 Python3網絡爬蟲入門實戰解析
Python3網絡爬蟲入門實戰解析
網絡爬蟲簡介
網絡爬蟲,也叫網絡蜘蛛(WebSpider)。它根據網頁地址(URL)爬取網頁內容,而網頁地址(URL)就是我們在瀏覽器中輸入的網站鏈接。
在瀏覽器的地址欄輸入URL地址,在網頁處右鍵單擊,找到檢查。(不同瀏覽器的叫法不同,Chrome瀏覽器叫做檢查,Firefox瀏覽器叫做查看元素,但是功能都是相同的)
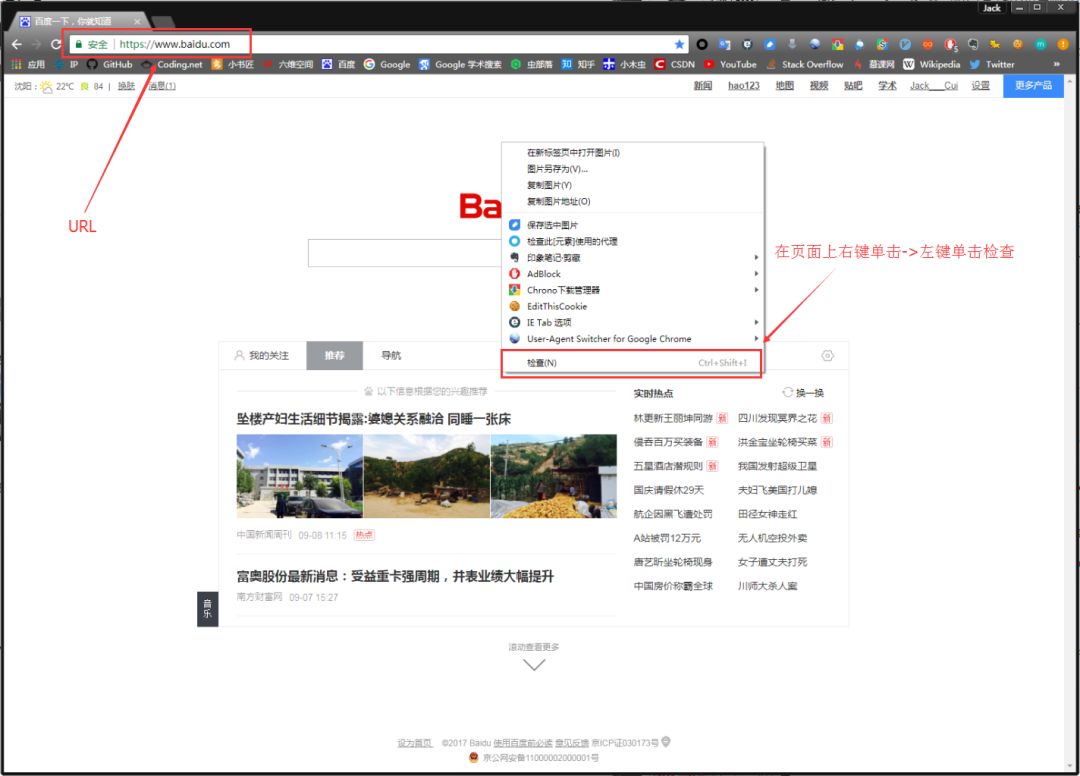
我們可以看到,右側出現了一大推代碼,這些代碼就叫做HTML。什么是HTML?舉個容易理解的例子:我們的基因決定了我們的原始容貌,服務器返回的HTML決定了網站的原始容貌。
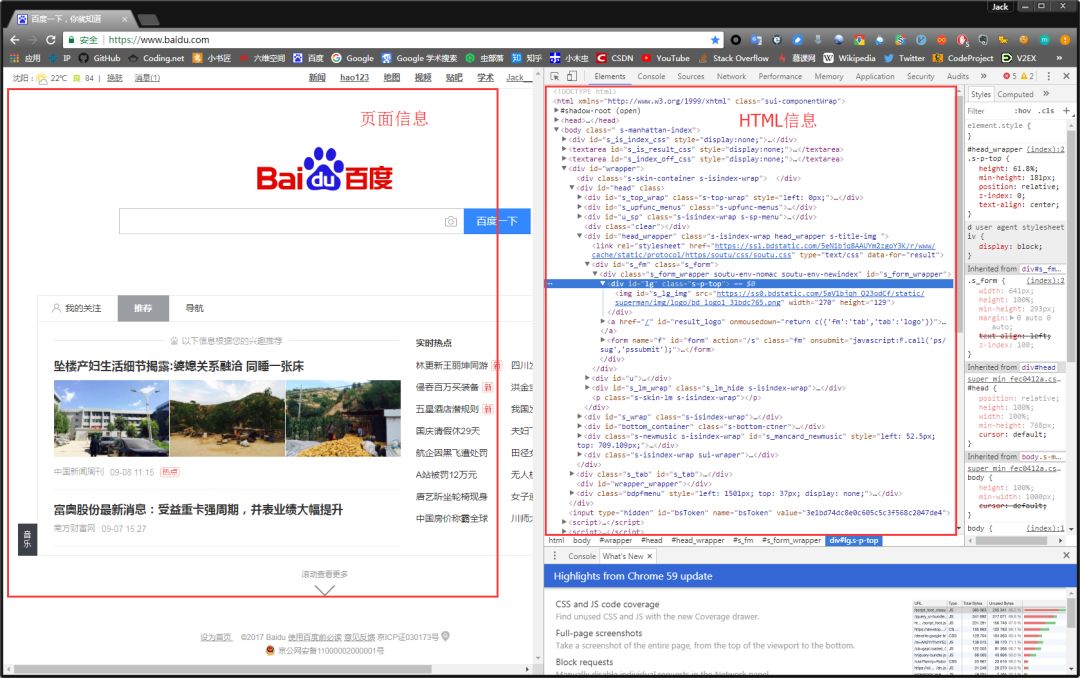
為啥說是原始容貌呢?因為人可以整容啊!扎心了,有木有?那網站也可以"整容"嗎?可以!請看下圖:
我能有這么多錢嗎?顯然不可能。我是怎么給網站"整容"的呢?就是通過修改服務器返回的HTML信息。我們每個人都是"整容大師",可以修改頁面信息。我們在頁面的哪個位置點擊審查元素,瀏覽器就會為我們定位到相應的HTML位置,進而就可以在本地更改HTML信息。
再舉個小例子:我們都知道,使用瀏覽器"記住密碼"的功能,密碼會變成一堆小黑點,是不可見的。可以讓密碼顯示出來嗎?可以,只需給頁面"動個小手術"!以淘寶為例,在輸入密碼框處右鍵,點擊檢查。
可以看到,瀏覽器為我們自動定位到了相應的HTML位置。將下圖中的password屬性值改為text屬性值(直接在右側代碼處修改):
我們讓瀏覽器記住的密碼就這樣顯現出來了:
