") RNN及其變體LSTM和GRU
RNN及其變體LSTM和GRU
對于文本和語音這樣的序列化數(shù)據(jù)而言,循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)是非常高效的深度學(xué)習(xí)模型。RNN的變體,特別是長短時(shí)記憶(LSTM)網(wǎng)絡(luò)和門控循環(huán)單元(GRU),在自然語言處理(NLP)任務(wù)中得到了廣泛應(yīng)用。
然而,盡管在語言建模、機(jī)器翻譯、語言識別、情感分析、閱讀理解、視頻分析等任務(wù)中表現(xiàn)出色,RNN仍然是“黑盒”,難以解釋和理解。
有鑒于此,香港科技大學(xué)的Yao Ming等提出了一種新的可視化分析系統(tǒng)RNNVis,基于RNNVis,可以更好地可視化用于NLP任務(wù)的RNN網(wǎng)絡(luò),理解RNN的隱藏記憶。
在介紹RNNVis系統(tǒng)之前,先讓我們溫習(xí)一下RNN及其變體LSTM和GRU.
RNN及其變體
循環(huán)神經(jīng)網(wǎng)絡(luò)
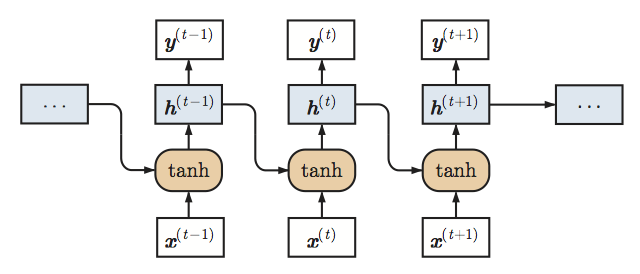
如上圖所示,原始RNN接受序列化輸入{x(0), ...,x(T)},并維護(hù)一個(gè)基于時(shí)間的隱藏狀態(tài)向量h(t)。在第t步,模型接受輸入x(t),并據(jù)下式更新隱藏狀態(tài)h(t-1)至h(t):

其中,W、V為權(quán)重矩陣而f是非線性激活函數(shù)。上圖中,f為tanh.
h(t)可直接用作輸出,也可以經(jīng)后續(xù)處理后用作輸出。比如,在分類問題中,對隱藏狀態(tài)應(yīng)用softmax運(yùn)算后輸出概率分布:
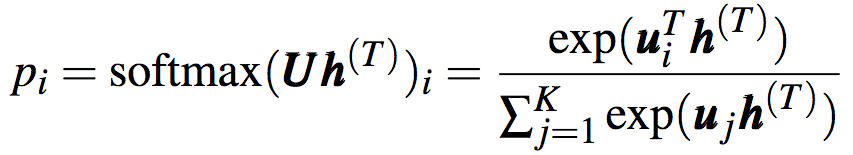
長短時(shí)記憶網(wǎng)絡(luò)
