") 如何快速簡單地訓(xùn)練神經(jīng)網(wǎng)絡(luò)?
如何快速簡單地訓(xùn)練神經(jīng)網(wǎng)絡(luò)?
如何快速簡單地訓(xùn)練神經(jīng)網(wǎng)絡(luò)?谷歌大腦研究人員研究了CNN的可訓(xùn)練性,提出了一種簡單的初始化策略,不需要使用殘差連接或批標(biāo)準(zhǔn)化,就能訓(xùn)練10000層的原始CNN。作者表示,他們的這項(xiàng)工作清除了在訓(xùn)練任意深度的原始卷積網(wǎng)絡(luò)時(shí)存在的所有主要的障礙。
2015年,ResNet橫空出世,以令人難以置信的3.6%的錯(cuò)誤率(人類水平為5-10%),贏得了當(dāng)年ImageNet競賽冠軍,在圖像分類、目標(biāo)檢測和語義分割各個(gè)分項(xiàng)都取得最好成績,152層順序堆疊的殘差模塊讓業(yè)界大為贊嘆。
此后,ResNet作為訓(xùn)練“極”深網(wǎng)絡(luò)的簡單框架,得到了廣泛的應(yīng)用,包括最強(qiáng)版本的AlphaGo——AlphaGo Zero。
此后,隨著神經(jīng)網(wǎng)絡(luò)向著更深、更大的規(guī)模發(fā)展,性能不斷提高的同時(shí),也為訓(xùn)練這樣的網(wǎng)絡(luò)帶來了越來越大的挑戰(zhàn)。雖然現(xiàn)在有類似谷歌AutoML的項(xiàng)目,將設(shè)計(jì)和優(yōu)化神經(jīng)網(wǎng)絡(luò)的工作,交給神經(jīng)網(wǎng)絡(luò)自己去做,而且效果還比人做得更好。但是,AI研究者還是在思考,為什么殘差連接、批標(biāo)準(zhǔn)化等方法,會有助于解決梯度消失或爆炸的問題。
在谷歌大腦研究人員發(fā)表于ICML 2018的論文《CNN動態(tài)等距和平均場論》(Dynamical Isometry and a Mean Field Theory of CNNs: How to Train 10,000-Layer Vanilla Convolutional Neural Networks)中,他們對CNN的可訓(xùn)練性和信號在卷積網(wǎng)絡(luò)中的傳輸特點(diǎn)進(jìn)行了研究,并拓展了此前關(guān)于深度學(xué)習(xí)平均場論(Mean Field Theory)的工作。
他們發(fā)現(xiàn),卷積核在空間上的分布情況扮演了很重要的角色:當(dāng)使用在空間上均勻分布的卷積核對CNN做初始化時(shí),CNN在深度上會表現(xiàn)得像全連接層;而使用在空間上不均勻分布的卷積核時(shí),信號在深度網(wǎng)絡(luò)中就表現(xiàn)出了多種傳輸模式。
基于這一觀察,他們提出了一個(gè)簡單的初始化策略,能夠訓(xùn)練10000層乃至更深的原始CNN結(jié)構(gòu)。
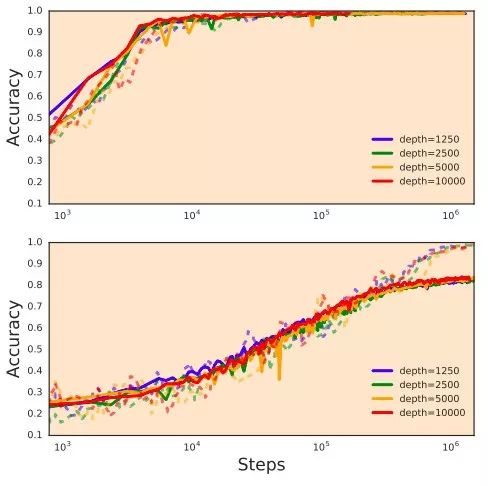
不用殘差連接,也不用批標(biāo)準(zhǔn)化,只用一個(gè)簡單的初始化策略,就能訓(xùn)練10000層深度的網(wǎng)絡(luò)。上圖為在MNIST數(shù)據(jù)集的結(jié)果,下圖是CIFAR10,實(shí)線是測試,訓(xùn)練是訓(xùn)練。來源:論文
作者表示,他們的這項(xiàng)工作提供了對殘差連接、批標(biāo)準(zhǔn)化等實(shí)踐方法的理論理解。“殘差連接和批標(biāo)準(zhǔn)化(Batch Normalization)這些結(jié)構(gòu)上的特征,可能在定義好的模型類(model class)中有著重要的作用,而不是僅僅簡單地能夠提高訓(xùn)練的效率。”
CNN可以被訓(xùn)練的深度,就是信號能完全通過的層數(shù)
在物理學(xué)和概率論中,平均場論(Mean Field Theory,MFT)是對大且復(fù)雜的隨機(jī)模型的一種簡化。未簡化前的模型通常包含數(shù)量巨大且存在相互作用的小個(gè)體。
