 深度學習高效化與專用處理芯片設計
深度學習高效化與專用處理芯片設計
“夫因樸生文,因拙生巧,相因相生,以至今日。”在人工智能領域,機器學習研究與芯片行業的發展,即是一個相因相生的過程。自第一個深度網絡提出,深度學習歷經幾次寒冬,直至近年,才真正帶來一波AI應用的浪潮,這很大程度上歸功于GPU處理芯片的發展。與此同時,由于AI應用場景的多元化,深度學習在端側的應用需求日益迫切,也促使芯片行業開展面向深度學習的專用芯片設計。如果能夠將深度算法與芯片設計相結合,將大大拓展AI的應用邊界,真正將智能從云端落地。本文中,來自中科院自動化所的程健研究員,將帶著大家一方面探索如何將深度學習高效化,另一方面討論如何針對深度算法來設計專用處理芯片。文末,提供文中提到參考文獻的下載鏈接。
上圖是本次匯報的大綱,主要從深度學習發展現狀、面臨的挑戰、神經網絡加速算法設計、深度學習芯片設計和對未來的展望五個方面來展開。

首先我們來看一下深度學習的發展現狀。毋庸置疑的是深度學習目前在各個領域都取得了一些突破性的進展,上圖展示了深度學習目前廣泛應用的領域。

深度學習近年來取得的長足發展離不開三個方面,上圖展示了其不可或缺的三個要素。一是隨著互聯網的發展產生的大數據,二是游戲行業的發展促使的如GPU計算資源的迅速發展,三是近年來研究者們對于深度學習模型的研究。在目前的情況下,給定一個應用場景,我們可以使用大量的數據和計算資源搭建非常深的網絡模型來達到比較高的性能。然而在實際應用中,這些復雜網絡由于需要很高的計算量難以很好地部署到設備上以滿足實際應用的需求,所以如何減少深度神經網絡計算量,成為深度學習領域中的研究熱點。

另一方面,面向深度學習設計的芯片也受到了越來越多的關注。目前一些通用的芯片如CPU不能很好地適應神經網絡這種計算量非常密集的操作,而計算能力強大的GPU由于其價格和功耗因素很難在大量終端設備上部署。所以如何設計一個面向深度學習的專用芯片達到速度和功耗的要求是目前比較火熱的研究方向。

