 人機交互從哪些方面來改變人類生活
人機交互從哪些方面來改變人類生活
在人機交互過程中,人通過和計算機系統進行信息交換,信息可以是語音、文本、圖像等一種模態或多種模態。對人來說,采用自然語言與機器進行智能對話交互是最自然的交互方式之一,但這條路充滿了挑戰,如何機器人更好的理解人的語言,從而更明確人的意圖?如何給出用戶更精準和不反感的回復?都是在人機交互對話過程中最為關注的問題。對話系統作為NLP的一個重要研究領域受到大家越來越多的關注,被應用于多個領域,有著很大的價值。
▌前言
我從1982年開始坐在電腦前面,一直到現在。上一次做人工智能是27年前,大概1991年的時候,那個時候做人工智能的人非常可憐 ,因為做什么東西都注定做不出來,隨便一個機器學習的訓練、神經網絡訓練需要20天,調個參數再重新訓練又是20天,非常非常慢。電腦棋類我除了圍棋沒做以外,其他都做了,本來這輩子看不到圍棋下贏人,結果兩年前看到了。后來做語音識別,語音識別那個年代也都是玩具,所以那個年代做人工智能的人最后四分五裂,因為根本活不下去,后來就跑去做搜索引擎、跑去做金融、跑去做其他的行業。
這次人工智能卷土重來,真的開始進入人類生活,在周邊地方幫上我們的忙。今天我來分享這些人機交互的技術到底有哪些變化。

先講“一個手環的故事”,這是一個真實的故事,我們在兩年前的4月份曾經想要做這個,假設有一個用戶戴著手環,“快到周末了,跟女朋友約會,給個建議吧”。背后機器人記得我的一些事情,知道我過去的約會習慣是看電影,還是去爬山,還是在家打游戲、看視頻。如果要外出的話,周末的天氣到底怎樣,如果下大雨的話那可能不適合。

