") 知存科技致力于開發(fā)的基于NOR Flash的存算一體化人工智能芯片
知存科技致力于開發(fā)的基于NOR Flash的存算一體化人工智能芯片
知存科技致力于開發(fā)的基于NOR Flash的存算一體化人工智能芯片,其芯片特點是能耗低、運算效率高、速度快和成本低,適用于終端設(shè)備的人工智能應(yīng)用。
知存科技演講實錄
知存科技是一家剛剛成立半年的公司,今年3月份正式運營,專注于開發(fā)低功耗低成本的存算一體AI芯片。
人工智能目前還處于發(fā)展階段,當前的落地的應(yīng)用場景較少,沒有達到社會的期望。隨著人工智能算法的進步以及芯片算力的提升,未來人工智能將會出現(xiàn)一個更大的爆發(fā)點,會涌現(xiàn)更多的應(yīng)用落地。
人工智能芯片作為人工智能的載體,被大家寄予厚望,在2020年,人工智能芯片市場預(yù)計達到千億量級。傳統(tǒng)芯片巨頭比如arm、Intel、NVIDIA都通過自研和收購?fù)瞥隽藬?shù)款芯片,互聯(lián)網(wǎng)巨頭比如Google、亞馬遜和微軟等也都正推出和開發(fā)的人工智能芯片。這個領(lǐng)域的創(chuàng)業(yè)公司就更多了,中國的幾家頭部公司就做得非常好。
人工智能依賴的算法有幾大特點:這是一個很龐大和復(fù)雜的網(wǎng)絡(luò),有很多參數(shù)要存儲,也需要完成大量的計算,這些計算當中又會產(chǎn)生大量數(shù)據(jù)。為了完成大量計算的過程當中,一般芯片的設(shè)計思路是將大量增加并行的運算單元,比如上千個卷積單元,需要調(diào)用的存儲資源也在增大,然而存儲資源一直是有限的。隨著運算單元的增加,每個運算單元能夠使用的存儲器的帶寬和大小在逐漸減小,存儲器是人工智能芯片的瓶頸。
在很多人工智能推理運算中,90%以上的運算資源都消耗在數(shù)據(jù)搬運的過程。芯片內(nèi)部到外部的帶寬以及片上緩存空間限制了運算的效率。現(xiàn)在工業(yè)界和學(xué)術(shù)界很多人都認為存算一體化是未來的趨勢。
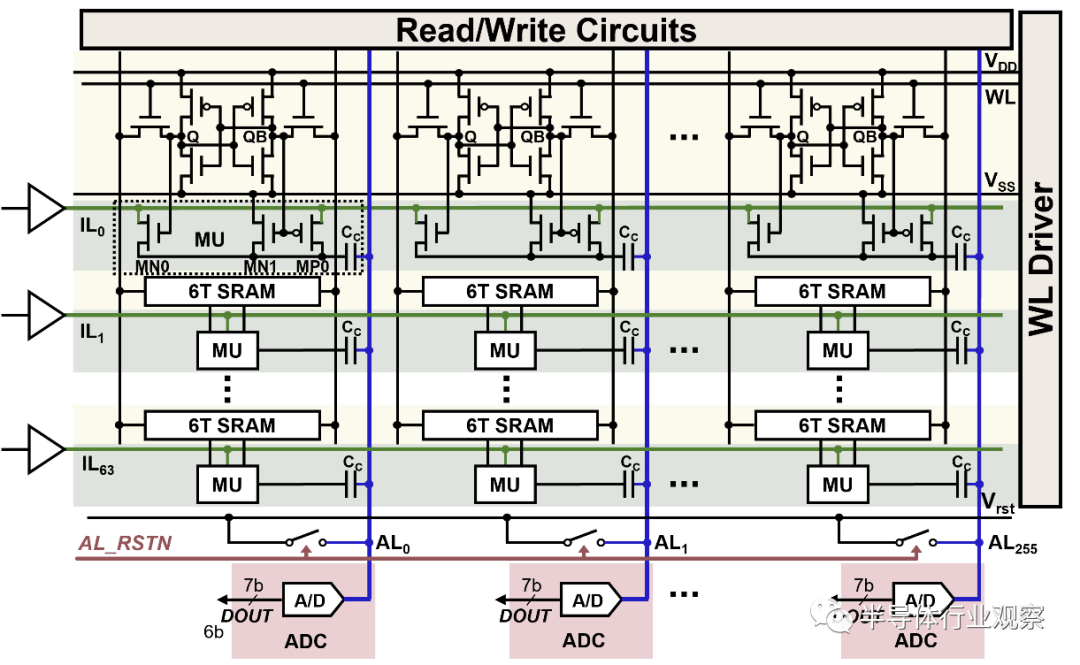
存算一體化分為幾種:DRAM和SSD中植入計算芯片或者邏輯計算單元,可以被叫做存內(nèi)處理或者近數(shù)據(jù)計算,這種方式非常適合云端的大數(shù)據(jù)和神經(jīng)網(wǎng)絡(luò)訓(xùn)練等應(yīng)用;另一種就是存儲和計算完全結(jié)合在一起,使用存儲的器件單元直接完成計算,比較適合神經(jīng)網(wǎng)絡(luò)推理類應(yīng)用。我們研發(fā)的是后者這樣的技術(shù),將存儲和計算結(jié)合到閃存單元中的存算一體。閃存技術(shù)已經(jīng)非常成熟,商用幾十年了,成本很低。
