 在多個異構數據集上進行訓練并可開發它們的語義層次結構
在多個異構數據集上進行訓練并可開發它們的語義層次結構
摘要:我們提出了一種帶有分層分類器的卷積網絡,可針對每個像素進行語義分割,能夠在多個異構數據集上進行訓練并可開發它們的語義層次結構。我們的網絡是第一個同時在智能交通工具領域的三個不同數據集(即Cityscapes,GTSDB和Mapillary Vistas)上訓練的網絡,并且能夠處理不同的細節語義級別、類別不平衡和不同的注釋類型,即密集的每像素和稀疏的邊界框標簽。我們通過與平面,非等級分類器進行比較來評估我們的分層方法,并且我們顯示Cityscapes類的平均像素精度為13.0%,Vistas類為2.4%,GTSDB類為32.3%。對于在GPU上運行的108個類,我們在520 x 706的分辨率下實現了17 fps的推理速率。
作者:Panagiotis Meletis and Gijs Dubbelman
第一節,介紹:
隨著深度學習技術的發展,按照像素分類提出的分割任務在過去幾年中取得了很大進展[2],語義分類成為自動駕駛汽車感知子系統中的一項關鍵任務。然而,兩個關鍵挑戰仍然需要解決:1)盡可能多地利用各種訓練數據; 2)將可識別類的數量從幾十個增加到幾乎任何場景可以包含的內容。
在這項工作中,為了解決這兩個挑戰,我們積極采取措施并提出一種方法,利用具有不同類和注釋類型的多個異構數據集,來訓練一個完全卷積網絡進行每個像素語義分割。這種方法有助于更好地使用可用數據集,從而減少注釋工作量,并增加可識別的類的數量。我們在高度自動駕駛(HAD)環境中使用的數據集是Cityscapes[3],Mapillary Vistas [4]和GTSDB [5]。
第一個挑戰,即對具有不同注釋的語義分段的訓練,在先前的工作[6][7]中一般會通過外部組件到網絡中進行處理,以便生成偽的每個像素基礎事實。相比之下,我們的方法是自包含的,使用網絡自身的輸出來細化不兼容的、多樣的注釋以進行監督。
第二個挑戰,即增加可識別類的數量,可以通過兩種方式來完成: 1 )用額外(子)類(例如[8] )繼續按像素注釋現有數據集;2 )僅對新(子)類使用現有輔助數據集。第一種方法對于大數據集來說可能非常昂貴,并且是不必要的,因為存在大量具有細粒度(子)類的數據集(例如交通標志類型、汽車模型、行人)。
圖1.我們在推理過程中的層次分類卷積網絡。輸入圖像被轉換為共享特征表示,其通過適配子網連接到分類器的層次結構。Level-1分類器輸出對圖像的每個像素的預測,而每個后續分類器僅推斷其自己的一組類。將所有級別的輸出進行組合,形成最終的細粒度每像素分割。
在我們的工作中,我們研究的是第二種方法。為此,數據集的異質性(即不同的標簽空間和注釋類型)對于將它們與傳統的“平面”(即非分層的)分類器組合提出了挑戰。因此,我們建議使用分層分類器,它明確地利用數據集之間的語義關系,并與平面分類器進行比較。我們的層次結構與[9][10]相當,但它提供的可擴展性不同。