說這么多,什么意思呢?瀏覽器就是作為客戶端從服務器端獲取信息,然后將信息解析,并展示給我們的。我們可以在本地修改HTML信息,為網頁"整容",但是我們修改的信息不會回傳到服務器,服務器存儲的HTML信息不會改變。刷新一下界面,頁面還會回到原本的樣子。這就跟人整容一樣,我們能改變一些表面的東西,但是不能改變我們的基因。
2、簡單實例
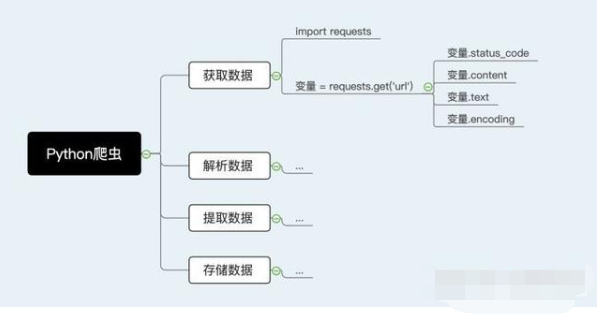
網絡爬蟲的第一步就是根據URL,獲取網頁的HTML信息。在Python3中,可以使用urllib.request和requests進行網頁爬取。
urllib庫是python內置的,無需我們額外安裝,只要安裝了Python就可以使用這個庫。
requests庫是第三方庫,需要我們自己安裝。
requests庫強大好用,所以本文使用requests庫獲取網頁的HTML信息。requests庫的github地址:https://github.com/requests/requests
(1)requests安裝
在cmd中,使用如下指令安裝requests:
pip install requests
或者:
easy_install requests
(2)簡單實例
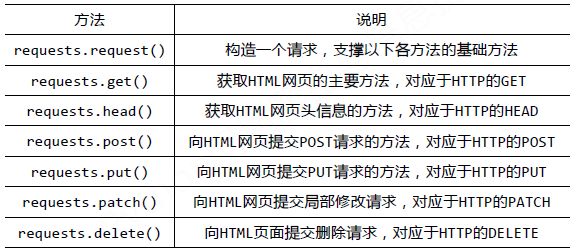
requests庫的基礎方法如下:
官方中文教程地址:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
requests庫的開發者為我們提供了詳細的中文教程,查詢起來很方便。本文不會對其所有內容進行講解,摘取其部分使用到的內容,進行實戰說明。
首先,讓我們看下requests.get()方法,它用于向服務器發起GET請求,不了解GET請求沒有關系。我們可以這樣理解:get的中文意思是得到、抓住,那這個requests.get()方法就是從服務器得到、抓住數據,也就是獲取數據。讓我們看一個例子(以 www.gitbook.cn為例)來加深理解:
