 讓機器人通過觀察人類的操作來學會操作新的物體
讓機器人通過觀察人類的操作來學會操作新的物體
模仿能力是智能重要的組成部分,人和動物常常通過觀察其他個體來學習新的技能。那么我們能不能將這種能力賦予機器人呢?是否可以像下圖一樣,讓機器人通過觀察人類的操作來學會操作新的物體呢?
機器人在觀察人類行為后學會了將桃子放到了紅色的碗里
如果擁有這樣的能力,將極大地簡化部署機器人完成新任務的過程。我們只需要展示給機器人需要進行的任務,而無須進行遙操作或設計復雜的獎勵函數。很多工作探索了機器人可以從本身的專業經驗中很好的學習,這樣的學習方式稱為模仿學習。
然而基于視覺技能的模仿學習需要大量專業的示范數據。例如利用原始像素輸入來靠近單一固定物體的任務就需要200次表現良好的示范才能達到。如果只提供一個示范樣本,要完成這樣的模仿對于機器人來說十分困難。
除此之外,如果機器人需要模仿人類的示范的特定操作技能還需要面臨額外的挑戰。除了機械臂與人類手臂的構造差異外,在人類示范和機器人示范之間建立起正確的對應關系是一件十分困難的事情。這并不僅僅是對運動簡單的跟蹤和重映射,其中最主要的部分在于運動對環境中物體的影響,并且我們需要建立一個以這種相互作用為中心的對應關系。
為了使得機器人可以模仿視頻中人類的技能,可以結合一系列先驗經驗而不是從零開始學習。通過結合先前的經驗,機器人可以迅速學會對于新物體的操作而在域的移動中保持不變性,就像在觀察了人類的示范后機器人可以在不同背景和視角下學會操縱物體。研究人員的目標是通過從示范數據中學會學習,來實現少樣本的模仿和域不變性。這種被稱為元學習的技術是賦予機器人通過觀察模仿人類的關鍵。
One-Shot模仿學習
那么如何利用元學習來幫助機器人快速的適應不同的物體呢?研究人員們采用結合元學習和模仿學習的方式來實現一次模仿學習。關鍵的想法在于給機器人提供某一特定任務的當個示范,機器人就能迅速的識別任務,并在不同的情形下成功解決。早先的一個工作通過從成千上萬個示范中學會學習來實現一次學習,并給出了優秀的結果。如果我們希望一個實際的機器人能夠模仿人類并操縱各種各樣的新物體,就需要開發一個能從視頻數據集的示范中學會學習的系統,而這些數據可以在真實環境中收集。接下來的部分首先討論了通過遙操作收集的單個示范來實現的視覺模仿,隨后展示了這種方法是如何拓展到向人類視頻中學習的范疇中去的。