在第二節,我們描述了我們的分層方法所解決的確切挑戰。一個例子是Cityscapes和GTSDB的綜合培訓。在這種情況下,所有GTSDB類都是Cityscapes中交通標志類的子類。在傳統的平面分類器中直接結合兩個數據集的類的簡單方法是不可行的,因為一個交通標志像素不能根據它來自的數據集有不同的標簽。這給平面分類器的端到端訓練和推理帶來了挑戰,而我們的分級分類方案可以解決這些挑戰。
第三節我們提供了一般分層方法的基本原理;第四節我們提供了實施的細節;在第五節,我們演示了使用三個異構數據集的層次分類器的性能增益,而不是使用平面的、非層次的分類器。此外,我們展示了使用我們提出的方法可對公共特征表示進行多數據集訓練可以提高所有數據集的性能,而不管它們的結構差異如何。
綜上所述,本研究對每個像素語義分割的貢獻如下:
一種對數據集進行組合訓練的方法,該數據集具有分離但語義相連的標簽空間。
分層分類器的模塊化體系結構,可以取代現代卷積網絡中的分類階段。
我們的系統實施可供研究界[11]使用。此外,我們為GTSDB交通標志子類提供了Cityscapes數據集的每個像素注釋,我們將其用于驗證目的,但不需要進行訓練。在本文中,我們將此數據集稱為Cityscapes Extended。
第二節,來自多個數據集訓練的挑戰
由于數據集的結構差異,對多個數據集的端到端監督訓練可能面臨許多挑戰。其中最重要的挑戰可分為以下幾類:
語義層面的細節:每個數據集都標有一組語義類。在樸素平面分類方法中,分類器的輸出將是來自所有數據集的類的聯合。一個數據集中的類的語義很可能包含在另一個數據集的類的語義中。如果這些類被放置在相同的級別上,就像在平面分類器中一樣,則會發生監督沖突,因為屬于同一語義類的一些像素將被標記為不同的類。
對于我們的三個數據集來說,這一挑戰出現在三種情況下: 1 ) Cityscapes將其道路等級定義為“汽車通常行駛的部分地面”,包括車道標記、自行車道、坑洼等。在Vistas中,除了道路類之外,這些細粒度的子類被單獨標記,導致標簽的語義細節層次的沖突。2)Cityscapes和Vistas包含一個高級交通標志類,而GTSDB有43個交通標志子類。3)Cityscapes只有一個騎手類,而Vistas區分三個不同的騎手子類。如圖2所示,引入標簽層次結構有效地解決了這一挑戰,將在第三節A部分中更詳細地討論。
注釋類型:根據定義,語義分割是每個像素的問題,因此必須在像素級提供監督。不幸的是,許多現有數據集具有邊界框或每個圖像注釋,這對于每個像素訓練是不兼容的。使它們兼容的直接方法是將這些注釋轉換為掩碼。然而,這些掩碼將包括不屬于感興趣對象的像素,例如,邊界框可能包含許多非相關的背景像素,這些像素將被分配給前臺類。最終,在訓練期間,對網絡的監督將從錯誤標記的像素流出,導致權重混亂。
在我們的例子中,Cityscapes和Vistas有每個像素注釋,但GTSDB只有邊界框注釋。為了將GTSDB包含在訓練中,我們提出了一種新的層次損失,它在第三節的D部分中提供,統一處理來自不同注釋類型的監督。
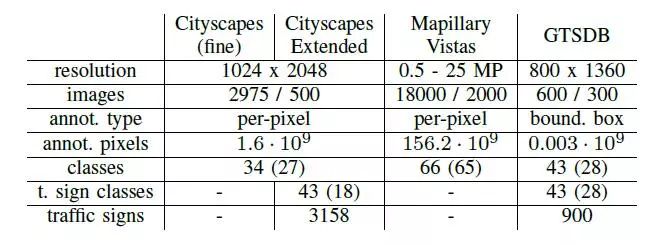
