 如何輸入3D網格物體(原始三角形和頂點),得到分類概率的輸出
如何輸入3D網格物體(原始三角形和頂點),得到分類概率的輸出
2017 年 3 月,當時我的老板說自動識別 3D 物體幾乎是不可能的,但大家一致反對。
因此,今天我要解決的問題是:如何輸入 3D 網格物體(原始三角形和頂點),得到分類概率的輸出。
我找到了如下幾種解決方案:
對物體進行縮放并將其分割成體素。將體素給到神經網絡中。
計算大量描述符,將其放入分類器。
從多側進行物體投射,嘗試用單獨的分類器進行識別,然后將其放到元分類器中。
在這里我想詳細講述一下一種相對簡單有效的方法,即 DeepPano 方法。
▌數據準備
如今,圖像數據集包含大量樣本。但就 3D 模型數據集而言,并非如此。3D模型數據集中沒有成千上萬的圖像,因此 3D 模型識別沒有得到深入研究,3D模型數據集也不均衡。大多數數據集包含有未進行方向對齊的物體。
ModelNet10 是一個相對清晰的 3D 物體數據集。3D 物體在數據集中被存儲為包含點線面的.off文件。 .off文件格式不支持顯示布料、紋理以及其他材質。
這里是物體種類與樣本數量:
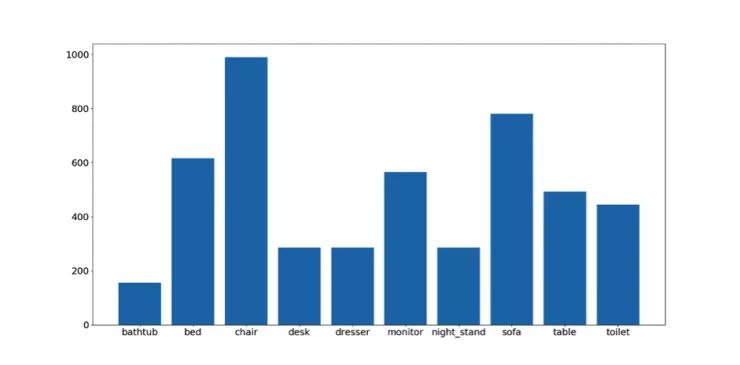
樣本總數約為 5000。當然這個數據集也非常不均衡。
首先要做的是選擇分類器類型。由于如圖像、語音等重要數據的技術解決方案都是基于神經網絡(或在 Kaggle 比賽中經常使用的奇特組件),因此訓練神經網絡是合乎邏輯的。神經網絡對數據集的均衡性很敏感。所以第二步需要做的是使數據集更均衡。
我決定使用從 3dWarehouse 中得到的模型獲取更多數據并創建擴展數據集。這些模型是以.skp文件格式存儲的,因此必須進行轉換。我使用SketchUp C Api創建了.skp - >.off轉換器來進行轉換。
下一步是數據清理,完全相同的圖像已被刪除。可以這樣分配:
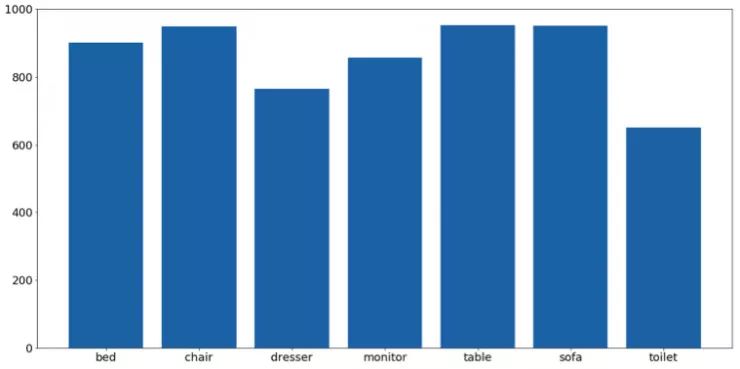
這樣數據集看起來就比較均衡了。除馬桶外,幾乎每個物體類別都包含有近 1000 個樣本。其他物體類型之間的不均衡可通過分類權重進行修正。
▌數據預處理
在之前的步驟中,我們已經做了幾件重要的事情。
闡述問題。
下載我們將要使用的基本數據集(ModelNet10)。
從最初的 10 類物體中選出了7類。
通過創建.skp - > .off 轉換器來轉換 3d warehouse.中的模型,數據集變得更加均衡。
現在開始深入了解數據預處理。
在預處理過程中,數據預處理的最終結果是要用一種新的圖像來表示 3D 網格物體。我們將使用圓柱投影來創建圖像。
3D網格物體