雖然現在對神經網絡模型設計和深度學習芯片設計的研究很多,但依舊面臨很多挑戰。
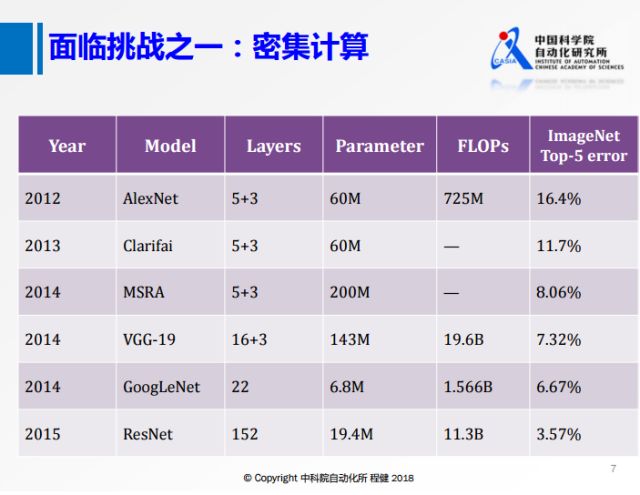
面臨的挑戰之一是越來越復雜的網絡模型,上圖展示了近年來主流網絡模型的參數和計算量等信息。可以看出隨著網絡規模越來越大,網絡結構越來越復雜,由此帶來的越來越大的計算量會是一個挑戰。

面臨的挑戰之二是深度學習復雜多變的應用場景,主要包括在移動設備上算不好、穿戴設備上算不了、數據中心算不起三個方面。由于移動設備和可穿戴設備本身硬件比較小,允許運行的計算量非常有限,在面臨非常復雜多變的應用場景的時候,往往不能滿足實際需求。而目前存在的一些移動中心的計算由于其代價昂貴使得大多數人只能望而卻步。
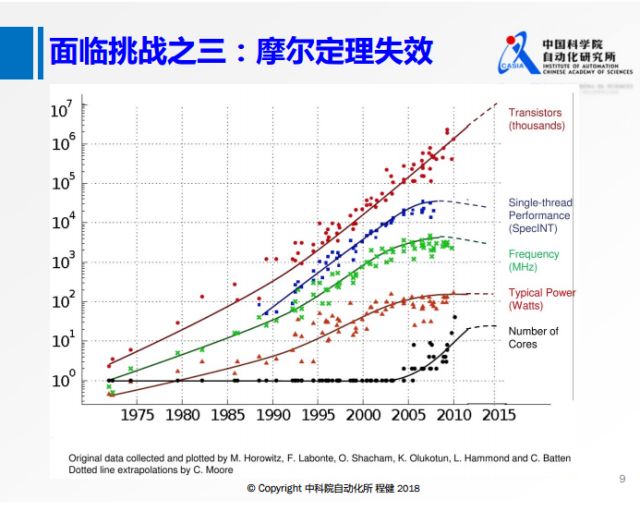
面臨的挑戰之三是近年來摩爾定理隨著時間推移的失效,不能像以前一樣僅僅依靠在硬件上堆疊晶體管來實現物理層面的性能提升。

目前深度學習面臨的三個挑戰促使我們從兩個方面去思考,一是網絡模型本身優化的問題,二是設計面向深度學習專用芯片來實現神經網絡的高效計算。下面分別從這兩個方面進行闡述。
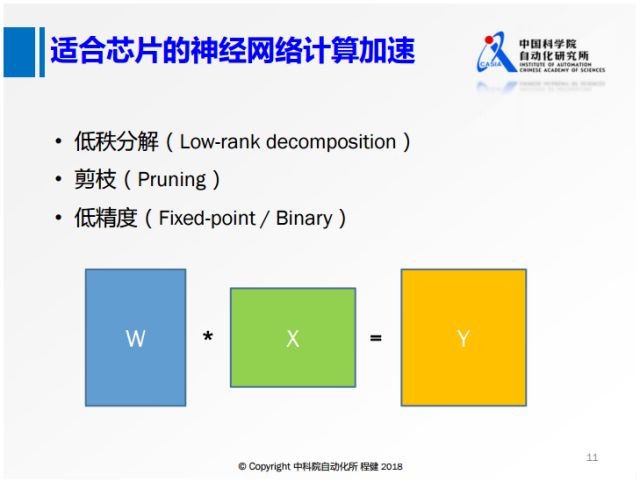
在深度學習模型的優化計算方面,包括一些最近幾年研究的工作,上圖展示了三種方式,下面主要列出了一些比較適合芯片的神經網絡加速計算的方法。
首先對于神經網絡大部分的計算,無論是卷積層還是全連接層都可以轉換成矩陣乘的基礎操作,上圖展示了這個過程,所以對矩陣乘進行加速的方法都可以引入到神經網絡的加速中來,包括低秩分解、網絡稀疏化、低精度表示等方法。
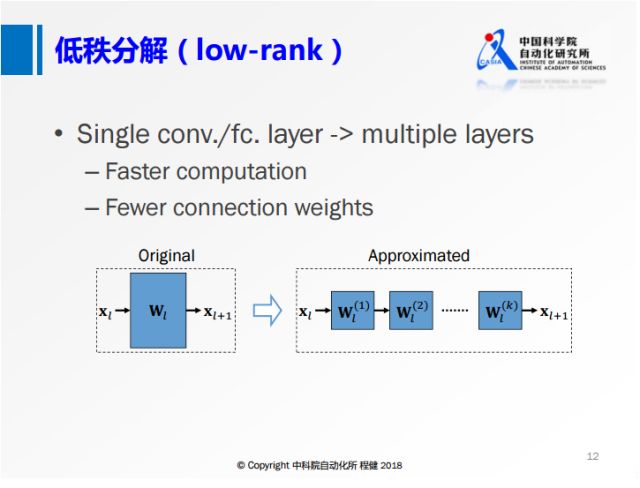
上圖展示了低秩分解的基本思想,將原來大的權重矩陣分解成多個小的矩陣,右邊的小矩陣的計算量都比原來大矩陣的計算量要小,這是低秩分解的基本出發點。
