 用MLP做圖像分類識別?
用MLP做圖像分類識別?
▌一、前言
閱讀本文的基礎:我會認為你對BP神經網絡有充分的了解,熟讀過我上一篇文章,本文會大量引用上一篇文章的知識以及代碼。
▌二、用MLP做圖像分類識別?
在沒有CNN以及更先進的神經網絡的時代,樸素的想法是用多層感知機(MLP)做圖片分類的識別,沒毛病。
作為上篇筆記學習的延續,以及下一篇CNN的藥引,使用MLP來做圖片分類識別,實在是個不錯的過度例子。通過這個例子,從思路上引出一系列的問題,我不賣關子,自問自答吧,即:
MLP能做圖片分類識別嗎?--> 答案是是可以的,上一篇我們是擬合非線性分類函數,這里是擬合圖像特征,數學本質沒區別。
MLP做這個事情效果如何?--> 個人認知內,只能說一般一般。
MLP在這一領域效果一般,是有什么缺陷嗎? --> 缺陷是有的,下文會詳細說。
有更好的解決方案嗎? --> 那也是必須有的,地球人火星人喵星人都知道有CNN等等更先進的東東;但是在沒有這些東西存在的時代,你發明出來了,那才真是666。
▌三、先上車
1. 數據源
數據源當然是圖片,但是是經過數據化處理的圖片,使用的是h5文件。h5文件簡單說就是把數據按索引固化起來,挺簡單的不多說,度度一下:
h5py入門講解:
https://blog.csdn.net/csdn15698845876/article/details/73278120
我們有3個h5文件,存著不重復的圖片數據,分別是:
train_catvnoncat.h5 (用來訓練模型用的,一共有209張,其中有貓也有不是貓的圖片,尺寸64*64像素)
test_catvnoncat.h5 (用來測試模型準確度的,一共有50張圖片,,其中有貓也有不是貓的圖片,尺寸64*64像素)
my_cat_misu.h5 (用來玩的,我家貓主子的1張照騙,尺寸64*64像素)
2. 數據結構
拿train_catvnoncat.h5舉例,這個文件有2個索引:
train_set_x:這是一個數組,因為是209張圖片,所以數組長度是209。數組中的元素是一個 64*64*3 的矩陣。64*64是圖片像素尺寸,3是什么鬼?別忘了這是彩色圖片,3就是代表RGB這3個顏色通道的值。
train_set_y:圖片標簽數組,長度也是209,是209張圖片的標簽(label),對應數組下標的值是1時,代表這張圖片是喵星人,0則代表不是。
同理,test_catvnoncat.h5 中有 test_set_x 和 test_set_y;my_cat_misu.h5 中有 mycat_set_x 和 mycat_set_y
3. 告訴你怎么制作圖片的h5文件,以后做cnn等模型訓練時,非常有用
以我主子為例子:
原圖:
自己處理成64*64的圖片,當然你也可以寫代碼做圖片處理,我懶,交給你實現了:
python代碼,用到h5py庫:
def save_imgs_to_h5file(h5_fname, x_label, y_label, img_paths_list, img_label_list): # 構造n張圖片的隨機矩陣 data_imgs = np.random.rand(len(img_paths_list), 64, 64, 3).astype('int') label_imgs = np.random.rand(len(img_paths_list), 1).astype('int') # plt.imread可以把圖片以多維數組形式讀出來,然后我們存成 n*n*3 的矩陣 for i in range(len(img_paths_list)): data_imgs[i] = np.array(plt.imread(img_paths_list[i])) label_imgs[i] = np.array(img_label_list[i]) # 創建h5文件,按照指定的索引label存到文件中,完事了 f = h5py.File(h5_fname, 'w') f.create_dataset(x_label, data=data_imgs) f.create_dataset(y_label, data=label_imgs) f.close() return data_imgs, label_imgs #用法 # 圖片label為1代表這是一張喵星人的圖片,0代表不是 save_imgs_to_h5file('datasets/my_cat_misu.h5', 'mycat_set_x', 'mycat_set_y', ['misu.jpg'],[1])
4. 看看我的數據源的樣子
用來訓練的圖片集合,209張:
用來校驗模型準確度的圖片集合, 50張
用來玩的,主子照騙,1張:
▌四. 開車了
1. 如何設計模型:
輸入層:我們的圖片是64*64的像素尺寸,那么算上RGB三個通道的數據,我們把三維矩陣拉成面條 64*64*3 = 12288。 也就是我們輸入層的數據長度是12288。
隱藏層:使用多層隱藏層,可以自行多嘗試一下不同的結構。這里我使用3個隱藏層,隱藏層神經元個數分別是20,7,5
輸出層:我們的目標就是判斷某張圖片是否是貓而已,所以輸出層1個神經元,輸出概率大于0.5認為是貓,小于等于0.5認為不是。
【插播】:有人會想,第一層隱藏層的神經元和輸入層數量一致是不是會好點?理論上是會好點,但是這涉及到MLP的一個缺陷,因為全連接情況下,這樣做,第一層的權重w參數就有1228的平方個,約為1.5個億。如果圖片更大呢?參數會成指數級膨脹,后果盡情想象。
2. 如何訓練模型
還用說,把209張圖片的數據扔到神經網絡,完成一次迭代,然后訓練1萬次,可自行嘗試迭不同代次數觀察效果。
3. 如何衡量模型的準確度
大神吳恩達(Andrew Ng)提到的方法之一,就是劃分不同集合,一部分用來訓練,一部分用來驗證模型效果,這樣可以達到衡量你所訓練的模型的效果如何。所以我們訓練使用209張圖片,最終使用50張測試模型效果。
為了好玩,可以自己用不同圖片通過模型去做分類識別。
▌五. 老規矩,甩代碼
還是說明一下代碼流程吧:
代碼使用到的 NeuralNetwork 是我上一篇筆記的代碼,實現了BP神經網絡,import進來直接用即可。