和原始RNN不同,LSTM除了維護(hù)隱藏狀態(tài)h(t)外,還維護(hù)另一個(gè)稱為細(xì)胞狀態(tài)(cell state)的記憶向量c(t)。此外,LSTM使用輸入門i(t)、遺忘門f(t)、輸出門o(t)顯式地控制h(t)、c(t)的更新。三個(gè)門向量通過如下方法計(jì)算:
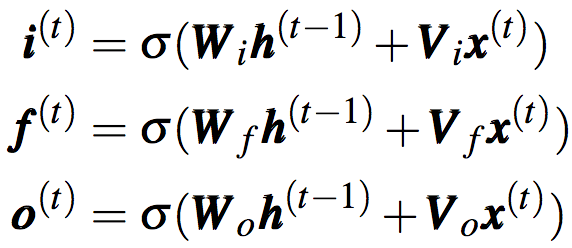
細(xì)胞狀態(tài)和隱藏狀態(tài)則通過如下方法計(jì)算:
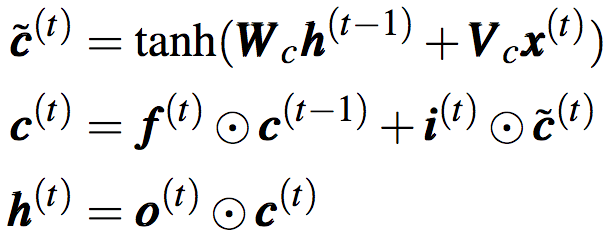
上面的第一個(gè)公式為候選細(xì)胞狀態(tài)。
基于細(xì)胞狀態(tài)和門向量,相比原始RNN,LSTM能維持更久的信息。
門控循環(huán)單元
相比LSTM,GRU要簡單一點(diǎn)。GRU只使用隱藏狀態(tài)向量h(t),和兩個(gè)門向量,更新門z(t)、重置門r(t):

在更新隱藏狀態(tài)之前,GRU會(huì)先使用重置門計(jì)算候選隱藏狀態(tài):
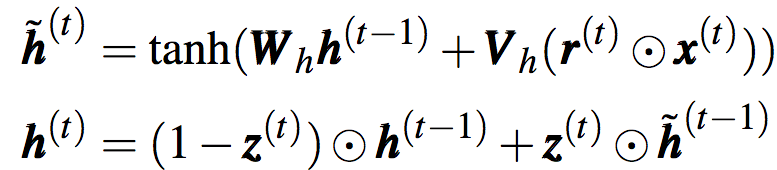
多層模型
為了增加表示能力,直接堆疊RNN網(wǎng)絡(luò)可得到多層RNN模型:
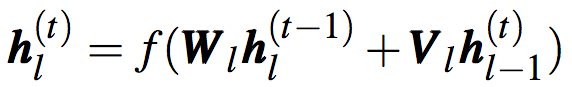
其中,h0(t)=x(t)
類似地,LSTM和GRU也可以通過堆疊得到多層模型。
協(xié)同聚類可視化二分圖
還記得我們之前提到,對隱藏狀態(tài)進(jìn)行后續(xù)處理(例如softmax)可以輸出分類的概率分布嗎?
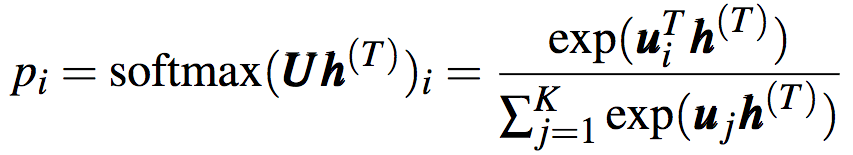
上式可以分解為乘積:
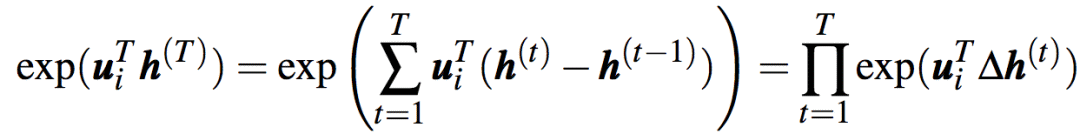
其中,?h(t)可以解讀為模型對輸入單詞t的反應(yīng)。
相應(yīng)地,模型對輸入單詞w的反應(yīng)的期望可以通過下式計(jì)算:
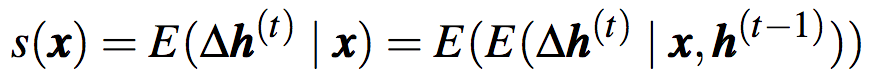
其中,x為單詞w的嵌入向量,s(x)i表示hi和w之間的關(guān)系。s(x)i的絕對值較大,意味著x對hi較重要。基于足夠的數(shù)據(jù),我們可以據(jù)下式估計(jì)反應(yīng)的期望:
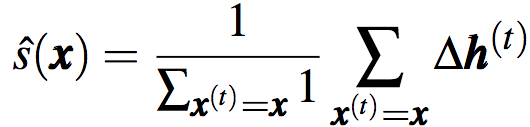
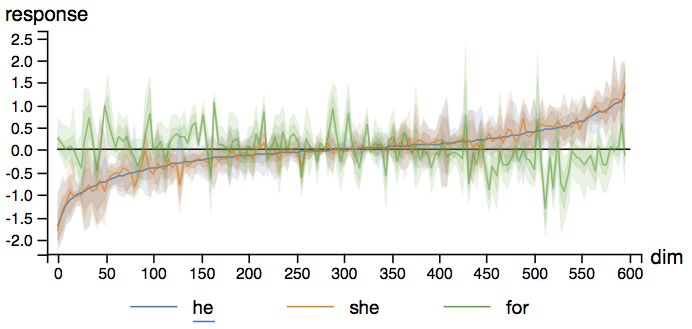
下圖為一個(gè)雙層LSTM對三個(gè)不同的單詞的反應(yīng)分布。該LSTM每層有600個(gè)細(xì)胞狀態(tài)單元,基于Penn Tree Bank(PTB)數(shù)據(jù)集訓(xùn)練。我們可以看到,模型對介詞(“for”)和代詞(“he”、“she”)的反應(yīng)模式大不相同。
基于前述期望反應(yīng),每個(gè)單詞可以計(jì)算出n個(gè)隱藏單位的期望反應(yīng),同時(shí),每個(gè)隱藏單元可以計(jì)算出對n個(gè)單詞的期望反應(yīng)。如果將單詞和隱藏單元看作節(jié)點(diǎn),這一多對多關(guān)系可以建模為二分圖G = (Vw, Vh, E)。其中,Vw和Vh分別為單詞和隱藏節(jié)點(diǎn)的集合。而E為加權(quán)邊:
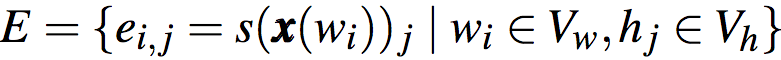
要可視化分析二分圖,很自然地就想到使用協(xié)同聚類。

從上圖我們可以看到,功能類似的單詞傾向于聚類在一起。
RNNVis
以上述可視化分析技術(shù)為核心,論文作者構(gòu)建了RNNVis可視化系統(tǒng):
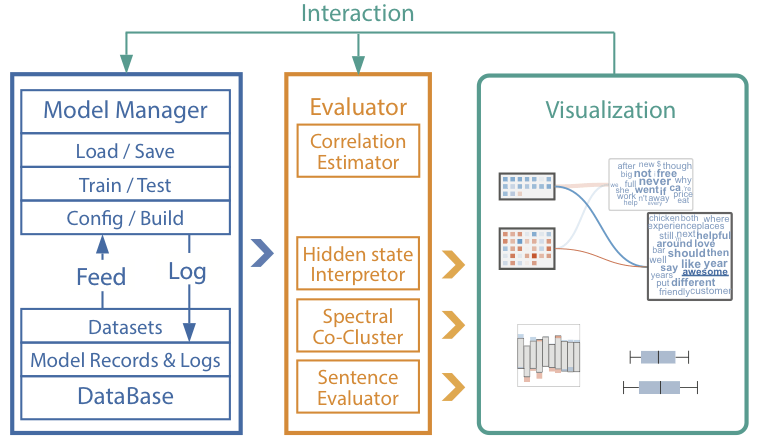
如上圖所示,RNNVis包含3個(gè)主要模塊:
模型管理器使用TensorFlow框架構(gòu)建、訓(xùn)練和測試RNN模型。用戶可以通過編輯配置文件修改模型的架構(gòu)。
RNN評估器分析訓(xùn)練好的模型,提取隱藏狀態(tài)中學(xué)習(xí)到的表示,并進(jìn)一步處理評估結(jié)果以供可視化。同時(shí),它也能夠提供單詞空間中每個(gè)隱藏狀態(tài)的解釋。
交互式可視化用戶可以在主界面點(diǎn)擊單詞或記憶單元,以查看詳情。另外,用戶也可以調(diào)整可視化風(fēng)格。
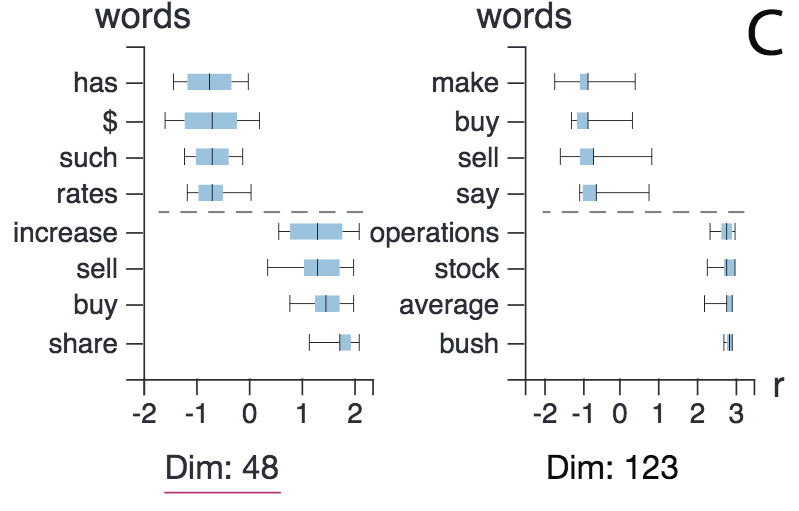
上圖為詳情頁面。箱形圖顯示,第48維和第123維都捕捉到了像“buy”(“買”)和“sell”(“賣”)這樣的動(dòng)詞,盡管兩者的符號不同。另外,這一詳情界面也表明,LSTM網(wǎng)絡(luò)能夠理解單詞的語法功能。
比較不同模型
除了用于理解單個(gè)模型的隱藏記憶,RNNVis還可以用來比較兩個(gè)模型:
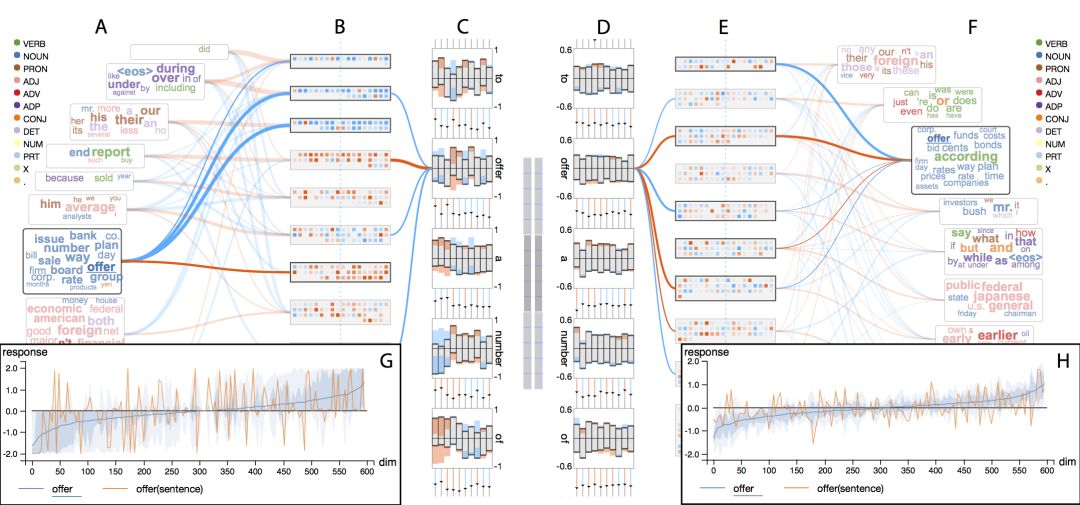
上圖比較了原始RNN和LSTM。無論是記憶單元的飽和度(B和E),還是具體的響應(yīng)歷史(C和D),都反映了RNN比LSTM更密集地更新隱藏記憶。換句話說,LSTM對輸入的反應(yīng)更加稀疏。詳情頁面基于單個(gè)單詞的比較也印證了這一點(diǎn)(G和H)。
LSTM相比RNN更“懶惰”,這可能是它在長期記憶方面勝過RNN的原因。
比較同一模型的不同層
除了用來比較不同模型,RNNVis還可以用來比較同一模型的不同層。
對CNN的可視化研究揭示了,CNN使用不同層捕捉圖像中不同層次的結(jié)構(gòu)。初始層捕捉較小的特征,例如邊緣和角落,而接近輸出的層學(xué)習(xí)識別更復(fù)雜的結(jié)構(gòu),以表達(dá)不同的分類。

圖片來源:arXiv:1710.10777