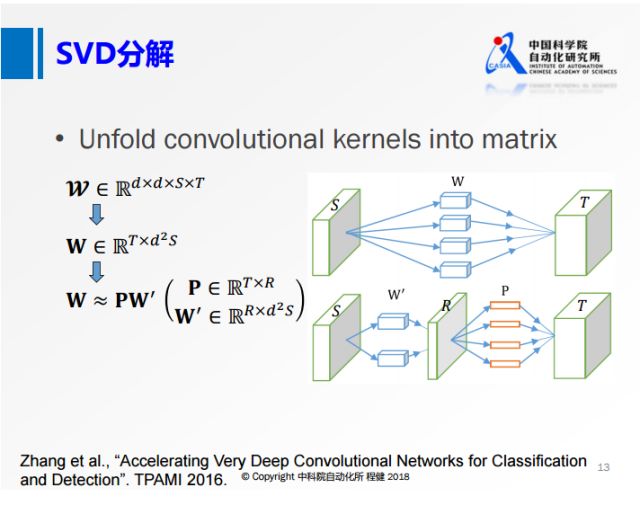
低秩分解有很多方法,最基本的是奇異值分解SVD。上圖是微軟在2016年的工作,將卷積核矩陣先做成一個二維的矩陣,再做SVD分解。上圖右側相當于用一個R的卷積核做卷積,再對R的特征映射做深入的操作。從上面可以看到,雖然這個R的秩非常小,但是輸入的通道S還是非常大的。
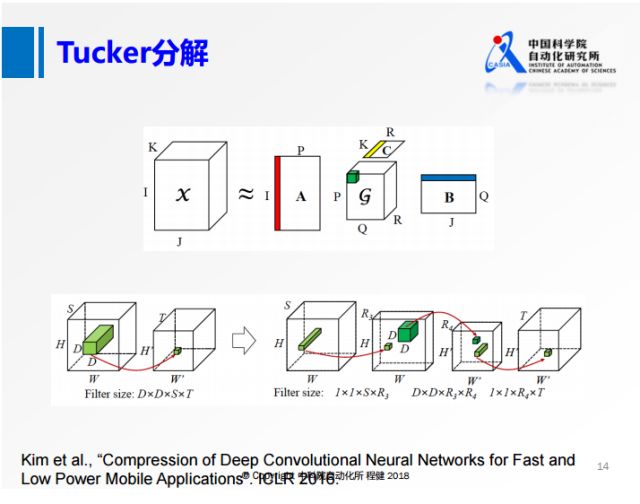
為了解決SVD分解過程中通道S比較大的問題,我們從另一個角度出發,沿著輸入的方向對S做降維操作,這就是上圖展示的Tucker分解的思想。具體操作過程是:將原來的卷積,首先在S維度上做一個低維的表達,再做一個正常的3×3的卷積,最后再做一個升維的操作。
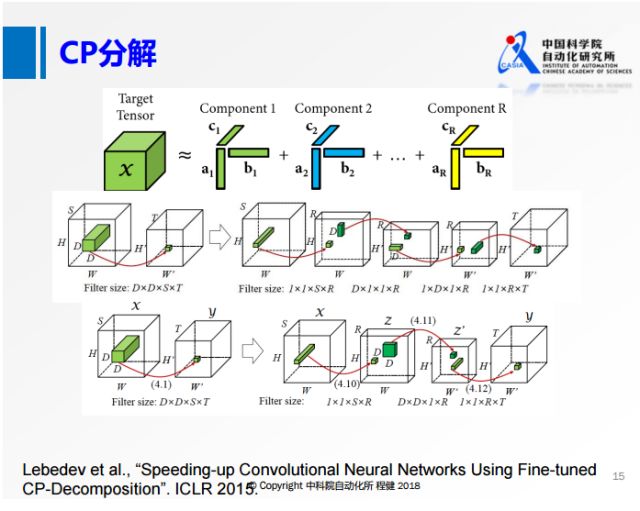
在SVD分解和Tucker分解之后的一些工作主要是做了更進一步的分解。上圖展示了使用微調的CP分解加速神經網絡的方法。在原來的四維張量上,在每個維度上都做類似1×1的卷積,轉化為第二行的形式,在每一個維度上都用很小的卷積核去做卷積。在空間維度上,大部分都是3×3的卷積,所以空間的維度很小,可以轉化成第三行的形式,在輸入和輸出通道上做低維分解,但是在空間維度上不做分解,類似于MobileNet。
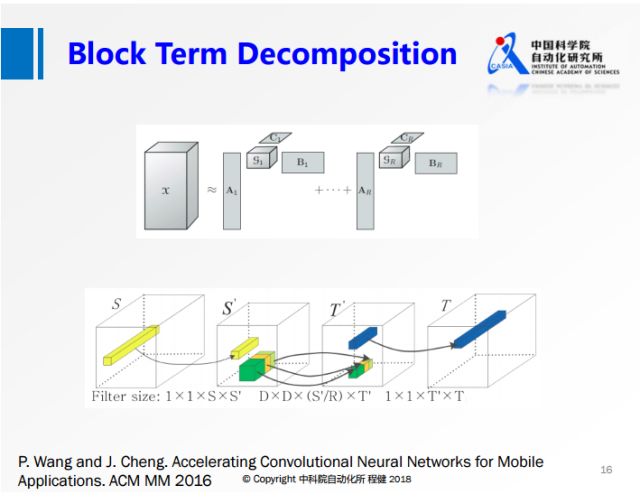
上圖展示了我們在2016年的工作,結合了上述兩種分解方法各自的優勢。首先把輸入參數做降維,然后在第二個卷積的時候,做分組操作,這樣可以降低第二個3×3卷積的計算量,最后再做升維操作。另一方面由于分組是分塊卷積,它是有結構的稀疏,所以在實際中可以達到非常高的加速,我們使用VGG網絡在手機上的實驗可以達到5-6倍的實際加速效果。
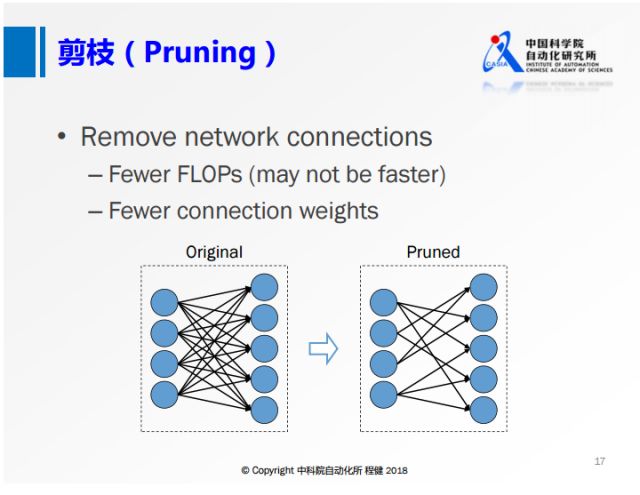
第二個方面是網絡的剪枝,基本思想是刪除卷積層中一些不重要的連接。
