 Linux以inode的方式,讓數據形成文件
Linux以inode的方式,讓數據形成文件
Linux文件管理從用戶的層面介紹了Linux管理文件的方式。Linux有一個樹狀結構來組織文件。樹的頂端為根目錄(/),節點為目錄,而末端的葉子為包含數據的文件。當我們給出一個文件的完整路徑時,我們從根目錄出發,經過沿途各個目錄,最終到達文件。
我們可以對文件進行許多操作,比如打開和讀寫。在Linux文件管理相關命令中,我們看到許多對文件進行操作的命令。它們大都基于對文件的打開和讀寫操作。比如cat可以打開文件,讀取數據,最后在終端顯示:
$cat test.txt
對于Linux下的程序員來說,了解文件系統的底層組織方式,是深入進行系統編程所必備的。即使是普通的Linux用戶,也可以根據相關的內容,設計出更好的系統維護方案。
存儲設備分區
文件系統的最終目的是把大量數據有組織的放入持久性(persistant)的存儲設備中,比如硬盤和磁盤。這些存儲設備與內存不同。它們的存儲能力具有持久性,不會因為斷電而消失;存儲量大,但讀取速度慢。
觀察常見存儲設備。最開始的區域是MBR,用于Linux開機啟動(參考Linux開機啟動)。剩余的空間可能分成數個分區(partition)。每個分區有一個相關的分區表(Partition table),記錄分區的相關信息。這個分區表是儲存在分區之外的。分區表說明了對應分區的起始位置和分區的大小。
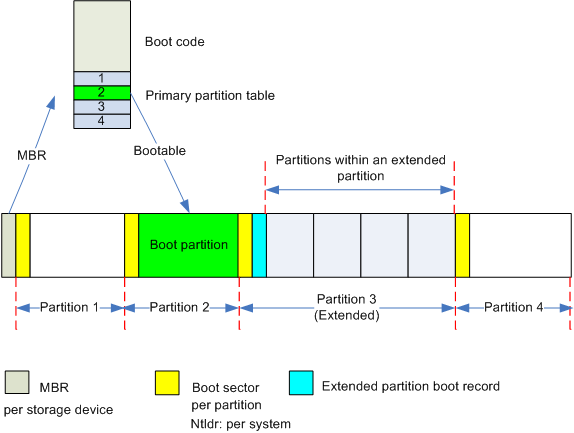
我們在Windows系統常常看到C分區、D分區等。Linux系統下也可以有多個分區,但都被掛載在同一個文件系統樹上。
數據被存入到某個分區中。一個典型的Linux分區(partition)包含有下面各個部分:
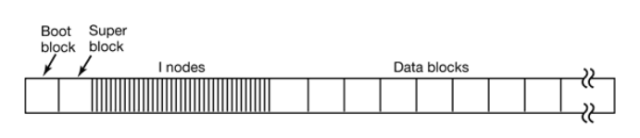
分區的第一個部分是啟動區(Boot block),它主要是為計算機開機服務的。Linux開機啟動后,會首先載入MBR,隨后MBR從某個硬盤的啟動區加載程序。該程序負責進一步的操作系統的加載和啟動。為了方便管理,即使某個分區中沒有安裝操作系統,Linux也會在該分區預留啟動區。
啟動區之后的是超級區(Super block)。它存儲有文件系統的相關信息,包括文件系統的類型,inode的數目,數據塊的數目。
隨后是多個inodes,它們是實現文件存儲的關鍵。在Linux系統中,一個文件可以分成幾個數據塊存儲,就好像是分散在各地的龍珠一樣。為了順利的收集齊龍珠,我們需要一個“雷達”的指引:該文件對應的inode。每個文件對應一個inode。這個inode中包含多個指針,指向屬于該文件各個數據塊。當操作系統需要讀取文件時,只需要對應inode的”地圖”,收集起分散的數據塊,就可以收獲我們的文件了。
最后一部分,就是真正儲存數據的數據塊們(data blocks)了。
inode簡介
上面我們看到了存儲設備的宏觀結構。我們要深入到分區的結構,特別是文件在分區中的存儲方式。
文件是文件系統對數據的分割單元。文件系統用目錄來組織文件,賦予文件以上下分級的結構。在硬盤上實現這一分級結構的關鍵,是使用inode來虛擬普通文件和目錄文件對象。
在Linux文件管理中,我們知道,一個文件除了自身的數據之外,還有一個附屬信息,即文件的元數據(metadata)。這個元數據用于記錄文件的許多信息,比如文件大小,擁有人,所屬的組,修改日期等等。元數據并不包含在文件的數據中,而是由操作系統維護的。事實上,這個所謂的元數據就包含在inode中。我們可以用$ls -l filename來查看這些元數據。正如我們上面看到的,inode所占據的區域與數據塊的區域不同。每個inode有一個唯一的整數編號(inode number)表示。
在保存元數據,inode是“文件”從抽象到具體的關鍵。正如上一節中提到的,inode儲存由一些指針,這些指針指向存儲設備中的一些數據塊,文件的內容就儲存在這些數據塊中。當Linux想要打開一個文件時,只需要找到文件對應的inode,然后沿著指針,將所有的數據塊收集起來,就可以在內存中組成一個文件的數據了。
