 人工智能教育領域的專家來剖析智適應技術的內核做對比研究
人工智能教育領域的專家來剖析智適應技術的內核做對比研究
人工智能和機器學習第一次讓我們真正有可能規模化地實現“因材施教”。AI+教育不僅能徹底改變輔導教育,顛覆6800億的K-12校外輔導市場,還有可能徹底改變教育市場格局及教育本身。變革前夜,在這股新興的浪潮中,我們來探究智適應教育的國內外成功案例,找到人工智能教育領域的專家來剖析智適應技術的內核做對比研究。
上月,亞太地區第二場“教育界AlphaGo”對人類教師的人機大戰在成都上演,對壘雙方是乂學教育的松鼠AI教學機器人與平均教齡近20年的三名高級教師、優質課競賽一等獎名師、中考命題組成員。
比賽結果:教學機器人組的學生取得的成績提升比優秀教師組的學生高出了7分。
這是繼去年10月份之后,機器人又一次戰勝人類教師。
去年,全球最著名的兩家科技巨頭創始人,比爾·蓋茨和馬克·扎克伯格聯手投入1200萬美元到個性化教育,將2017年的教育市場對智能個性化方向的關注推向一個高點;國內,包括乂學教育、好未來、新東方、學霸君、一起作業網等30多家教育機構相繼宣布開始轉型智適應技術驅動的個性化教育。
本文主要從自適應學習的概念談起,以乂學教育的松鼠AI智適應系統為范例,美國的幾家人工智能自適應企業的技術方案為參考,全面剖析智適應技術的發展歷程,深度展示智適應教育技術的核心理念和關鍵細節。
科技巨頭紛紛介入個性化教育,“教育界AlphaGo”教學成績超過高級教師和中考命題人
5月在成都舉辦的亞太第二場“教育界AlphaGo”對人類教師的人機大戰,相比去年第一次在鄭州的70多名學生,這次實驗人數達到160人。對壘雙方是乂學教育的松鼠AI教學機器人與平均教齡近20年的三名高級教師、優質課競賽一等獎名師、中考命題組成員。
最終,教學機器人組的學生取得的成績提升比優秀教師組的學生高出了7分。
第二次完勝優秀教師的松鼠AI教學機器人所采用的是乂學埋頭三年研發打造的基于人工智能的自適應學習模型。
從2014年底開始,中國迅猛地卷起了智適應教育的浪潮,乂學教育、學吧課堂、論答、高木等等一批批新創智適應公司開始落地;傳統線下行業巨頭也開始布局,好未來一手從BAT挖來700多人改造傳統線下教育模式,一手投資了乂學、Knewton、作業盒子等智適應公司;幾乎所有的原來做題庫、作業、測評、語音識別、視頻內容、和流量平臺、甚至一對一直播的公司都紛紛宣布轉型人工智能自適應,并且因為這個概念紛紛獲得了高額融資。
在這一場智適應顛覆教育行業的歷史性時機,中國無論是在資本市場投入還是教育行業創始人的堅定性上都已經體現出絲毫不遜于美國的彎道超車的態勢,但是在技術水平層面呢?

智適應學習:實現個性化教育的最佳路徑
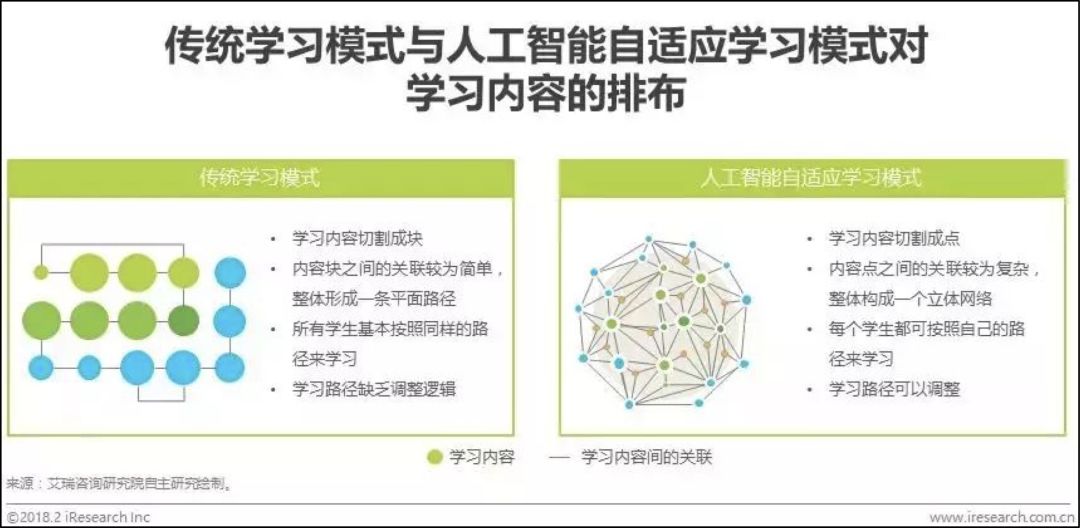
教育領域的幾個最重要的因素:學生—內容—學習,構成了這一領域天然的完整閉環:學生對內容的學習,實際上是用戶制造數據的場景,而教育領域由于其高度粘性,場景產生的數據反過來又能反饋用戶。人工智能技術出現,讓以學生為核心的個性化教育成為資本、技術、市場追捧的對象。而個性化教育中,智適應學習成為一個重要的突破口和成熟的實踐路徑。
人工智能技術加持下,教育創新產品呈現出百花齊放的狀態。目前,已有的智能產品包括語音識別、自動閱卷、拍照答題等,雖然這些教學方法部分應用了先進的人工智能技術,但應用場景只停留在學習過程的輔助環節上,而不會直接帶來教學質量和效果的提升,實際上與傳統的線下教育并無模式上的差異。此外,各個學習知識點之間無法自動關聯。如果教學過程仍舊主要由老師完成,那么教學內容就無法結構化,學生的學習認知過程也無法數據化,導致算法在教學核心和環節無法發揮作用。