平均場理論則做了這樣的近似:對于某個(gè)獨(dú)立的小個(gè)體,所有其他個(gè)體對它產(chǎn)生的作用可以用一個(gè)平均的量給出,這樣簡化后的模型就成了一個(gè)單體問題。
這種思想源于皮埃爾·居里(對,就是居里夫人的老公)和法國物理學(xué)家皮埃爾·外斯(Pierre-Ernest Weiss)對相變的研究。現(xiàn)在,平均場論廣泛用于如傳染病模型、排隊(duì)論、計(jì)算機(jī)網(wǎng)絡(luò)性能和博弈論當(dāng)中。
在深度學(xué)習(xí)領(lǐng)域,平均場論也得到了研究。這些研究都揭示了一點(diǎn),那就是在初始化階段,信號能在網(wǎng)絡(luò)中傳輸?shù)纳疃却嬖谝粋€(gè)最大值,而深度網(wǎng)絡(luò)之所以能夠被訓(xùn)練,恰恰是因?yàn)樾盘柲軌蛉客ㄟ^這些層。
平均場論預(yù)測信號在網(wǎng)絡(luò)中傳輸深度存在一個(gè)最大值,這也就是網(wǎng)絡(luò)可以被訓(xùn)練的深度
在這項(xiàng)工作中,作者基于平均場論開發(fā)了一個(gè)理論框架,研究深度CNN中信號的傳播情況。通過研究信號在網(wǎng)絡(luò)中向前和向后傳播而不衰減的必要條件,他們得出了一個(gè)初始化方案,在不對網(wǎng)絡(luò)的結(jié)構(gòu)進(jìn)行任優(yōu)化(比如做殘差連接、批標(biāo)準(zhǔn)化)的情況下,這個(gè)方案能幫助訓(xùn)練超級深——10000乃至更深的原始CNN。
簡單初始化策略,訓(xùn)練10000層原始CNN
那么,這個(gè)初始化方案是什么呢?先從結(jié)論說起,就是這個(gè)算法:

這是一個(gè)生成隨機(jī)正交卷積核的算法,目的是為了實(shí)現(xiàn)動態(tài)等距(dynamical isometry)。
大家都知道,深度神經(jīng)網(wǎng)絡(luò)中權(quán)重的初始化會對學(xué)習(xí)速度有很大的影響。實(shí)際上,深度學(xué)習(xí)建立在這樣一個(gè)觀察之上,即無監(jiān)督的預(yù)訓(xùn)練為隨后通過反向傳播進(jìn)行的微調(diào)提供了一組好的初始權(quán)重。
這些隨機(jī)權(quán)重的初始化主要是由一個(gè)原理驅(qū)動,即深度網(wǎng)絡(luò)雅可比矩陣輸入-輸出的平均奇異值應(yīng)該保持在1附近。這個(gè)條件意味著,隨機(jī)選擇的誤差向量在反向傳播時(shí)將保持其范數(shù)。由于誤差信息在網(wǎng)絡(luò)中進(jìn)行忠實(shí)地、等距地反向傳播,因此這個(gè)條件就被稱為“動態(tài)等距”。
對深度線性網(wǎng)絡(luò)學(xué)習(xí)的非線性動力學(xué)的精確解進(jìn)行理論分析后發(fā)現(xiàn),滿足了動態(tài)等距的權(quán)重初始化能夠大大提高學(xué)習(xí)速度。對于這樣的線性網(wǎng)絡(luò),正交權(quán)重初始化實(shí)現(xiàn)了動態(tài)等距,并且它們的學(xué)習(xí)時(shí)間(以學(xué)習(xí)輪數(shù)的數(shù)量來衡量)變得與深度無關(guān)。
這表明深度網(wǎng)絡(luò)雅可比矩陣奇異值的整個(gè)分布形狀,會對學(xué)習(xí)速度產(chǎn)生巨大的影響。只有控制二階矩,避免指數(shù)級的梯度消失和爆炸,才能留下顯著的性能優(yōu)勢。
現(xiàn)在,最新的這項(xiàng)研究發(fā)現(xiàn),在卷積神經(jīng)網(wǎng)絡(luò)中也存在類似的情況。作者將要傳播的信號分解為獨(dú)立的傅里葉模式,促進(jìn)這些信號進(jìn)行均勻的傳播。由此證明了可以比較容易地訓(xùn)練10000層或更多的原始CNN。
清除訓(xùn)練任意深度原始CNN的所有主要障礙
在ICLR 2017的一篇論文中,谷歌的研究人員,包括深度學(xué)習(xí)教父 Geoffrey Hinton 和谷歌技術(shù)大牛 Jeff Dean在內(nèi),提出了一個(gè)超大規(guī)模的神經(jīng)網(wǎng)絡(luò)——稀疏門控混合專家層(Sparsely-Gated Mixture-of-Experts layer,MoE)。
