") Salesforce發(fā)布了一項(xiàng)新的研究成果:decaNLP十項(xiàng)自然語(yǔ)言任務(wù)的通用模型
Salesforce發(fā)布了一項(xiàng)新的研究成果:decaNLP十項(xiàng)自然語(yǔ)言任務(wù)的通用模型
AI科技大本營(yíng)按:目前的NLP領(lǐng)域有一個(gè)問(wèn)題:即使是再厲害的算法也只能針對(duì)特定的任務(wù),比如適用于機(jī)器翻譯的模型不一定可以拿來(lái)做情感分析或摘要。
然而近日,Salesforce發(fā)布了一項(xiàng)新的研究成果:decaNLP——一個(gè)可以同時(shí)處理機(jī)器翻譯、問(wèn)答、摘要、文本分類、情感分析等十項(xiàng)自然語(yǔ)言任務(wù)的通用模型。
Salesforce的首席科學(xué)家RichardSocher在接受外媒采訪時(shí)表示:我們的decaNLP就好比NLP領(lǐng)域的瑞士軍刀!
以下為AI科技大本營(yíng)對(duì)Salesforce的論文概述《The Natural Language Decathlon》的編譯,enjoy!
▌引言
深度學(xué)習(xí)已經(jīng)顯著地改善了自然語(yǔ)言處理任務(wù)中的最先進(jìn)的性能,如機(jī)器翻譯、摘要、問(wèn)答和文本分類。每一個(gè)任務(wù)都有一個(gè)特定的衡量標(biāo)準(zhǔn),它們的性能通常是由一組基準(zhǔn)數(shù)據(jù)集測(cè)量的。這也促進(jìn)了專門設(shè)計(jì)這些任務(wù)和衡量標(biāo)準(zhǔn)的體系的發(fā)展,但是它可能不會(huì)促使那些能夠在各種自然語(yǔ)言處理(NLP)任務(wù)中表現(xiàn)良好的通用自然語(yǔ)言處理模型的涌現(xiàn)。為了探索這種通用模型的可能性以及在優(yōu)化它們時(shí)產(chǎn)生的權(quán)衡關(guān)系,我們引入了自然語(yǔ)言十項(xiàng)全能(decaNLP)。
這個(gè)挑戰(zhàn)涵蓋了十個(gè)任務(wù):?jiǎn)柎稹C(jī)器翻譯、摘要、自然語(yǔ)言推理、情感分析、語(yǔ)義角色標(biāo)注、關(guān)系抽取、任務(wù)驅(qū)動(dòng)多輪對(duì)話、數(shù)據(jù)庫(kù)查詢生成器和代詞消解。自然語(yǔ)言十項(xiàng)全能(decaNLP)的目標(biāo)是開(kāi)發(fā)出可以整合所有十個(gè)任務(wù)的模型,并研究這種模型與那些為單一任務(wù)訓(xùn)練而準(zhǔn)備的模型有何不同。出于這個(gè)原因,十項(xiàng)全能的表現(xiàn)會(huì)被一個(gè)統(tǒng)一的指標(biāo)所衡量,該指標(biāo)集合了所有十項(xiàng)任務(wù)的度量標(biāo)準(zhǔn)。