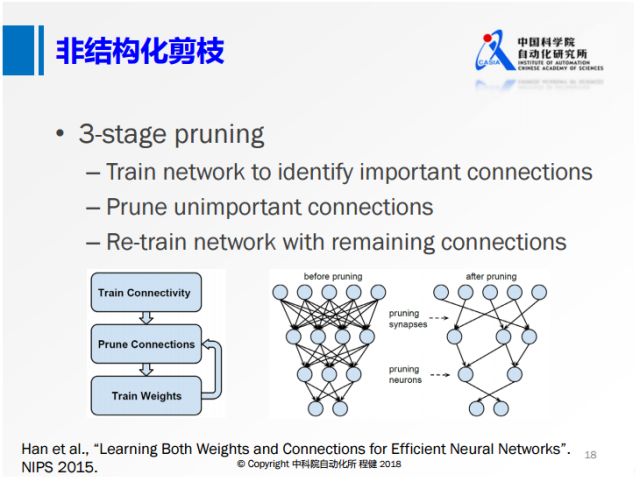
上圖展示了在NIP2015上提出的非常經典的三階段剪枝的方法。首先訓練一個全精度網絡,隨后刪除一些不重要的節點,后面再去訓練權重。這種非結構化的剪枝的方法,雖然它的理論計算量可以壓縮到很低,但是收益是非常低的,比如在現在的CPU或者GPU框架下很難達到非常高的加速效果。所以下面這種結構化的剪枝技術越來越多。
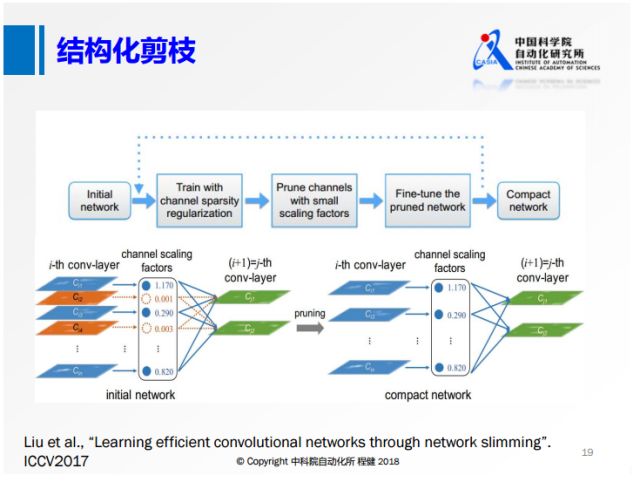
從去年的ICCV就有大量基于channel sparsity的工作。上面是其中的一個示意圖,相當于對每一個feature map定義其重要性,把不重要的給刪除掉,這樣產生的稀疏就是有規則的,我們可以達到非常高的實際加速效果。
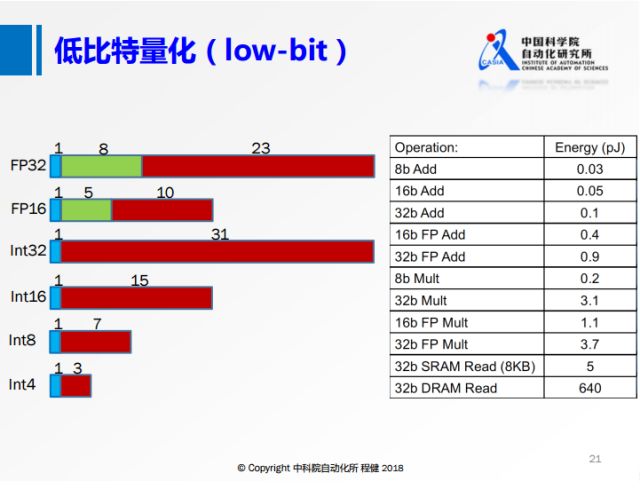
第三個方面是低比特量化,上圖展示了具體操作方法。目前的低比特量化方法和上面提到的低秩分解、網絡剪枝這兩種方法是可結合的。左側是不同的比特數在計算機上的存儲方式,右側是不同操作的功耗。可以看出來低比特的功耗遠遠小于高比特浮點數操作的功耗。

上圖是在定點表示里面最基本的方法:BNN和BWN。在網絡進行計算的過程中,可以使用定點的數據進行計算,由于是定點計算,實際上是不可導的,于是提出使用straight-through方法將輸出的估計值直接傳給輸入層做梯度估計。在網絡訓練過程中會保存兩份權值,用定點的權值做網絡前向后向的計算,整個梯度累積到浮點的權值上,整個網絡就可以很好地訓練,后面幾乎所有的量化方法都會沿用這種訓練的策略。前面包括BNN這種網絡在小數據集上可以達到跟全精度網絡持平的精度,但是在ImageNet這種大數據集上還是表現比較差。
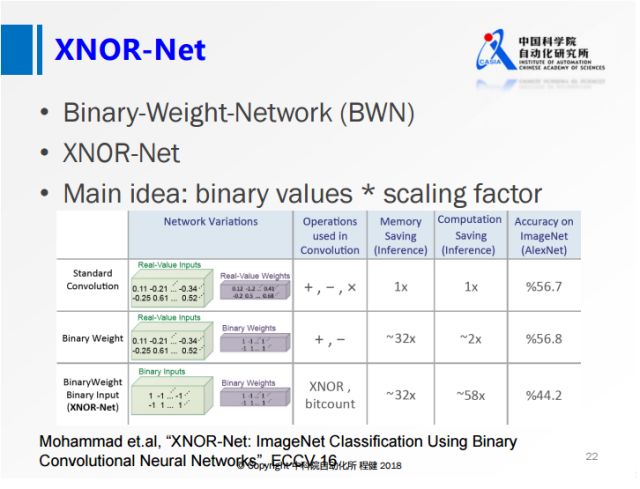