MoE 包含上萬個(gè)子網(wǎng)絡(luò)(也即“專家”),每個(gè)專家都有一個(gè)簡單的前饋神經(jīng)網(wǎng)絡(luò)和一個(gè)可訓(xùn)練的門控網(wǎng)絡(luò)(gating network),門控網(wǎng)絡(luò)會選擇專家的一個(gè)稀疏組合來處理每個(gè)輸入。
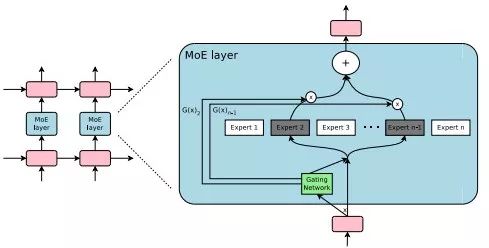
嵌入在循環(huán)語言模型中的混合專家(Mixture of Experts,MoE)模塊。在這種情況下,稀疏門函數(shù)選擇兩個(gè)專家來執(zhí)行計(jì)算,它們的輸出由門控網(wǎng)絡(luò)的輸出控制。
最終的網(wǎng)絡(luò)雖然是含有1370億個(gè)參數(shù)的龐然大物,但由于實(shí)現(xiàn)了條件計(jì)算的好處,模型容量得到了超過1000倍的提升,而計(jì)算效率只有相對微小的損失。MoE在大規(guī)模語言建模和機(jī)器翻譯基準(zhǔn)測試中,花費(fèi)很小的計(jì)算力實(shí)現(xiàn)了性能的顯著提升。這項(xiàng)工作也是深度網(wǎng)絡(luò)條件計(jì)算在產(chǎn)業(yè)實(shí)踐中的首次成功。
2017年6月,F(xiàn)acebook人工智能實(shí)驗(yàn)室與應(yīng)用機(jī)器學(xué)習(xí)團(tuán)隊(duì)合作,提出了一種新的方法,能夠大幅加速機(jī)器視覺任務(wù)的模型訓(xùn)練過程,僅 1 小時(shí)就訓(xùn)練完ImageNet這樣超大規(guī)模的數(shù)據(jù)集。Facebook 團(tuán)隊(duì)提出的方法是增加一個(gè)新的預(yù)熱階段(a new warm-up phase),隨著時(shí)間的推移逐漸提高學(xué)習(xí)率和批量大小,從而幫助保持較小的批次的準(zhǔn)確性。
現(xiàn)在,谷歌大腦的這項(xiàng)工作,提供了對這些實(shí)踐方法的理論理解。作者在論文中寫道,
我們的結(jié)果表明,我們已經(jīng)清除了在訓(xùn)練任意深度的原始卷積網(wǎng)絡(luò)時(shí)存在的所有主要的障礙。在這樣做的過程中,我們也為解決深度學(xué)習(xí)社區(qū)中的一些突出問題奠定了基礎(chǔ),例如單憑深度是否可以提高泛化性能。
我們的初步結(jié)果表明,在一定的深度上,在幾十或幾百層的這個(gè)數(shù)量級上,原始卷積結(jié)構(gòu)的測試性能已經(jīng)飽和。
這些觀察結(jié)果表明,殘差連接和批標(biāo)準(zhǔn)化(Batch Normalization)這些結(jié)構(gòu)上的特征,可能在定義好的模型類(model class)中有著重要的作用,而不是僅僅簡單地能夠提高訓(xùn)練的效率。
這一發(fā)現(xiàn)對深度學(xué)習(xí)研究社區(qū)有著重大的意義。不用批標(biāo)準(zhǔn)化,也不用殘差連接,僅僅通過一個(gè)初始化函數(shù),就訓(xùn)練10000層的原始CNN。
即使你不訓(xùn)練10000層,這個(gè)初始化帶來的訓(xùn)練速度提升也是可觀。
不過,作者目前只在MNIST和CIFAR10數(shù)據(jù)集上驗(yàn)證了他們的結(jié)果,推廣到更大的數(shù)據(jù)集后情況會如何,還有待觀察。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4764瀏覽量
100542 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5493瀏覽量
120983 -
cnn
+關(guān)注
關(guān)注
3文章
351瀏覽量
22171
原文標(biāo)題:【谷歌ICML】簡單初始化,訓(xùn)練10000層CNN
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論