 DNN與邏輯回歸效果一樣?
DNN與邏輯回歸效果一樣?
谷歌用深度學習分析電子病例的重磅論文給出了一個意外的實驗結果,DNN與邏輯回歸效果一樣,引發了熱烈討論。不僅如此,最近Twitter討論最多的論文,是UC戴維斯和斯坦福的一項合作研究,作者發現神經網絡本質上就是多項式回歸。下次遇到機器學習問題,你或許該想想,是不是真的有必要用深度學習。
近來,谷歌一篇關于使用深度學習進行電子病例分析的論文,再次引發熱議。
起因是以色列理工學院工業工程與管理學院的助理教授 Uri Shalit 在 Twitter 上發文,指出這篇論文的補充材料里,有一處結果非常值得注意:標準化邏輯回歸實質上與深度神經網絡一樣好。

Uri Shalit 的研究方向是將機器學習應用于醫療領域,尤其是在向醫生提供基于大型健康數據的決策支持工具方面。其次,他也研究機器學習和因果推斷的交集,重點是使用深度學習方法進行因果推斷。在加入以色列理工學院以前,他先后在 David Sontag 教授在紐約大學和在 MIT 的臨床機器學習實驗室當博士后。 Uri Shalit 說的補充材料中的結果是指這個:
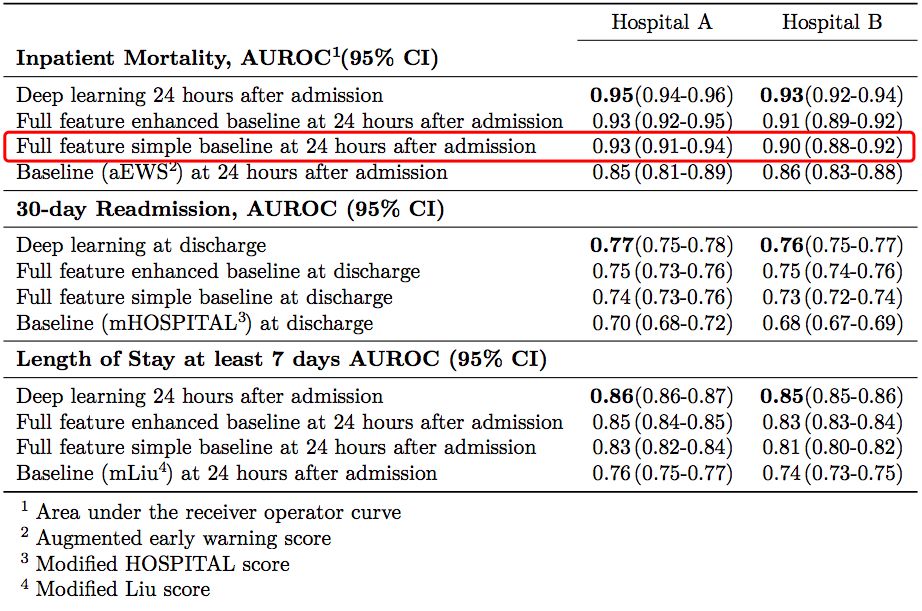
其中,基線 aEWS(augmented Early Warning Score)是一個有 28 個因子的邏輯回歸模型,在論文作者對預測患者死亡率的傳統方法 EWS 進行的擴展。而 Full feature simple baseline 則是 Uri Shalit 說的標準化邏輯回歸。
注意到基線模型(紅框標識)和深度模型在 AUCs 置信區間的重疊了嗎?