而關(guān)于RNN及其變體不同層的作用,研究較少。一個(gè)自然的假想是初始層學(xué)習(xí)抽象表示,而后續(xù)層更多地學(xué)習(xí)特定任務(wù)的表示。
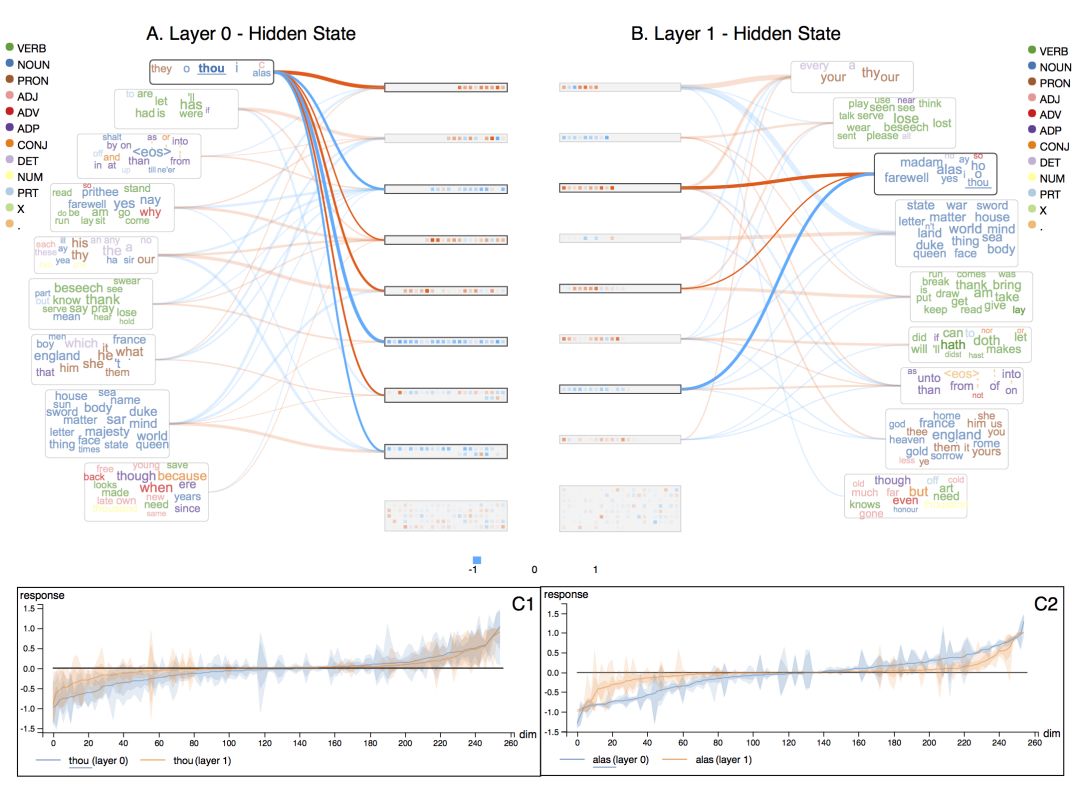
從上圖我們可以看到,第0層的“記憶芯片”的尺寸比第1層更均勻。另一方面,第1層的單詞云中單詞的顏色更一致。也就是說,第1層的單詞云的質(zhì)量比第0層更高。這意味著第0層對不同單詞的用法的把握更模糊,而第1層在識別不同功能的單詞方面更聰明。
分別點(diǎn)擊兩層中的單詞“thou”,我們可以看到,相比第0層(C1),第1層對單詞“thou”的反應(yīng)更稀疏(C2)。在其他單詞上也有類似的現(xiàn)象。對于語言建模而言,這樣的稀疏性有助于最后層,在最后層,輸出通過softmax直接投影到一個(gè)巨大的單詞空間(包含數(shù)千單詞)。
如此,我們通過可視化印證了之前的假想,模型使用第一層構(gòu)建抽象表示,使用最后一層表達(dá)更為任務(wù)相關(guān)的表示。
案例研究
論文作者通過兩個(gè)案例試驗(yàn)了RNNVis的效果。
情感分析
論文作者使用的數(shù)據(jù)集是Yelp Data Challenge,該數(shù)據(jù)集包含四百萬餐館點(diǎn)評及評分(一分到五分)。評分正好可以視為點(diǎn)評的標(biāo)簽。為了簡化問題,論文作者預(yù)處理了五個(gè)標(biāo)簽,將其歸并為兩個(gè)標(biāo)簽,其中,一分、二分映射為“消極”,四分、五分映射為“積極”,三分的點(diǎn)評不計(jì)在內(nèi)。同樣是為了簡化問題,只使用了原數(shù)據(jù)集的一個(gè)子集,2萬條長度小于100個(gè)單詞的點(diǎn)評。然后按照80/10/10的百分比分割訓(xùn)練/驗(yàn)證/測試集。
所用網(wǎng)絡(luò)為單層GRU,包含50個(gè)細(xì)胞狀態(tài),在驗(yàn)證集和測試集上分別達(dá)到了89.5%和88.6%的精確度。