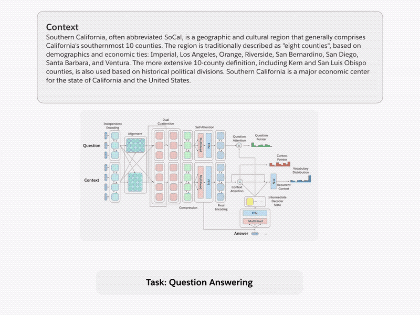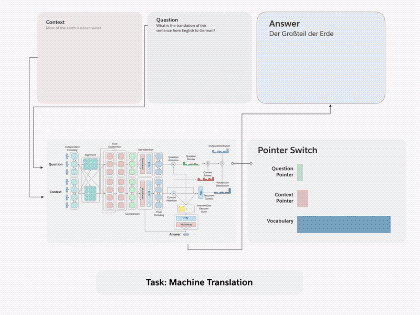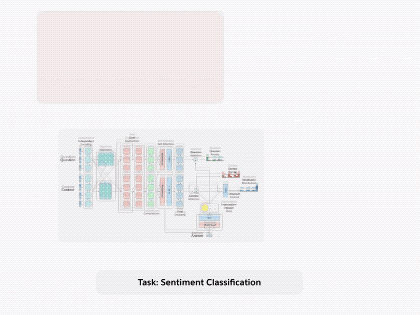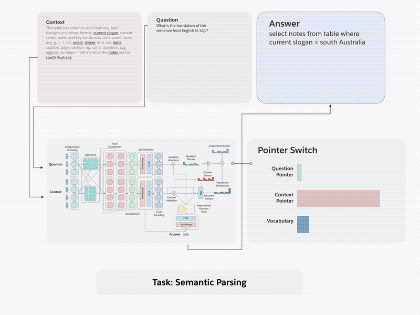
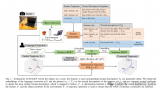
圖1.通過(guò)將 decaNLP的所有十個(gè)任務(wù)整合成問(wèn)答形式,我們可以訓(xùn)練一個(gè)通用的問(wèn)答模型
我們把所有十個(gè)任務(wù)都統(tǒng)一轉(zhuǎn)化為問(wèn)答的方式,提出了一個(gè)新的多任務(wù)問(wèn)答網(wǎng)絡(luò)(MQAN),它是一個(gè)不需要特定任務(wù)的模塊或參數(shù)而進(jìn)行共同學(xué)習(xí)任務(wù)的網(wǎng)絡(luò)。在機(jī)器翻譯和實(shí)體識(shí)別命名中,MQAN顯示出了遷移學(xué)習(xí)(Transfer learning)方面的改進(jìn)。在情感分析和自然語(yǔ)言推理中,MQAN顯示出了在領(lǐng)域適應(yīng)方面的改進(jìn),同時(shí)對(duì)于文本分類方面也顯示出了其zero-shot的能力。
在與基線的比較中,我們證明了MQAN的多指針編解碼器(multi-pointer-generator decoder)是成功的關(guān)鍵,并且使用相反的訓(xùn)練策略(anti-curriculum training strategy)進(jìn)一步改進(jìn)了性能。 盡管該設(shè)計(jì)用于decaNLP和通用的問(wèn)答,MQAN恰好也能在單任務(wù)設(shè)置中表現(xiàn)良好:它在WikiSQL語(yǔ)義解析任務(wù)上與單項(xiàng)模型最佳成績(jī)旗鼓相當(dāng),任務(wù)驅(qū)動(dòng)型對(duì)話任務(wù)中它排名第二,在SQuAD數(shù)據(jù)集不直接使用跨監(jiān)督方法的模型中它得分最高,同時(shí)在其他任務(wù)中也表現(xiàn)良好。decaNLP的從獲取和處理數(shù)據(jù)、訓(xùn)練和評(píng)估模型到復(fù)現(xiàn)實(shí)驗(yàn)的所有代碼已經(jīng)開(kāi)源。
▌任務(wù)
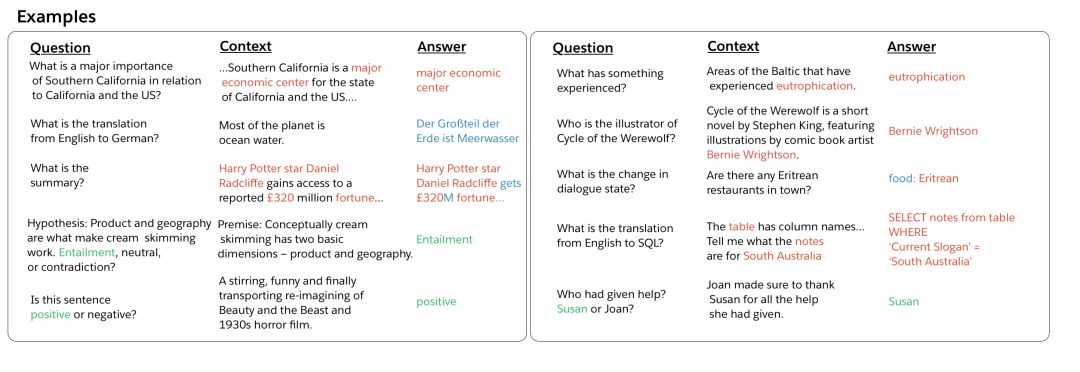
圖2.(問(wèn)題、上下文、答案)問(wèn)答、機(jī)器翻譯、摘要、自然語(yǔ)言推理、情感分析、詞性標(biāo)注、關(guān)系抽取、目標(biāo)導(dǎo)向?qū)υ挕⒄Z(yǔ)義解析和代詞解析任務(wù)的例子
讓我們首先開(kāi)始討論這些任務(wù)及其相關(guān)數(shù)據(jù)集。我們的論文包含更多的細(xì)節(jié),包括對(duì)每個(gè)任務(wù)的歷史背景和最近的工作進(jìn)行更深入的討論。每個(gè)任務(wù)的輸入-輸出對(duì)示例如上圖所示。