# -*- coding:UTF-8 -*-import requestsif __name__ == '__main__': target = 'http://gitbook.cn/' req = requests.get(url=target) print(req.text)
requests.get()方法必須設置的一個參數就是url,因為我們得告訴GET請求,我們的目標是誰,我們要獲取誰的信息。運行程序看下結果:
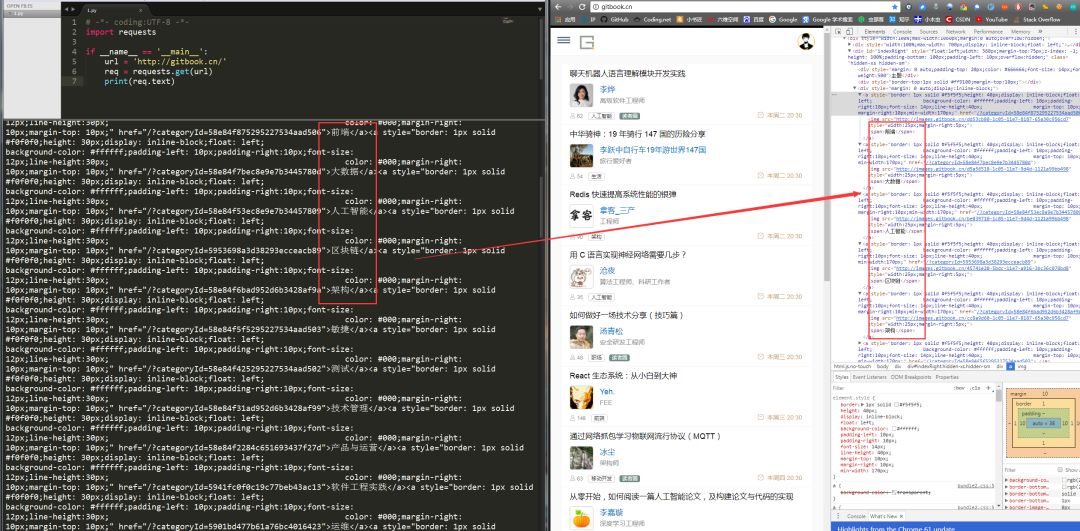
左側是我們程序獲得的結果,右側是我們在www.gitbook.cn網站審查元素獲得的信息。我們可以看到,我們已經順利獲得了該網頁的HTML信息。這就是一個最簡單的爬蟲實例,可能你會問,我只是爬取了這個網頁的HTML信息,有什么用呢?客官稍安勿躁,接下來會有網絡小說下載(靜態網站)和優美壁紙下載(動態網站)實戰,敬請期待。
-
網絡爬蟲
+關注
關注
1文章
52瀏覽量
8642 -
python3
+關注
關注
0文章
18瀏覽量
3892
原文標題:最通俗的 Python3 網絡爬蟲入門
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Python數據爬蟲學習內容
安裝python3的步驟
Python爬蟲簡介與軟件配置
python網絡爬蟲概述


python爬蟲入門教程之python爬蟲視頻教程分布式爬蟲打造搜索引擎
Python爬蟲入門知識:解析數據篇
如何使用Python3檢查文件是否存在







 工商網監
工商網監
評論