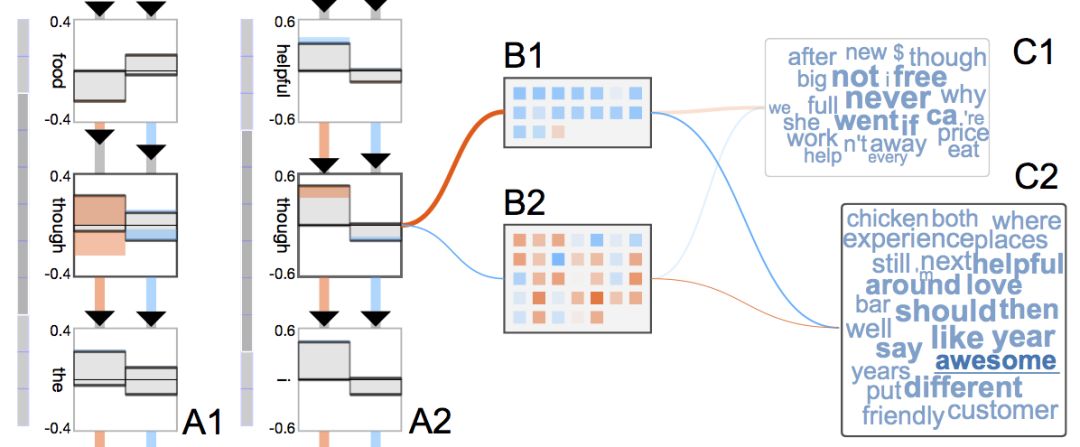
從上圖的單詞云可以看到,GRU可以理解單詞的極性。上面的云包含“never”、“not”之類的消極單詞,而下面的云包含“l(fā)ove”、“awesome”、“helpful”之類的積極單詞。
另外,上圖分析的是兩個(gè)不同的轉(zhuǎn)折句:
I love the food, though the staff is not helpful. (我喜歡食物,不過服務(wù)人員不熱情。)
The staff is not helpful, though I love the food. (服務(wù)人員不熱情,不過我喜歡食物。)
從上圖可以看到,GRU對同一個(gè)單詞“though”的反應(yīng)不同,第一個(gè)句子中的“though”導(dǎo)致隱藏狀態(tài)的更新更多,也就是說,GRU對消極情緒更敏感。
另一方面,數(shù)據(jù)集中許多消極單詞,比如“bad”(“糟”)和“worst”(“最糟”)并沒有出現(xiàn)在可視化之中。
這兩點(diǎn)暗示GRU在積極點(diǎn)評和消極點(diǎn)評上的表現(xiàn)可能不一樣。論文作者檢查了數(shù)據(jù)集,發(fā)現(xiàn)數(shù)據(jù)集并不均衡,積極點(diǎn)評與消極點(diǎn)評的比例接近3:1。基于過采樣技術(shù),得到了均衡的數(shù)據(jù)集。在該數(shù)據(jù)集上重新訓(xùn)練的GRU模型,表現(xiàn)提升了,在驗(yàn)證集和測試集上分別達(dá)到了91.52%和91.91%的精確度。
可視化新模型后,單詞云(C)包含更多情緒強(qiáng)烈的單詞,比如消極單詞云中的“rude”(粗魯)、“worst”(最糟)、“bad”(糟),和積極單詞云中的“excellent”(極好)、“delicious”(美味)、“great”(棒)。詳情頁面(A)顯示,模型對“excellent”和“worst”具備完全相反的反應(yīng)模式。
