 繼OpenAI發布Dota2的團戰AI后,DeepMind今天也發布了自家的最新研究
繼OpenAI發布Dota2的團戰AI后,DeepMind今天也發布了自家的最新研究
編者按:繼OpenAI發布Dota2的團戰AI后,DeepMind今天也發布了自家的最新研究,一些可以互相協作,也可以和人類選手合作的人工智能機器人。以下是論智對DeepMind博文的編譯。
在游戲項目中,讓AI掌握策略、理解戰術并進行團隊合作是非常重要的。現在的強化學習經過發展,我們的智能體在《雷神之錘III:競技場》的奪旗比賽(Capture the Flag)中的表現達到了人類水平,它們在團隊合作方面展示出了較高水準。
《雷神之錘III:競技場》的奪旗模式(CTF)是一款以第一人稱視角展示的多人游戲,參賽者分成兩組,紅隊和藍隊。每組隊員的目標是奪取對方的旗幟并將它帶回自己的基地,同時保護己方旗幟。殺死對手得1分,自己非正常死亡扣1分,奪取對方旗子得3分,殺死奪旗者得2分,重新拿到己方旗子得1分,成功奪取一次旗子(將旗子送回己方基地)得5分。五分鐘內有較多旗子的一方獲勝。
我們訓練的四個智能體在室內和室外兩種環境下進行對戰,并逐漸修煉到能夠奪旗的水平
對人類來說,每個個體都有自己的目標和行動方式,但我們仍然能在團隊和組織中展示出集體智慧,我們將這一設置稱為“多智能體學習”:多個智能體必須獨立行動,但是要學習與其他智能體交互合作。這個問題非常困難,因為環境是在不斷變化的。
為了研究這一問題,我們以各類3D第一人稱視角的電子游戲為研究對象,它們代表了大多數游戲的形式,能反映各類玩家的策略,因為其中包括了他們對游戲的理解、手眼配合以及團隊計劃。我們的智能體所面臨的挑戰是直接從原始像素中學習,從而輸出動作。
實驗中我們選用的《雷神之錘III:競技場》游戲是現在許多第一人稱角色游戲的基礎,我們訓練智能體像單人一樣學習和行動,但是仍要在團隊間進行合作,共同對抗敵方。
從一個多智能體的角度,CTF需要玩家既能和隊友完美合作,也要與敵人對抗,不論在什么風格下都要保持水平的穩定。
為了讓這一過程更有趣,我們還設計了一個CTF的變體,其中的平面地圖每一場都不一樣。結果我們的智能體被迫學習到了一種“通用策略”,而非靠對地圖的記憶獲勝。除此之外,為了評估游戲場地,我們的智能體用人類的方式感受了一下CTF的環境:它們通過一個虛擬游戲控制器觀察一連串的像素圖像和動作。
CTF的環境不斷更新,所以智能體必須適應陌生地圖
我們的智能體必須從零開始學習在陌生環境中如何觀察地形、行動、合作、競爭,這一切都要從每場比賽的單一強化信號中得來:不論它們所在隊伍是否獲勝。這是一個具有挑戰性的學習問題,而解決方法基于三個強化學習的基本問題:
與訓練單一智能體相反,我們訓練的是多個智能體,它們通過與各種隊友和對手的互動來學習。
團隊里的每個智能體都從它自己的內部獎勵信號中學習,從而讓智能體生成自己內部的目標,例如獲得一面旗幟。兩階段的優化過程優化了智能體內部的獎勵,同時用內部獎勵的強化學習學習了智能體的策略。
智能體會在快慢兩種速度下進行訓練,這樣會提高他們利用內存并生成連續動作的能力。
最終訓練出的智能體(FTW)在玩CTF上表現出了很高的水準。重要的是,該智能體在各種地圖、隊員數量的情況下,表現得都很穩定。不論是在戶外模式還是室內模式,或者有人類參與的比賽中,FTW都表現的很好。
我們組織了一場聯賽,其中有40名人類玩家,將人類和智能體隨機組合分配到游戲中。
FTW智能體學習之后比基準的方法更強大,同時超過了人類選手的取勝率。事實上,在對參賽者的評估上,智能體的合作能力比人類更強。