Uri Shalit 表示,他由此得出的結論是,在電子病例分析這類任務中,應該選擇使用邏輯回歸,而不是深度學習,因為前者更加簡單,更具可解釋性,這些優點要遠遠勝過深度學習帶來的微小的精度提升。
或者,Uri Shalit 補充說,這表明我們目前還沒有找到正確的深度學習結構,能實現在圖像、文本和語音建模領域中那樣的性能提升。
谷歌首篇深度學習電子病歷分析論文,Jeff Dean等大牛扛鼎之作,結果出人意料
谷歌的這篇論文“Scalable and Accurate Deep Learning for Electronic Health Records”,發表在自然出版集團(NPG)旗下開放獲取期刊 npJ Digital Medicine 上,由 Jeff Dean 率隊,聯合 UCSF、斯坦福、芝加哥大學眾多大牛,與全球頂級醫學院聯合完成,從題目到作者都吊足了大家的胃口。

實際上,早在今年初,新智元就介紹過這篇論文,當時它還只是掛在 arXiv 上,康奈爾大學威爾醫學院助理教授王飛對當時的 arXiv 版本進行了解讀。
這項工作是在 UCSF 和 UChicago 這兩大醫院系統的電子病歷數據上,用深度學習模型預測四件事:1)住院期間的死亡風險;2)規劃之外的再住院風險;3)長時間的住院天數;4)出院的疾病診斷。
文章仔細介紹了實驗信息,例如如何構建病人隊列、特征如何變換、算法如何評價等等。對于每一個預測任務,作者也都選取了臨床上常用的算法作為基線來進行比較,例如評價死亡風險的 EWS 分數,以及評價再住院風險的 HOSPITAL 分數,并對這些模型做了微小的改進。最終結果,作者提出的深度學習模型在各項任務中都顯著優于傳統模型(AUC 普遍提高 0.1 左右)。
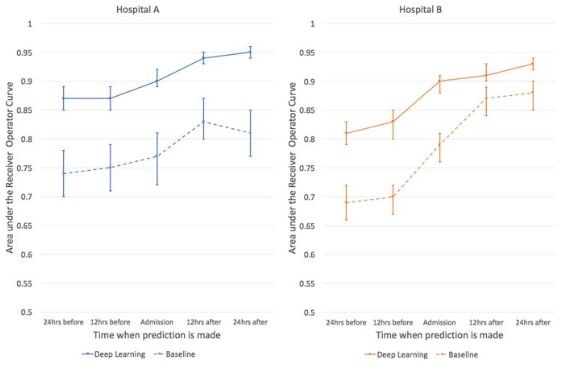
論文插圖:使用深度學習預測病人住院期間死亡風險,深度學習(實線)在前后24小時時間范圍內,都比基線水平(虛線)準確率更高。
如果說這次在同行評議期刊發表出的論文與之前的 arXiv 版本有什么不同,最大的就是給出了 15 頁的補充資料,展示了深度學習方法與各種基線的具體數值。
谷歌這篇論文的初衷,是強調直接從 FHIR 數據中進行機器學習(“我們提出了一種對病人整個基于 FHIR 格式的原始 EHR 的表示”)。正如論文中所寫的那樣,其方法的原創性并不僅僅在于對模型性能的提升,而是“這種預測性能是在沒有對專家認為重要的那些變量進行手動選擇的情況下實現的……模型訪問每位患者數以萬計的預測因子,并從中確定哪些數據對于進行特定的預測非常重要”。
但是,從論文的一些表述,尤其是標題中,難免有宣傳深度學習的嫌疑,也是這次爭議重點所在。
UC戴維斯和斯坦福新研究,首次證明神經網絡 = 多項式回歸
現如今,深度神經網絡已經成了很多分析師進行預測分析的首選。而在大眾媒體里,“深度學習”也幾乎可以算得上“人工智能”的同義詞。
深度學習的熱潮或許仍在持續,但很明顯,越來越多的人開始冷靜下來思考并且質疑。
在一篇最新公布的文章里,加州大學戴維斯分校和斯坦福的研究人員便指出,神經網絡本質上是多項式回歸模型。他們的文章取了一個謹慎的標題《多項式回歸作為神經網絡的代替方法》(Polynomial Regression As an Alternative to Neural Nets),對神經網絡的眾多性質進行了討論。

作者在論文中列出了他們這項工作的主要貢獻,包括:
NNAEPR 原理:證明了任何擬合的神經網絡(NN)與擬合的普通參數多項式回歸(PR)模型之間存在粗略的對應關系;NN 就是 PR 的一種形式。他們把這種松散的對應關系稱為 NNAEPR——神經網絡本質上是多項式模型(Neural Nets Are Essentially Polynomial Models)。
NN 具有多重共線性:用對 PR 的理解去理解 NN,從而對 NN 的一般特性提供了新的見解,還預測并且確認了神經網絡具有多重共線性(multicollinearity),這是以前未曾在文獻中報道過的。