莎士比亞著作
論文作者使用莎士比亞的著作(包含一百萬單詞)構(gòu)建了一個(gè)語言建模數(shù)據(jù)集(詞匯量一萬五千)。數(shù)據(jù)集按80/10/10百分比分為訓(xùn)練/驗(yàn)證/測試數(shù)據(jù)集。
研究人員使用小、中、大三個(gè)規(guī)模的LSTM網(wǎng)絡(luò)。
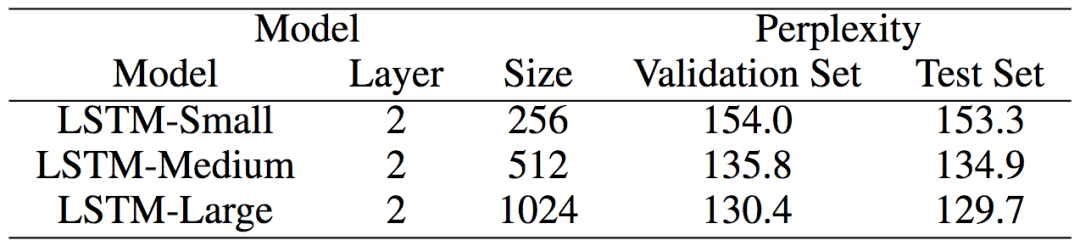
下面的評估和可視化結(jié)果屬于中等規(guī)模的LSTM網(wǎng)絡(luò),不過,其他兩個(gè)LSTM網(wǎng)絡(luò)上的結(jié)果與此類似。
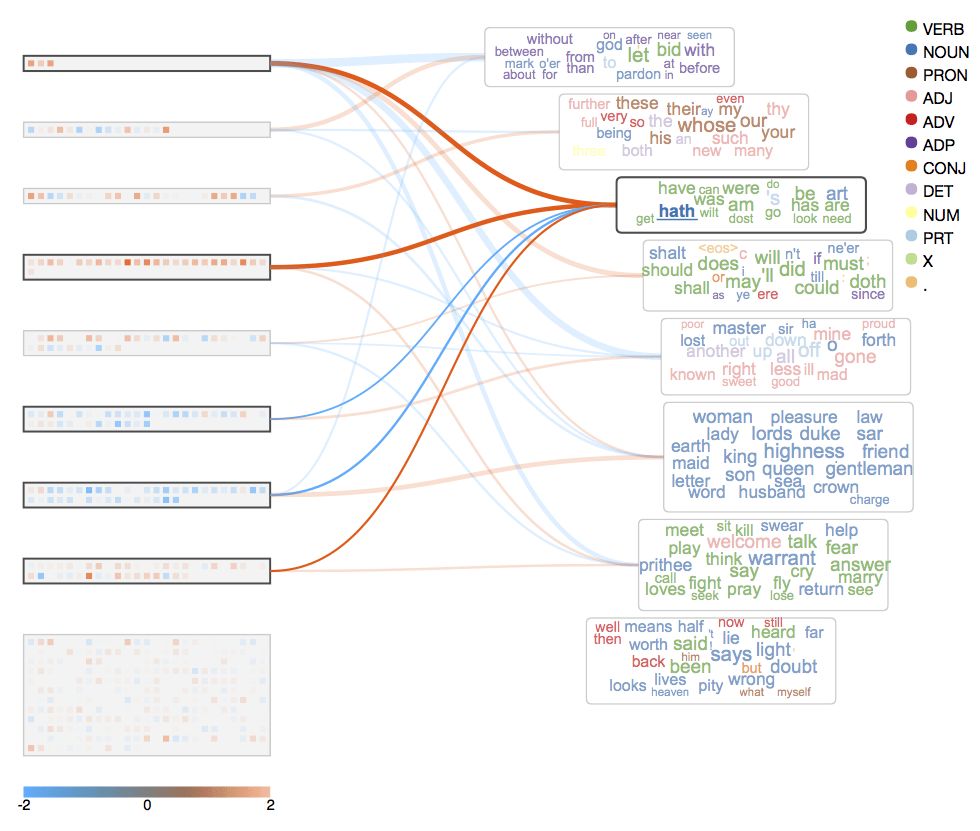
莎士比亞的語言混雜了新舊兩個(gè)時(shí)期的英語。而從上圖我們可以看到,“hath”、“dost”、“art”和“have”、“do”、“are”位于同一片單詞云中。這說明,模型能夠?qū)W習(xí)這些用途相似的助詞,不管它們是來自古英語還是現(xiàn)代英語。詳情界面印證了這一點(diǎn),成對的新詞和舊詞具有相應(yīng)的反應(yīng)模式。

上圖中有一個(gè)例外,是“thou”和“you”。這是因?yàn)樵谏勘葋啎r(shí)期,“thou”和“you”的用法有細(xì)微的差別,“thou”為單數(shù),常用于非正式場合,而“you”為復(fù)數(shù),更正式、更禮貌。
以后的工作
論文作者計(jì)劃部署一個(gè)RNNVis的線上版本,并增加更多RNN模型的量化指標(biāo)以提升可用性。
由于可視化分析技術(shù)基于文本的離散輸入空間,RNNVis只適用于分析用于文本的RNN系列模型。分析用于音頻應(yīng)用的RNN模型尚需構(gòu)建可解釋的表示。