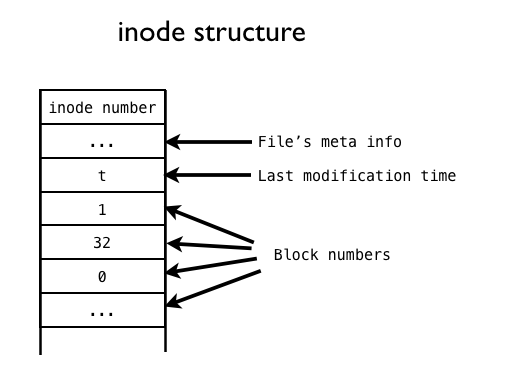
數據塊在1, 32, 0, …
inode并不是組織文件的唯一方式。最簡單的組織文件的方法,是把文件依次順序的放入存儲設備,DVD就采取了類似的方式。但如果有刪除操作,刪除造成的空余空間夾雜在正常文件之間,很難利用和管理。
復雜的方式可以使用鏈表,每個數據塊都有一個指針,指向屬于同一文件的下一個數據塊。這樣的好處是可以利用零散的空余空間,壞處是對文件的操作必須按照線性方式進行。如果想隨機存取,那么必須遍歷鏈表,直到目標位置。由于這一遍歷不是在內存進行,所以速度很慢。
FAT系統是將上面鏈表的指針取出,放入到內存的一個數組中。這樣,FAT可以根據內存的索引,迅速的找到一個文件。這樣做的主要問題是,索引數組的大小與數據塊的總數相同。因此,存儲設備很大的話,這個索引數組會比較大。
inode既可以充分利用空間,在內存占據空間不與存儲設備相關,解決了上面的問題。但inode也有自己的問題。每個inode能夠存儲的數據塊指針總數是固定的。如果一個文件需要的數據塊超過這一總數,inode需要額外的空間來存儲多出來的指針。
inode示例
在Linux中,我們通過解析路徑,根據沿途的目錄文件來找到某個文件。目錄中的條目除了所包含的文件名,還有對應的inode編號。當我們輸入$cat /var/test.txt時,Linux將在根目錄文件中找到var這個目錄文件的inode編號,然后根據inode合成var的數據。隨后,根據var中的記錄,找到text.txt的inode編號,沿著inode中的指針,收集數據塊,合成text.txt的數據。整個過程中,我們參考了三個inode:根目錄文件,var目錄文件,text.txt文件的inodes。
在Linux下,可以使用$stat filename,來查詢某個文件對應的inode編號。
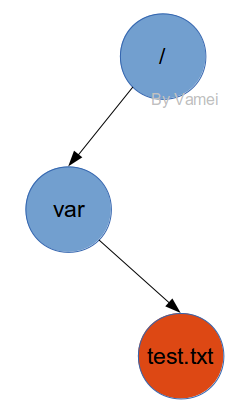
在存儲設備中實際上存儲為:
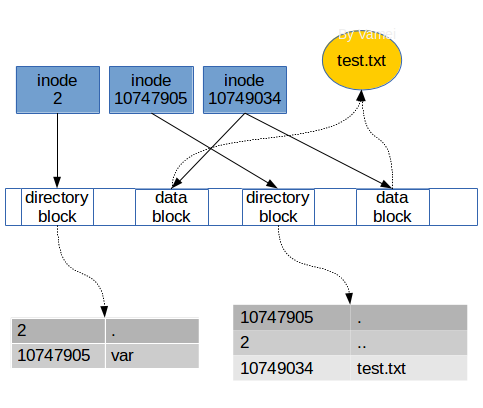
當我們讀取一個文件時,實際上是在目錄中找到了這個文件的inode編號,然后根據inode的指針,把數據塊組合起來,放入內存供進一步的處理。當我們寫入一個文件時,是分配一個空白inode給該文件,將其inode編號記入該文件所屬的目錄,然后選取空白的數據塊,讓inode的指針指像這些數據塊,并放入內存中的數據。
文件共享
在Linux的進程中,當我們打開一個文件時,返回的是一個文件描述符。這個文件描述符是一個數組的下標,對應數組元素為一個指針。有趣的是,這個指針并沒有直接指向文件的inode,而是指向了一個文件表格,再通過該表格,指向加載到內存中的目標文件的inode。如下圖,一個進程打開了兩個文件。
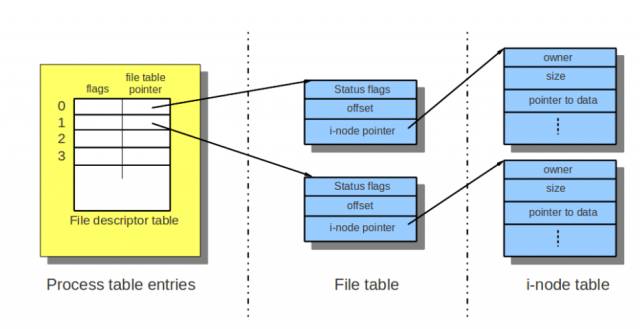
可以看到,每個文件表格中記錄了文件打開的狀態(status flags),比如只讀,寫入等,還記錄了每個文件的當前讀寫位置(offset)。當有兩個進程打開同一個文件時,可以有兩個文件表格,每個文件表格對應的打開狀態和當前位置不同,從而支持一些文件共享的操作,比如同時讀取。
要注意的是進程fork之后的情況,子進程將只復制文件描述符的數組,而和父進程共享內核維護的文件表格和inode。此時要特別小心程序的編寫。
總結
這里概括性的總結了Linux的文件系統。Linux以inode的方式,讓數據形成文件。
-
硬盤
+關注
關注
3文章
1290瀏覽量
57233 -
Linux
+關注
關注
87文章
11227瀏覽量
208921 -
存儲設備
+關注
關注
0文章
159瀏覽量
18573
原文標題:Linux文件系統的實現
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Linux文件恢復的實現
Linux下的inode的理解
linux下利用inode刪除指定文件文件

inode是理解Unix/Linux文件系統和硬盤儲存的基礎







 工商網監
工商網監
評論