而且它知道我喜歡看什么電影、不喜歡看什么電影、我的女朋友喜歡看什么、不喜歡看什么,它甚至知道我跟哪一個女朋友出去,喜歡吃什么,不喜歡吃什么,餐廳的價位是吃2000塊一頓,還是200塊一頓,還是30塊一頓的餐館,然后跟女朋友認識多久了,剛認識的可能去高檔一點的地方,認識6年了吃頓便飯就和了,還有約會習慣。
有了這些東西之后,機器人給我一個回應,說有《失落 的世界2》在某某電影院,這是我們習慣去的地方,看完電影,附近某家餐館的價位和口味 是符合我們的需要。我跟它說“OK,沒問題”,機器人就幫我執行這個命令,幫我買電影票、幫我訂餐館、周末時幫我打車,甚至女朋友剛認識,買一束花放在餐館的桌上。
我們當時想象是做這個。這個牽扯到哪些技術?第一,有記憶力,你跟我講過什么東西,我能記得。還包括人機交互,我今天跟它講“周末是女朋友生日 ,訂個好一點的吧。”它能幫我換個餐館,能理解我的意思。
如果手環能夠做到這個樣子,你會覺得這個手環應該是夠聰明的,這個機器人是夠聰明的,能夠當成 你的助手陪伴你。最后,我們并沒有做出來,我們做到了一部分,但是有一部分并沒有做到。
我們公司的老板叫Kenny,他之前是 微軟亞洲互聯網工程院副院長,負責小冰及cortana的,老板是做搜索引擎出身的,我以前也是做搜索引擎的,做了11年。左下角的曹川在微軟做搜索引擎。右上角在微軟做搜索引擎。右下角在谷歌做搜索引擎。目前的人工智能很多是 搜索引擎跑回來的,因為搜索引擎也是做語義理解、文本 分析,和人工智能的文本 分析有一定的相關度。
▌人機交互的發展
一開始都是一些關鍵詞跟模板的方式,我最常舉的例子,我桌上有一個音箱,非常有名的一家公司做的,我今天跟這個音箱說“我不喜歡吃牛肉面”,音箱會抓到關鍵詞“牛肉面”,它就跟我說“好的,為您推薦附近的餐館”,推薦給我的第一個搞不好就是牛肉面。我如果跟它說“我剛剛吃飯吃很飽”,關鍵詞是“吃飯”,然后它又說“好的,為您推薦附近的餐館”,所以用關鍵詞的方式并不是不能做,它對語義意圖理解的準確率可能在七成、七成五左右,也許到八成,但有些東西它是解不了的,因為它并不是真的理解你這句話是什么意思。所以要做得好的話,必須用自然語言理解的方式,用深度學習、強化學習,模板也用得上,把這些技術混搭在一起,比較有辦法理解你到底要做什么事情。
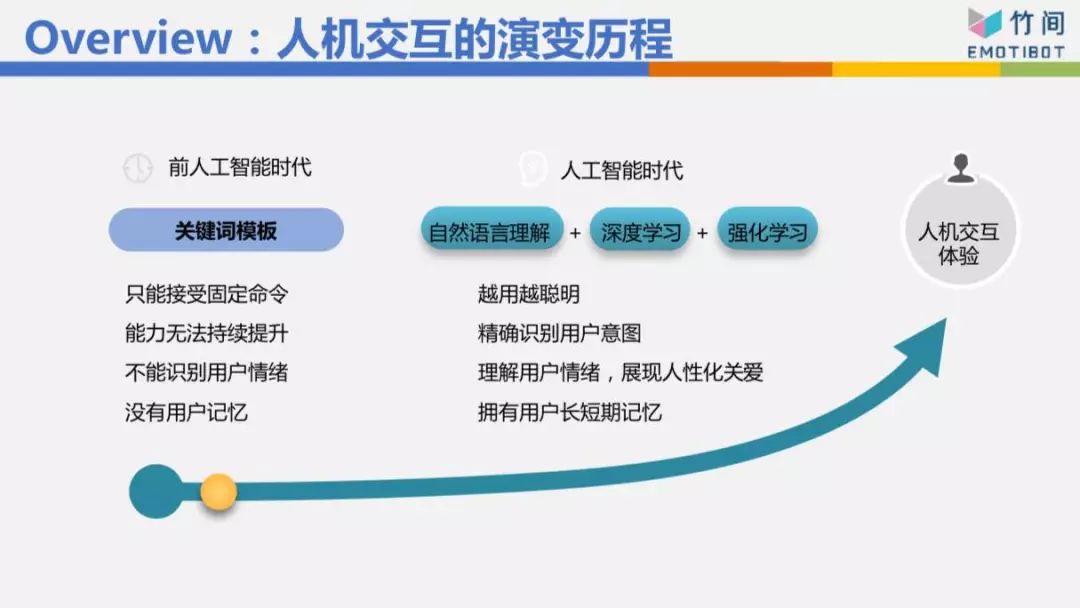
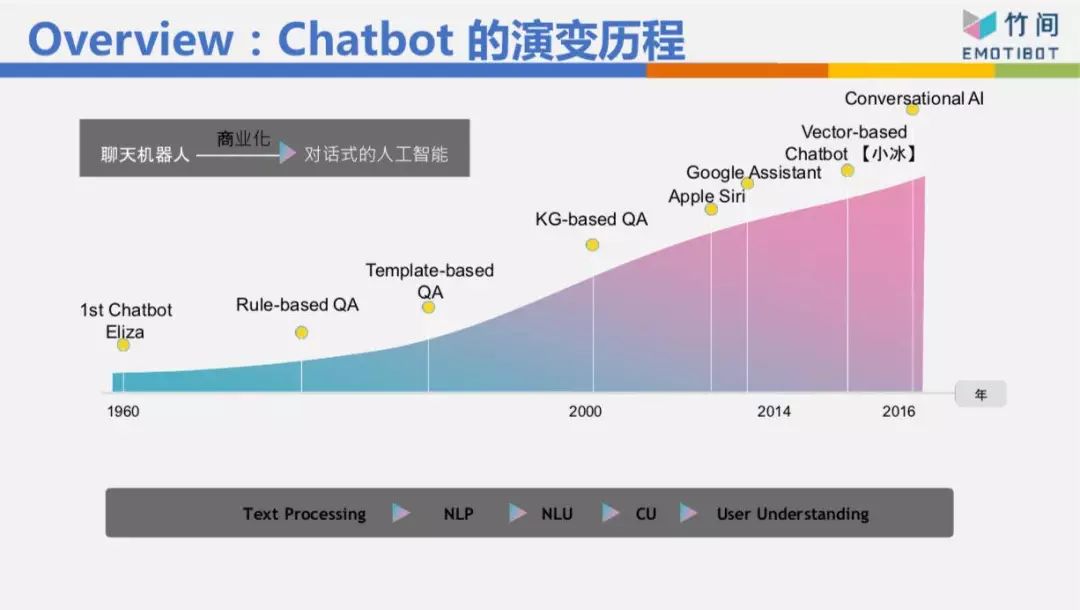
這個Chatbot的演變歷程我們不細講,但我今天要表達,在人機交互里面或者語義理解上面,我們分成三個層次。
最底層的叫自然語言理解,舉例來說,我現在想說“我肚子餓”跟“我想吃東西”這兩句話的句法、句型不太一樣,所以分析的結果也不太一樣,這是最底層的。
第二層叫“意圖的理解”,這兩句話雖然不一樣,但它們的意圖是一致的,“我肚子餓”跟“我想吃東西”可能代表我想知道附近有什么餐館,或者幫我點個外賣,這是第二層。目前大家做的是第一層跟第二層。
其實還有第三層,第三層就是這一句話背后真正的意思是什么,比如我們在八點上這個公開課,我突然當著大家的面說“我肚子餓”跟“我想吃東西”,你們心里會有什么感受?你們心理是不是會覺得我是不是不耐煩、是不是不想講了。你的感受肯定是負面的。今天如果我對著一個女生說“我肚子餓”,女生心里怎么想?會想我是不是要約她吃飯,是不是對她有不良企圖。目前大家離第三層非常遙遠,要走到那一步才是我們心目中真正要的AI,要走到那一步不可避免有情緒 、情感的識別、情境的識別、場景的識別、上下文的識別。
我們公司的名字叫“EMOTIBOT”,情感機器人,我們一開始創立時就試著把情緒 情感 的識別做好。我們情緒情感識別,光文字做了22種情緒 ,這非常變態 ,大部分公司做的是“正、負、中”三種,但是你看負面的情緒 ,有反感、憤怒、難過、悲傷、害怕、不喜歡、不高興,這些情緒 都是負面的,但是它不太一樣,我害怕、我悲傷、 我憤怒,機器人的反饋方式應該是不一樣的。
人臉表情我們做了9種,語言情緒 我們做了4種。而且我們做最多的是把這些情緒混合在一起做了多模態的情感。舉個例子,像高考光結束,我今天看了一段文字:“我高考考了500分”,你看了這段文字不知道該恭喜我還是安慰我。這時要看講話的語氣,如果我的語氣是說“哦,我高考考了500分。”你一聽就知道我是悲傷的,所以會安慰我。所以通常語音情感 比文字情感 來得更直接。
然后人臉表情加進來,三個加在一起,又更麻煩了。我們來看一段視頻,我用桌面 共享。(視頻播放)“鬼知道我經歷了什么”,文字上是匹配的——我已經要死了、生不如死,我的文字是憤怒的,但我的語音情緒跟臉表情是開心的,所以我的總情緒 仍然是開心的。這是把人臉表情、語音情緒 、文字情緒 混搭在一起做出來的多模態情感。
▌上下文理解技術
接下來進入比較技術面的部分,講話聊天時,任務型的機器人一定牽扯到上下文的理解技術。
什么叫上下文理解技術?
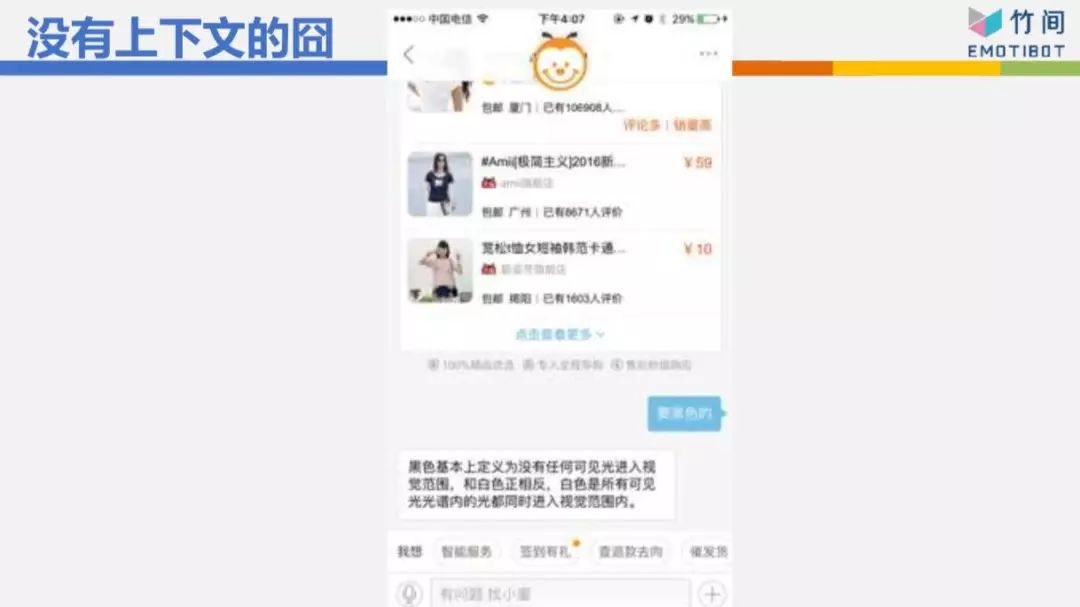
這是某個電商網站,我前面一句話跟它說“我要買T恤”,它給我3件T恤,我跟它說“要黑色的”,意思是我要黑色的那件T恤,但它完全不理解我的意思,因為沒有上下文。所以它居然在跟我解釋黑色的基本定義是什么,是因為不返色,所以你看不到光,所以它是黑色的。這完全不是我要的東西,所以沒有上下文時,它的反應常常啼笑皆非。
我們來看看上下文怎么做,上下文有幾種做法。第一種是補全與指代消解,像說“明天上海會不會下雨”,回答了“明天上海小雨”,“那后天呢”缺了主謂賓等一些東西,所以往上去找,把它補全,把“那后天呢”改成“后天上海會不會下雨”,然后機器人就有辦法處理。