上圖展示了ECCV2016上一篇名為XNOR-Net的工作,其思想相當于在做量化的基礎上,乘了一個尺度因子,這樣大大降低了量化誤差。他們提出的BWN,在ImageNet上可以達到接近全精度的一個性能,這也是首次在ImageNet數據集上達到這么高精度的網絡。

上圖展示了阿里巴巴冷聰等人做的通過ADMM算法求解binary約束的低比特量化工作。從凸優化的角度,在第一個優化公式中,f(w)是網絡的損失函數,后面會加入一項W在集合C上的loss來轉化為一個優化問題。這個集合C取值只有正負1,如果W在滿足約束C的時候,它的loss就是0;W在不滿足約束C的時候它的loss就是正無窮。為了方便求解還引進了一個增廣變量,保證W是等于G的,這樣的話就可以用ADMM的方法去求解。
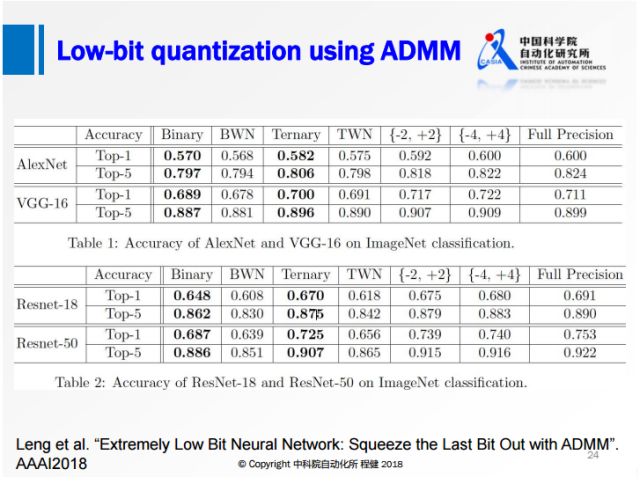
他們在AlexNet和ResNet上達到了比BWN更高的精度,已經很接近全精度網絡的水平。

上圖是我們今年通過Hashing方法做的網絡權值二值化工作。第一個公式是我們最常用的哈希算法的公式,其中S表示相似性,后面是兩個哈希函數之間的內積。我們在神經網絡做權值量化的時候采用第二個公式,第一項表示輸出的feature map,其中X代表輸入的feature map,W表示量化前的權值,第二項表示量化后輸出的feature map,其中B相當于量化后的權值,通過第二個公式就將網絡的量化轉化成類似第一個公式的Hashing方式。通過最后一行的定義,就可以用Hashing的方法來求解Binary約束。
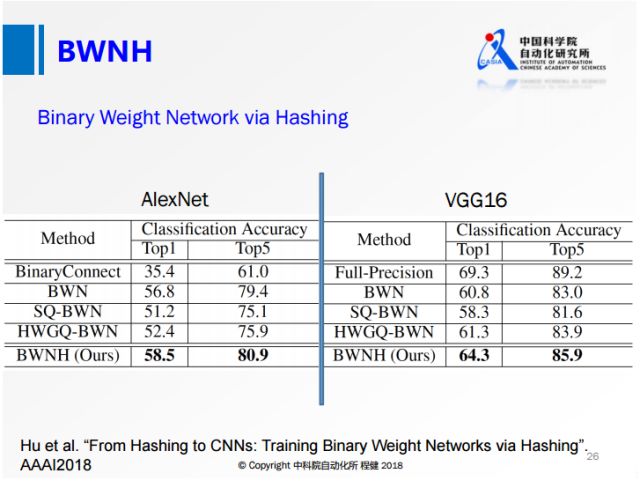
我們做了實驗,達到了比之前任何一個網絡都高的精度,非常接近全精度網絡的性能。
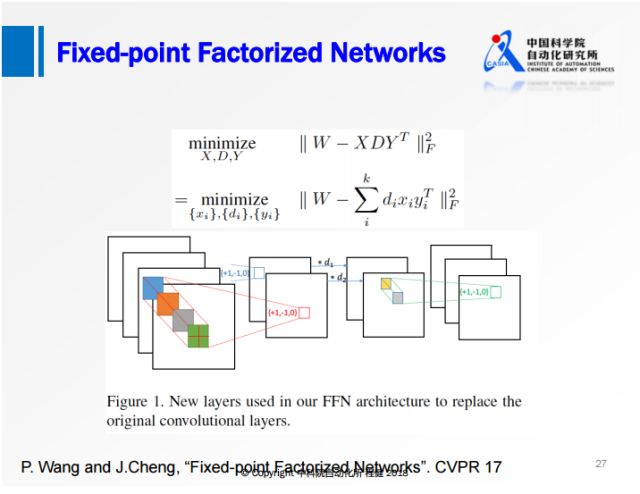
上圖是我們在CVPR2017上的工作。實際中借助了矩陣分解和定點變換的優勢,對原始權值矩陣直接做一個定點分解,限制分解后的權值只有+1、-1、0三個值。將網絡變成三層的網絡,首先是正常的3×3的卷積,對feature map做一個尺度的縮放,最后是1×1的卷積,所有的卷積的操作都有+1、-1、0。