問(wèn)答。問(wèn)答(QA)模型接收一個(gè)問(wèn)題以及它所包含的必要的信息的上下文來(lái)輸出理想的答案。我們使用斯坦福問(wèn)答數(shù)據(jù)集的原始版本(SQuAD)來(lái)完成這項(xiàng)任務(wù)。該上下文是從英文維基百科中摘取的段落,答案是從文章中復(fù)制的單詞序列。
機(jī)器翻譯。機(jī)器翻譯模型以源語(yǔ)言文本的形式為輸入,輸出為翻譯好的目標(biāo)語(yǔ)言。我們使用2016年為國(guó)際口語(yǔ)翻譯研討會(huì)(IWSLT)準(zhǔn)備的英譯德數(shù)據(jù)為訓(xùn)練數(shù)據(jù)集,使用2013年和2014年的測(cè)試集作為驗(yàn)證集和測(cè)試集。這些例子來(lái)自TED演講,涵蓋了會(huì)話語(yǔ)言的各種主題。這是一個(gè)相對(duì)較小的機(jī)器翻譯數(shù)據(jù)集,但是它與其他任務(wù)的數(shù)據(jù)集大致相同。當(dāng)然你還可以使用額外的訓(xùn)練資源,比如機(jī)器翻譯大賽(WMT)中的數(shù)據(jù)集。
摘要。摘要模型接收一個(gè)文檔并輸出該文檔的摘要。如今在摘要方面最重要的進(jìn)展是將CNN/DailyMail (美國(guó)有線電視新聞網(wǎng)/每日郵報(bào))語(yǔ)料庫(kù)轉(zhuǎn)換成一個(gè)摘要數(shù)據(jù)集。我們?cè)赿ecaNLP中包含這個(gè)數(shù)據(jù)集的非匿名版本。平均來(lái)講,這些實(shí)例包含了該挑戰(zhàn)賽中最長(zhǎng)的文檔,以及從上下文直接提取答案與語(yǔ)境外生成答案之間平衡的force Model。
自然語(yǔ)言推理。自然語(yǔ)言推理(NLI)模型接受兩個(gè)輸入句子:一個(gè)前提和一個(gè)假設(shè)。模型必須將前提和假設(shè)之間的推理關(guān)系歸類為支持、中立或矛盾。我們使用的是多體裁自然語(yǔ)言推理語(yǔ)料庫(kù)(MNLI),它提供來(lái)自多個(gè)領(lǐng)域的訓(xùn)練示例(轉(zhuǎn)錄語(yǔ)音、通俗小說(shuō)、政府報(bào)告)和來(lái)自各個(gè)領(lǐng)域的測(cè)試對(duì)。
情感分析。情感分析模型被訓(xùn)練用來(lái)對(duì)輸入文本表達(dá)的情感進(jìn)行分類。斯坦福情感樹(shù)庫(kù)(SST)由一些帶有相應(yīng)的情緒(積極的,中立的,消極的)的影評(píng)所組成。我們使用未解析的二進(jìn)制版本,以便明確對(duì)decaNLP模型的解析依賴。