智適應學習的出現,能夠解決傳統在線教學的痛點,是實現規模化個性化教育的最佳路徑。
智適應學習在中國的先行者和范例
乂學教育創始人栗浩洋介紹,“松鼠AI”是基于人工智能、面向K-12群體而推出的智適應學習平臺,是乂學教育推出的以系統為主導完成“教”和“學”的核心過程的“全循環”AI教育產品,完全不同于國內其他機構僅僅以測評、練習、作業等輔助老師教學的“邊緣性”AI教育工具。
乂學建立的是連續性的全過程的智適應學習模型和相應的算法,其中應用了智能測評算法,能力診斷和學生狀態表征模型,以及應用在學習路徑規劃和學習內容規劃這兩個方面的推薦算法,除此之外,乂學還在研究利用深度學習進行的學習模式選擇和預警/干預等算法。其核心是通過采集和分析學習數據,讓AI結合“納米級”的知識圖譜用最少的時間檢驗/掌握與目標相關的知識點,連續地通過學生知識狀態的衡量,建立個性化的動態學生畫像,了解每位學生的學習狀態和遇到的問題,相應地設計測試和學習路徑,調整教學行為,并在學習過程中不斷推薦最合適的學習材料,而且衡量學習效果,并形成對AI預測能力和內容效果的自我學習和反饋。
據乂學教育首席科學家崔煒博士介紹,乂學推出的“松鼠AI”就像AlphaGo模擬圍棋大師一樣模擬特級教師。現階段,乂學教育分別對用戶(學生)、場景(學習)、數據(內容)三個要素進行建模:
針對學生的用戶畫像。即學生的個人偏好興趣、學習風格、認知特性、能力水平和知識狀態的掌握。
對學習內容進行建模,構建“納米級”知識圖譜。把不同形式的學習資源以視頻、文字、音頻、圖片和題目的形式展現。同時建立算法對知識點和題目“打標簽”,給出相應的難度系數等。
個性化匹配。通過前述兩個步驟產生的數據,為每個學生匹配最適合的學習路徑和課程,推薦個性化的學習內容,最大化學習效率。
美國自適應的探秘和借鑒
乂學的人工智能自適應學習模型和技術,代表了中國市場上的最先進水平,很大一個原因在于乂學教育的創始人栗浩洋,先后引進集結了三位全球領先的智適應學習技術專家包括崔煒、Richard Tong和Dan Bindman分別作為首席科學家、首席架構師和首席數據科學家。崔煒、Richard Tong和Dan Bindman 分別來自于全球著名的三家人工智能自適應教育企業RealizeIT,Knewton, 和 ALEKS,他們綜合了近十年的第一手的智適應教育技術應用和研發經驗,讓乂學站在了巨人的肩膀上,幫助構建了乂學擁有自主知識產權的不斷進化演變的技術壁壘。
Richard Tong
Dan Bindman
崔煒博士
Richard曾先后任Amplify Education (News Corp) 的方案架構總監和Knewton亞太區方案實施總負責人,擔任SIF Association 國際技術委員會委員,從2011年起領導著包括評估和鑒定管理工作組在內的兩個工作小組,是美國K-12教育領域公認的專家和領導者。
而DanBindman從PhD開始就研究人工智能,在2002年UC Irvine博士畢業后就直接加入了ALEKS的智適應產品初創團隊,并領導規劃/實施了ALEKS整體的知識點和關聯知識圖譜(百萬級別的圖譜數據連接參數體系);2015-2017年擔任Ready4的數據科學總監。
在上個月乂學聯合新智元等媒體舉辦的全球第一屆人工智能自適應教育峰會上,三位全球頂級專家的深度演講吸引了近千人參會,其中參會的近百家基金的總計規模超過2000億。
更值得一提的是,很多中國同行往往將海外專家聘為顧問,而乂學的這三位專家卻全部是全職加入,用全部工作時間投入到技術研究和開發之中,下面是他們對Knewton、ALEKS和RealizeIt的介紹和技術分析:
Knewton
Knewton是一家自適應學習平臺公司,2008年由Jose Ferreira (自適應教育這一名詞的締造者)創立于美國紐約,目前估值近10億美金。核心產品是自適應學習引擎,使用個性化數據展現學生的特征,在學生學習數據搜集、個性化學習內容推送等技術上處于世界領先地位。其目標是為發行商、學校及全球的學生提供預測性分析及個性化推薦。其學習效果經過數次十萬人次以上的實驗和實地使用的顯著性論證,得到國際教育界的廣泛引用,是自適應領域的標桿型企業。
在學習過程中,Knewton提供了三種核心服務:向學生提供建議;向教師和學生提供分析服務;向出版商和編輯提供內容方面的見解。在合作伙伴的數字化課程中,Knewton平臺對學生個體的能力偏好進行推斷,并在此推斷和導師定義的目標基礎上,建議學生如何開展下一步學習。
Knewton自適應學習平臺的基本流程

在自適應學習技術上,Knewton的最大貢獻是結合算法和知識圖譜來規模化地實現以學習目標為導向的連續人工智能自適應推薦引擎。通過細分每個知識點,不斷評估每個學生對材料的掌握程度,對學習路徑和內容進行動態推薦,下面是Knewton采用的一些基本算法和理論出發點:
1) 概率圖模型 Probabilistic Graphical Models (PGMs)
概率圖模型可以分成兩大類,分別是貝葉斯網絡和馬爾可夫網絡。Knewton使用貝葉斯網絡計算相關聯的知識點之間的關聯度,并推導學生在關聯知識點上的掌握度以及置信區間。貝葉斯網絡的應用,也是推薦算法的核心。

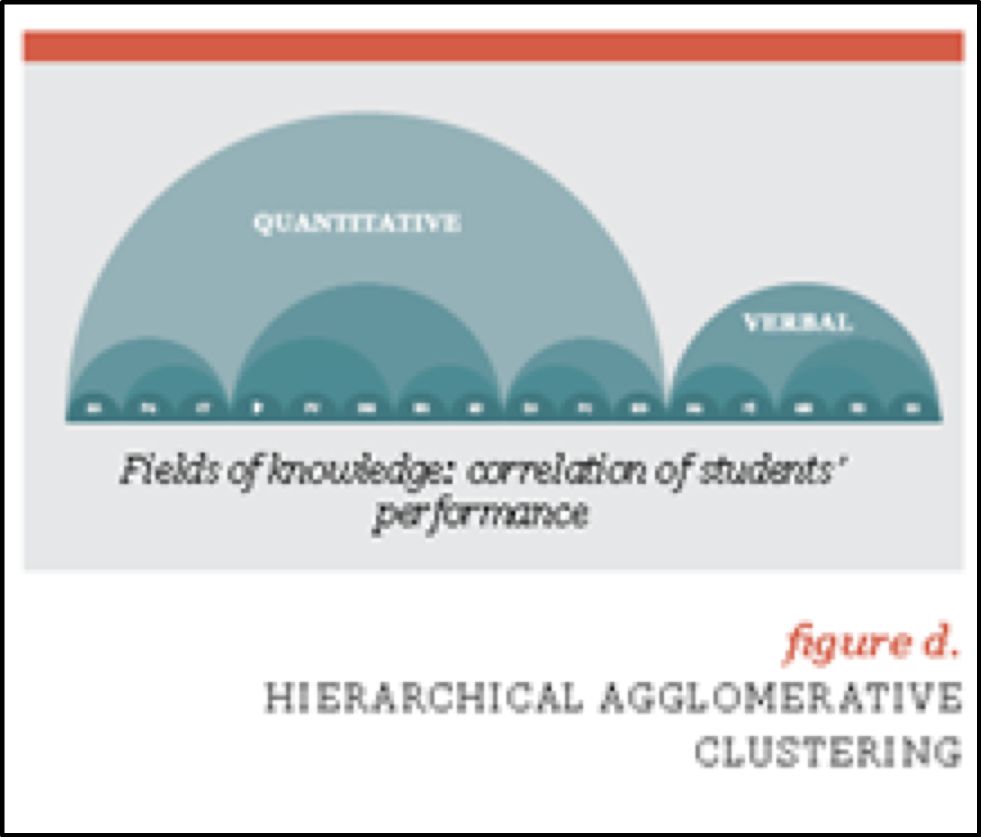
2)層級聚簇分類法 Hierarchical Agglomerative Clustering
Knewton使用機器學習過程中常用的層級聚簇分類法對學生進行實時分組和分類,從而形成適宜其相應程度的學習環境。
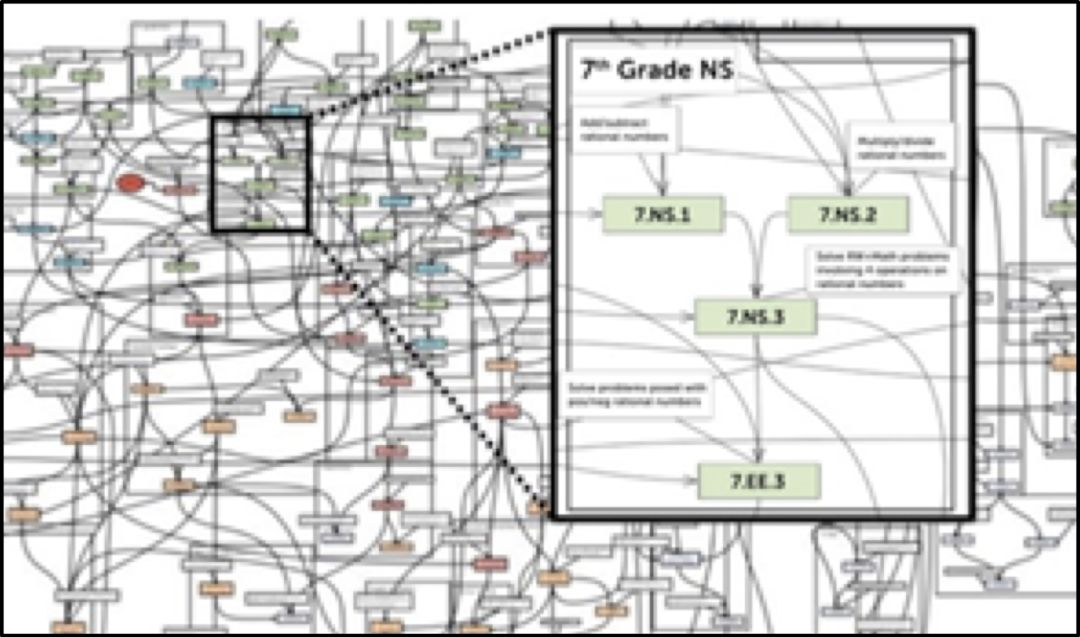
3) 知識圖譜 (Knowledge Graph)
Knewton建立了知識圖譜結構模型,并應用標準化的圖譜體系來建立完整可復制的內容體系(測試內容和教學內容)和系統宏信息(Metadata, Meta Information Model,比如學習目標,知識體系,教材大綱,考綱等)直接的關聯,并以此驅動人工智能產品的方向和軌跡。
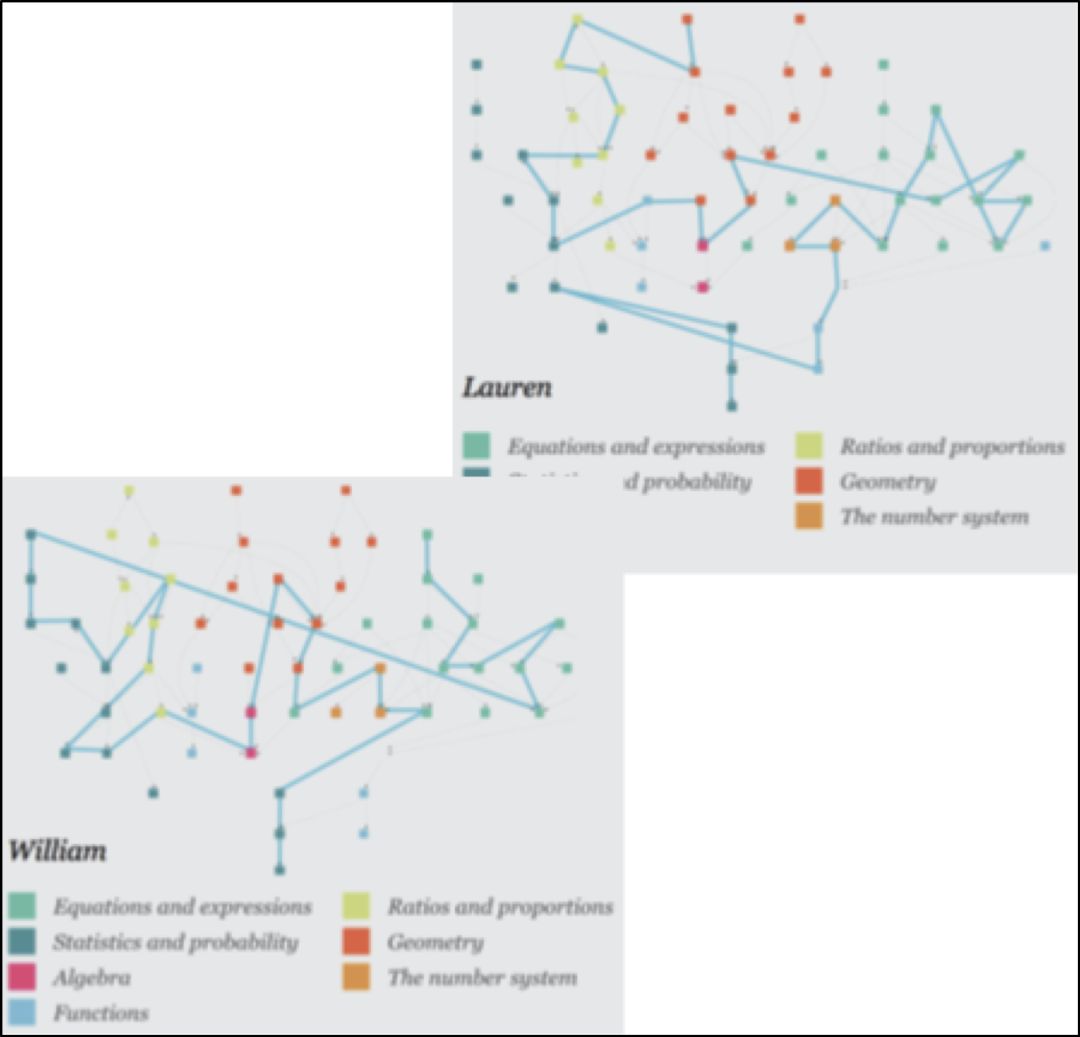
4) 連續型的智適應 ,而非單點自適應(Continuous, as opposed to single-point adaptivity)
Knewton連續型的自適應模型和相應的算法引擎,始終不斷地伴隨學生行為進行實時計算和預測,并隨時推薦內容,活動和調整學習路徑。
5) 間隔重復和間隔加強等針對記憶曲線的應用 (Spaced Repetition, Spaced Reinforcement and Memory Curve)
針對記憶性較強的語言學習類課程,Knewton采用了針對基于記憶曲線和遺忘曲線設計的間隔重復和間隔加強算法,來保證學生的有效深度學習。
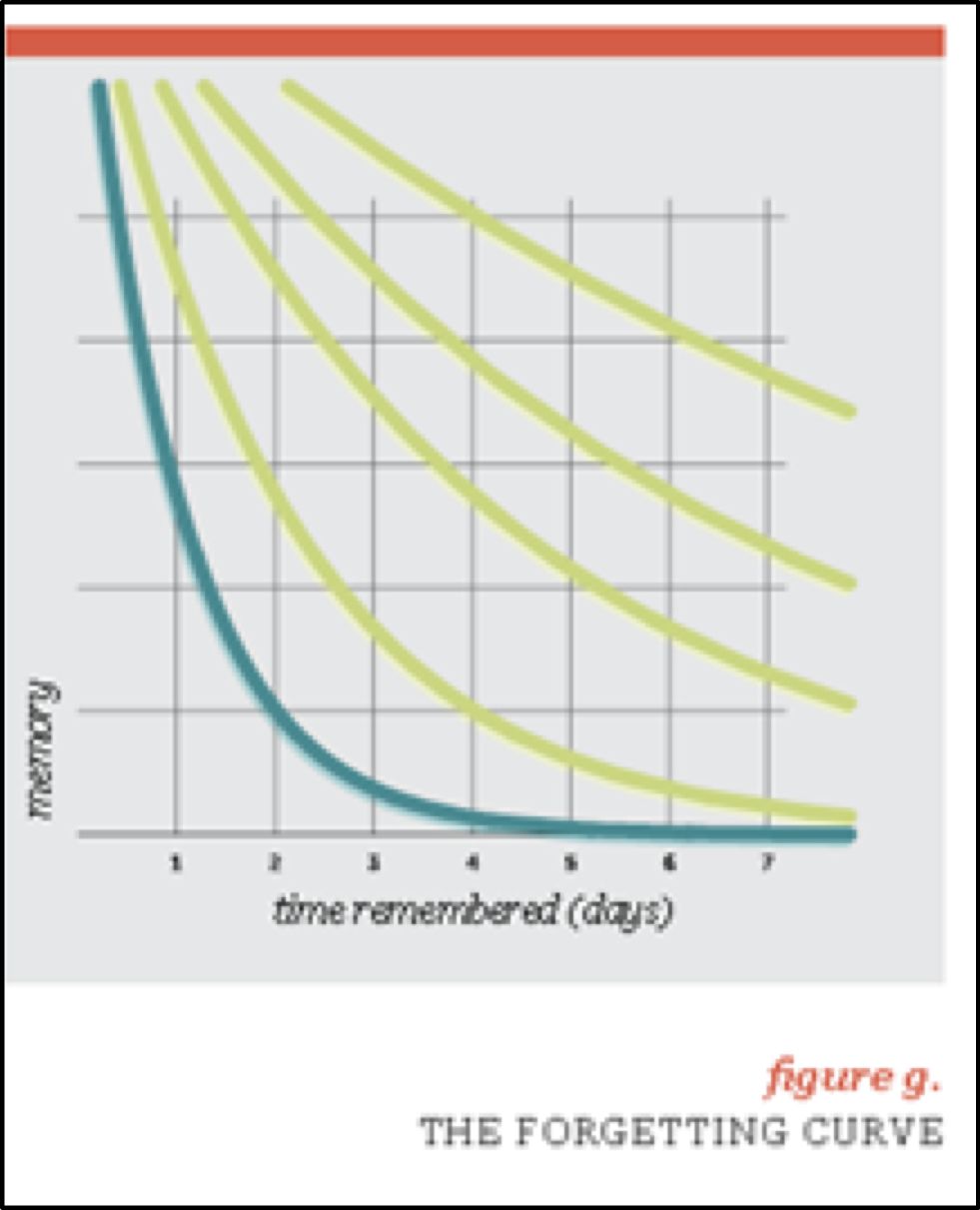
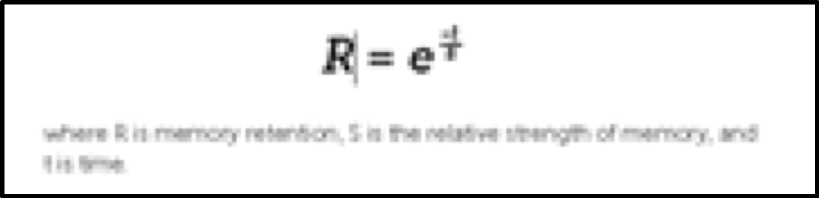
Knewton的強項在于平臺化的算法運營和完善的B2B服務,這使其快速地占有了自適應市場,獲取的大量第一手數據和產品經驗。但這又使其受到合作方的內容和運營模式掣肘,無法充分發揮自適應的潛力。
ALEKS
