié)構(gòu)程序設(shè)計(jì)的詳細(xì)資料概述

機(jī)器學(xué)習(xí)算法中的ID3算法詳細(xì)資料合集免費(fèi)下載
機(jī)器學(xué)習(xí)算法中的FSS算法詳細(xì)資料合集免費(fèi)下載
機(jī)器學(xué)習(xí)matlab源代碼的詳細(xì)資料免費(fèi)下載
PHP基礎(chǔ)學(xué)習(xí)知識(shí)點(diǎn)詳細(xì)資料匯總免費(fèi)下載

STM32Cube學(xué)習(xí)教程之時(shí)鐘樹(shù)配置的詳細(xì)資料概述
工業(yè)機(jī)器人的詳細(xì)資料和應(yīng)用編程等培訓(xùn)資料概述
DSP入門學(xué)習(xí)必看的一些知識(shí)點(diǎn)詳細(xì)概述
python的內(nèi)置函數(shù)詳細(xì)資料概述
5G概述和基本原理的詳細(xì)資料說(shuō)明
機(jī)器學(xué)習(xí)教程之線性模型的詳細(xì)資料說(shuō)明

機(jī)器學(xué)習(xí)的模型評(píng)估與選擇詳細(xì)資料說(shuō)明







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論