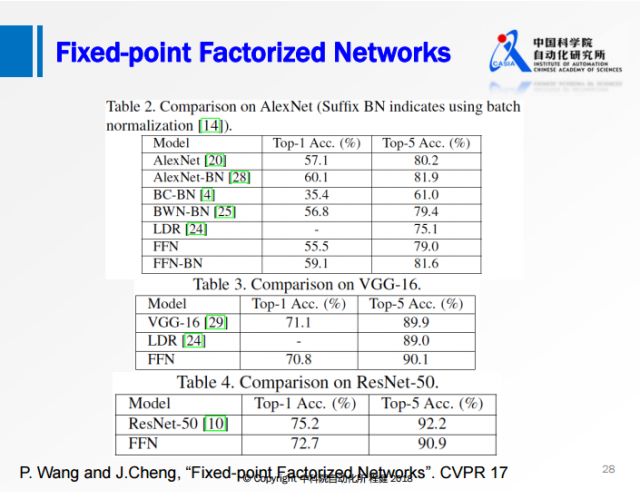
上圖是我們在ImageNet數據集上與流行的網絡模型做的對比實驗,可以看出我們提出的FFN與一些網絡相比已經達到甚至超過全精度網絡的性能;雖然與ResNet-50相比還存在一些性能上的損失,但是相比之前的方法損失已經小了很多。

下面講述一些專門針對深度學習芯片設計的工作。
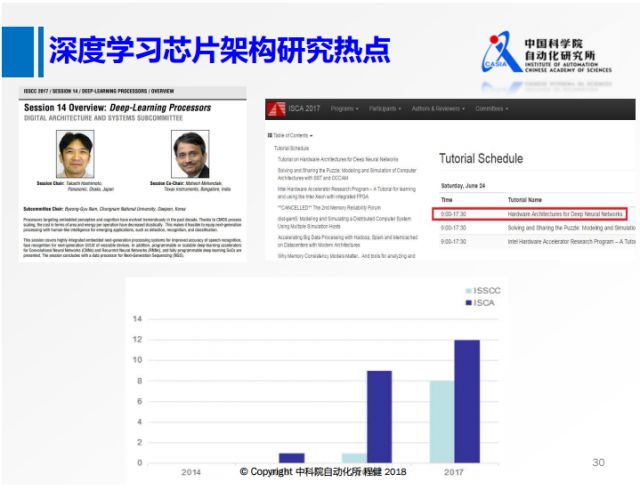
上圖是2017年芯片設計兩個頂會ISCA和ISSCC上與deep learning相關session情況,這兩個會議上都有專門針對深度學習的討論可以看出深度學習對芯片設計產生了巨大影響。
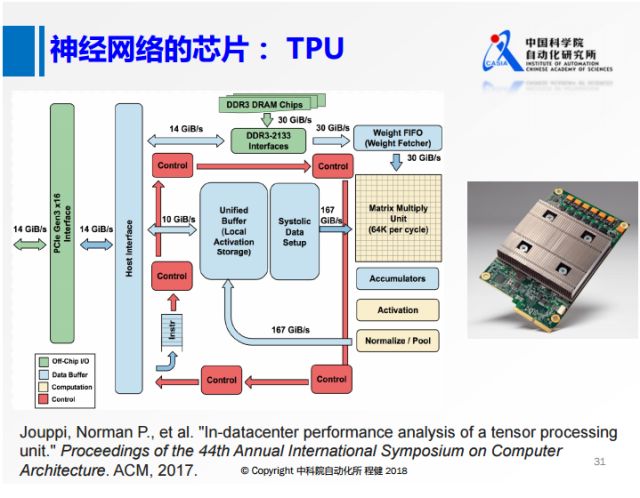
首先是上圖中谷歌在2017年推出的的TPU,設計了矩陣基本乘法的單元,使用int8來表示,還專門針對芯片上包括權值的所有數據設計了一些緩沖區域。
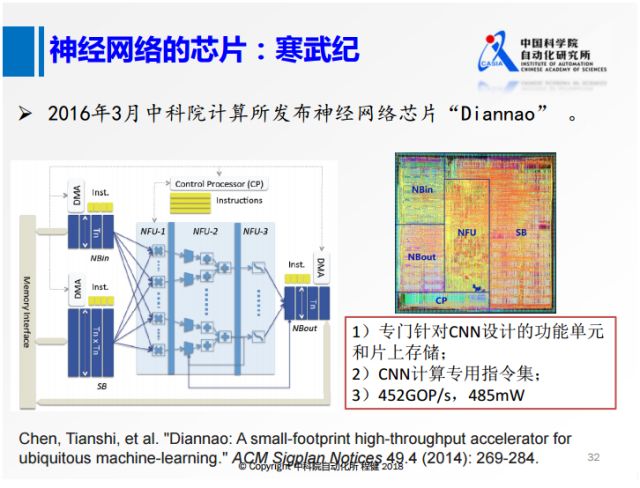
上圖是中科院計算所研發的寒武紀。它在思想上實際和TPU有一點相似,實際中專門針對CNN設計了一些計算單元,還對常用的一些卷積神經網絡中的操作專門設計了一些指令,這樣芯片可以達到452GOP/s的高速度和485Mw的低功耗。
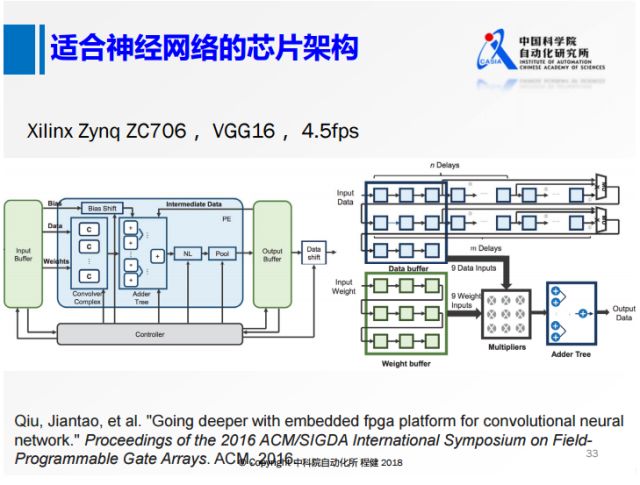
上圖是清華大學2016年在FPGA平臺上使用了VGG16所做的早期工作,采用類似正常網絡的計算思路,在FPGA上實現了VGG16,可以達到4.5幀每秒的速度。
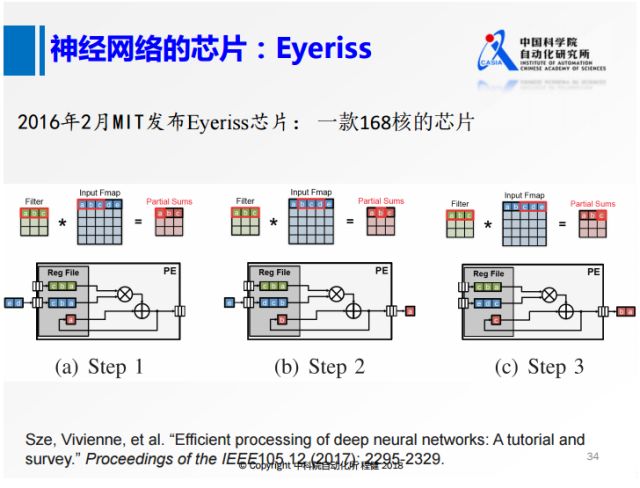