ALEKS(Assessment and LEarning in Knowledge Spaces)是一個基于人工智能自適應的評估和學習系統,最初由美國加州大學歐文分校于20世紀90年代末的教授、博士生、軟件工程師、數學家和認知科學家組成的團隊開發,獲得來自美國國家科學基金會的數百萬美元的資助。ALEKS基于一種名為“知識空間理論”的算法,該理論最初由紐約大學Jean-Claude Falmagne博士在20世紀80年代開始開發,并一直延續到ALEKS的創建和全面開發。[ 法爾馬涅博士是ALEKS的董事長和創始人。]了解更多:https://en.wikipedia.org/wiki/Knowledge_space
ALEKS的主要學科是數學(從小學算術到大學微積分之間的所有數學課程)和化學,同時還有一些會計和其他各種課程。 在開始ALEKS的課程時,學生通常都要從20到30個問題開始進行適應性初步評估,ALEKS使用這些問題的結果來快速準確地確定學生已經掌握課程中的哪些知識點、未掌握哪些知識點。然后,ALEKS僅指導學生他尚未掌握但已經準備好可以開始學習的知識點。 這些是學生已具備了所有先行知識點,但尚未掌握的知識點。 對于學生而言,其他被認為太難的知識點將被“鎖住”,直到學生掌握了掌握所有先行知識點后再打開。 當學生通過課程學習時,ALEKS會定期重新評估學生,以確保已經學習過的知識點也得以牢固掌握。

圖:ALESK-1
ALEKS最獨特的特點是或許就是它構建了一個精確的知識圖譜,確切地在一個非常精細的知識點級別表明學生到底掌握了什么。學生知識映射的關鍵是每門課程的知識圖譜。 知識圖譜是連接主題的有向圖。 一個典型的ALEKS課程可能由500個這樣的知識點組成,對于這些知識點中的任何一個,系統隨時都會對學生做出(通常是準確的)預測,以了解該知識點是已經被掌握、已經準備好可以開始學習、尚未掌握,還是還沒有準備好開始學習。這種精確的,高分辨率的學生知識映射,(1)使系統能夠提供一個非常強大的自適應學習環境,學生在這里不會浪費時間處理那些太容易(已經掌握)或太困難的知識點( 還沒有準備好學習),以及(2)很多教育工作者非常看重每個學生在課程中知識的精確診斷。
在很多情況下,知識點是由邏輯順序連接的。 例如,“同分母分數加法”知識點是“異分母分數加法”的邏輯先決條件。 但是,知識點也可以通過經驗聯系起來。 例如,“根據圓方程通用式畫圓”和“同分母分數加法”這兩個知識點在邏輯上并不相關,但實際上,我們可以99%確定知道根據圓方程通用式畫圓知識點的學生也知道同分母分數加法知識點,相反,如果學生不知道同分母分數加法知識點,我們可以99%確定他也不知道圖形知識點。 所以同分母分數加法知識點可能是圖形界知識點的經驗先決條件。為了建立每門課程的知識圖譜,除了內容專家的專業知識之外,ALEKS還使用學生數據,找到所有應該包含的強連接,同時避免弱連接,因為這可能會導致錯誤的推論。
一個知識圖譜代表一個學科主題的知識體系,不同的學生對知識掌握程度不同,對應的知識狀態也不一樣。一個知識點數量較少的簡單知識圖譜可以較快窮盡所有可能的知識狀態,如圖ALEKS-1所示為含有五個知識點的圖譜窮盡出來的所有可能的知識狀態。但是含有數百個知識點的復雜知識圖譜是很難以窮盡所有可能的知識狀態,圖ALEKS-2很形象的形容了含有45個知識點的圖譜窮盡知識狀態的復雜性。圖中不同顏色代表不同的知識點,圖中每一個點代表一個知識狀態。
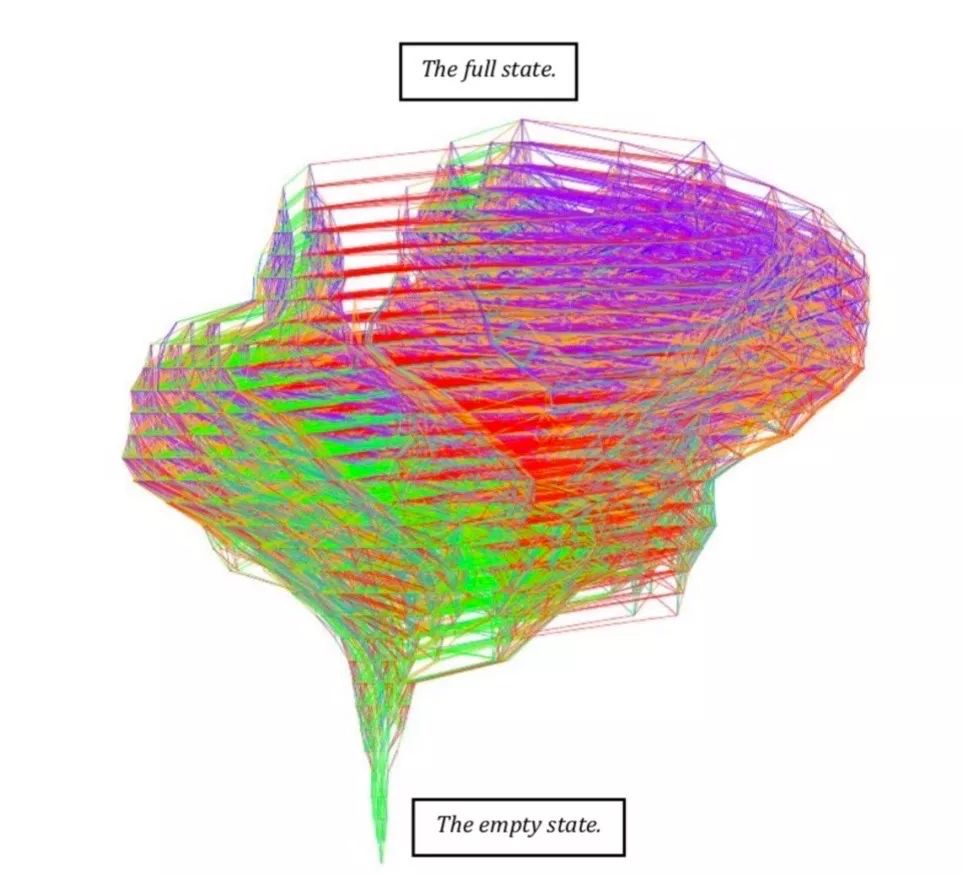
圖:ALEKS-2
