") 建立一個(gè)源于StackExchange的新數(shù)據(jù)集
建立一個(gè)源于StackExchange的新數(shù)據(jù)集
ACL、EMNLP、NAACL和COLING是NLP領(lǐng)域的四大國(guó)際頂會(huì),其中ACL(Annual Meeting of the Association for Computational Linguistics)一直以受關(guān)注度更廣、論文投遞數(shù)量多著稱。7月15日至20日,第56屆年度ACL會(huì)議將在澳大利亞墨爾本舉辦,辛苦碼論文的你,準(zhǔn)備好了嗎?
作為頂會(huì),評(píng)選“最佳論文”和“終身成就獎(jiǎng)”幾乎已經(jīng)是一項(xiàng)“標(biāo)配”,ACL也不例外。往年會(huì)議通常會(huì)在正會(huì)上宣布獲獎(jiǎng)?wù)撐?嘉賓,但今年主辦單位計(jì)算語(yǔ)言學(xué)協(xié)會(huì)卻一反常態(tài),在會(huì)議前一個(gè)月就提前放出了“最佳論文”的評(píng)選結(jié)果——三篇“最佳長(zhǎng)論文”和兩篇“最佳短論文”。
Best Long Papers

Best Short Papers

雖然Finding syntax in human encephalography with beam search(用集束搜索在人體腦電圖中尋找語(yǔ)法)這篇論文從標(biāo)題上看起來(lái)似乎更具吸引力,但考慮到這5篇論文中只公開(kāi)了2、3兩篇長(zhǎng)論文,因此論智在這里只能簡(jiǎn)要介紹這兩篇的內(nèi)容。如果讀者有條件看到會(huì)場(chǎng)海報(bào),歡迎隨時(shí)分享。
論文2:Learning to Ask Good Questions

詢問(wèn)是溝通的基礎(chǔ),如果一臺(tái)機(jī)器連提問(wèn)都不會(huì),那它也絕對(duì)做不到高效地和人類溝通。在日常交流中,提問(wèn)的主要目標(biāo)是進(jìn)一步澄清問(wèn)題,填補(bǔ)信息空白,如當(dāng)用戶在論壇上向機(jī)器人詢問(wèn)Ubuntu操作系統(tǒng)使用問(wèn)題時(shí),為了篩選原因,機(jī)器人會(huì)根據(jù)條件產(chǎn)生幾個(gè)提問(wèn)選項(xiàng):
(a) 您的系統(tǒng)是哪個(gè)版本的?
(b) 您的無(wú)線網(wǎng)卡有哪些功能?
(c) 您是在64位操作系統(tǒng)上運(yùn)行的嗎?
在這種情況下,機(jī)器人不該問(wèn)(b),因?yàn)檫@是個(gè)無(wú)效問(wèn)題;它也不該選(c),因?yàn)檫@個(gè)問(wèn)題的答案面太狹窄了,如果用戶的回復(fù)是“不是”“不知道”,這也成了個(gè)無(wú)效問(wèn)題。所以這三個(gè)選項(xiàng)中唯一符合人類風(fēng)格的只有(a)。
本文主要做了兩方面工作,一是構(gòu)建了一個(gè)新型神經(jīng)網(wǎng)絡(luò)模型,它能基于獲得完美信息的期望值為問(wèn)題排序;二是建立了一個(gè)源于StackExchange的新數(shù)據(jù)集,它是模型的學(xué)習(xí)基礎(chǔ)。
新型神經(jīng)網(wǎng)絡(luò)模型
這個(gè)神經(jīng)模型的靈感來(lái)自完全信息期望值(EVPI),即擁有此隨機(jī)事件的完全信息時(shí)的最大期望值與未擁有此隨機(jī)事件完全信息時(shí)的最大期望值之差。當(dāng)然這里不用算最大,通俗來(lái)講,本文關(guān)注的是如果我們對(duì)Ubuntu操作問(wèn)題有一個(gè)已知信息X,那X的用處到底有多大?
因?yàn)楝F(xiàn)在沒(méi)有這個(gè)X,所以我們要先找出所有可能的X,并根據(jù)似然值加權(quán)計(jì)算。在提問(wèn)場(chǎng)景中,對(duì)于模型的給定問(wèn)題qi(前提是能回答),用戶可能有A個(gè)可能的回答;對(duì)于每個(gè)可能的回答aj∈A,模型有概率從中抽取信息,能為得出最終答案提供作用。因此qi的期望值是:

其中,
p是用戶發(fā)表的提問(wèn)帖;
qi是候選問(wèn)題集Q中的一個(gè)可能的問(wèn)題;
aj是針對(duì)Q的候選回答集A里的一個(gè)答案;
P[aj|p, qi]計(jì)算了對(duì)于帖子p和提問(wèn)qi,模型獲得回答aj的概率;
U(p+aj)是微觀經(jīng)濟(jì)學(xué)中常見(jiàn)的效用函數(shù),用來(lái)描述獲得答案aj后,它對(duì)帖子p的信息補(bǔ)充程度;
下圖展示了模型在測(cè)試期間的邏輯:

給定一個(gè)帖子p,模型先檢索10個(gè)類似p的帖子,并生成相應(yīng)的問(wèn)題集Q和答案集A。然后輸入p和提問(wèn)qi,獲得神經(jīng)網(wǎng)絡(luò)的輸出,也就是回答表征F(p, qi),計(jì)算P[aj|F(p, qi)]和P[aj|p, qi]的接近程度。之后,用U(p+aj)計(jì)算把回答改成aj后,p的信息補(bǔ)充提升效果。最后,再根據(jù)這個(gè)期望效果對(duì)問(wèn)題集Q里的問(wèn)題一一排序。
看到這里,這個(gè)模型要解決的問(wèn)題就只剩下兩個(gè)了:
概率分布P[aj|p, qi];
效用函數(shù)U(p+aj)。
那么它們背后的原理是什么呢?考慮到篇幅有限,小編這里不再展開(kāi)介紹了,如果好奇,請(qǐng)大家去讀原文——結(jié)構(gòu)清晰美觀,強(qiáng)烈推薦。
新數(shù)據(jù)集
關(guān)于這個(gè)數(shù)據(jù)集,內(nèi)容不多。它的原型是StackExchange上的評(píng)論數(shù)據(jù),共77,097條內(nèi)容。論文作者圍繞【帖子】【問(wèn)題】【答案】三個(gè)內(nèi)容創(chuàng)建了一個(gè)數(shù)據(jù)集,其中帖子都是未經(jīng)編輯的原帖,問(wèn)題是包含問(wèn)題的評(píng)論,答案是作者對(duì)帖子的修改和他對(duì)其他留言的評(píng)論。
實(shí)驗(yàn)結(jié)果
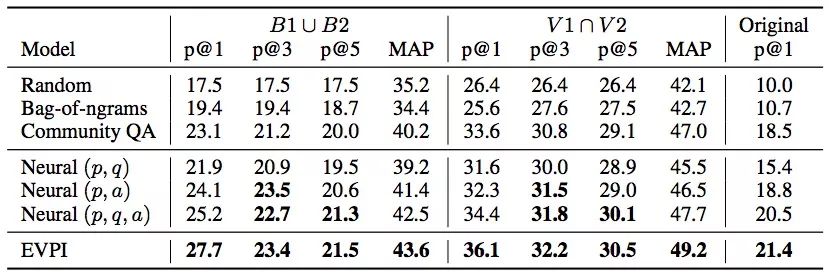
從上圖數(shù)據(jù)可以看出,論文提出的EVPI模型表現(xiàn)不錯(cuò),它在問(wèn)題生成任務(wù)上非常有前景,能切實(shí)幫助機(jī)器人在論壇上寫出高質(zhì)量回復(fù)。
論文地址:arxiv.org/pdf/1805.04655.pdf
論文3:Let’s do it “again”

這同樣是一篇有趣的論文,它在2010年Layth Muthana Khaleel那篇An Analysis of Presupposition Triggers in English Journalistic Texts的基礎(chǔ)上再次研究了語(yǔ)用學(xué)中的“預(yù)設(shè)”(Presupposition)問(wèn)題。
什么是語(yǔ)用預(yù)設(shè)?
預(yù)設(shè)一詞來(lái)自英國(guó)著名哲學(xué)家Strawson的《邏輯理論導(dǎo)論》:“一個(gè)命題S預(yù)設(shè)P,而且僅當(dāng)P是S有真值或價(jià)值的必要條件。”在語(yǔ)用學(xué)中,預(yù)設(shè)指的是參與對(duì)話者在言語(yǔ)交流時(shí)都已經(jīng)知道的信息和假設(shè),同時(shí)這些共知信息無(wú)需被說(shuō)出來(lái)。它在日常自然對(duì)話中隨處可見(jiàn),如:
(1) John is going to the restaurant again.
(2) John has been to the restaurant.
在這個(gè)例子中,因?yàn)榇嬖谝粋€(gè)“again”,所以只有當(dāng)(2)為真時(shí),(1)的表述才是合理的。表示因?yàn)镴ohn之前去過(guò)一次飯店,所以他能“再”去一次。語(yǔ)用預(yù)設(shè)和語(yǔ)義預(yù)設(shè)不同,其中最明顯的是它不會(huì)因在句子中添加否定而改變,如John is not going to the restaurant again,(2)同樣是這句話的預(yù)設(shè)。
我們把像“again”這樣表示預(yù)設(shè)存在的表達(dá)稱為預(yù)設(shè)觸發(fā)語(yǔ),它可以是實(shí)際的副詞、動(dòng)詞,也可以是一段明確的表述。而本文的研究?jī)?nèi)容則是一個(gè)可以檢測(cè)狀語(yǔ)預(yù)設(shè)觸發(fā)語(yǔ)的模型。
新數(shù)據(jù)集
為了訓(xùn)練模型,論文作者也自制了數(shù)據(jù)集。他們從Penn Treebank(PTB)和English Gigaword第三版子集這兩個(gè)語(yǔ)料庫(kù)里提取數(shù)據(jù),其中PTB里的22、23兩章和Gigaword里的700-760章是測(cè)試集,剩余數(shù)據(jù)里的90%是訓(xùn)練集,最后的10%則被用來(lái)提升模型。