語(yǔ)義角色標(biāo)注。語(yǔ)義角色標(biāo)注(SRL)模型給出一個(gè)句子和謂語(yǔ)(通常是一個(gè)動(dòng)詞),并且必須確定“誰(shuí)對(duì)誰(shuí)做了什么”、“什么時(shí)候”、“在哪里”。我們使用一個(gè)SRL數(shù)據(jù)集,該數(shù)據(jù)集將任務(wù)視為一種問(wèn)答:QA-SRL。這個(gè)數(shù)據(jù)集涵蓋了新聞和維基百科的領(lǐng)域,但是為了確保decaNLP的所有數(shù)據(jù)都可以自由下載,我們只使用了后者。
關(guān)系抽取。關(guān)系抽取系統(tǒng)包含文本文檔和要從該文本中提取的關(guān)系類型。在這種情況下,模型需要先識(shí)別實(shí)體間的語(yǔ)義關(guān)系,再判斷是不是屬于目標(biāo)種類。與SRL一樣,我們使用一個(gè)數(shù)據(jù)集,該數(shù)據(jù)集將關(guān)系映射到一組問(wèn)題,以便關(guān)系抽取可以被視為一種問(wèn)答形式:QA-ZRE。對(duì)數(shù)據(jù)集的評(píng)估是為了在新的關(guān)系上測(cè)量零樣本性能——數(shù)據(jù)集是分開(kāi)的使得測(cè)試時(shí)看到的關(guān)系在訓(xùn)練時(shí)是無(wú)法看到的。這種零樣本的關(guān)系抽取,以問(wèn)答為框架,可以推廣到新的關(guān)系之中。
任務(wù)驅(qū)動(dòng)多輪對(duì)話。對(duì)話狀態(tài)跟蹤是任務(wù)驅(qū)動(dòng)多輪對(duì)話系統(tǒng)的關(guān)鍵組成部分。根據(jù)用戶的話語(yǔ)和系統(tǒng)動(dòng)作,對(duì)話狀態(tài)跟蹤器會(huì)跟蹤用戶為對(duì)話系統(tǒng)設(shè)定了哪些事先設(shè)定目標(biāo),以及用戶在系統(tǒng)和用戶交互過(guò)程中發(fā)出了哪些請(qǐng)求。我們使用的是英文版的WOZ餐廳預(yù)訂服務(wù),它提供了事先設(shè)定的關(guān)于食物、日期、時(shí)間、地址和其他信息的本體,可以幫助代理商為客戶進(jìn)行預(yù)訂。
語(yǔ)義解析。SQL查詢生成與語(yǔ)義解析相關(guān)。基于WikiSQL數(shù)據(jù)集的模型將自然語(yǔ)言問(wèn)題轉(zhuǎn)換為結(jié)構(gòu)化SQL查詢,以便用戶可以使用自然語(yǔ)言與數(shù)據(jù)庫(kù)交互。
代詞消解。我們的最后一個(gè)任務(wù)是基于要求代詞解析的Winograd模式:“Joan一定要感謝Susan的幫助(給予/收到)。誰(shuí)給予或者收到了幫助?Joan還是Susan?”。我們從Winograd模式挑戰(zhàn)中的示例開(kāi)始,并對(duì)它們進(jìn)行了修改(導(dǎo)致了修訂的Winograd模式挑戰(zhàn),即MWSC),以確保答案是上下文中的單個(gè)單詞,并且分?jǐn)?shù)不會(huì)因上下文、問(wèn)題和答案之間的措辭或不一致而增加或者減少。