ALEKS AI的優勢在于僅采用20至30個問題就能有效地確定學生對300至500個知識點的掌握情況。 需要指出的是,知識圖譜中的知識點前后置關系越多,評估就越有效率。 因此,在過去的5到10年中,該模型得到了擴展和改進,以包含其他更復雜的鏈接,這些鏈接進一步減少了知識狀態,幾乎不犧牲評估準確性。 我們不會在這里討論這個更復雜的系統,但會注意到這些鏈接涉及與先決條件相關的“或”關系:意思是知識點Z可以具有X或Y兩個先行知識點,這意味著XZ,YZ ,以及XYZ都是包括Z的有效狀態,但是Z單獨不是有效狀態,因為掌握Z之前學生必須掌握X或Y。圖ALEKS-3描述了評測過程中,ALEKS-AI系統對學生知識狀態的更新和調整。
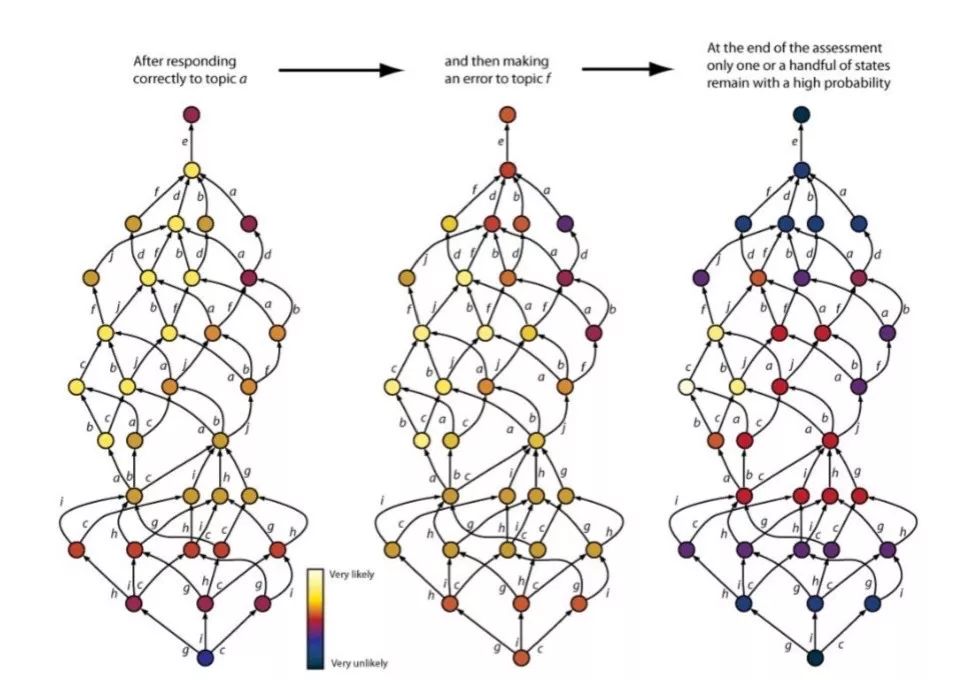
圖ALEKS-3
知識圖譜控制了大部分學生的學習。 雖然學生通常會得到多個可以進行下一步學習的知識點的選擇,但許多知識點也被分為已掌握的(在這種情況下,學生在該知識點上努力是浪費時間)或者未掌握,未準備好可以學習的(在這種情況下,由于學生沒有掌握學習的先決條件知識,所以學習這個知識點是浪費時間)。 通過這種方式,ALEKS為學生提供了一個強大的適應性學習環境,涵蓋了學生學習的“甜蜜點”(既不困難也不太容易)的知識點。一般來說,當ALEKS為學生提供一個新的知識點時,他們平均成功率達到95%。
ALEKS的另一個將其與其他學習系統區分開來重要特征是,它再每個知識點上面的題目設計方式,以及當學生在學習某一個知識點的時候如何為學生推題。 現在,當學生在ALEKS中學習一個知識點時,他們通常會連續做多個該知識點的題目,努力作答他們認為自己知道該怎么做的題目,并在他們不知道該怎么做時點擊“Explanation”。 如果他們能夠表明他們大部分時間都能正確回答而不需要“Explanation”,那么ALEKS將會“過關”這些題目,從而有效地確定學生已經充分掌握了該知識點,至少現在“已經掌握”(直到后來的評估與此相矛盾)。一般來說,一個ALEKS的知識點包含數百甚至數千或數百萬個算法生成的題目,對于任何特定的知識點,在問題之間的太多變化和太少之間存在微妙的平衡。 變化太小會導致學生表面的“教科書”式學習,而這種學習方式長時間不能很好地保持,但是太多的變化可能會給知識結構和人工智能造成嚴重的問題,同時也可能導致想要 以特定順序教授課題。 因此,ALEKS內容人員花費了大量的時間和精力來成功地平衡這些因素。
RealizeIT
Realizeit是由CCKF公司開發的人工智能自適應學習產品,旨在幫助每一個學生實現自己的學習目標,為每個學習者提供新一代的學習體驗,既能適應個人學習風格,又能使學習者自身能力得到提升。Realizeit不僅是一個個性化學習平臺,還是一個包含智能學習引擎的一體化系統,能夠通過任何相關的內容占據任何目標知識空間,并為每個學生提供自適應學習體驗,幫助每個學習者實現真正的個性化學習。
Realizeit模擬了教師一對一教學過程。Realizeit將內容和課程分離,課程代表了一類相關的概念,用于指引學習方向,課程內容能夠將知識傳達給個人。正如每個教師可以同多種方式傳達相同的概念,Realizeit可將多種內容匹配到課程中的每個概念,實現將多種內容匹配到課程,從而模擬教師平衡課程、內容、個人之間的相互關系的過程和方法,確保學習的有效性和高效性。
Realizeit的課程通過知識先決網絡這種多維結構補充了知識和概念的層級表示法,這是一種有向無環圖,通過知識先決網絡促進在Realizeit系統中的學習,捕獲學習者的整個畫面,給學生量身定制自己的學習方式。