訓練樣本不平衡:批量訓練受到類別不平衡的影響,特別是當每批次的例子有限時。在我們的例子中,我們面臨著強大的數據集內和數據集間的不平衡。數據集之間的不平衡是由于注釋像素的巨大差異造成的,例如,以103的順序(詳見表一)。相同數據集的類之間的不平衡在街道場景數據集中是常見的,因為大多數像素都屬于大型表面的類,比如道路和建筑物。我們的方法通過在相同的分類器中放置具有相似的示例順序的類來處理不平衡,因此所有類具有更大的概率在同一批次中表示。這種策略非常有益,如第五節的E部分有所展示。
第三節,利用語義層次結構培養和推斷異構數據集
在本節中,我們描述了針對任意數量的異構數據集的一般分層分類方法的組件。這些組件為第二節的挑戰提供了解決方案,并為每一個組件提供了我們所選擇的數據集的具體情況。我們目前的實驗,詳見第五節,是基于使用3個數據集的具有3級層次結構的實現。第四節中提供了此實現的細節。
A.標簽空間的語義層次結構
多個數據集訓練需要為所有選定的數據集提供一個公共標簽空間。我們建議將單獨的標簽空間合并到公共空間中,其中包含來自所有數據集的標簽,通過分層的方式合并到標簽的語義樹中。這種方法通過引入必要的父節點或中間節點和/或現有標簽的分組來解決標簽語義定義中的任何沖突。
圖2描繪了使用本文三個選定數據集的所有標簽的3級層次結構。第二節中介紹了將這三個標簽空間組合起來所帶來的挑戰,解決辦法如下: 1)引入了一個新的高級驅動類來解決Cityscapes和Vistas道路類語義沖突,2)增加了一類超級交通標志和一個中間節點,用于區分Vistas和前方交通標志,3)引入了一個騎手超類,包括Cityscapes騎手類和3 Vistas騎手子類。
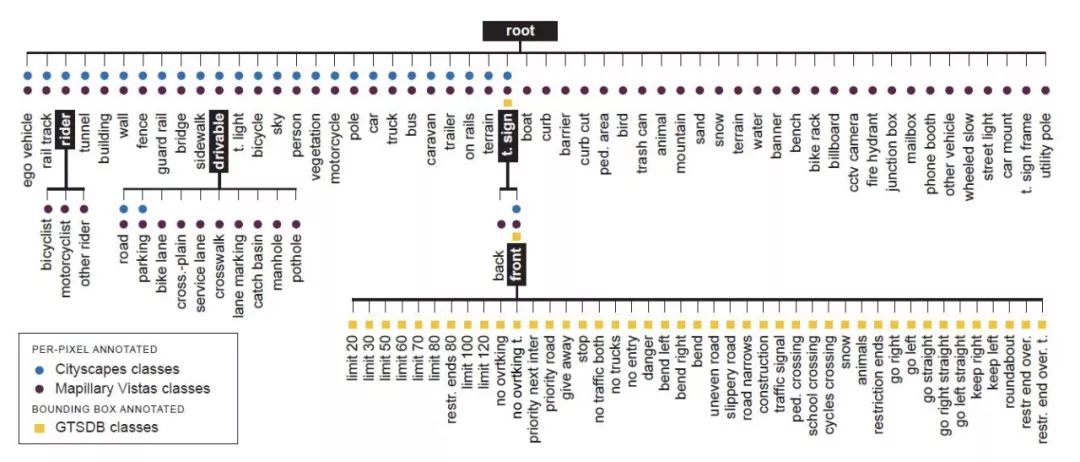
圖2.三級語義標簽層次結構,結合了來自Cityscapes,Mapillary Vistas和GTSDB數據集的108個類。標記為黑色的類別對應于圖1的L1,L2和L3分類器。
標簽的語義層次結構引起相應的分類器層次結構。每個分類器都對一個節點的子標簽進行分類,并且對整個分類器樹進行訓練,以一種端到端、完全卷積的方式對共享的特性表示進行訓練。
B .卷積網絡體系結構
所提出的網絡架構(例如,參見圖1)包括用于計算密集的共享表示的完全卷積特征提取器和一組分類器,每個分類器對應于語義層次的內部類節點。每個分類器都可以與層次結構中一級向下的分類器連接,以便將其預測傳遞給推理和注釋類型獨立訓練,如第三節中CD部分所述。每個分類器之前可以有一個淺適應網絡,它使共同表征、深度和接受域適應分類器的需要。這使網絡設計人員有機會為每個分類器選擇不同的特性維度和接受域。例如,區別交通標志比較容易[12],因為與高級別區別相比,需要較少的特征,如道路對人行道和灌木叢對樹木[ 3 ]。根據分類器的對象平均大小,將不同的視圖字段應用到不同的分類器上具有一定的靈活性,可以或多或少的實現上下文聚合,例如,交通標志通常比建筑物或汽車更小。
C.推理:分層決策規則
在softmax分類器樹中,以分層方式按像素進行推斷。為自己的一組像素集p∈Pj和一組類Cj= {0,1….}每個分類器j計算類概率的每個像素的歸一化向量σj,p,以及輸出每像素的決定