十項(xiàng)全能得分(decaScore)
在decaNLP上競(jìng)爭(zhēng)的模型是被特定任務(wù)中度量標(biāo)準(zhǔn)的附加組合來(lái)評(píng)估的。所有的度量值都在0到100之間,因此十項(xiàng)全能得分在10個(gè)任務(wù)中的度量值在0到1000之間。使用附加組合可以避免我們?cè)跈?quán)衡不同指標(biāo)時(shí)可能產(chǎn)生的隨意性。所有指標(biāo)都不區(qū)分大小寫(xiě)。我們將標(biāo)準(zhǔn)化的F1(nF1)用于問(wèn)答、自然語(yǔ)言推理、情感分析、詞性標(biāo)注和MWSC;平均值ROUGE-1、ROUGE-2、ROUGE-L作為摘要的評(píng)分等級(jí);語(yǔ)料BLEU水平得分用于對(duì)機(jī)器翻譯進(jìn)行評(píng)分;聯(lián)合目標(biāo)跟蹤精確匹配分?jǐn)?shù)和基于回合的請(qǐng)求精確匹配得分的平均值用于對(duì)目標(biāo)導(dǎo)向進(jìn)行評(píng)分;邏輯形式精確匹配得分用于WikiSQL上的語(yǔ)義解析;以及語(yǔ)料庫(kù)級(jí)F1評(píng)分等級(jí),用于QA-ZRE的關(guān)系提取。
為了代替標(biāo)準(zhǔn)的驗(yàn)證數(shù)據(jù),我們選擇了按要求的decaNLP模型提交到原始的小組平臺(tái)進(jìn)行測(cè)試。類似地,MNLI測(cè)試集不是公開(kāi)的,decaNLP模型必須通過(guò)一個(gè)Kaggle系統(tǒng)來(lái)評(píng)估MNLI的測(cè)試性能。
▌多任務(wù)問(wèn)答網(wǎng)絡(luò)(MQAN)
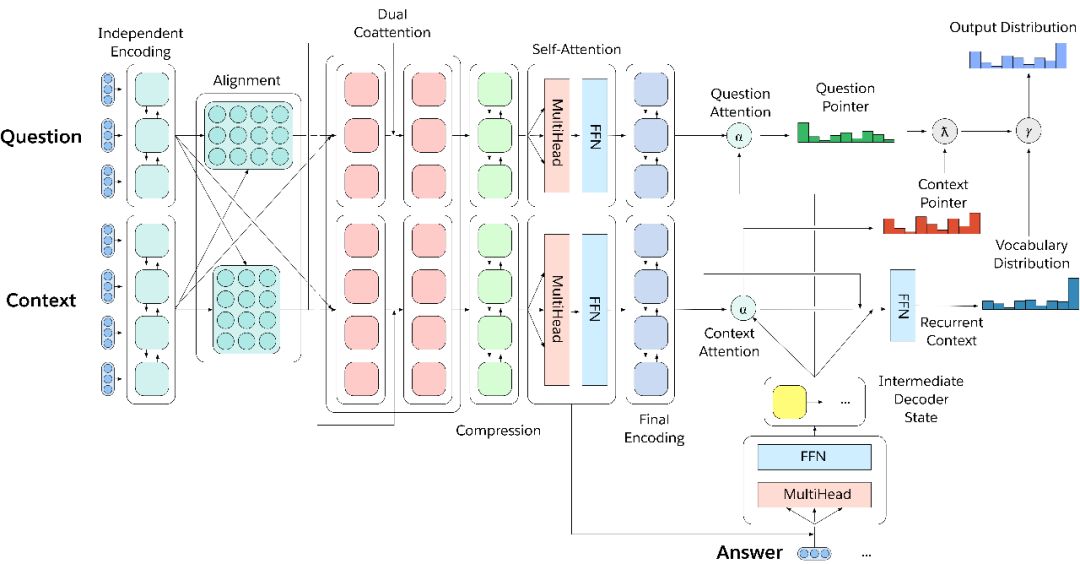
圖3.多任務(wù)問(wèn)答網(wǎng)絡(luò)
為了有效地在所有decaNLP中進(jìn)行多任務(wù)處理,我們引入了MQAN,一個(gè)多任務(wù)問(wèn)題回答網(wǎng)絡(luò),它沒(méi)有任何針對(duì)特定任務(wù)的參數(shù)和模塊。
簡(jiǎn)單地說(shuō),MQAN采用一個(gè)問(wèn)題和一個(gè)上下文背景文檔,用BiLSTM編碼,使用額外的共同關(guān)注對(duì)兩個(gè)序列的條件進(jìn)行表示,用另兩個(gè)BiLSTM壓縮所有這些信息,使其能夠更高層進(jìn)行計(jì)算,用自我關(guān)注的方式來(lái)收集這種長(zhǎng)距離依賴關(guān)系,然后使用兩個(gè)BiLSTM對(duì)問(wèn)題和背景環(huán)境的進(jìn)行最終的表示。多指針生成器解碼器著重于問(wèn)題、上下文以及先前輸出象征來(lái)決定是否從問(wèn)題中復(fù)制,還是從上下文復(fù)制,或者從有限的詞匯表中生成。關(guān)于我們的模型的其他細(xì)節(jié)可以在我們的文章的第3節(jié)中找到。