對(duì)于每個(gè)數(shù)據(jù)集,他們的關(guān)注目標(biāo)是這5個(gè)副詞:too、again、also、still和yet。由于它們?cè)谟⒄Z(yǔ)中一般就充當(dāng)預(yù)設(shè)觸發(fā)語(yǔ),這就相當(dāng)于整個(gè)學(xué)習(xí)問(wèn)題被簡(jiǎn)化成了副詞預(yù)設(shè)觸發(fā)語(yǔ)是否存在——一個(gè)二元分類問(wèn)題。他們把包含這些副詞的句子標(biāo)記為positive,不包含的則是negative。
學(xué)習(xí)模型
這是一個(gè)引入了注意力機(jī)制的模型,從某種程度上來(lái)說(shuō),它擴(kuò)展了雙向LSTM模型,通過(guò)計(jì)算每個(gè)時(shí)間步的隱藏狀態(tài)之間的相關(guān)性,在這些相關(guān)性上應(yīng)用注意力機(jī)制。
下圖是論文提出的加權(quán)池化(WP)神經(jīng)網(wǎng)絡(luò)架構(gòu):

模型輸入序列u = {u1, u2,..., uT}在數(shù)據(jù)集原始序列基礎(chǔ)上經(jīng)過(guò)one-hot編碼而來(lái),時(shí)間步長(zhǎng)為T;
輸入網(wǎng)絡(luò)后,序列中的每個(gè)單詞ut會(huì)嵌入預(yù)訓(xùn)練的嵌入矩陣We∈R|V|×d,其中V表示數(shù)據(jù)集V中的單詞數(shù),d則是嵌入空間大小;
嵌入后所得的單詞向量xt∈Rd可以簡(jiǎn)單地用xt= utWe來(lái)表示,其中,因?yàn)閤t可能還包含單詞的詞性標(biāo)注,所以其實(shí)這個(gè)等式還應(yīng)該加上經(jīng)one-hot編碼的詞性標(biāo)注pt:xt= utWe||pt(||:向量級(jí)聯(lián)運(yùn)算符)。
我們獲得了雙向LSTM的輸入,之后用LSTM進(jìn)行編碼;
將編碼饋送進(jìn)注意力機(jī)制,計(jì)算出注意力權(quán)重后,對(duì)編碼狀態(tài)進(jìn)行加權(quán)平均;
將輸出依次連接到全連接層,預(yù)測(cè)狀語(yǔ)預(yù)設(shè)觸發(fā)語(yǔ)。
(上述過(guò)程中的雙向LSTM和注意力機(jī)制運(yùn)算非常常規(guī),請(qǐng)看原文)
實(shí)驗(yàn)結(jié)果

從結(jié)果上看他們的模型還是不錯(cuò)的,但考慮到我們使用的是中文,語(yǔ)用預(yù)設(shè)更加復(fù)雜,英語(yǔ)語(yǔ)境下的這種二元分類方法可能并不適用,但這也為其他語(yǔ)言研究提供了一個(gè)比較可行的思路。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4765瀏覽量
100561 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24648
原文標(biāo)題:ACL 2018:最佳論文評(píng)選結(jié)果提前出爐
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
建立開(kāi)發(fā)集和測(cè)試集(總結(jié))
PTB數(shù)據(jù)集建立語(yǔ)言模型
怎么建立一個(gè)驅(qū)動(dòng)為SQL D 的數(shù)據(jù)源?
一個(gè)benchmark實(shí)現(xiàn)大規(guī)模數(shù)據(jù)集上的OOD檢測(cè)
中國(guó)建立自主可控技術(shù)體系的一個(gè)機(jī)遇
一個(gè)完整的MNIST測(cè)試集,其中包含60000個(gè)測(cè)試樣本
Facebook AI發(fā)布了一個(gè)包含編碼問(wèn)題和代碼片段答案的數(shù)據(jù)集
數(shù)據(jù)科學(xué)平臺(tái)cnvrg.io攜手NetApp用深度學(xué)習(xí)改變MLOps數(shù)據(jù)集緩存
GitHub上開(kāi)源了個(gè)集眾多數(shù)據(jù)源于一身的爬蟲工具箱——InfoSpider
如何用PHP做一個(gè)機(jī)器學(xué)習(xí)數(shù)據(jù)集
建立計(jì)算模型來(lái)預(yù)測(cè)一個(gè)給定博文的抱怨強(qiáng)度
SAS:?數(shù)據(jù)集的橫向合并(一)
最全自動(dòng)駕駛數(shù)據(jù)集分享系列一:目標(biāo)檢測(cè)數(shù)據(jù)集

建立一個(gè)網(wǎng)狀連接的家庭項(xiàng)目





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論