yj,p^=argmaxiσij,p,這里yj,p^∈Cj。這一組每個分類器都必須為此做出決定的Pj,由其父代根據自己的決定生成。來自可用的標簽集{y^j,p}j∈J,輸入的每個像素都標有所需的細節,其中J是為這個特定像素生成決策的分類器。
D.訓練:等級分類損失
如第二節所述,許多數據集的注釋類型與語義分割所需的每個像素監督是不兼容的。我們提出的方法是使用統一的方法處理不兼容的注釋,不需要外部組件,如[6][7],并且對系統的計算負荷可以忽略不計。處理各種基本事實的靈活性與根分類器上的類的唯一約束交換,應該具有每個像素注釋的示例。任何其他級別的注釋可以是任何類型的,甚至可以是混合的。
我們提出了分級分類損失,它將監視與像素級的注釋類型分離開來。每個分類器j在所有標記像素Pj=Pj1 +PJ2上訓練,所述標記像素對應于標簽層級中的其相應節點。使用標準的單熱交叉熵損失訓練具有每個像素注釋的像素Pj1。為了實現這一點,我們的方法在訓練過程中使用父分類器的在線、每個像素的決定,來細化偽每個像素的標簽。該過程如圖3所示。首先,將不兼容的注釋轉換為每個像素偽地面實況。
圖3.訓練期間的在線程序,用于從邊界框標簽生成每像素地面實況。
然后,在每個訓練步驟中,父分類器的決定與該偽基礎事實相交,以產生用于監督的每像素地面實況。
兩種損失都按照分類器累積到所謂的等級損失:
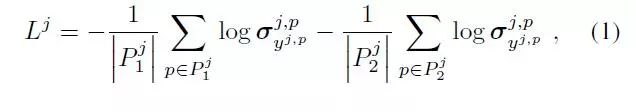
其中|·|是像素集的基數,并且yj,p∈Cj為分類器j選擇對應于像素p的地真類的σ元素。最后,收集所有分類器的損失并用不同的超參數j加權,以獲得最小化的總目標:
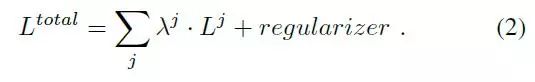
第四節,具有CITYSCAPES,MAPILLARYVISTAS和GTSDB的的三級標簽層次結構
在本節中,我們概述了實現細節,以提高我們實驗的可重復性。
卷積網絡架構:網絡如圖1所示。特征提取器由ResNet- 50架構[ 13 ]的特征層和1 x1卷積層(具有ReLU和批處理規范化)組成,以將特征維數減少到256。使用擴張的卷積,輸入上的步幅從32減小到8。該表示具有深度256,空間維度1/8的輸入,并在5個分支中共享。每個分支都有一個額外的瓶頸模塊[ 13 ],并以一個softmax分類器結束,該分類器包括一個混合上采樣模塊。我們選擇每個分類器適配子網的特征維度和視野對于所有分支是相同的。在實驗了不同的上行采樣技術(分步卷積、雙線性、卷積)后,我們得出結論,通過混合上采樣獲得最佳性能和減少偽像,其中包括一個2x2可學習的分數跨度卷積層,然后是雙線性上采樣以達到輸入維度。
實施細節:我們使用Tensorflow[14]和Titan X(Pascal架構)GPU進行訓練和推理。由于內存有限,我們將批量大小設置為4(Cityscapes:Vistas:GTSDB = 1:2:1),將訓練尺寸設置為512x706(Vistas圖像的平均值縮放到較小的Cityscapes維度)。在訓練期間,按照原長寬比縮小圖像,然后隨機裁剪。該網絡針對17個Vistas時期(早期停止)進行訓練,,隨機梯度下降,動量為0.9,L2權重正則化,衰減為0.00017,初始學習率為0.01,三次減半,批量標準化和指數移動平均衰減均設為0.9。將Eq的超參數λj分別選擇為1.0、0.1和0.1,分別用于三個層次的層次結構。作為推論,我們目前達到17 fps的幀速率,即每幀58毫秒。