智能體在訓練時的表現與人類的對比
理解智能體的內部機制
為了了解智能體是如何表示游戲狀態的,我們查看了智能體神經網絡的活動形式。下面的圖表展示了游戲過程中的情形,其中密密麻麻的點根據CTF在游戲中的狀態分成不同的顏色,根據顏色可以判斷:智能體在哪個房間?旗子的狀態如何?能看到哪個隊友或對手?通過觀察顏色相同的點,我們發現在相似狀態的智能體動作也相似。

各色點點代表游戲中各種智能體所處的狀態和位置
我們不會告訴智能體游戲的規則,而是讓他們自己學習基礎概念。事實上,我們可以找到具體編碼有重要游戲狀態的神經元,比如當旗子被奪走時活動的神經元,或者隊友拿到旗時活動的神經元。想知道更多智能體細節,可查看原論文。
除了這些多樣的表示,智能體實際上是怎樣運作的?首先,我們注意到智能體的反應時間很快,并且還有精確的標記器。但是當人為地降低他們的精度和反應時間,我們看到導致成功的只有一個因素。
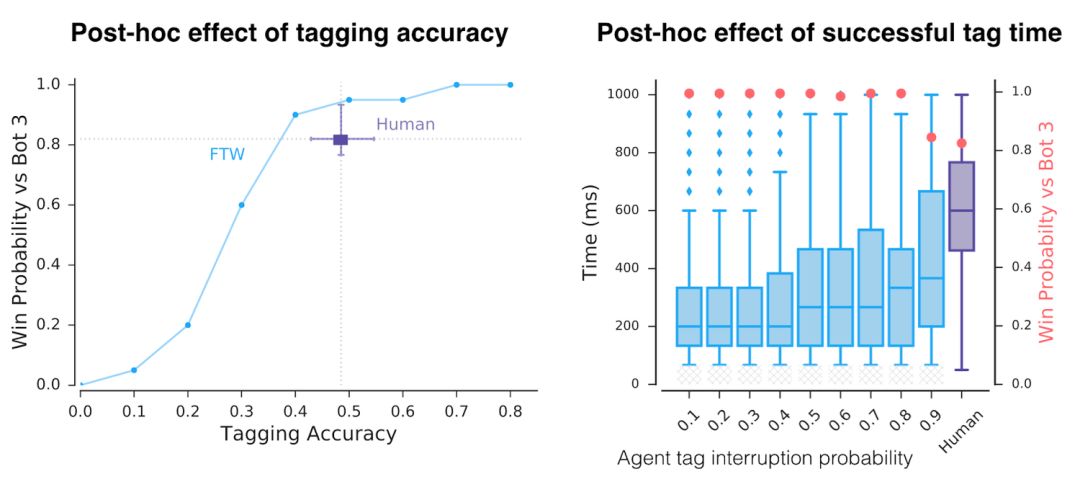
智能體的精確度和反應時間比人類要高
通過無監督學習我們創建了智能體的原始動作,發現智能體實際上是在模仿人類行為,例如跟隨隊友或者在對手的基地“安營扎寨”。這些動作都是在訓練中通過強化學習和進化得來的。

結語
最近人工智能在星際爭霸II和Dota 2這樣復雜的游戲中都取得了不小的進步,雖然這一項目的側重點在于“奪旗”游戲,但是做出的貢獻是通用的,研究人員表示,他們很高興看到其他研究者在不同環境中應用這一技術。在未來,他們將對目前的強化學習和基于多個智能體的訓練方法進行改進。總的來說,這項工作突出了多智能體訓練的潛力,有助于它們與人類的合作。
-
機器人
+關注
關注
210文章
28212瀏覽量
206554 -
智能體
+關注
關注
1文章
132瀏覽量
10568 -
DeepMind
+關注
關注
0文章
129瀏覽量
10819
原文標題:不論隊友是機器人還是人類,DeepMind智能體學會了復雜合作
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論