 DeepMind論文推出了一種新的神經網絡——GQN
DeepMind論文推出了一種新的神經網絡——GQN
編者按:今天,DeepMind的研究人員在Science上發表論文,推出了一種新的神經網絡——GQN,只用幾張二維照片,就能重建全部的三維場景,可以說是計算機視覺領域的又一關鍵突破。
讓機器對空間環境進行感知似乎一直是DeepMind研究的重點,一個多月前我們曾報道過他們的另一項研究:DeepMind用AI解密大腦:當你找路時,大腦發生了什么。空間感知對人類來說很簡單,例如當我們第一次走進一個房間,掃一眼就能知道屋里有哪些物品、它們都在哪個位置上。只看到桌子的三條腿,你也能推斷出第四條腿的大致位置和形狀。另外,即使你沒有熟悉屋里的每個角落,也能大概描繪出它的平面圖,或者能想象出從另一個角度看房間應該是什么樣子的。
但是想讓人工智能系統做到上述行為的確很困難。現在最先進的計算機視覺系統仍需要在大型經過標注的數據集上進行訓練,而數據標注又是一項費時費力的工作,所以每次模型只能捕捉一小部分場景。隨著網絡越來越復雜,想詳細了解的周圍環境也越復雜:最近的座位在哪?沙發是什么材質的?所有影子的光源在哪?照明開關可能在哪?
在這次的研究中,DeepMind研究人員介紹了一種能感知周圍環境的框架——GQN(Generative Query Network)。和嬰兒或動物一樣,GQN通過觀察周圍環境收集數據,從而學習,無需人類對場景進行標記,就能掌握大致空間結構。
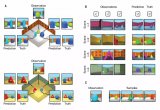
GQN模型由兩部分組成:一個表示網絡和一個生成網絡。表示網絡將智能體所觀察到的畫面作為輸入,生成一個表示(向量),描述了基本場景。之后,生成網絡從此前沒有觀察到的角度對場景進行預測(或者說是“想象”)。
但是表示網絡并不知道生成網絡要從哪個視角預測場景,所以它必須找到一種高效、精確的描繪場景平面的方法。它通過捕捉最重要的元素,例如物體的位置、顏色和房間平面,進行簡單表示。訓練期間,生成器學習辨認物體、特征、關系和環境的規律。這一套“共享”的概念讓表示網絡能用一種高度簡練、抽象的方式描繪場景,剩余的細節部分就由生成網絡補充。例如,表示網絡用一小串數字表示一個“藍色方塊”,生成網絡就知道從某個角度應該如何用像素展現出來。
DeepMind研究人員在程序生成的虛擬3D環境中對GQN做了多次試驗,包括多種不同物體,被擺放在不同的位置,并且形狀、顏色、材質都不相同,同時還改變了光線方向和遮擋程度。通過在這些環境上進行訓練,他們用GQN的表示網絡去生成一個從未見過的場景。在實驗中人們發現GQN展現出了幾個重要特征:
GQN的生成網絡可以在全新視角“想象”出此前沒有見過的景象,精確度非常高。給定一個場景表示和新的相機角度,網絡不需要任何先前信息就能生成精確的圖像。所以生成網絡也可以近似看成是從數據中學習的渲染器:

GQN的表示網絡可以獨自學習算數、定位、分類物體。就算在小型表示上,GQN也能在具體視角上做出非常精準的預測,和現實幾乎一模一樣。這說明了表示網絡觀察得非常仔細,例如下面這個由幾個方塊堆疊起來的場景:

GQN可以表示、測量并且減少不確定性。即使在沒有完全看到所有場景的情況下,網絡也可以解釋其中的不確定之處。同時也能根據部分圖像拼成完整的場景。下面的第一人稱視角和自上而下的預測方法就是其中的“秘訣”。模型通過它預測的變化性表達不確定性,其中預測的變化性隨著不斷在迷宮中移動減少(灰色三角是觀察位置)。

GQN表示支持穩定、數據高效的強化學習。給定GQN表示后,目前頂尖的深度強化學習智能體就開始學習以數據有效的方式完成任務。對這些智能體來說,生成網絡中編入的信息可以看作是對環境固有的認知:

利用GQN我們觀察到了更多數據有效的學習,比通常只利用原始像素的方法快了近4倍達到收斂水平
相較于前人研究,GQN是一種全新的學習現實場景的簡單方法。重要的是,這種方法不需要對具體場景建模,或者花大量時間對內容標注,一個模型就能應用多個場景。它還學習了一種強大的神經渲染器,能夠在任意角度生成精確的場景圖像。
不過,與一些傳統計算機視覺技術相比,這次所提出的方法仍然有很多限制,并且目前也都是在虛擬的合成場景上訓練的。不過,隨著更多可用數據的出現以及硬件的提升,研究人員希望進一步套索GQN的可能性,比如將它應用到現實場景中,同時提高成像分辨率。未來,研究GQN對更廣泛的場景理解非常重要,例如加入時間的維度,讓它學習對場景和移動的理解,同時應用到VR和AR技術中。盡管前路漫漫,這項工作對全自動場景辨別來說是重要一步。
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100568 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45930 -
數據集
+關注
關注
4文章
1205瀏覽量
24649
原文標題:DeepMind重磅論文:不用人類標記,幾張圖片就能渲染出3D場景
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
人工神經網絡原理及下載
【PYNQ-Z2試用體驗】神經網絡基礎知識
人工神經網絡實現方法有哪些?
神經網絡結構搜索有什么優勢?
如何構建神經網絡?
一種基于綜合幾何特征和概率神經網絡的HGU軸軌識別方法
一種基于高效采樣算法的時序圖神經網絡系統介紹
一種基于PID神經網絡的解耦控制方法的研究
一種基于人工神經網絡的秘密共享方案
一種改進的BP神經網絡調制分類器
Google AI子公司開發出一個神經網絡GQN,其組成部分介紹





 工商網監
工商網監
評論