Realizeit的內容是不可知的,它適用于任何學習領域,并提供任何形式的學習內容。它為每個單獨的知識項提供豐富的學習內容庫,在學生的學習過程中生成內容要素,并將其反饋給學生。每一項內容都是根據學生個人的認知特性和學習風格特別定制的。Realizeit提供基礎結構,讓內容具有關聯性和適應性,將自適應智能引擎用于每個單獨的學生,通過智能引擎并將內容個性化。
Realizeit以自適應智能引擎為基礎模擬教師一對一教學過程。Realizeit首次實現了學習者個人技能的判斷方法,在學生學習的每一個步驟中,根據學生的學習成果和模式為其提供最佳課程指導,實現了為每一位學習者選擇最佳學習路徑,保證最有效的學習。最后以自適應學習引擎為基礎觀察并適應每個學生的可變技能、行為和學習偏好,利用自身的精確性和高性能確保每個學生能夠接受最全面的個性化學習體驗,從本質上模仿一對一的教師-學生學習情境。

另外,RealizeIt的智能自適應引擎具備兩個重要特征。第一:當新的用戶、課程或內容添加到Realizeit中時,智能引擎能夠在未提供數據的情況下做出智能決策。第二:智能引擎能夠根據采集的學生數據提升自身的準確性、效能和效率。
學生畫像的維度包括以下幾個方面:
學習者的自信程度/自我評估
完成自適應課程練習的時間
回答學習問題時的表現
學習方式偏好
對先前的學習目標的掌握
具有相似學習檔案的學生過去的表現
距上次接觸相關內容的時間
個人學習模塊中取得的成效

4. Realizeit收集關鍵數據點,采用學習分析法將商業智能方法和策略用于教師和教育機構的分析,不僅可以幫助教師進行學習者分析和評估學生,利用學習者(作為評估結果)和新型算法、工具之間的聯系,確保迅速獲取學生能力和學習過程的整體概況,以便隨時可用,實現教學定制化;還可以幫助教育機構收集不同層級的課程、學校、部門和機構數據,從而提供實時的學習狀態瀏覽以及各層級的信息,從而引導其作出正確的決策。
Realizeit實現了教學課程定制化
教師可添加其他課程軟件中的內容或問題
教師可設置或修改課程軟件中分級的范圍或分數
教師可設置課程軟件的“門檻”
教師可將不同的任務分配給每個學生
教師可選擇能力目標和學習目標、添加特定的提問模板、設計學生評估流程、導入學習材料、創建規則等

研究結果表明:使用Realizeit系統學習的學生總體表現優于使用傳統方法和在校教學模式的學生表現。總體而言,使用Realizeit的學生對這個系統都相當滿意。83.7%的學生認為還會再次使用Realizeit系統,82.8%認為與其他教學模式下的課程相比,Realizeit使得他們能夠更好地學習課程材料。與其他學習群組相比,使用Realizeit學習系統的學生對教學方法的滿意度更高。
調查中其他問題的結果也解釋了為何得出這么高的百分比。89.4%的學生認為Realizeit使用方便,并且能提供清晰、有用的反饋和指導;91.2%的學生認為Realizeit的教學方法清晰明了;86.9%的學生認為Realizeit系統提供的反饋對其后續的學習有幫助。Realizeit便于使用,并且提供了有用的、清晰的反饋和指導。89.4%的學生認為Realizeit學習系統便于使用,而91.2%的學生認為Realizeit的教學方法明確。
學生信任Realizeit:77.7%的學生認為Realizeit給出的成績評估方法有效,80.9%的學生認為Realizeit能準確衡量他們的水平。73.5%的學生認為隨著時間的推移,Realizeit能提供個人定制的學習。80.9%的學生認為Realizeit提高了他們的參與度。
乂學的探索和優勢
乂學松鼠AI智適應學習系統,兼各家所長,采用多種AI技術,通過學生的自身特點與合適的內容設置,平衡教學和評估在特定的時間內的組合,解決用智能手段優化學生的學習方法。乂學松鼠AI智適應系統框架采用的人工智能技術,在學習過程中的不同環節被使用。