第五節,評價
我們進行以下實驗來評估我們的分級分類方法:
1 )平面分類基線:設置用于單數據集和多數據集訓練的平面分類器基線。
2 )三個異構數據集的分層分類:演示了我們的完整方法在三個異構數據集(Cityscapes、GTSDB、Vistas )上進行組合訓練的好處,這些數據集具有不相交的標簽空間和不同的注釋類型。
3)Cityscapes Extended上的分層與平面分類:通過在具有兩級標簽空間的每像素注釋Cityscapes Extended數據集上隔離它來驗證我們的分層方法對極不平衡類的有效性。
A.數據集
我們總結了表I中使用的數據集。接下來,我們將描述實驗所需的額外注釋。請注意,這些注釋僅用于驗證目的,而不用于訓練網絡。
1)用交通標志類標記城市景觀:我們使用GTSDB的43個交通標志類擴展了Cityscapes的標簽空間。Cityscapes只提供每個像素的交通標志注釋,而不區分實例。我們設計了一種基于8鄰域距離的自動分割算法,用于分離地面真實交通標志遮罩中連接的交通標志實例,并設計了一個GUI應用程序,提出了用于標注的圖像區域。我們把原來的和新的注釋打包成Cityscapes Extended的名字。該數據集分別包含列車中的2778個和380個交通標志以及驗證拆分。
2)用每個像素標簽標注GTSDB:只有在涉及平面分類器的特定實驗中,我們才使用交通標志形狀(圓形、三角形、六邊形)將GTSDB邊界框注釋轉換為精細的每個像素注釋。這個程序對于交通標志的面內旋轉可能是有問題的,但是在數據集檢查之后,我們觀察到只有很少的面內旋轉存在。
表一
數據集統計。圖像包含訓練和驗證拆分。在括號中顯示了被評估的類的數量。
表二
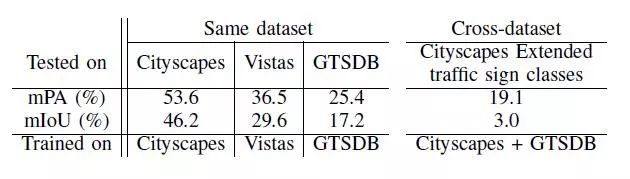
對每個像素注釋數據集的平面分類性能基線。
B.度量和評估慣例
我們使用多類平均像素精度(mPA)和聯合的平均交叉點(mIoU),它們與自動駕駛相關,它們代表了先進的地方和地區的標準,遵循了[ 15 ]中給出的定義。對于Cityscapes,我們報告了27個課程的結果(官方基準測試中的19個和Vistas中常見的8個)。對于交通標志類,我們評估滿足兩種條件的43個交通標志的子集:1 )在GTSDB訓練集中具有少于103個像素。2) GTSDB和Cityscapes擴展驗證集的像素都小于103像素。請注意,我們選擇了103像素的限值,因為它比Cityscapes中最少代表的類要小2個數量級。對于Vistas,我們報告關于官方65級基準的結果。最后,我們每隔一個時期評估模型的性能,并報告最近兩次運行的平均值。