指代消解也是“我喜歡大張偉”,然后機器人回答說“我也喜歡他”,“他”是誰?這個代名詞,我知道“他”是大張偉,所以把“我也喜歡他”改成“我也喜歡大張偉”,這樣才有辦法去理解。然后那個人就說“最喜歡他唱得《倍兒爽》”,那他是誰?要把它改成寫“最喜歡大張偉唱的《倍兒爽》”。這兩個是基本的東西,基本上每家公司都能夠做得到。

然后我們看難一點的東西,可以不可以做對話主題式補全?這個開始有一些上下文在里面,“我喜歡大張偉”,第一句話目前的對話主題是大張偉,然后它回答說“對啊,我也喜歡他”改成“我也喜歡大張偉”,這沒問題。
第二句話是“喉嚨痛怎么辦?”這有兩種可能,因為我現在的對話主題是大張偉,所以可能是“喉嚨痛怎么辦”,也可能是“大張偉喉嚨痛怎么辦”,這時候怎么辦?我到底應該選哪一個?先試第一個“喉嚨痛怎么辦”,居然就可以找到答案了,我知道能夠找到好的答案,我就回答了“喉嚨痛就多喝開水”,目前的對話主題也變成喉嚨痛。
第三個是“他唱過什么歌?”這個他到底是誰?有兩個對話主題,一個是喉嚨痛,一個是大張偉,有可能是“喉嚨痛他唱過什么歌”或者“大張偉他唱過什么歌”。因為優先,最近的對話主題是喉嚨痛,所以我先看第一個,但是一找不到答案,所以我再去看第二個“大張偉唱過什么歌”,那我知道大張偉唱過歌,所以他唱過《倍兒爽》,我就可以回答,這是對話主題式補全。

另外,利用主題做上下文對話控制。像現在在世界杯,我問你“你喜歡英超哪支球隊?”我的主題是“運動”底下的“足球”底下的“五大聯賽”底樣。的“英超”,我可以回答“我喜歡巴薩”,你問我英超,我回答西甲,這沒有什么太大的毛病,雖然最底下的對話主題不太一樣,但是前面是一樣的。或者你問我足球,我可不可以回答籃球,“我比較喜歡看NBA”,這可能不太好,但是也不至于完全不行。如果我回答說“我喜歡吃蛋炒飯”這肯定是不對的,因為你問我的是運動體育里面的東西,我居然回答美食。

這個對話主題我可不可以根據上下文主題,去生成等一下那句回答應該是什么主題?我可以根據上下文去猜測等一下你的下一句回答應該有哪些關鍵詞,我可以根據上下文猜出你下一句是什么句型,是肯定句還是正反問句。我有了關鍵詞、有了句型、有了主題,我可以造句,造出一句回答,這也是上下文解法的一種。或者我什么東西都不管,我直接根據上下文用生成式的方式回你一句話。這個目前大家還在研究發展之中,目前的準確度還不是很高,但這是一個未來的發展方向。
▌NLU的重要性
NLU我們做了12個模塊,最基本的當然是分詞,然后詞性標注,是主詞還是動詞、形容詞稱、第二人稱、第三人稱,然后命名實體,北京有什么好玩的跟上海有什么好玩的,一個是北京,一個是上海,兩個不太一樣。然后我如果問“你喜歡吃蘋果嗎?”“等一下我們去吃麥當勞好不好?”這是一個問句,而且我在問你的個人意見,所以你的回答可能是一個肯定的,可能是一個否定的,也可能反問我一個問句說“等一下幾點去吃”,無論如何,你的回答不會跟我講“早安”或“晚安”,因為我問的是“等一下我們去吃麥當勞好不好。”我們還做了一些奇怪的東西,例如語義角色的標注 ,后面可以看到一些例子。