例如,乂學可以比較學生的詳細學習歷史,收集并分析龐大的數據,改善學習領域的檢測,診斷和熟練程度的測量。最重要的,核心的自適應學習技術之處在于結合了多種模型來提供給學生和教師不斷個性化的建議,以直接幫助學生更好地學習和更快的自適應模型。對于單個老師,分析學生如此龐大的數據量往往是一個困難和耗時的過程,但對于自適應AI,特別是隨著現代技術,如GPU加速的深度學習的幫助,這樣的過程可以自動進行,結果可以返回更快,更準確。
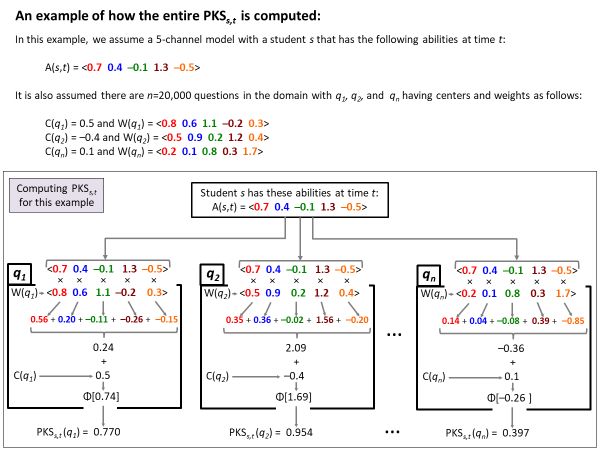
在乂學的模型中,采用了針對學生學習能力和對測試內容進行的向量擬合,再用不斷更新的實時向量估值來預測學生在什么時候回答對問題,我們把這個預測值簡稱為學生的知識狀態PKS。

比如說有兩個學生,兩個學生的PKS在下面狀態。學生1的PKS狀態在回答問題1的正確概率是0.29,回答問題4的正確概率是0.74;學生2在某一個時間回答第一個問題的正確概率是PKS=0.53,到回答第四個問題時PKS是0.35。
在這個動態過程中,不同學生的PKS是不同的,通過對PKS的評估可以分析出學生掌握知識的狀況。在任何時間點時,算出PKS值,就可以了解到他們的學習狀態。這是模型當中采用是連續估計值,學生對某一個問題掌握程度是是用概率來估計他掌握知識的程度。學生的PKS可以完全反映他對于知識的掌握程度。
我們的假設是學生的能力和題目需要的能力,可以用知識軌道的系數來表達,能力有可能是10個知識軌,也有可能是20個知識軌。舉例說我們用5個知識軌,根據模型,可以了解在任何時候學生回答問題有三個因素決定了PKS,一個是學生在各知識軌道的能力,二個是問題的權重,第三個是問題的中心概率值,我們采用PKS的CDF函數來了解一個學生回答一個問題概率準確度,用一個等式來決定概率準確率。
這個PKS在我們的實驗數據中得到預測效果是非常好的,76個學生相關的結果,一共1500個題的作答結果我們采用相關的參數來預測的PKS,通過數據分組,把我們排好序的PKS進行分組校驗。

通過上面的預測對比實際數據來看,預測值和實際結果是非常接近的,也就是說,我們的模型的預測效果是相當準確的,在右邊藍點圖當中也可以直觀地看出來相當高的實驗擬合度。
這個模型在實際使用上,可以看出PKS可以直接應用于智適應學習的測試和推薦場景,在PKS有相當的準確度和清晰度的情況下,可以知道哪些課程的哪些內容適合于學生的個性化學習:

在這里,可以看到藍色代表是太容易的,綠色代表最優化的,紅色代表太難的。通過這種方法就可以了解到,對于A學生來說這個時間點內他的內容應該怎么樣去選擇。通過藍色、紅色的圖表顯示現在的情況,這一堂課的分布情況。比如說在這里A、B、C三門課,它的平均值是0.68、0.67、0.63,這一堂課有些問題是難的,比如說這里有0.52、0.46,有些問題對于這些學生太容易了,比如說0.87。可以看到,C課程總體太難了,PKS平均值是0.43,大部分問題對于這個學生來說是沒有辦法回答的。不僅在題目和內容的選擇上,在學習路徑的搭配和智適應推薦的原理上,這個模型也能夠直接和我們現有的模型對接和共同使用。
乂學的數據和內容一樣,都無法單獨模仿,不僅如此,用于人工智能的教育數據的一個顯著特征是,教育數據不僅有傳統意義上的數量和質量要求,而且其關聯性、維度性、時效性、場景性都極為重要。因此,由此所積累的多維度相關聯的數據,采用的場景記錄,以及選用算法的相應參數和調優及反饋過程,都會是競爭對手很難直接復制的,這給了具有模式先發優勢的公司制造了屏蔽性壁壘的機會。