上圖是MIT發布的一款名為Eyeriss的芯片,把正常的3×3卷積核操作做差分運算,將每一行做一個類似的處理,在卷積核進來以后,對整個feature map掃描以后,再把數據給拋掉。
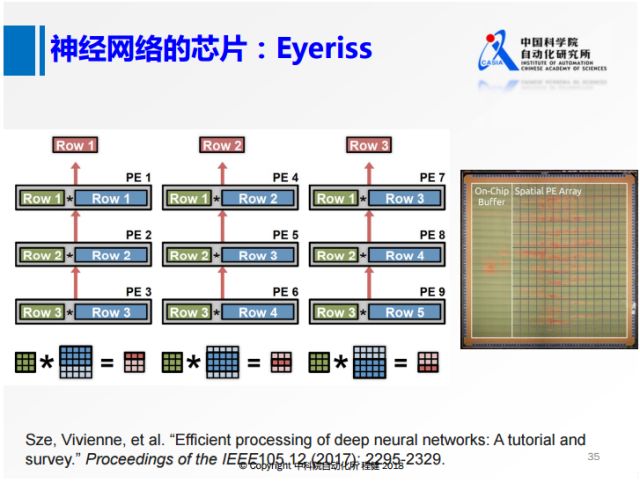
上面對3×3的卷積核的處理只是針對一行,如果并行處理三行,就是上面這張圖。將三行都保存在片上,藍色的部分相當于特征,對其使用類似于一個流水線的方式進行處理,最左邊的圖表示一二三,中間是三三四,右邊是三四五,用這種方式把feature map在芯片上所有位置的響應都計算出來。
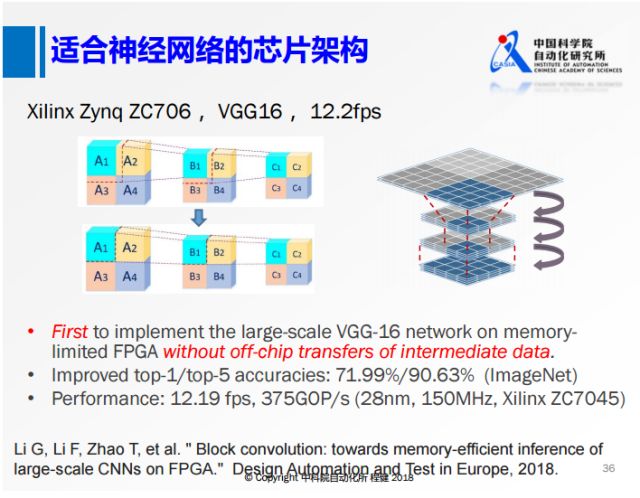
上面是我們2018年在DATE上的工作,我們和清華大學使用相同的板子做了VGG16。我們的出發點是這樣的,由于VGG16的feature map非常大,所以在計算過程中我們不可避免地需要在內存和板子上搬數據,這會帶來非常大的功耗。如果我們一次要搬這個數據的話,無論是從功耗還是速度的角度都有很大的損失。我們從算法和硬件結合的角度考慮,首先從算法上對神經網絡進行分塊的操作,將上面正常的卷積,分成2×2的四塊,本來從A1計算B1的時候需要A2和A3的信息,現在在算法的層面把這些依賴都去掉,就可以轉化成下面的這種方式。所有對B1的計算只依賴于A1,得到B1以后不需要等B2和B3的計算結果,就可以直接使用B1去計算C1,而且還可以把A1、B1、C1的操作做層之間的合并,這樣計算時延非常低,并且我們在整個網絡的運算過程中不需要大量的內存,從而大幅提高了神經網絡的計算速度。

下面談一談我們能看到的對神經網絡未來的展望。

1. 首先前面提到的二值化方法大多都是針對權值的二值化,對這些網絡的feature map做8比特的量化,很容易達到類似于feature map是浮點數的性能。如果我們能夠把feature map也做成binary的話,無論是在現有的硬件還是在專用的硬件上都可以達到更好的性能。但是性能上還有很大損失。所以如何更高效地二值化網絡也是未來研究的熱點。