▌基線和結(jié)果
除了MQAN,我們還嘗試了幾種基線方法并計(jì)算了它們的十項(xiàng)全能得分。第一個(gè)基線,S2S,是具有注意力和指針生成器的序列到序列的網(wǎng)絡(luò)。我們的第二基線,S2S w/SAtt,是一個(gè)S2S網(wǎng)絡(luò),它在編碼器側(cè)的BiLTM層和解碼器側(cè)的LSTM層之間添加了自注意(Transformer)層。我們的第三個(gè)基線,+CAtt,將上下文和問(wèn)題分成兩個(gè)序列,并在編碼器側(cè)添加一個(gè)額外的共同關(guān)注層。MQAN是一個(gè)種帶有附加問(wèn)題指針的+CAtt模型,在我們的基線/消融研究中,它被稱為+QPtr。針對(duì)每一個(gè)模型,我們都提出了兩種實(shí)驗(yàn)。第一,我們報(bào)告出十個(gè)任務(wù)模型中的單任務(wù)性能。第二,我們提出多任務(wù)性能,即模型在所有任務(wù)中被聯(lián)合訓(xùn)練所體現(xiàn)出的性能。
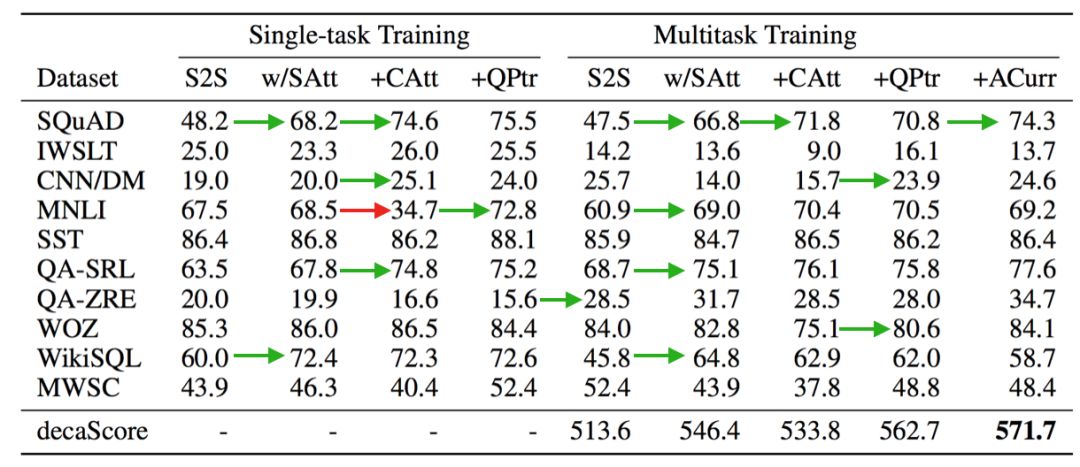
圖4.單任務(wù)和多任務(wù)實(shí)驗(yàn)對(duì)不同模型和訓(xùn)練策略的驗(yàn)證結(jié)果
比較這些實(shí)驗(yàn)的結(jié)果突出了在序列到序列和通用NLP問(wèn)答方法之間的多任務(wù)和單任務(wù)之間的權(quán)衡關(guān)系。從S2S到S2S w/ SAtt提供了一種模型,該模型在混合上下文和輸入的系列問(wèn)題中添加了附加關(guān)注層。這大大提高了 SQuAD和WiKISQL的性能,同時(shí)也提高了QA-SRL的性能。僅此一點(diǎn)就足以實(shí)現(xiàn)WiKISQL的最新技術(shù)性能。這也表明,如果不隱性地學(xué)習(xí)如何分離它們的表示方法,而顯性地去分離上下文和問(wèn)題會(huì)使模型建立更豐富的表示方法。
下一個(gè)基線使用上下文和問(wèn)題作為單獨(dú)的輸入序列,相當(dāng)于使用一個(gè)共同關(guān)注機(jī)制(+CAT)來(lái)增強(qiáng)S2S模型,該機(jī)制分別構(gòu)建了兩個(gè)序列表示。 使得每個(gè)SQuAD和QA-SRL的性能增加了 5 nF1。但遺憾的是,這種分離不能改善其他任務(wù),并且極大地?fù)p害了MNLI和MWSC的性能。對(duì)于這兩個(gè)任務(wù),可以直接從問(wèn)題中復(fù)制答案,而不是像大多數(shù)其他任務(wù)那樣從上下文中復(fù)制答案。由于兩個(gè)S2S基線都將問(wèn)題連接到上下文,所以指針生成器機(jī)制能夠直接從問(wèn)題中復(fù)制。當(dāng)上下文和問(wèn)題被分成兩個(gè)不同的輸入時(shí),模型就失去了這種能力。