當(dāng)前RNNVis的瓶頸在于協(xié)同聚類的效率和質(zhì)量,可能導(dǎo)致交互時(shí)的延遲。
另外,目前RNNVis還不能可視化一些特化的RNN變體,比如記憶網(wǎng)絡(luò)(memory network)或注意力模型(attention model)。支持這些RNN變體需要對RNNVis進(jìn)行擴(kuò)展。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4762瀏覽量
100541 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120978 -
自然語言
+關(guān)注
關(guān)注
1文章
287瀏覽量
13332
原文標(biāo)題:可視化循環(huán)神經(jīng)網(wǎng)絡(luò)的隱藏記憶
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
GRU是什么?GRU模型如何讓你的神經(jīng)網(wǎng)絡(luò)更聰明 掌握時(shí)間 掌握未來
FPGA也能做RNN
放棄 RNN 和 LSTM 吧,它們真的不好用
LSTM和GRU的動(dòng)態(tài)圖解
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)和(LSTM)初學(xué)者指南
一種具有強(qiáng)記憶力的 E3D-LSTM網(wǎng)絡(luò),強(qiáng)化了LSTM的長時(shí)記憶能力

循環(huán)神經(jīng)網(wǎng)絡(luò)LSTM為何如此有效?
神經(jīng)網(wǎng)絡(luò)中最經(jīng)典的RNN模型介紹
深度分析RNN的模型結(jié)構(gòu),優(yōu)缺點(diǎn)以及RNN模型的幾種應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論