 OpenAI最新提出的可逆生成模型Glow
OpenAI最新提出的可逆生成模型Glow
OpenAI最新提出的可逆生成模型Glow,可以使用相對少的數據,快速生成高清的逼真圖像,具有GAN和VAE所不具備的精確操作潛在變量、需要內存少等優勢。
OpenAI剛剛在博客介紹了他們的最新成果——Glow,一種使用可逆1x1卷積的可逆生成模型。
Glow 可以生成逼真的高分辨率圖像,支持高效采樣,并且可以自動學習圖像中屬性特征,比如人的五官。
先來看效果,加了胡子的Hinton,笑容調到最高,眼神也看起來更亮:
下圖是使用Glow操縱兩名研究人員面部圖像的屬性。模型在訓練的時候并沒有給出眼睛、年齡等屬性標簽,但自己學習了一個潛在空間,其中某些方向對應胡須密度,年齡,發色等屬性的變化。
人臉混合過度的效果也十分自然:
這是使用30,000個高分辨率面部數據集進行訓練后,Glow模型中的樣本,可以說很逼真了。如果不說明,應該有不少人會覺得是真人照片。
再放大來看,這個效果至少是不輸給GAN的:
Glow模型生成一個256x 256的樣本,在NVIDIA 1080 Ti GPU上只需要大約130ms。使用 reduced-temperature模型采樣結果更好,上面展示的例子是溫度0.7的結果。
數據利用率高,可泛化,優于GAN和VAE
Glow是一種可逆生成模型(reversible generative model),也被稱為基于流的生成模型(flow-based generative model)。目前,學界還很少關注基于流的生成模型,因為GAN和VAE這些顯而易見的原因。
OpenAI的研究人員在沒有標簽的情況下訓練基于流的模型,然后將學習到的潛在表示用于下游任務,例如操縱輸入圖像的屬性。這些屬性可以是面部圖像中的頭發顏色,也可以是音樂的音調或者文本句子的情感。
上述過程只需要相對少量的標記數據,并且可以在模型訓練完成后完成(訓練時不需要標簽)。使用GAN的工作需要單獨訓練編碼器。而使用VAE的方法僅能確保解碼器和編碼器數據兼容。Cycle-GAN雖然可以直接學習表示變換的函數,但每次變換都需要進行重新訓練。
訓練基于流的生成模型操縱屬性的簡單代碼:
Glow的具體操作過程
OpenAI研究人員表示,這項工作是建立在非線性成分估計(Dinh L. et, NICE: Non-linear Independent Components Estimation)和RealNVP(Dinh L. et, Density estimation using Real NVP)的基礎上。
他們的主要貢獻是增加了可逆的1x1卷積,并且刪除了RealNVP的其他組件,從而簡化了整體架構。
RealNVP架構包含兩種類型的層:一種是有棋盤格masking的層,一種是有channel-wise masking的層。OpenAI去掉了前一種棋盤格masking,簡化了整體結構。
在Glow模型的工作中,具有channel-wise masking的層不斷重復下列步驟:
通過在channel維度上反轉輸入的順序來置換輸入。
將輸入在特征和維度的中間分為A和B兩部分。
將A輸入一個淺層的卷積神經網絡,根據神經網絡的輸出線性變換B
連接A和B
將這些層鏈接起來,讓A更新B,B更新A,然后A再更新B,以此往復。這種雙向信息流非常rigid。研究人員發現,通過將步驟(1)的反向排列改變為(固定的)shuffle 排列還能改善模型性能。
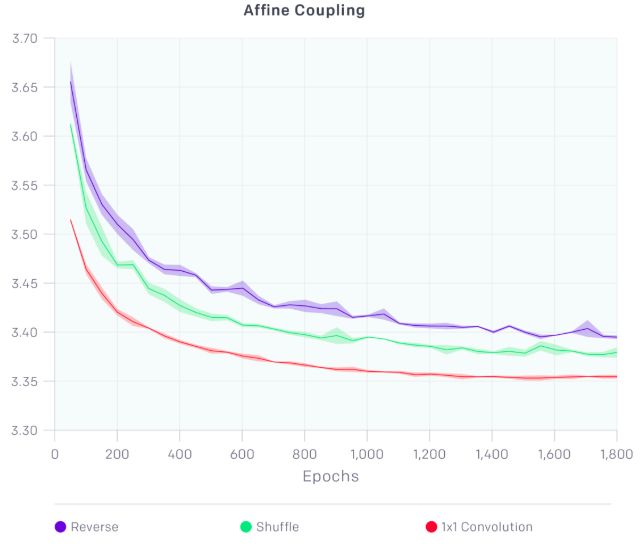
使用1x1卷積的效果要顯著好于逆轉和Shuffle
此外,他們還將批歸一化(BN)換成了一個激活歸一化層(activation normalization layer)。這個層能夠轉變和放大激活。因此,能將大圖像最小的批量大小縮小到1,并擴大模型的大小。
這個架構結合了多種優化,例如梯度檢查點(gradient checkpointing),使研究人員能夠比平常更大規模地訓練基于流的生成模型。他們還使用Horovod在多臺機器的集群上訓練模型,上面演示中使用的模型在5臺機器上訓練,每臺有8個GPU。使用這種設置,他們訓練了具有超過一億個參數的模型。
基于流的生成模型,大有可為!