此物體的轉換結果
首先,我們需要讀入 3D 網格物體并進行存儲。這可以通過功能強大的 trimesh 庫來完成。它不僅提供讀/寫功能,而且有大量其他有用的功能,如網格變換,光線追蹤等。
第二步是計算圓柱投影。圓柱投影是什么呢?假設一個立方體位于 XoY 平面的中心,且原點有一條垂直軸。
注意:如果物體的主軸不垂直,則需要在進行物體識別前應用方向對齊算法。這是一個完全不同的領域,因此在這里不對此主題進行探討。
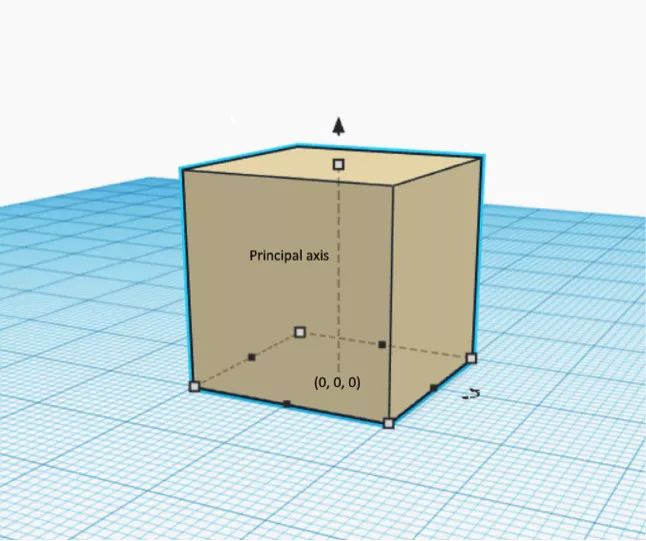
立方體和主軸

現在假設有一個包裹立方體的最小圓柱體。

現在將圓柱體的側面切割成 M×N 的網格。

現在將每個網格節點垂直投影到主軸上并獲取一組投影點。投影點集合由P表示。投影線集合由 S 表示。
綠色是主軸,紅色是網格,黃色是幾何投影線。
現在將 S 集合中的每段與網格體,即該立方體相交。你將從每條射線獲得一個交點。將該點分配給相應的網格節點。
其實這是一個特例。一般情況下,S 中的一個投影線可以有多個交點,或者根本沒有交點。下面就是一個例子。
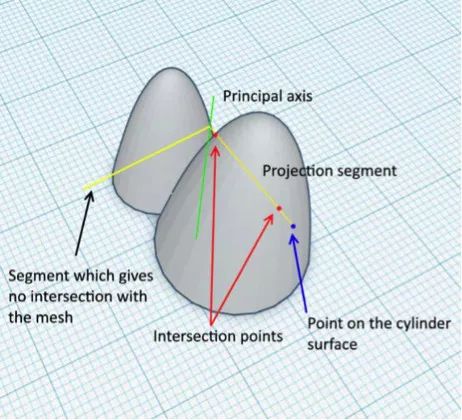
因此,通常這個過程的結果是在每個單元中都有一個 M×N 矩陣,其中可能具有交點數組,也可能是空的。對于立方體,每個單元格將包含具有單個元素的數組。
下一步是從每個單元格的交點中選取離對應的 M 中的點距離最遠的點,并將它們之間的距離寫入 M×N 矩陣 R。矩陣(或圖像)R 稱為全景圖。
我們為什么要選取最遠的點?最遠的點通常集中于物體的外表面。我們將其用全景圖表示,可用于識別模塊。當然,有人可能會說:“圓環和高度相同的圓柱體會呈現出完全相同的全景圖”或者“中心有一個球形孔的立方體和沒有孔的立方體會呈現出完全相同的全景圖”,這是正確的。
以全景圖來呈現 3D 物體并不完美,但如果是用體素來呈現則沒有這樣的缺點。幸運的是,像椅子、床、汽車或飛機這些真實存在的物體由于其復雜性,很少有相同的全景圖。
最后一步是通過將單元格的值縮放到[0,1]區間,對R矩陣進行歸一化。如果單元格沒有交點,則該單元格的值為零。
現在我們可以將矩陣 R 視為灰度圖像。這里是所描述過程的 Python 代碼和全景圖計算的一個例子。
混凝土床(左上)、椅子(右上)和馬桶(中)的全景圖。
我們總結一下到目前為止已經完成的步驟。
現在我們已經將 3D 網格物體表示為灰度圖像。
3D 物體必須正確對齊。如果沒有正確對齊,那么我們首先需要使用方向對齊算法。
兩個不同的物體有可能具有相同的全景圖,但這種可能性很小。
現在我們準備創建卷積神經網絡并解決識別問題。
▌開始識別!
