") Dota2敗給OpenAI-Five究竟是為什么?
Dota2敗給OpenAI-Five究竟是為什么?
OpenAI昨日發(fā)布研究成果,宣布Dota2 5v5在限定條件下(英雄陣容固定,部分道具和功能禁用)戰(zhàn)勝人類半職業(yè)選手。本文主要對其模型技術(shù)架構(gòu)做一些分析總結(jié)。
一、 模型輸入與輸出
模型的輸入是使用RAM(內(nèi)存信息),如位置坐標,技能血量數(shù)值狀態(tài)等,而不是圖像像素信息。
模型輸入主要分為兩個部分:
直接觀測的信息:場面其他英雄的絕對位置,相對距離,相對角度,血量,狀態(tài)等。
人工定義抽象的信息:是否被攻擊以及正在被誰攻擊,炮彈距離命中的時間,朝向的cos與sin,最近12幀內(nèi)的英雄的血量變化等。
模型的輸出即是指AI所選擇的動作,包括移動,攻擊釋放技能等。OpenAI將連續(xù)的動作,離散化對應(yīng)到網(wǎng)格,并對各種技能定制化釋放動作,以減少動作空間的大小。以下圖為例,AI要釋放一個攻擊技能,需要選取這個技能,并選擇一個目標單位周圍網(wǎng)格內(nèi)的一個位置:
值得注意的是,在Dota2游戲內(nèi)還有其他動作,例如操控信使,購買裝備,技能升級與天賦等,這些都是人工定義好,而不需AI決策的。而操控幻象分身,召喚物等涉及更復(fù)雜的多單位操作,則未在OpenAI當前版本的考慮范圍內(nèi)。
二、 網(wǎng)絡(luò)架構(gòu)與訓(xùn)練方式
網(wǎng)絡(luò)架構(gòu)架構(gòu)局部如下圖:
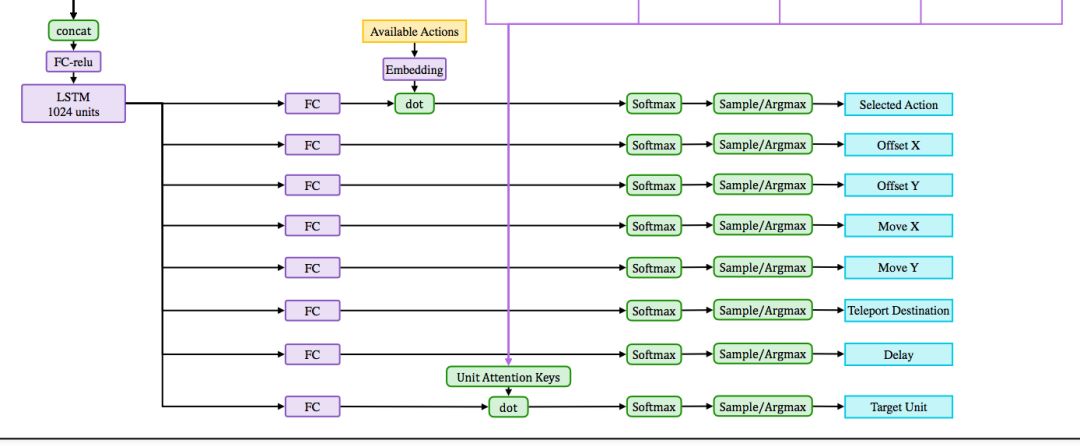
模型大圖下載鏈接:https://d4mucfpksywv.cloudfront.net/research-covers/openai-five/network-architecture.pdf
總的來看,大量信息通過連接(concatenate)與全連接層(dense)層進行綜合,作為1024維的LSTM的輸入。LSTM綜合時序信息,并輸出決策向量,再用決策向量解構(gòu)出詳細動作。
訓(xùn)練方式:
純自我對弈訓(xùn)練。
隨機化訓(xùn)練:隨機初始狀態(tài)(血量速度移動等)的訓(xùn)練,以增強泛化能力。
使用很高的γ=0.9997。γ為獎勵衰減值,一般在其他環(huán)境中設(shè)置為0.98,0.998。
大量計算:128,000CPU+256GPU,能做到每天模擬玩180年的游戲。
獎勵(reward)設(shè)計:
總體獎勵:當前局面評估(塔的情況等),KDA(個人戰(zhàn)績),補兵表現(xiàn)等。
合作獎勵:全隊的表現(xiàn)作為自己獎勵的一部分。
分路對線的獎勵與懲罰:最開始分配一條路,前期發(fā)育時如果偏離就會懲罰。
三、 總結(jié)
用強化學(xué)習(xí)玩Dota2需要面對4個挑戰(zhàn):狀態(tài)空間大,局面不完全可見(有視野限制),動作空間大,時間尺度大。
近期論文中提出的解決方案,大致有以下幾個方向:
狀態(tài)空間大:解決方法如先用World Models抽象,再進行決策。
局面不完全可見:一般認為需要進行一定的搜索,如AlphaGo的MCTS(蒙特卡洛樹搜索)。
動作空間大:可以使用模仿學(xué)習(xí)(Imitation Learning),或者與層次強化學(xué)習(xí)結(jié)合的方法。
時間尺度大:一般認為需要時間維度上的層次強化學(xué)習(xí)(Hierarchical Reinforcement Leanring)來解決這個問題。
而神奇的是,OpenAI沒有使用上述任一方法,而僅僅使用高γ值的PPO基礎(chǔ)算法,就解決了這些問題。這說明憑借非常大量的計算,強化學(xué)習(xí)的基礎(chǔ)算法也能突破這些挑戰(zhàn)。
OpenAI沒有使用的WorldModels,MCTS,IL,HRL等方法,既是學(xué)術(shù)界研究的重點方向,也是OpenAI-Five潛在的提升空間。這些更高效的方法若被合理應(yīng)用,可以加快模型的學(xué)習(xí)速度,增強模型的遷移能力,并幫助模型突破當前的限制。
-
AI
+關(guān)注
關(guān)注
87文章
30146瀏覽量
268411 -
模型
+關(guān)注
關(guān)注
1文章
3172瀏覽量
48713
原文標題:技術(shù)架構(gòu)分析:攻克Dota2的OpenAI-Five
文章出處:【微信號:AItists,微信公眾號:人工智能學(xué)家】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論