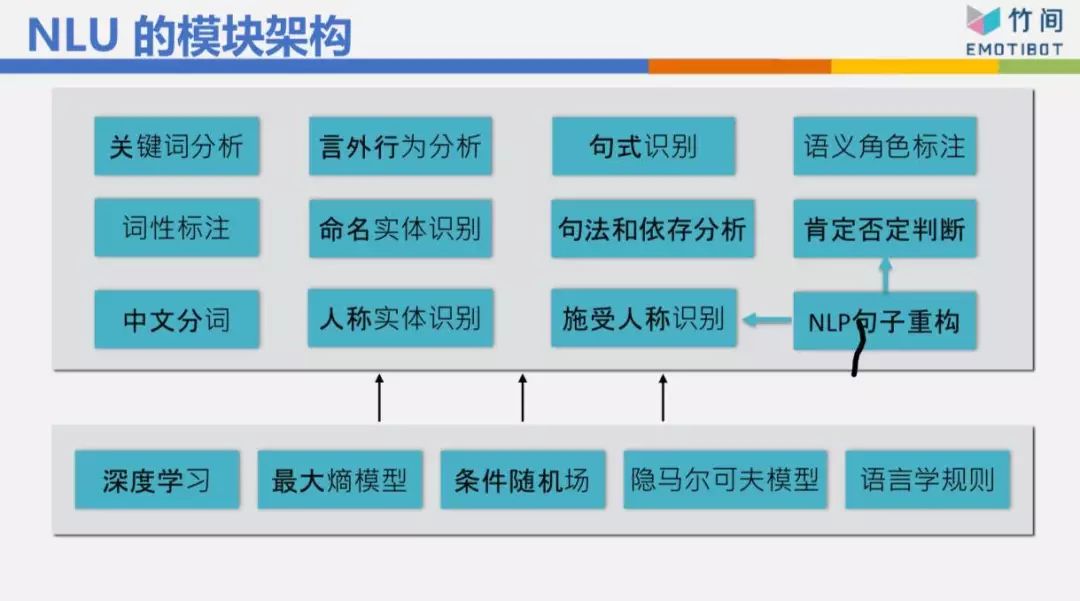
以這個句子來說,“我明天飛上海,住兩天,要如家”整個句子的句法結構拆出來,核心動詞是“飛、住、要”,把它分出來“我飛”、“飛上海”、“住兩天”、“要如家”,有了這些核心動詞,我知道我的意圖不是訂機票,如果只有“我明天飛上海”,我的意圖可能是訂機票,但是因為有后面的“住兩天”跟“要如家”,所以根據這些東西判斷出來我的意圖是訂酒店,根據這些東西算出來:明天入住,3天后離店,都市是上海,酒店名稱叫如家酒店。整個東西就可以把它解析出來。
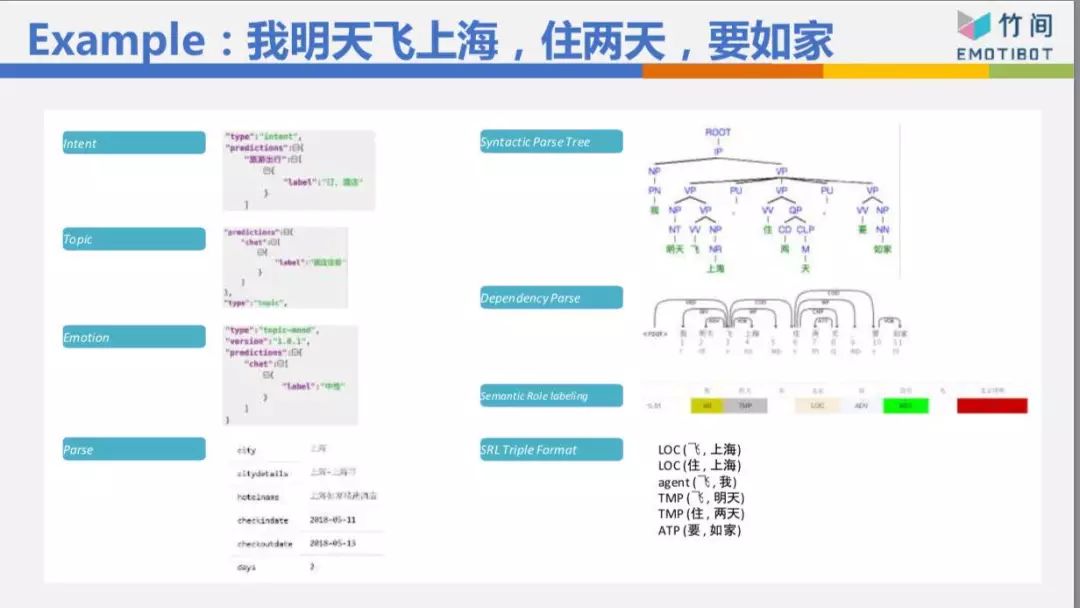
這樣的解法跟深度學習黑盒子最大的差別是,這樣的解法先把句子拆成一些零件,拆成一些基本的信息,我再根據這些信息,可能以深度學習的方式判斷你的意圖、對話主題,這樣我的數據量可以小很多。如果整個大黑盒子,數據量要五十萬比、一百萬比、兩百萬比,才能夠有一定的準確率。今天我做了足夠的拆解,所以我的數據量三萬比、五萬比就夠了,就可以訓練出一個還不錯的模型。
再介紹一下我如何利用NLU的基礎信息,像“上周買衣服多少錢”這句話,我從Speach Act知道這是一個問句,是一個question-info,你不是說“上周買衣服花了好多錢”,這不是一個問句,就不需要處理。是一個問句的話,再看它是一個數量問句,還是地點的問句,還是時間的問句,“我什么時候買了這件衣服?”“我在哪里買了這件衣服?”問句不一樣,后面知道查哪個數據庫的哪張表。根據核心動詞“花錢”跟“買衣服”,知道類別 是衣服飾品,不是吃飯、不是交通,由時間知道是“上周”,整個東西就可以幫你算出來。這等于是我一句話先經過NLU的解析,再判斷你的意圖和細節信息。

▌多輪對話與機器人平臺
像剛剛訂酒店那個例子,如果表明“我要訂酒店”,訂酒店有8個信息要抽取,這時機器人要跟你交流:你要訂哪里的酒店、幾號入住、幾號離店、酒店名稱、星級、價格等等這一堆東西。今天我們的用戶不會乖乖回答。“你要訂哪里的酒店?”他可能乖乖跟你說“上海的”、“北京的”,它也可能跟你說“我明天飛上海,住兩天,要如家”,他一句話就告訴我四個信息,所以基本用填槽的方式,有N個槽要填。然后看看這句話里面有哪些信息,把它抽取出來,填到相對應的槽,再根據哪幾個槽缺失信息決定下一輪的問句該問什么問題,這樣比較聰明。舉例來說,“我想要買一個理財產品”,“您需要是保本還是不保本?”我只問你保本還是不保本,結果他一次回答“保本的,一年的,預期收益不低于5個點。”他一次告訴我3個 信息,而且3個信息已經夠了,我就直接幫你推薦,不用再問你“你要一年、半年還是兩年的?”這樣的機器人看起來就很傻。