當前商用的神經(jīng)網(wǎng)絡(luò)非常龐大,擁有幾百萬到幾千萬的權(quán)重參數(shù),或者推理過程中需要完成幾百萬到上千萬個乘加法運算。傳統(tǒng)的計算系統(tǒng)需要將網(wǎng)絡(luò)權(quán)重參數(shù)存在片外的非易失性存儲器中,比如NAND Flash或者NOR Flash。運算的過程中,需要把部分需要的權(quán)重參數(shù)搬運到DRAM,再把小部分參數(shù)傳入到芯片中的SRAM和eDRAM中,之后導(dǎo)入寄存器和運算單元完成運算。神經(jīng)網(wǎng)絡(luò)運算需要大面積SRAM和eDRAM來減少片內(nèi)外數(shù)據(jù)搬運和提高運算效率,但是由于片上存儲成本的限制,也需要高成本高速度的DRAM來緩存片上無法容納的權(quán)重參數(shù)和臨時數(shù)據(jù)。
我們存算一體化的做法是這樣的:我們的Flash存儲單元本身就可以存儲神經(jīng)網(wǎng)絡(luò)的權(quán)重參數(shù),同時又可以完成和此權(quán)重相關(guān)的乘加法運算,就是將乘加法運算和存儲全部融合到一個Flash單元里面。舉個例子,只需要100萬個Flash單元,就可以存儲100萬個權(quán)重參數(shù)同時并行完成100萬次乘加法運算。我們做的是這樣一款芯片,深度學(xué)習(xí)網(wǎng)絡(luò)被映射到多個Flash陣列,這些Flash陣列不僅存儲和深度學(xué)習(xí)網(wǎng)絡(luò)同時完成網(wǎng)絡(luò)的推理,這個過程不需要邏輯計算電路。這種方式的運算效率非常高,成本很低,單個Flash單元能夠完成7、8 bit的乘加法運算。
之前我們說我們芯片有兩個特點:一個是運算效率高,相比于現(xiàn)在基于馮諾依曼架構(gòu)的深度學(xué)習(xí)芯片,大概能夠提高運算效率10-50倍;另一個是產(chǎn)品成本低,節(jié)省了DRAM、SRAM、片上并行計算單元的面積消耗,簡化了系統(tǒng)的設(shè)計,同時無需采用先進的芯片加工工藝,可以數(shù)倍地降低生產(chǎn)成本,幾十倍地降低流片和研發(fā)成本。當前階段,我們尋找的是對成本和運算效率(功耗)敏感的應(yīng)用,比如終端的低功耗低成本的語音識別應(yīng)用。未來,隨著人工智能和物聯(lián)網(wǎng)的發(fā)展,我們會拓展更多的應(yīng)用場景,比如說低成本和低功耗的感知應(yīng)用和人機交互。
2014年,我們開始在加州大學(xué)圣芭芭拉分校的實驗室做這項技術(shù)的研發(fā),完成過6次流片和技術(shù)驗證。去年年末在北京注冊的公司,今年3月份正式開始運營,僅僅5個月的時間我們就把設(shè)計送出去流片,順利的話,過3-4個月就會完成芯片測試,爭取明年量產(chǎn)。我們的團隊畢業(yè)于北京大學(xué)、北京航空航天大學(xué)、美國加州大學(xué)洛杉磯分校,加州大學(xué)圣芭芭拉分校等學(xué)校。核心團隊成員大部分都有十年以上的行業(yè)經(jīng)驗,團隊目前有11個人,年末也會擴大團隊規(guī)模。
乘法計算的方式是通過類似模擬電路的電流鏡方式。輸入電流轉(zhuǎn)換成電壓耦合到Flash晶體管的控制柵上,F(xiàn)lash晶體管的輸出電流等于輸入電流和存儲的權(quán)重相乘。加法的計算方式類似于并聯(lián)電路電流求和。
怎么看待Intel新的X Point技術(shù)?