為了補(bǔ)救這個(gè)問(wèn)題,我們?cè)谇懊娴幕€中添加了一個(gè)問(wèn)題指針(+QPTR),一種在之前添加給MQAN的指針。這提高了MNLI和MWSC的性能,甚至能夠比S2S基線達(dá)到更高的分?jǐn)?shù)。它也改善了在SQuAD,IWSLT和 CNN/DM上的性能,該模型在WiKISQL上實(shí)現(xiàn)了最新的成果,是面向目標(biāo)的對(duì)話數(shù)據(jù)集的第二高執(zhí)行模型,并且是非顯式地將問(wèn)題建模為跨度提取的最高性能模型。因?yàn)楫?dāng)使用直接跨度監(jiān)督時(shí),我們會(huì)看到應(yīng)用在通用問(wèn)答中的一些局限性。
在多任務(wù)設(shè)置中,我們看到了類似的結(jié)果,但我們還注意到一些額外的顯著特性。在QA-ZRE中,零樣本關(guān)系提取,性能比最高的單任務(wù)模型提高11個(gè)點(diǎn),這支持了多任務(wù)學(xué)習(xí)即使在零樣本情況下也能得到更好的泛化的假設(shè)。在需要大量使用S2S基線的指針生成器解碼器的生成器部分的任務(wù)上,性能下降了50%以上,直到問(wèn)題指針再次添加到模型中。我們認(rèn)為這在多任務(wù)設(shè)置中尤為重要。原因有二:首先,問(wèn)題指針除了在一個(gè)共同參與的上下文語(yǔ)境環(huán)境之外,還有一個(gè)共同參與的問(wèn)題。這種分離允許有關(guān)問(wèn)題的關(guān)鍵信息直接流入解碼器,而不是通過(guò)共同參與的上下文。其次,通過(guò)更直接地訪問(wèn)這個(gè)問(wèn)題,模型能夠更有效地決定何時(shí)生成輸出令牌比直接復(fù)制更合適。
使用這種反課程訓(xùn)練策略,最初只針對(duì)問(wèn)答進(jìn)行訓(xùn)練,在decaNLP上的性能也進(jìn)一步有所提高。
▌零樣本和遷移學(xué)習(xí)能力
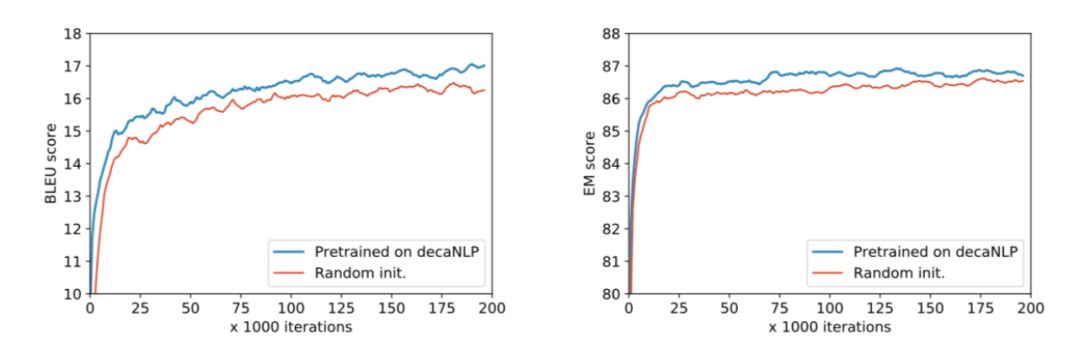
圖5.在適應(yīng)新域和學(xué)習(xí)新任務(wù)時(shí),MQAN對(duì)decaNLP的預(yù)訓(xùn)練優(yōu)于隨機(jī)初始化。左:一個(gè)新的語(yǔ)言對(duì)的訓(xùn)練-英文到捷克語(yǔ),右:訓(xùn)練一個(gè)新的任務(wù)-實(shí)體識(shí)別命名(NER)
考慮到我們的模型是在豐富和多樣的數(shù)據(jù)上進(jìn)行訓(xùn)練的,它構(gòu)建了強(qiáng)大的中間表示方法,從而實(shí)現(xiàn)了遷移學(xué)習(xí)。相對(duì)于一個(gè)隨機(jī)初始化的模型,我們的模型在decaNLP上進(jìn)行了預(yù)先訓(xùn)練,使得在幾個(gè)新任務(wù)上更快的收斂并且也提高了分?jǐn)?shù)。我們?cè)谏蠄D中給出了兩個(gè)這樣的任務(wù):命名實(shí)體識(shí)別和英文到捷克語(yǔ)的翻譯。 我們的模型也具有領(lǐng)域適應(yīng)的零樣本能力。