代碼做的事情就是:
從h5文件加載圖片數據
把原始圖片顯示出來,同時也保存成圖片文件
訓練神經網絡模型
驗證模型準確度
把識別結果標注到原始圖片上,同時也保存成圖片文件
#coding:utf-8 import h5py import matplotlib.font_manager as fm import matplotlib.pyplot as plt import numpy as np from NeuralNetwork import * font = fm.FontProperties(fname='/System/Library/Fonts/STHeiti Light.ttc') def load_Cat_dataset(): train_dataset = h5py.File('datasets/train_catvnoncat.h5', "r") train_set_x_orig = np.array(train_dataset["train_set_x"][:]) train_set_y_orig = np.array(train_dataset["train_set_y"][:]) test_dataset = h5py.File('datasets/test_catvnoncat.h5', "r") test_set_x_orig = np.array(test_dataset["test_set_x"][:]) test_set_y_orig = np.array(test_dataset["test_set_y"][:]) mycat_dataset = h5py.File('datasets/my_cat_misu.h5', "r") mycat_set_x_orig = np.array(mycat_dataset["mycat_set_x"][:]) mycat_set_y_orig = np.array(mycat_dataset["mycat_set_y"][:]) classes = np.array(test_dataset["list_classes"][:]) train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0])) test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0])) mycat_set_y_orig = mycat_set_y_orig.reshape((1, mycat_set_y_orig.shape[0])) return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, mycat_set_x_orig, mycat_set_y_orig,classes def predict_by_modle(x, y, nn): m = x.shape[1] p = np.zeros((1,m)) output, caches = nn.forward_propagation(x) for i in range(0, output.shape[1]): if output[0,i] > 0.5: p[0,i] = 1 else: p[0,i] = 0 # 預測出來的結果和期望的結果比對,看看準確率多少: # 比如100張預測圖片里有50張貓的圖片,只識別出40張,那么識別率就是80% print(u"識別率: " + str(np.sum((p == y)/float(m)))) return np.array(p[0], dtype=np.int), (p==y)[0], np.sum((p == y)/float(m))*100 def save_imgs_to_h5file(h5_fname, x_label, y_label, img_paths_list, img_label_list): data_imgs = np.random.rand(len(img_paths_list), 64, 64, 3).astype('int') label_imgs = np.random.rand(len(img_paths_list), 1).astype('int') for i in range(len(img_paths_list)): data_imgs[i] = np.array(plt.imread(img_paths_list[i])) label_imgs[i] = np.array(img_label_list[i]) f = h5py.File(h5_fname, 'w') f.create_dataset(x_label, data=data_imgs) f.create_dataset(y_label, data=label_imgs) f.close() return data_imgs, label_imgs if __name__ == "__main__": # 圖片label為1代表這是一張喵星人的圖片,0代表不是 #save_imgs_to_h5file('datasets/my_cat_misu.h5', 'mycat_set_x', 'mycat_set_y', ['misu.jpg'],[1]) train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, mycat_set_x_orig, mycat_set_y_orig, classes = load_Cat_dataset() train_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T test_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T mycat_x_flatten = mycat_set_x_orig.reshape(mycat_set_x_orig.shape[0], -1).T train_set_x = train_x_flatten / 255. test_set_x = test_x_flatten / 255. mycat_set_x = mycat_x_flatten / 255. print(u"訓練圖片數量: %d" % len(train_set_x_orig)) print(u"測試圖片數量: %d" % len(test_set_x_orig)) plt.figure(figsize=(10, 20)) plt.subplots_adjust(wspace=0,hspace=0.15) for i in range(len(train_set_x_orig)): plt.subplot(21,10, i+1) plt.imshow(train_set_x_orig[i],interpolation='none',cmap='Reds_r',vmin=0.6,vmax=.9) plt.xticks([]) plt.yticks([]) plt.savefig("cat_pics_train.png") plt.show() plt.figure(figsize=(8, 8)) plt.subplots_adjust(wspace=0, hspace=0.1) for i in range(len(test_set_x_orig)): ax = plt.subplot(8, 8, i + 1) im = ax.imshow(test_set_x_orig[i], interpolation='none', cmap='Reds_r', vmin=0.6, vmax=.9) plt.xticks([]) plt.yticks([]) plt.savefig("cat_pics_test.png") plt.show() plt.figure(figsize=(2, 2)) plt.subplots_adjust(wspace=0, hspace=0) for i in range(len(mycat_set_x_orig)): ax = plt.subplot(1, 1, i + 1) im = ax.imshow(mycat_set_x_orig[i], interpolation='none', cmap='Reds_r', vmin=0.6, vmax=.9) plt.xticks([]) plt.yticks([]) plt.savefig("cat_pics_my.png") plt.show() # 用訓練圖片集訓練模型 layers_dims = [12288, 20, 7, 5, 1] nn = NeuralNetwork(layers_dims, True) nn.set_xy(train_set_x, train_set_y_orig) nn.set_num_iterations(10000) nn.set_learning_rate(0.0075) nn.training_modle() # 結果展示說明: # 【識別正確】: # 1.原圖是貓,識別為貓 --> 原圖顯示 # 2.原圖不是貓,識別為不是貓 --> 降低顯示亮度 # 【識別錯誤】: # 1.原圖是貓,但是識別為不是貓 --> 標紅顯示 # 2.原圖不是貓, 但是識別成貓 --> 標紅顯示 # 訓練用的圖片走一遍模型,觀察其識別率 plt.figure(figsize=(10, 20)) plt.subplots_adjust(wspace=0, hspace=0.15) pred_train, true, accuracy = predict_by_modle(train_set_x, train_set_y_orig, nn) for i in range(len(train_set_x_orig)): ax = plt.subplot(21, 10, i + 1) x_data = train_set_x_orig[i] if pred_train[i] == 0 and train_set_y_orig[0][i] == 0: x_data = x_data/5 if true[i] == False: x_data[:, :, 0] = x_data[:, :, 0] + (255 - x_data[:, :, 0]) im = plt.imshow(x_data,interpolation='none',cmap='Reds_r',vmin=0.6,vmax=.9) plt.xticks([]) plt.yticks([]) plt.suptitle(u"Num Of Pictrues: %d Accuracy: %.2f%%" % (len(train_set_x_orig), accuracy), y=0.92, fontsize=20) plt.savefig("cat_pics_train_predict.png") plt.show() # 不屬于訓練圖片集合的測試圖片,走一遍模型,觀察其識別率 plt.figure(figsize=(8, 8)) plt.subplots_adjust(wspace=0, hspace=0.1) pred_test, true, accuracy = predict_by_modle(test_set_x, test_set_y_orig, nn) for i in range(len(test_set_x_orig)): ax = plt.subplot(8, 8, i + 1) x_data = test_set_x_orig[i] if pred_test[i] == 0 and test_set_y_orig[0][i] == 0: x_data = x_data/5 if true[i] == False: x_data[:, :, 0] = x_data[:, :, 0] + (255 - x_data[:, :, 0]) im = ax.imshow(x_data, interpolation='none', cmap='Reds_r', vmin=0.6, vmax=.9) plt.xticks([]) plt.yticks([]) plt.suptitle(u"Num Of Pictrues: %d Accuracy: %.2f%%" % (len(test_set_x_orig), accuracy), fontsize=20) plt.savefig("cat_pics_test_predict.png") plt.show() # 用我家主子的照騙,走一遍模型,觀察其識別率,因為只有一張圖片,所以識別率要么 100% 要么 0% plt.figure(figsize=(2, 2.6)) plt.subplots_adjust(wspace=0, hspace=0.1) pred_mycat, true, accuracy = predict_by_modle(mycat_set_x, mycat_set_y_orig, nn) for i in range(len(mycat_set_x_orig)): ax = plt.subplot(1, 1, i+1) x_data = mycat_set_x_orig[i] if pred_mycat[i] == 0 and mycat_set_y_orig[0][i] == 0: x_data = x_data/5 if true[i] == False: x_data[:, :, 0] = x_data[:, :, 0] + (255 - x_data[:, :, 0]) im = ax.imshow(x_data, interpolation='none', cmap='Reds_r', vmin=0.6, vmax=.9) plt.xticks([]) plt.yticks([]) if pred_mycat[i] == 1: plt.suptitle(u"我:'我主子是喵星人嗎?' A I :'是滴'", fontproperties = font) else: plt.suptitle(u"我:'我主子是喵星人嗎?' A I :'唔系~唔系~'", fontproperties = font) plt.savefig("cat_pics_my_predict.png") plt.show()
▌六.結論
1. 神經網絡模型的輸出結果,標注到了圖片上并展示出來,規則是:
結果展示說明:
【識別正確】:原圖是貓,識別為貓 --> 原圖顯示原圖不是貓,識別為不是貓 --> 降低顯示亮度【識別錯誤】:原圖是貓,但是識別為不是貓 --> 標紅顯示原圖不是貓, 但是識別成貓 --> 標紅顯示
圖片標題會顯示Accuracy(準確度),準確度的計算公式是: 識別正確圖片數/圖片總數。
2. 模型訓練完成后,把訓練用的209張圖片用訓練好的模型識別一遍,觀察結果:可以看到,迭代1w次的模型,識別訓練圖集,準確度是 100% 的:
3. 模型訓練完成后,使用測試圖集用訓練好的模型識別一遍,觀察結果:可以看到,迭代1w次的模型,識別訓練圖集,準確度只有 78%:
4. 看看模型能不能認出我主子是喵星人,看樣子,它是認出來了:
▌七.對結果進一步分析,引出一系列問題
拋出一個問題:為什么用測試圖集驗證模型,識別率只有78%?在我嘗試過改變神經網絡結構設計,參數調參后,仍然無法提高識別率,為什么呢?
不算徹底的解答:
也許是我水平有限,調參姿勢不對?姿勢帥并不是萬能的,我們應該從更深層次的原理進行分析。
有人說,你訓練數據少了,好像有那么些道理。其實是可以給模型輸入更多圖片的特征是個不錯的辦法,比如旋轉一下,圖片內容放大縮小,挪挪位置等。但是Andrew Ng也說過,過分追求訓練數據收集是一條不歸路。
在同等訓練數據集下,有更好的辦法嗎?由此引出下一個問題。
刨根問底:想要知道為什么MLP識別度難以做到很高,撇開網絡結構,調參,訓練數據先不談。我們應該從MLP身上找找茬。搞清楚我們目標,是提高對圖片進行分類識別,那么在使用MLP實現這個目標時,它自身是否有缺陷,導致實現這個目標遇到了困難。那么解決了這些困難,就找到了解決問題的方法。
MLP在做圖片分類識別的缺陷:神經元是全連接的方式構成的神經網絡,全連接情況下,假設圖片是1k*1k像素大小,那么隱藏層個數和輸入層尺寸一致時,不考慮RGB顏色通道,單通道下,權重w參數個數會是: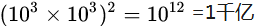 (沒數錯0的話)
(沒數錯0的話)
如果圖片再大點,參數膨脹到不可想象,直接導致的負面效果是:
參數過多,計算量龐大
全連接情況下,過深的網絡容易導致梯度消失,模型難以訓練
MLP全連接的情況下,無法做到圖片的形變識別。怎么理解這個詞呢,拿手寫數字舉個例子,比如寫8,每個人書寫習慣不一樣,有的人寫的很正,但有的人寫歪了點,上半部分小,下半部分大,等等。這時候,MLP的缺點就顯現出來了,同一張圖片,旋轉,或者稍微平移形變一下,它無法識別。你可以通過增加更多特征給模型,但這不是本質上的解決該問題的方法,而是對訓練的優化手段。
▌八. 總結要解決的問題,離下一個坑就不遠了
上面已經列舉了要解決的幾個問題,這里總結一下:
我們要解決參數膨脹帶來的計算量龐大的問題。
優化參數量之后,如何在同等訓練數據集不變的情況下,如何提取更多特征。
在輸入有一定的旋轉平移伸縮時,仍能正確識別。
能解決以上問題的眾所周知,就是CNN以及眾多更先進的神經網絡模型了。本文作為一篇引子文章,也是CNN的導火索。代碼在你手中,把第一層隱藏層設計成和輸入層一樣大,即 layers_dims = [12288, 12288, 20, 7, 5, 1]。還只是64*64的小圖片而已,那龜速,我和我的小破筆記本都不能忍啊。這也是為什么大神們發明CNN的原因之一吧!
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
AI
+關注
關注
87文章
30107瀏覽量
268401 -
圖像分類
+關注
關注
0文章
90瀏覽量
11907
原文標題:AI從入門到放棄2:CNN的導火索,用MLP做圖像分類識別?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于MLP的快速醫學圖像分割網絡UNeXt相關資料分享
介紹一種用于密集預測的mlp架構CycleMLP
花粉圖像分類識別
人體識別圖像技術的原理及分類
模擬矩陣在圖像識別中的應用

CNN圖像分類策略





 工商網監
工商網監
評論