One-Shot視覺模仿學習
為了讓機器人可以從視頻中學習,研究人員將模仿學習與一種高效的元學習算法(未知模型元學習,MAML)結合起來。通過標準的神經網絡來作為策略表示,在每個時間步長將機器人輸入的圖像ot和狀態信息xt(例如關節的角度和速度)映射到了機器人的行動上at(比如夾爪的線速度和角速度)。下圖展示了算法三個主要的步驟。
首先人們對于不同任務(操作不同物體)收集了大量操作示范構建了大型數據集;隨后利用MAML學習了策略參數θ的初始狀態。隨后提供某一特定物體的示范時,我們可以基于這一示范來運行梯度下降法來尋找對于這一物體的一般化策略θ’。當使用遙操作示范時,策略可以通過比較預測行動πθ(ot)和專家行為a*t來更新策略:

隨后通過促使策略πθ’的值來匹配同一物體其他示例的行為,實現對于參數θ的更新。在元訓練后,我們就可以利用這一任務的單一示范來計算梯度步驟,從而讓機器人去操縱完全沒有見過的物體了。這一步驟稱為元測試。
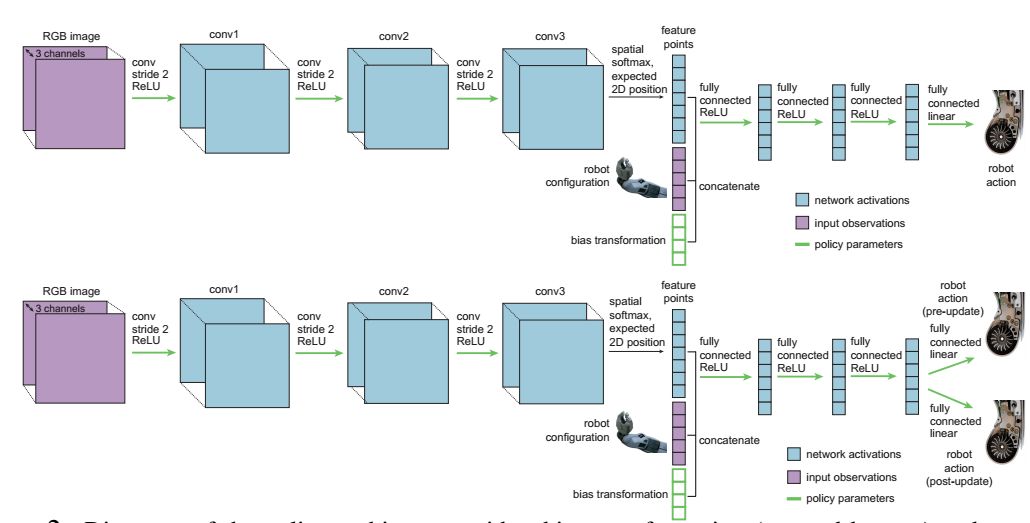
策略架構
由于這一方法沒有為元學習和優化引入額外的參數,具有很好的數據效率。因此它可以通過觀察遙操作機器人示例實現多樣化的控制任務,例如推動和放置等任務。
將物體放到新的容器中去,左圖是示范右圖是學習后的策略。
通過域適應性元學習,機器人觀察人類實現一次模仿
上述方法依然是依賴于遙操作機器人的示范而不是人類的示范。為了達到從人類示范學習的目標,研究人員們在上述算法的基礎上設計了一種域適應的一次模仿方法。收集了機器人和人執行不同任務的示范,隨后通過人類示范來計算策略更新,并用同一任務的機器人示范來評價更新后的策略,算法架構圖如下所示:
但人類示范只是在執行任務時的視頻而已,并不包含對應的行為,無法通過前面的公式計算出損失并更新策略。在這里,研究人員另辟蹊徑的提出了用深度學習的方法學習出一個幫助策略更新的損失函數,這個損失函數無需行動作為標記。直接學習損失函數背后的思想來自于,我們可以通過無標簽的數據得到損失函數,同時給出正確的梯度用于策略更新,并最終的到一個成功的策略。
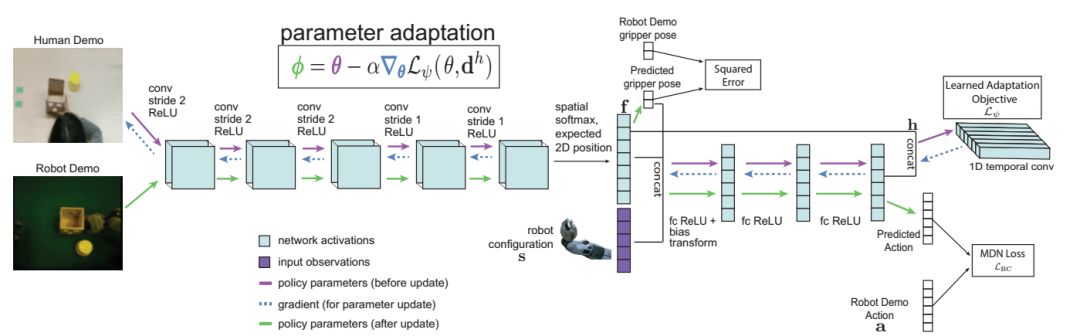
策略架構