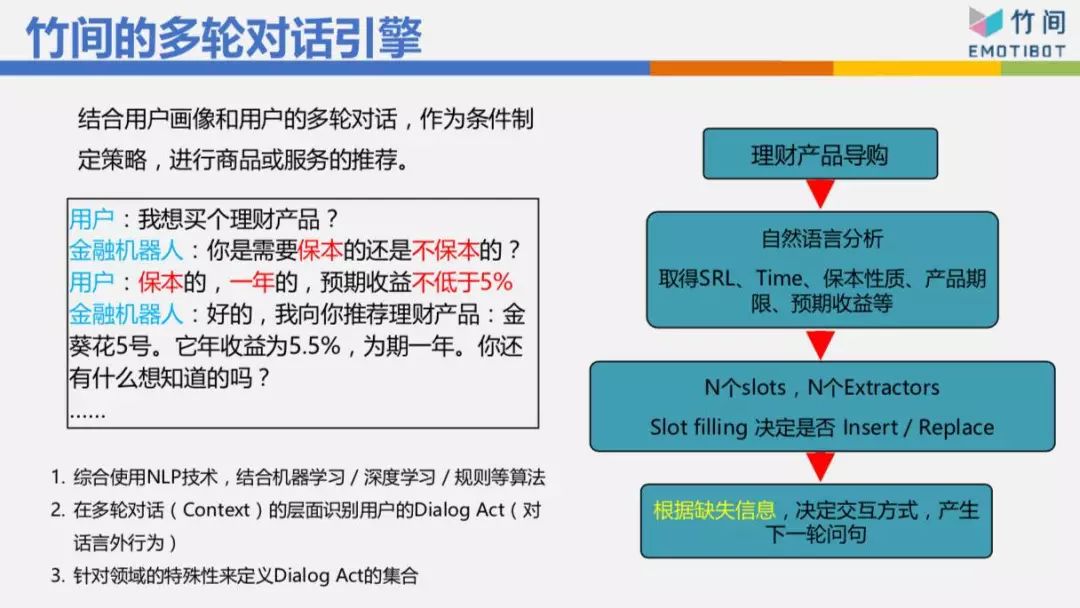
我們來看一些Live Demo的東西


第一個是對話機器人的定制,如何快速定制自己的機器人。
我們先切到共享桌面。在這里,假設我現在創建一個機器人,我的名字“小竹子”,然后我是什么機器人?是一個聊天 的、電商的還是金融機器人?我是一個聊天機器人好了,兩個步驟創建完了。然后可以做一些設置,機器人有形象,每個人拿到機器人會說:你是男生還是女生?你晚上睡覺嗎?你有沒有長腳?你今年幾歲?你爸爸是誰?你媽媽是誰?你住在哪里?你問“你是男生是女生”時我回答“我是女生”,可不可以修改?我修改“我是精靈”或者“我沒有性別”,保存。保存以后我還沒有修改,因為我沒有重新建模,我們先來問問看,“你是男生,還是女生?”它還是說“我是女生”。然后“你叫什么名字?”它說“叫小竹子”。我開始問它“明天上海會不會下雨?”“那北京呢?”這上下文代表北京明天會不會下雨,“北京明天有雨”,我再問“那后天呢?”這個上下文,是北京的后天還是上海的后天?應該是北京的后天,因為離北京最近。
然后再來問它一些知識類的“姚明有多高?”它告訴我是“226厘米”,我再問它“姚明的老婆有多高”,“190厘米”,還可以做些推論,例如像“謝霆鋒跟陳小春有什么關系?”這個很少有人知道,謝霆鋒的前妻是張柏芝,陳小春的前女友也是張柏芝,所以陳小春是謝霆鋒前妻的前男友。這是知識推論。還有一些該有的功能,如果很無聊,機器會跟你聊天。你可以更改任何你想要的回答,你可以更改知識圖譜,你可以建立自己的意圖。
來看第二個demo,像多輪對話場景要怎么做?
我先創建一個新的場景,場景的名稱叫“竹間訂餐廳”,觸發條件,什么樣的語句會觸發這個場景?我要新建一個意圖,意圖的名稱叫“訂餐廳”,使用者說“我要訂位”,或者“我要吃飯”。現在有一個訂餐廳的意圖,我只要講“我要吃飯”或者類似的講法,它就知道我要進入這個場景。下一步,訂餐廳有兩個信息,至少要知道時間跟人數,我打算怎么問?我可以有默認的問句“你要選擇的時間是什么?你要選擇的人數是什么?”但這看起來很死板,我可以自定義“請問 您要訂位的時間?請問總共有幾位?”這兩個問句分別抽取時間跟抽取人數,然后再下一步。抽取之后可以有一個外部的鏈接,鏈接到某個地方去幫你訂位。現在選擇回復的方式,“訂位成功,您的訂位時間是**,總共人數是**,謝謝”,儲存,我一行代碼都沒有寫,然后開始測試。
再來看下一個demo,直接用桌面來講,demo訂餐館。為什么訂餐館?因為上個月谷歌demo就是訂餐館,有個機器人幫你到餐館訂位置。我說“我要訂位”,它問我“是什么時間?”我這時候可以回答一個句子給它,可以跟它說“國慶節,我們有大概7、8個人,還帶2個孩子。要是可以的話,幫我訂一個包間,我們7點半左右到,預定8點”“好的”,它只問我一個時間,我回答了這么多東西,有沒有辦法理解?7、8個人是8個人,不是78個人,還帶2個小孩,要是可以的話幫我訂一個包間,所以是包廂,7點半左右到,所以預定8點好了,它有辦法理解。“好的”,我沒有跟它講時間是早上8點還是晚上8點,“晚上8點”,“需要寶寶椅嗎?”“因為我有小孩,所以一張寶寶椅”,問我“貴姓”,我說“富翁”,它幫我訂好了,但沒位置“要不要排號?”“好啊”,我說我有老人,它幫我排了比較方便出入的位置。“信息是否正確”“沒錯”,訂位完成。
我們再試另外一個,“我要訂位”“什么時間?”“后天晚上9點,8個人。”“要包間還是大堂?”“大堂太吵了,包間好了。”我不是用關鍵詞做的,如果用關鍵詞,有大堂 ,有包間,到底是哪一個?還有預定都包廂貴姓,“李”,排號。“有沒有人過生日?是否有誤?”“沒問題”,它就幫我訂好了。一個機器人如果能夠做到這個地步,隨便你怎么講,你不按照順序講,甚至你還可以修正,說“我有8個人,不對,是9個人”,它可以知道你是9個人而不是8個人。
▌人機交互下一步
有幾個案例可以分享:

第一個AIOT的平臺,這個東西目前有一些公司有一些企業在做,舉例來說,我跟我的手環、跟我的音箱、跟我的耳機說我在家里,我跟它說太暗了,太暗了是什么意思?假設今天我家里有很多盞智能燈都已經接到我的平臺上面,所以我跟我的平臺講太暗了,有哪些東西是跟光線有關?我發現窗簾跟光線有關,電燈跟光線有關,我就跑去問說你要開客廳的燈還是廁所的燈還是廚房的燈?這樣問其實非常傻,因為我可能人現在是在客廳,你干嗎要問我這個東西?但是我沒辦法人你到底在哪里?這有幾個解法,我在家里到處都裝攝像頭,我就知道你在哪里,但是這是一件非常可怕的事情,家里裝攝像頭相信里心里不太舒服。
當然過去的技術我多裝幾個WIFI,我裝三個WIFI在你家里三個不同的地方,我利用三角定位知道你人在哪里,我知道你在客廳,你說太暗了,我就把客廳的燈打開,我只要背后都是一個同樣的ALOT的中控中心幫我做這件事情。
另外一個我可能有多種選擇,我說太熱了,太熱了到底要開窗、開空調還是開電風扇?機器問你說我要幫你開電扇還是幫你開空調?你說空調吧,現在太熱,OK,機器人幫你執行,有些時候人的意圖有多種可能性,多個AIOT的家居設備都跟溫度控制有關,機器人可以掌握。當然他會聰明一點,不會有18個跟溫度有關,他一個一個問,最后人會暈倒,這個東西不會太遙遠,我認為在一年半到兩年之內這些東西會出來,甚至一年會出來。慢慢你家里會變成用ALOT的整個平臺跟LOT的設備來幫你管理這些東西,你會生活變得更方便。

第二個人機交互的下一步是人臉+語音的加入,我可不可以根據你人臉知道你是男生女生,你現在的情緒是什么?是長頭發短頭發,有沒有戴眼鏡,有沒有胡子?語音識別當然是最基本的,這個已經非常非常成熟了,可不可以知道這句話到底代表什么意思?語音把它轉變成文本,如果可以的話還可以知道你的語氣,你的語音情緒是憤怒還是悲傷,還是高興?我可以做一些參考,語音的情緒是非常重要的。
這個東西可以使用,我從人臉表情特征可以做什么,特征做了22種,性別、年齡、膚色、頭發、眉頭、顏值,長得漂不漂亮,臉形,特征是給人負面印象是冷酷無情,還是有正面印象你是有一個魅力值信賴的人,這第一印象這東西說不準。表情我們做了九種,喜怒哀樂、驚、懼、厭惡、藐視、困惑、中性。還有人臉的行為分析,我的視線目前是專注還是一直這樣低頭,顯得不自信,還是眼神飄忽不定,這東西是什么意思?
我們來講一個真實的應用的案例。

現在一些新零售,包括無人店,包含一些智慧門店,舉例來說,我們在幫某個電視的大廠在某個賣場剛開業,把我們的技術放進去,同時有五家公司都是在賣電視,包括競爭對手索尼,其他知名的品牌,那個賣場開幕三天,我們做了那家夏普收入是90萬,另外四家加起來40多萬,光夏普一家干掉四家的總和還一倍多。這個怎么做到?第一個可不可以吸引人流?在我的店的門口擺一個屏幕,擺一些東西,你攝像頭,你人經過的時候可以抓住你是男生女生,你的顏值怎么樣?你的情緒怎么樣?非常有趣,所有人經過停下來看,停下來看你是一個四十幾歲的男生,推薦里面有什么優惠活動,你是喜歡的,你是一個20歲的女生,推薦另外的優惠活動。你是一對情侶,是一個家庭帶著小孩,推薦給你的東西不一樣。
大家看到這個東西之后,我進店的人就會有機會比別人多,再來我可以主動式的交互,你走到貨架前面,我看到是一個長頭發的女生主動跟你聊天,一個機器人,一個屏幕,一個平板,這位長頭發的女士你的頭發很漂亮,我這里有一些洗發水,有一些潤發你有什么興趣了解,我根據你的屬性,因為你是女生長頭發,給你推薦某些東西跟你對話,我會跟你說臉上有一些黑斑,我有一些遮瑕膏你要不要?在對話的過程中發現這個人的臉色越來越難看,我趕快停止這個話題,這個東西不應該繼續講下去,是人臉的特征,人臉的情緒跟整個人機交互綜合的應用。
我們也可以做到,我在一些過道上面,這個商場的過道,我知道你的人進到店里面你是怎么走動,我發現你在某一臺電視前面停了五分鐘,停了特別久,你離開了什么都沒有買。兩天后你帶著一家大小來了,這是什么意思?你帶著老婆、帶著小孩上門,這可能代表你要來做決定你是要花錢的,而且我根據你上次的線上購買記錄,因為我知道你的臉部,知道你是誰,知道你的會員編號,我知道你上次買了一臺2萬多塊的冰箱,所以我知道你的消費能力不是那種一兩千塊錢,你可能是兩三萬,我馬上通知銷售員跟他說,這個人來了買電視,因為他兩天前看過某一些電視,而且他的消費能力是以萬來計算的,是萬等級,所以你上去不要推薦他四千塊的電視,你就是往高往貴推薦。也是因為這樣子,我們的賣場,我們的銷售的業績能夠比別人好。這些東西我相信在半年一年內,大家在各種各樣的商場會大量看到。
最后我們舉個例子。今天你們可能說我每個人都有一個機器人,我戴一個手環,手環的背后接我的機器人,我到每個店家也都有一套機器人,麥當勞有一套機器人,肯德基有一套機器人,今天我走進麥當勞,對著我的手環說我喜歡吃巨無霸,大杯可樂去冰,我的機器人聽到以后,我機器人主動去找麥當勞機器人,跟它說我要什么東西,兩個機器人之間的對話,不需要用中文,不需要用人類的語言,他們直接數據格式的交換,機器人有機器人的語言,他們自己交換,交換完以后麥當勞機器人接到這個訂單通知后面,告訴我三分鐘之后過來拿,可不可以這樣子?我的手環告訴我說,三分鐘之后可以過去拿。所以未來真的變成一個機器人世界,每個人都有一個代語,機器人跟機器人去溝通,把這個東西做好。