我們在上一步中做了一件非常重要的事情,即找到一種合適的方法將 3D 物體轉換成圖像,我們可以將其提供給神經網絡(NN)。
步驟如下所示:
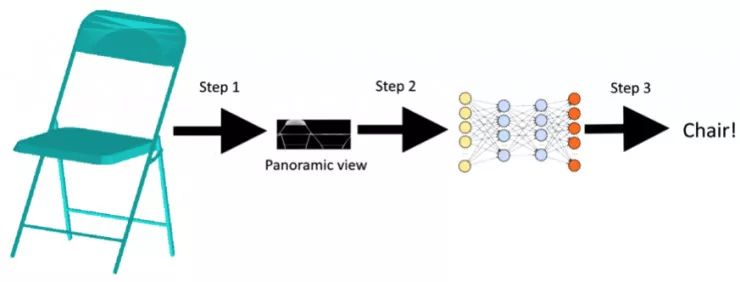
我們之前已經完成了第 1 步,所以現在我們開始第 2 步和第 3 步。
讓我們從模型創建開始。
你可以在架構中看到 RWMP 層。根據DeepPano論文,RWMP層的作用在于, 在 3D 物體圍繞主軸旋轉的情況下,保持識別精度不變。從技術上講,RWMP 只是一個行式的 MaxPooling。
模型準備就緒并編譯完成后,讀取數據,然后將其刷新,并通過圖像尺寸調節創建 ImageDataGenerator。請注意,數據預先按照 70:15:15 的比例進行了訓練、驗證和測試。由于圖像是合成的,并且代表了 3D 物體,因此數據無法進行擴增,因為:
由于圖像是灰度的,所以不能進行顏色增強。
由于 RWMP 的存在,不能進行水平翻轉。
垂直翻轉意味著將物體顛倒。
由于圖像的合成性質,無法使用ZCA白化。
隨機旋轉會損失寶貴的物體邊角信息,我無法確定這會對3D物體轉換產生什么影響。
所以我想不出任何可以應用在這里的數據擴增方法。

現在開始訓練模型。
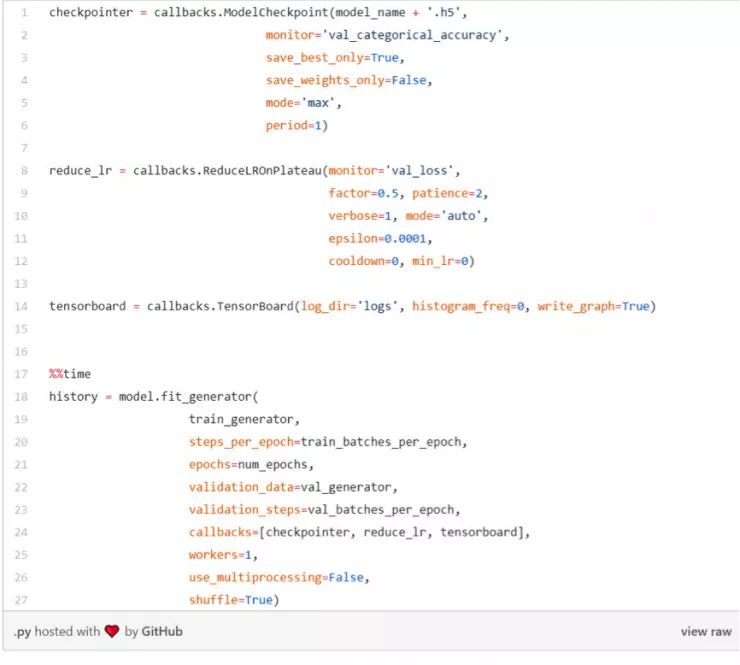
讓我們看看結果。
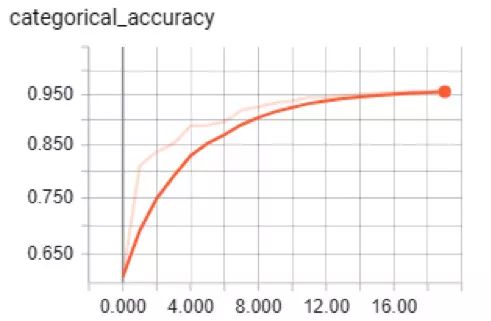
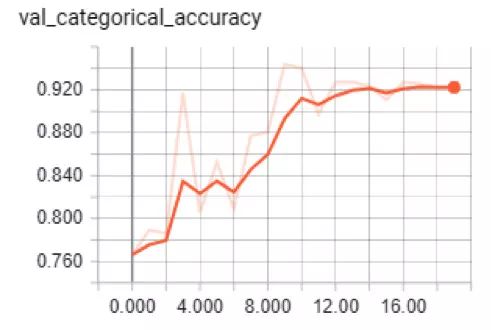