2. 目前在訓練階段的一些量化操作都是針對測試階段的。如果我們要設計一款有自主學習能力的芯片,則需要在訓練的階段實現量化,我們可以在芯片實際使用的時候在線更新權值,這是未來發展的一個趨勢。
3. 另一個方面是不需要重新訓練,或者只需要無監督訓練的網絡加速與壓縮方法。現在的網絡加速方法都是做了一些網絡壓縮以后還要做大量的fine-tuning操作,但是實際使用中用戶給定一個網絡,如果我們可以使用不需要重新訓練,或者我們只是用一部分不帶標簽的數據就可以對這個網絡進行壓縮的話,這是一個非常有實用價值的研究方向。
4. 面向不同的任務,現在進行加速的方法,包括面向深度學習的芯片,大部分都是針對分類任務去做的。但是在實際應用中,分類是一個最基礎的工作,而像目標檢測、圖像分割的應用也非常的廣泛,對這些任務進行加速也是非常重要的問題。
5. 單獨做神經網絡或芯片架構的優化都很難做得非常好,兩個方面結合起來協同優化會更好。這些就是我們能看到的一些未來的發展。
-
人工智能
+關注
關注
1791文章
46853瀏覽量
237547 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
原文標題:深度學習高效計算與處理器設計
文章出處:【微信號:deeplearningclass,微信公眾號:深度學習大講堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用
pcie在深度學習中的應用
GPU深度學習應用案例
AI大模型與深度學習的關系
深度學習模型中的過擬合與正則化
深度學習中的無監督學習方法綜述
深度學習與nlp的區別在哪
深度學習的模型優化與調試方法
FPGA在深度學習應用中或將取代GPU
為什么深度學習的效果更好?

芯來科技正式發布首款專用處理器產品線Nuclei Intelligence系列
深度學習如何訓練出好的模型





 工商網監
工商網監
評論