▌Q&A 時間
今天是我的分享,再下來是交互的時間,各位有什么問題想要問的?有人問一下提一下相關技術,看一下什么相關的技術?如果是圖像的話,圖像最頂尖的公司各位都可以查得到,當然目前比較以安防為主,不管是刷臉門禁,慢慢做到情緒情感的部分。如果是平臺的部分,目前全國做的也差不多有一二十家公司,大家各有它的優缺點,看你是一個封閉的平臺或者是開放的平臺,你找人工智能平臺,語意理解平臺,人工智能機器學習訓練平臺都可以找得到。
1.有人問說出現設定外的情緒機器人能處理嗎?
例如說我的語音情緒做了四種,高興、中性、憤怒跟悲傷,那突然出現一個害怕,語音出現害怕作為分類是分不出來,這是沒辦法處理的。
2.有人問到表情的理解,我大概講一下我們怎么做的?
我們人臉表情光標注,標注了200萬張的照片以上,每張照片三個人標注,三個人都說他是高興,OK,他是高興,三個人說他是悲傷,他是悲傷,三個人意見不一致,我找心理學家來做最后的判斷,你去算一算,200萬張的照片三個人標注,總共600萬人次,你需要多少時間?多少錢?
3.多模態情緒怎么做?
通過人臉表情算出一個分數,語音情緒算出一個分數,文字的情緒算出一個分數,我們背后有兩種模型,第一個規則,人臉表情就是多少分,語音情緒多少分以上,我加成上一個比重,或者說文字情緒算出來,這是一種方式。
另外一種,我們后面用的一個深度學習的模型,我們把這些所有的值標進去算出一個總情緒,當然一樣需要大量的標注數據。
4.有人問對話的答案是能機器人自動合成組合出來嗎?
這是自動生成的范圍,目前來說我認為,我實際上看到正確率大概在3—5成之間,它回答好的大概在3成—5成,有一半的概率不靠譜。
5.知識圖譜學習多少可用?
這個東西看你的領域,如果你是金融領域,金融知識可能12萬、18萬就夠了,如果你是一個醫療領域,可能是幾十萬,但是如果你是聊天的領域,衣食住行、電影、電視這些東西,加起來要800萬—1200萬知識圖譜的數據量。有些公司大企業做搜索引擎的,天生的數據量特別大,知識圖譜可能有8億,有20億,非常非常大量的數據。
6.有人問到說交流的過程中打錯字怎么辦?語音轉文字效果不好,如何提高意圖識別準確率?
在有限的場景之下,這個有辦法做到,像電視就68個意圖,100個意圖,可以做的非常準,真的可以轉成拼音去做,或者真的用一些模糊匹配的方式,可以把匹配的閾值放大一點可以做得好。在一個聊天的場景,有限的場景這個是不可能做得好的。
這其實是包含語音識別在內的,語音識別大家的普通話不一定很標準,像我也是有口音的,所以我語音轉轉文字,可不可以把它轉成拼音,我把平舌、翹舌、前鼻音、后鼻音把它去掉,這樣ch就跟c是一樣的,zh就跟z是一樣的,我用這些方法是做正規化。這些東西尤其在找歌曲的名字、電影的名字、視頻的名字非常有用,因為你歌曲的名字那么長,視頻的名字那么長,電視劇的名字那么長,你不一定講對,我要看《春嬌志明明》,沒有春嬌志明,是《志明與春嬌》,我要看《三生三世》,我知道三生三世十里桃花,我要看半月傳,羋月傳傳那個羋我不會念,我念成半月傳找不到,但是我發現用戶查字典,問了人,下句話他講對了我要看羋月傳,我發現你上面這句話跟下面這句話句型非常非常類似,你上面那句話找不到,下面那句話居然找到了,我可不可以說可能半月傳就是等于羋月傳,自動把它抓出來,做得好由人工判斷,人工做最后的判斷,這些東西就打勾打勾,這些東西是同義詞,一樣就把它輸入進去重新訓練就好了。
7.有人問到對話主題怎么建立?
我這個屏幕有限都是跳著回答,對話主題不算很龐大了,你的主題看你做到幾百種幾、幾千種,主題是有階層次的關系。就是說你的對話主題做出來之后你如何確定這句話是什么主題?當然有關鍵詞,也有機器學習、深度學習的方式都可以去做,而且準確度不會太低。
8.有人說在交流的過程中出現場景之外,怎么做到多輪?
就像剛剛那個我訂酒店機票訂到一半突然說我失戀了,機器人可以怎么回答?機器人可以開始跟你聊失戀的話題,訂酒店就算了,這是一種解法。列另外一種解法,我訂酒店訂到一半失戀了,我跟你說你失戀了好可憐,敷衍你一下,繼續問你說剛剛酒店還沒有訂,你要不要訂?你要不要繼續?我先把前一個場景處理掉,確定你場景已經結束,我才讓你到下一個場景。
9.有人問怎么判斷哪個答案更好?