這是一項很新的技術(shù),目前主要問題是成本和系統(tǒng)支持度的問題,但隨著產(chǎn)業(yè)鏈的發(fā)展,成本會越來越低,速度也會更快,系統(tǒng)也會更好的支持X-Point兼有的高速和非易失性的特性。這項技術(shù)的selector做得很好。作為存儲器、內(nèi)存或者他們的統(tǒng)一體這類應(yīng)用來說,未來成本降低之后,會有非常大的優(yōu)勢。Intel在這個技術(shù)的市場推廣上也投入很多精力,其他后來者可能會坐享其成。
北京知存科技有限公司成立于2017年10月,專注于開發(fā)基于存算一體的人工智能芯片和系統(tǒng)。公司通過自主研發(fā)的核心技術(shù)將計算和存儲融合在NOR Flash存儲芯片中,大幅度提高運算的并行讀,提升人工智能核心運算效率多個數(shù)量級。該設(shè)計方法還簡化了芯片設(shè)計架構(gòu),節(jié)省了內(nèi)存、緩存和神將網(wǎng)絡(luò)加速器模塊的支出,顯著地降低了芯片成本。當前公司正在流片的是面向終端設(shè)備的低功耗語音識別芯片。公司將長期致力于深入研發(fā)和優(yōu)化存算一體化技術(shù),將之應(yīng)用于廣闊的人工智能應(yīng)用場景中。
-
芯片
+關(guān)注
關(guān)注
454文章
50432瀏覽量
421899 -
存儲器
+關(guān)注
關(guān)注
38文章
7453瀏覽量
163610 -
人工智能
+關(guān)注
關(guān)注
1791文章
46873瀏覽量
237613 -
存算一體
+關(guān)注
關(guān)注
0文章
100瀏覽量
4288
原文標題:五期Demo Day路演回顧 | 知存科技:讓AI設(shè)備無所不在
文章出處:【微信號:ARMaccelerator,微信公眾號:安創(chuàng)空間ARMaccelerator】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
直播預(yù)約 |開源芯片系列講座第24期:SRAM存算一體:賦能高能效RISC-V計算

存算一體化與邊緣計算:重新定義智能計算的未來

存算一體架構(gòu)創(chuàng)新助力國產(chǎn)大算力AI芯片騰飛
科技新突破:首款支持多模態(tài)存算一體AI芯片成功問世

后摩智能推出邊端大模型AI芯片M30,展現(xiàn)出存算一體架構(gòu)優(yōu)勢
知存科技推動新一代存內(nèi)計算芯片產(chǎn)品產(chǎn)業(yè)化進程
知存科技助力AI應(yīng)用落地:WTMDK2101-ZT1評估板實地評測與性能揭秘
存內(nèi)計算WTM2101編譯工具鏈 資料
探索存內(nèi)計算—基于 SRAM 的存內(nèi)計算與基于 MRAM 的存算一體的探究

知存科技攜手北大共建存算一體化技術(shù)實驗室,推動AI創(chuàng)新
北京大學(xué)-知存科技存算一體聯(lián)合實驗室揭牌,開啟知存科技產(chǎn)學(xué)研融合戰(zhàn)略新升級

什么是通感算一體化?通感算一體化的應(yīng)用場景







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論