這看起來像是不可能完成的任務,但要記住的是元訓練過程依舊通過梯度步驟后機器人行為監督著策略的更新。學習損失函數可以被理解為通過抽取場景中適宜的視覺線索來更新參數從而修正策略。所以元訓練的行為輸出將會產生正確的行動。研究人員利用Temporal卷積來實現了損失函數的學習,可以抽取視頻示范中的順時信息。
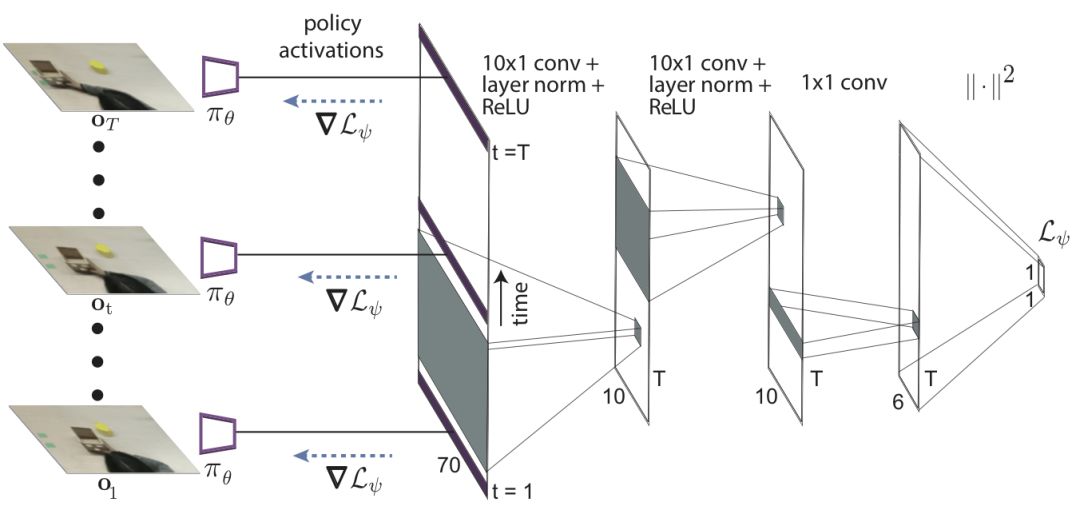
研究人員將這一方法歸為具有域適應性的元學習算法,這是因為它可以通過其他域的數據實現學習,而不是機器人的策略操縱空間。這一方法使得PR2機器人高效的學會了如何推動很多不同的物體到目標位置,而這些物體在元訓練的過程中是從來沒有看到過的。
同時也能通過觀察人類對于每個物體的操縱,實現物體的抓取并將其放置到新的目標容器中去:
同時利用不同背景環境和相機拍攝的人類示范來驗證算法的有效性, 發現即使相機和背景的變化,算法依舊可以保持良好的表現。
未來工作
目前已經實現了教會機器人通過觀看單個視頻就能學習操縱新物體,下一步自然是擴大這種方法的規模,不同的任務對應著完全不同的運動和目標,例如使用不同的工具來進行不同的運動。通過考慮潛在任務分布的多樣性,研究人員希望這樣的模型可以適用于更廣泛的任務,幫助機器人在新環境中迅速的建立起策略。同時這里提到的技術并不僅僅限于機器人操縱或控制,模仿學習和元學習可以用于語言和其他序列化決策過程中。通過少數的示例學會模仿是一個未來一個十分有趣的研究方向。
-
機器人
+關注
關注
210文章
28231瀏覽量
206615 -
神經網絡
+關注
關注
42文章
4765瀏覽量
100566
原文標題:看視頻就能學會新技能,伯克利的機器人如何學會模仿人類?
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
不寒而栗:機器人只需看看 就能模仿人類
扭矩傳感器實現機器人敏捷操作
代替人類完成危險性較大實驗的雙臂機器人——Mahoro
會物體識別和語音識別的nao機器人
我與我的機器人
機器人將取代人類,你覺得吶?
人工智能機器人大戰即將開啟,機器人世界主導,機器人是否能賦予如人類一般的情感。
人類與人工智能機器人合作的前景
桁架機器人操作注意守則
如何打造出與人類自然交流的機器人?
桁架機器人的概念與特點都有哪些?
讓機器人通過一段只有一個人的視頻來模仿學習






 工商網監
工商網監
評論