假設我背后有18個模塊,有20個模塊,有20個模塊都可以出答案,天氣、講笑話、知識圖譜的聊天、各種各樣的場景、訂酒店、訂機票,一樣我一句話進來,我可不可以讓每個模塊舉手,這個模塊說這句話我可以回答,別的模塊說這句話我可以回答,當然每個模塊都會回答,而且每個模塊除了回答以外會有一個信心分數,當然有些模塊我都是100分,跑來搶答案,這個時候就要看你到底靠不靠譜?當然我在我的中控中心,我根據上下文判斷我的情緒,我的意圖,我的主題,我發現說你的對話主題是體育、運動,回答的對話主題是美食,我把這個答案直接丟掉,我發現你的問句是快樂的,回答居然是一句悲傷的句子,直接把它丟掉。我可以利用我的中控中心做這樣的事情,還是沒辦法,有些模塊是亂回答的話,我把它分數降低,它以后宣稱它自己是100分,我都打個八折,以證明它不靠譜。
10.一語雙關的語句可以理解多少?
這個非常難,這個是目前解不了的,現在世界杯,我們舉例,中國乒乓球誰都打不贏,中國足球誰都踢不贏,這兩句話的句型完全一模一樣,但是意思可能是相反的,那這個東西怎么理解?老實話目前還做不到這個地步,不知道五年后、十年后可能有機會,剛剛兩句話你去問一個小學生,其實小學生也搞不懂,你要足夠的社會知識,你有足夠的社會歷練你才知道這句話什么意思。
11.怎么知道機器的回答對不對?
有幾種方法了,有一種還是看人工,我今天機器人回答,這個用戶就生氣了,用戶說你這個機器人好笨,我都聽不懂你在講什么,顯然這個機器人回答不好,我就可以反饋回去說這個回答不對。另外一種,我發現我回答以后,這個用戶決定直接轉人工,假設我是一個智能客服,回答完以后用戶決定轉人工,代表我剛剛的回答肯定是有問題的。第三種是說,我同樣的問題問了第三次,我開戶該帶哪些證件?機器人回答我不滿意,我再問我到底該怎么開戶?再問說開戶到底應該怎么辦?我三個句子不太一樣,其實意思是一樣的,所以今天當問了第三句話,代表我前面的回答一定不對,用戶會問到第三句,基本上靠人的反饋來做。
12.有人問對于學生有什么建議?
在校的學生我的建議是說,你要先想,你現在有很多(01:00:35英文)各式各樣的框架,數據網絡上也都能拿得到,甚至這些代碼都可以直接下載,你就可以做一些基本的東西,這是練習,你最后要解決仍然是真實的問題,你到底要解決什么問題?解決那些問題你打算怎么解?你要設定一個目標,解到使什么地步才是人類可以用的,而不是做一個模型,做一個PPT,這個是不夠的,你越早能夠知道人工智能實際的技術邊界在哪里,什么東西只是一個花俏的東西,什么是東西是真的可以用的,這個對你未來進入職場會有幫助,或者對你未來研究的方向有幫助,畢竟人工智能幫助人,幫助各種各樣的行業,才能夠幫上忙。
13.有人問什么時候機器人可以寫一本中文小說,或者機器人什么時候可以思考?
我覺得還非常非常遙遠,也許十年,也許十五年,機器人的思考方式一定跟人是不一樣的,但是現在機器人都是一大堆的規則,我不覺得機器人是可以思考,甚至有創造力。
14.五年內人工智能的實際應用場景結合最好的方向?
這個我無法預測,人工智能目前都在摸索,我大概可以猜到一年后會有哪些東西?哪些東西是假的,哪些東西不可能實現的,哪些東西是有機會的,一年內我大概可以猜得出來,五年內我猜不出來,因為技術的發展超過我的控制范圍。但是我覺得深度學習、機器學習沒辦法解決NLP,NLP的復雜度不是可以解決的,而且沒有這樣的數據鏈,NLP要解決好也許還出現更新的科技能夠出來。
15.如何斷句,如何分詞?
這樣說好了這其實是一個大的難題,我在黃浦江邊,我是分成黃浦跟江邊,還是黃浦江跟邊,你好可愛,是你好、可愛還是你好加可愛,我們先不要講長句,光這個短句分可能分錯,有時候你好在一起,有時候你好要分開,這個東西只能說我拿現在的東西,我再去不斷不斷優化,而且有可能說,我們累積好幾萬的bug,我去看這些bug我可能用新的模型來解,新的bug可能用新的算法來解,一群一群去解這些問題,才能慢慢前進,這個沒有什么快速的方法。
-
人機交互
+關注
關注
12文章
1200瀏覽量
55321 -
人工智能
+關注
關注
1791文章
46859瀏覽量
237580
原文標題:人機交互如何改變人類生活 | 公開課筆記
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
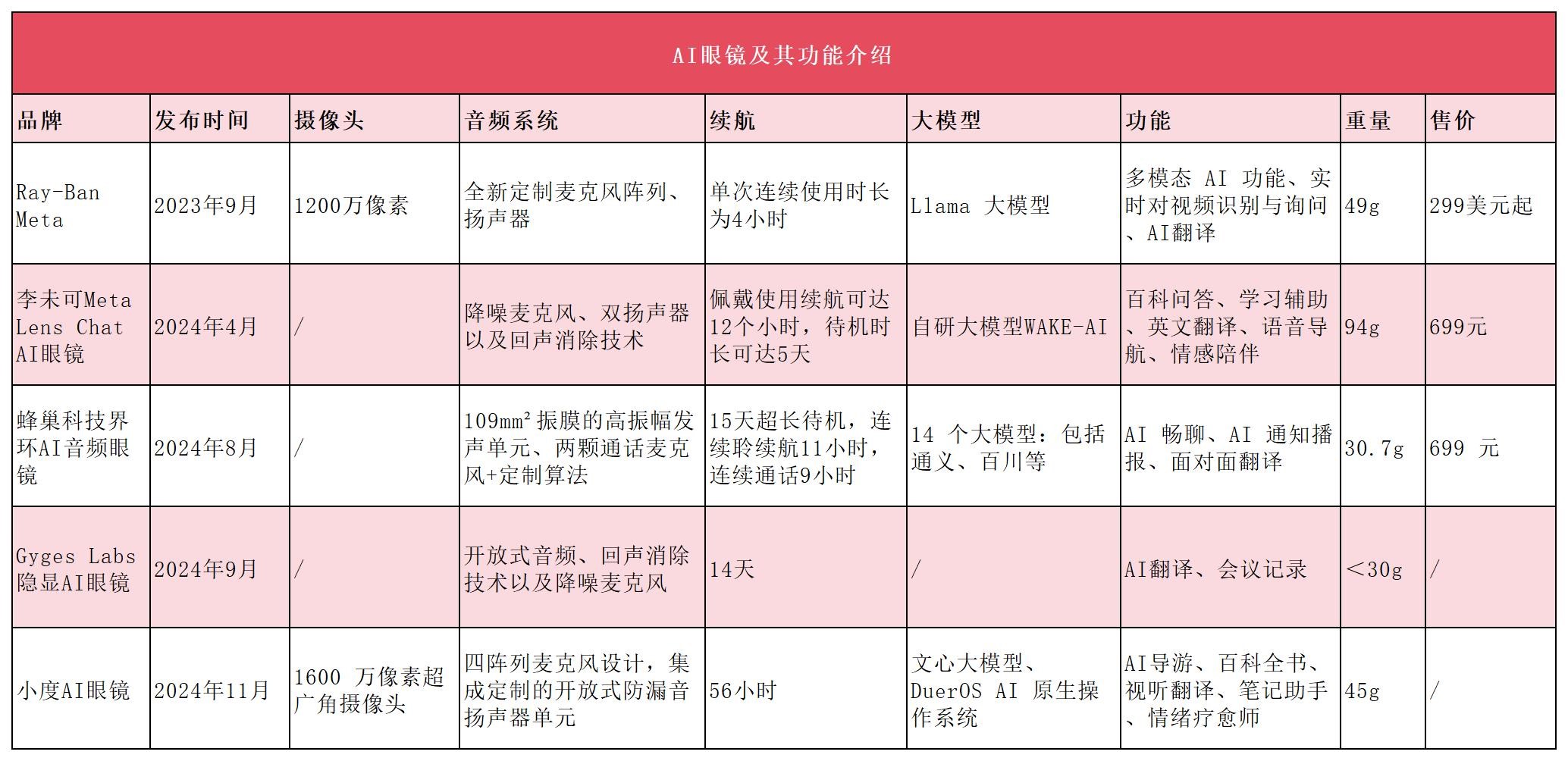
新的人機交互入口?大模型加持、AI眼鏡賽道開啟百鏡大戰
具身智能對人機交互的影響
DJN人機交互解決方案
基于傳感器的人機交互技術
人機界面交互方式的介紹
人機交互界面是什么_人機交互界面的功能
工業平板電腦在人機交互中的應用
人機交互與人機界面的區別與聯系
芯海科技“壓容二合一SoC”系列芯片打造極致人機交互體驗

人機交互系統的發展史及過程步驟





 工商網監
工商網監
評論