訓練絕對準確度和驗證絕對準確度
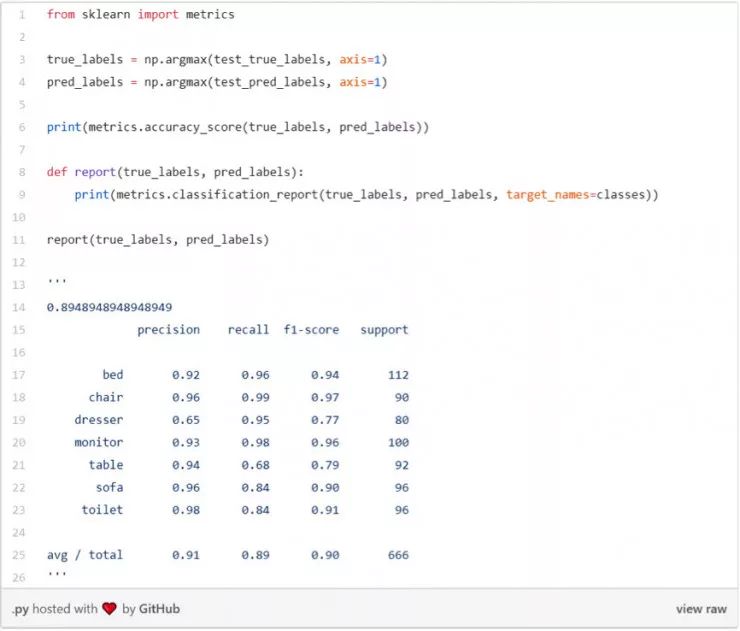
正如你所看到的,該模型驗證的準確度達到了92%,訓練的準確度達到了95%,所以沒有過度擬合。該模型數據集測試的整體準確度度為 0.895。
分類報告:
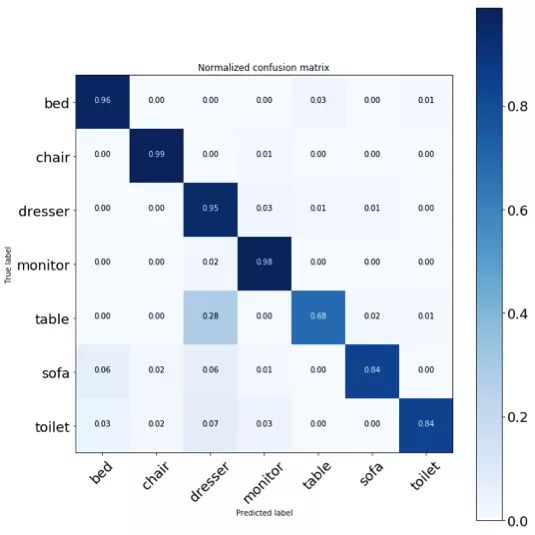
測試數據集的混淆矩陣
我們也可以自行排列這個模型。
來自上面的代碼片段
結果看起來不錯,一切都進行得都很順利,只是有些桌子被錯誤地識別為梳妝臺了。我不確定為什么會發生這種情況。這可能是未來需要改進的步驟之一。
讓我們列出可能需要改進的地方。
識別時要考慮材料、紋理和幾何尺寸等因素,否則會形成致無序模型。
提高數據集的均衡性或至少使用分類權重。生成模型(例如VAE)可使數據集更均衡。
添加更多的物體類別。
基于全景圖和不同的表示形式創建元模型,例如體素。這可能很昂貴。
目前為止,所有步驟介紹完畢。
-
自動識別
+關注
關注
3文章
217瀏覽量
22818 -
三維網格
+關注
關注
1文章
6瀏覽量
7562 -
數據集
+關注
關注
4文章
1205瀏覽量
24647
原文標題:一文教會你三維網格物體識別
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
三角形柵格矩形徑向線螺旋陣列天線的設計與實驗研究

基于貪心優化策略的三角形排布算法
星形/三角形的變換法介紹





 工商網監
工商網監
評論