我們的模型在decaNLP上接受過(guò)訓(xùn)練,在沒(méi)有看過(guò)訓(xùn)練數(shù)據(jù)的情況下,我們將SNLI數(shù)據(jù)集調(diào)整到62%的精確匹配分?jǐn)?shù)。因?yàn)閐ecaNLP包含SST,它也可以在其他二進(jìn)制情感分析任務(wù)中執(zhí)行得很好。在亞馬遜和Yelp的評(píng)論中,MQAN在decaNLP上進(jìn)行了預(yù)先培訓(xùn),分別獲得了82.1%和80.8%的精確匹配分?jǐn)?shù)。此外,用高興/憤怒或支持/不支持來(lái)替換訓(xùn)練標(biāo)簽的符號(hào)來(lái)重新表示問(wèn)題,只會(huì)導(dǎo)致性能的輕微下降,因?yàn)槟P椭饕蕾囉赟ST的問(wèn)題指針。這表明,這些多任務(wù)模型對(duì)于問(wèn)題和任務(wù)中的微小變化更加可靠,并且可以推廣到新的和不可見(jiàn)的類。
-
機(jī)器翻譯
+關(guān)注
關(guān)注
0文章
139瀏覽量
14873 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120977 -
nlp
+關(guān)注
關(guān)注
1文章
487瀏覽量
22011
原文標(biāo)題:NLP通用模型誕生?一個(gè)模型搞定十大自然語(yǔ)言常見(jiàn)任務(wù)
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
使用LLM進(jìn)行自然語(yǔ)言處理的優(yōu)缺點(diǎn)
AI大模型在自然語(yǔ)言處理中的應(yīng)用
【《大語(yǔ)言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)篇
谷歌發(fā)布革命性AI天氣預(yù)測(cè)模型NeuralGCM
nlp自然語(yǔ)言處理的主要任務(wù)及技術(shù)方法
nlp自然語(yǔ)言處理模型有哪些
用于自然語(yǔ)言處理的神經(jīng)網(wǎng)絡(luò)有哪些
自然語(yǔ)言處理技術(shù)有哪些
自然語(yǔ)言處理是什么技術(shù)的一種應(yīng)用
自然語(yǔ)言處理包括哪些內(nèi)容
神經(jīng)網(wǎng)絡(luò)在自然語(yǔ)言處理中的應(yīng)用
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的基礎(chǔ)技術(shù)
【大語(yǔ)言模型:原理與工程實(shí)踐】揭開(kāi)大語(yǔ)言模型的面紗
一種基于自然語(yǔ)言的軌跡修正方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論