很多時候 PR 都優于 NN:根據 NNAEPR 原理,許多應用都可以先簡單地擬合多項式模型,繞過 NN,這樣就能避免選擇調整參數、非收斂等問題。作者還在不同數據集上做了實驗,發現在所有情況下,PR 的結果都至少跟 NN 一樣好,在一些情況下,甚至還超越了 NN。
NNAEPR 原理——神經網絡本質上是多項式回歸
其中,作者重點論證了他們的 NNAEPR 原理。此前已經有很多工作從理論和實踐角度探討了神經網絡和多項式回歸的共性。但是,UC戴維斯和斯坦福的這幾名研究人員表示,他們的這項工作是首次證明了 NN 就是 PR 模型,他們從激活函數切入:
根據通用逼近定理,NN 可以無限逼近回歸函數 r (t),
假設 p = 2,用 u 和 v 來表示特征,第一層隱藏層的輸入,包括“1”的節點,將是
設激活函數為 ,那么第一層的輸出將是 u 和 v 的二次函數。類似地,第二層將產生四次多項式,依此類推,可以生成在回歸函數空間中密集的多項式。
,那么第一層的輸出將是 u 和 v 的二次函數。類似地,第二層將產生四次多項式,依此類推,可以生成在回歸函數空間中密集的多項式。
而對于更加實際的激活函數,其本身就常常被多項式逼近。因此,也適用于上述規則。
換句話說,NN 可以被松散地視為多項式回歸的一種。
實驗結果:多項式回歸在很多時候都優于神經網絡
作者進行了很多實驗來比較 PR 與 NN 的性能。在下面的各種結果中,PR 表示多項式回歸,PCA 表示在生成多項式之前用 90%總方差主成分分析降維。KF 表示通過 Keras API 的神經網絡,默認配置是兩層,一層 256 個單元,一層 128 個單元(寫作 “256,128”),dropout 比例是 0.4。DN 表示通過 R 語言包 deepnet 的神經網絡。DN 會比 KF 快很多,因此在大一些的問題里會用 DN,但兩者性能還是相似的。
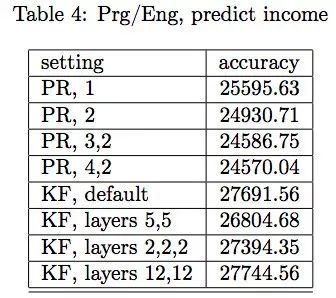
硅谷程序員收入預測的結果
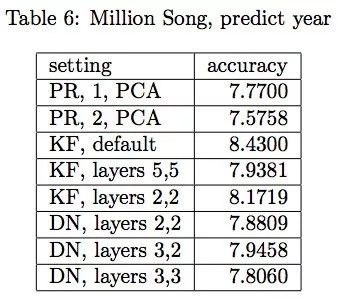
預測歌曲出版時間的結果
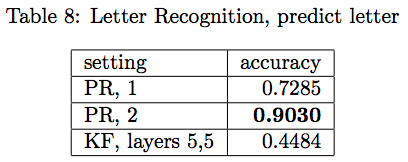
UCI 數據集字母預測的結果
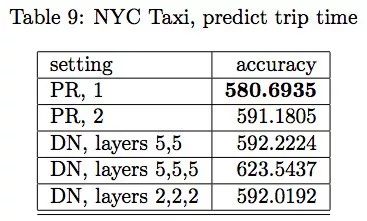
Kaggle 數據集出租車旅途時長預測結果
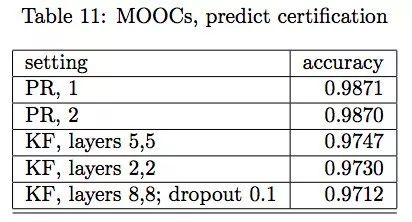
哈佛/MIT MOOC獲得證書預測結果
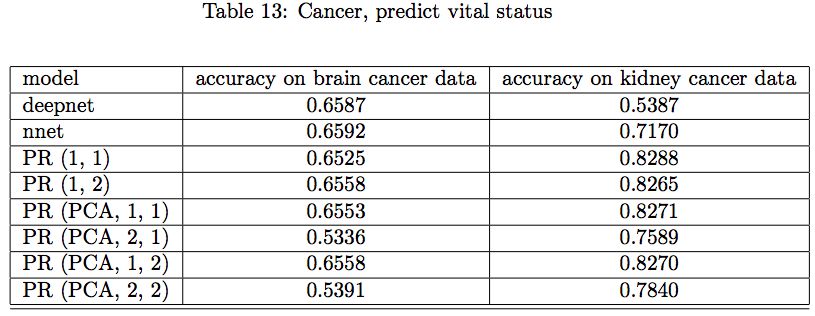
NCI 基因數據癌癥預測結果
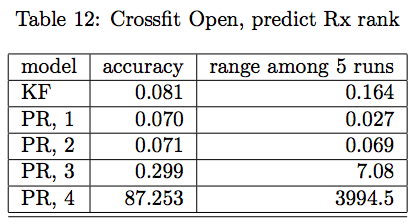
男女運動數據預測 Crossfit Open 排名

Crossfit Open 排名,數據集大小與預測精度的比較
總之,一系列實驗結果表明,PR 至少不會比 NN 差,有些時候還超過了 NN。在實踐中,許多分析師只是一開始就去擬合過大的模型,比如使用很多層,每層有數百個神經元。他們發現,使用 PR,很少需要超越 2 級,NNAEPR 原理表示,只用一層或者兩層就夠了,每一層有少量的神經元。
同時,作者也開始懷疑,擬合大的 NN 模型通常導致大多數的權重為0,或接近于0。他們已經開始調查這一點,初步結果與 NNAEPR 原理相結合表明,在 NN 初始化中 configur 大型網絡可能是個糟糕的策略。
最后,他們開源了一個 R 語言的軟件包 polyreg(Python 的正在制作中),里面有很大源代碼可以實現很多功能。
-
機器學習
+關注
關注
66文章
8306瀏覽量
131845 -
深度學習
+關注
關注
73文章
5422瀏覽量
120593
原文標題:【神經網絡本質是多項式回歸】Jeff Dean等論文發現邏輯回歸和深度學習一樣好
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論