OpenAI研究人員表示,他們在這項工作中表明,可以訓練基于流的模型(flow-based)來生成逼真的高分辨率圖像,并且學習可以輕松用于下游任務(如數據操作)的潛在表示。
基于流的生成模型有以下優點:
精確的潛變量推斷和對數似然估計。在VAE中,只能近似推斷出與某個數據點相對應的潛在變量的值。GAN則根本沒有編碼器來推斷潛伏變量。但是,在可逆生成模型中,不僅可以實現準確的潛在變量推理,還可以優化數據的對數似然,而不是只是其下限。
高效的推理和有效的合成。自回歸模型,例如PixelCNN,也是可逆的,但是這些模型的合成難以并行化,往往在并行硬件上效率很低。基于流的生成模型,比如Glow和RealNVP,可以有效地進行推理與合成的并行化。
下游任務的有用潛在空間。自回歸模型的隱藏層邊際分布式未知的,因此很難進行有效的數據操作。在GAN中,數據點通常不能直接在潛在空間中表示,因為它們沒有編碼器,可能不完全支持數據分布。但可逆生成模型和VAE,就能進行數據點之間的插值,對現有數據點進行有意義的修改等操作。
節省內存的巨大潛力。如RevNet論文所述,在可逆神經網絡中計算梯度需要的內存是固定的,不會隨著深度的增加而增加。
他們建議未來可以繼續探索這兩個方向:
自回歸模型和VAE在對數似然性方面比基于流的模型表現更好,但它們分別具有采樣低效和推理不精確的缺點。未來,可以將基于流的模型、VAE和自回歸模型結合起來,權衡彼此優勢,這將是一個有趣的方向。
改進架構來提高計算效率和參數效率。為了生成逼真的高分辨率圖像,面部生成模型使用200M規模參數和大約600個卷積層,這需要花費很高的訓練成本。深度較小的模型在學習長時間依賴(long-range dependencies)方面表現較差。使用self attention結構,或者用漸進式訓練擴展到高分辨率,可以讓訓練流模型的計算成本更低。
-
圖像
+關注
關注
2文章
1083瀏覽量
40418 -
GaN
+關注
關注
19文章
1922瀏覽量
73052 -
數據集
+關注
關注
4文章
1205瀏覽量
24649
原文標題:超越GAN!OpenAI提出可逆生成模型,AI合成超逼真人像
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
OpenAI的研究者們提出了一種新的生成模型,能快速輸出高清、真實的圖像
字節跳動否認借助OpenAI技術研發大模型,已刪除GPT生成數據
OpenAI發布首個視頻生成模型Sora
OpenAI推出新款大模型Sora,引領多模態AI新潮流
奧特曼發布王炸模型Sora OpenAI首個文生視頻模型Sora正式亮相
OpenAI發布文生視頻模型Sora,引領AI視頻生成新紀元
OpenAI發布文生視頻大模型Sora、英偉達市值超谷歌
OpenAI新年開出王炸,視頻生成模型Sora問世
OpenAI發布Sora模型,瞬間生成高清大片
openai發布首個視頻生成模型sora
OpenAI新推文生視頻大模型Sora引發熱議,首批受益者涌現
OpenAI文生視頻模型Sora要點分析

OpenAI 在 AI 生成視頻領域扔出一枚“王炸”,視頻生成模型“Sora”






 工商網監
工商網監
評論