在智適應學習領域里,乂學不僅借鑒國際先進的理論和實踐,而且在最新研究的基礎上,研發了多知識軌道學習模型的預測算法。這涉及到使用對多維度知識向量的邏輯回歸,使用MLE卷積算法進行模型擬合,與現有的算法相結合,能提高測評效率和預測的顆粒和精準度,并在多維度知識點拆分后,形成以前無法做到的快速反饋。
國內外智適應學習產品和市場的比較
中國和美國、歐洲在智適應教育的發展歷程不盡相同,這有其技術方面的原因,更多的是受教育產業國情的影響,不同的足跡和環境也造就了中國的人工智能自適應學習產品的自身特色和服務模式。中國K12教培市場更加廣闊,學生基數大,學生家庭的參與度高,付費習慣要比歐美強得多。
專家們都更看好中國智適應行業的前景,尤其是乂學這種自主研發核心算法、自主定制專為算法引擎配套的教學內容、同時自主招生提供終端教育服務的全球獨有的三位一體模式,能最大地發揮人工智能自適應的優越性實現革命性的突破,這也是三位智適應技術專家崔煒,Richard Tong和Dan Bindman 愿意加入乂學的根本原因。
根據最新的Research&Markerts《全球自適應學習軟件市場報告(2017-2021年)》,自適應學習軟件復合年增長率為31.07%。軟件市場逐年穩定增長,作為自適應學習平臺提供商,自適應學習公司將內容供應商所提供的內容與其獨特的技術和個性化服務對接,這塊領域尚是一片藍海。
《2017-2018中國互聯網教育發展趨勢報告》顯示,70后和80后是互聯網教育付費的主力軍,這兩個代際的人群,處于中國最具消費力的中產階層,由于受教育程度高,并有國際化視野,因此,對自我職業成長和對于孩子的教育都產生了集體性焦慮,由此催生了早教產品、K12在線課程以及職業教育的龐大需求。
這樣的需求也反映在了提供相關教育產品的公司的融資情況上面。目前,在中國的自適應學習公司融資事件中,K12和語言學習兩個細分領域最多,占比分別達到52.2%和34.8%。其中,K12是中國教育培訓行業中市場規模最大的一個子領域。
根據艾瑞咨詢發布的《2017年中國B2B2C在線教育平臺行業研究報告》,2017年中國在線教育市場規模預計達1941.2億元人民幣,同比增長22.9%。未來幾年,中國在線教育的市場規模增長勢頭保持穩健,預計在2019年市場規模將達到2727.1億元。
AI+教育的前景不僅能徹底改變輔導教育,顛覆6800億的K-12校外輔導市場,還有可能徹底改變教育產業的格局,無論是教授應試能力,還是教授素質培養,其AI主導的個性化的模式,都會是更可靠、更便宜、更有效率的。
我們已經站在了AI+教育應用的爆發前夜,中國的智適應學習創業市場巨大,已經至少有40家公司存在,未來不排除還有更多人入局。不可否認的是,盡管行業融資火熱,但從行業發展階段來看,目前人工智能自適應教育行業仍處在發展早期,誰能擁有可持續的核心產品研發競爭力,誰先占領市場贏得用戶,誰能得到充分的資金支持誰就能在未來競爭中贏得先機。
6月20日,乂學人工智能教育將在北京舉辦“松鼠AI”品牌暨產品發布會,屆時將會有國內外一系列專家、學者、教授為大眾揭曉人工智能自適應教育的巨大優勢,國內知名教育專家俞敏洪、松鼠AI代言人“首席好家長”吳秀波、乂學教育及松鼠AI品牌創始人栗浩洋、斯坦福研究中心教授、中科院教授、及頂級風投大佬都將親臨現場。
-
機器人
+關注
關注
210文章
28205瀏覽量
206532 -
人工智能
+關注
關注
1791文章
46859瀏覽量
237579
原文標題:蓋茨、扎克伯格都看好的AI智適應教育,松鼠AI聚攏頂尖技術專家
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論