本文介紹了一種新的公平比較評價的協議,該協議僅適用于第五節的C部分的實驗,該實驗是在兩個數據集上訓練平面分類器。它解決了高級別交通符號類與交通符號子類相同級別的語義沖突(第二節)。交通標志像素的判定是正確的:1)如果正確標注了任何交通標志子類, 2)如果它被標記為交通標志,第二個最可能的選擇是正確的交通標志子類。為清楚起見,我們不將此評估方案用于分層分類器,而僅用于扁平分類器。
C.平面分類的基線
在表二中,我們為傳統的平面分類方法設置了相同和跨數據集的基線,使用第四節中描述的實現細節中相同的輸入維度和批量大小,為了能夠與表三的分層結果進行公平比較。在第1 – 3列中,我們在三個數據集上獨立訓練三個模型,并為表一的評估類提供結果。在第4欄中,我們提供了聯合訓練Cityscapes和GTSDB的Cityscapes Extended交叉數據集結果。
為了進行公平的比較,第3和第4列的模型是通過GTSDB數據集的生成的每個像素注釋來訓練的(詳細細節請參見第五節A2部分)。由于每個圖像的訓練像素數量有限,因此43類GTSDB的訓練不會收斂,因此我們將未標記的像素作為額外的類包括在內,以解決此問題。可以觀察到,Cityscapes和GTSDB的同時訓練未能在Cityscapes Extended的交通標志類別上獲得令人滿意的跨數據集結果。
表三
4種數據集中完全分層分類方法的表現。
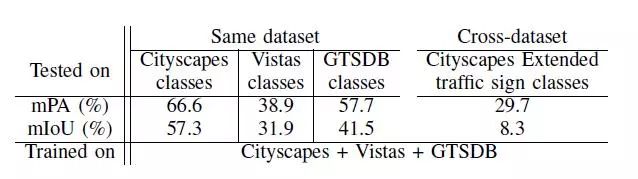
圖4.Cityscapes val拆分圖像示例。網絡預測包括來自層次結構的L1-L3級別的決策。請注意,地面實況僅包括一個交通標志超類(黃色)且沒有道路屬性標記。
D. 3個異構數據集的層次分類
該實驗評估了我們在三個異構數據集(Cityscapes,Mapillary Vistas和GTSDB)上的完整層次分類方法。在表三中,我們提供了關于模型訓練的三個數據集的驗證分割的評估結果(第1-3列)和Cityscapes Extended(第4列)上的交通標志子類的結果,這在訓練期間未使用。在圖4、5、6中描述了定性結果。
對于所有數據集,通過比較表二第1-3列和表三第1-3列,我們實現了平均PA(在+ 2.4%至+ 32.3%范圍內)和IoU(在+ 2.3%至+ 24.3%范圍內)的顯著性能提升。通過比較表二第4列和表三第4列,我們還觀察到交通標志子類的交叉數據集性能的增加。值得注意的是,該模型未經過Cityscapes Extended交通標志類別的任何示例訓練,平均PA增加10.6%僅僅是由于我們的分層多數據集訓練方案的結果。我們得出結論,當數據集具有不同的類,不同的注釋類型以及數據集內和數據集之間的不平衡時,層次分類對于組合的異構數據集訓練非常有利。
E. Cityscapes Extended的層次分類與平面分類
在本實驗中,我們使用每像素注釋和兩級標簽空間評估Cityscapes Extended上的層次分類方法。我們的目標是將我們的方法隔離在一個數據集中,以顯示它在高度不平衡的數據集中對平面分類的有效性。我們使用512 x 1024輸入尺寸,批量為2。
圖5.Mapillary Vistas驗證分割圖像示例。網絡預測包括來自層次結構的L1-L3級別的決策。請注意,基本事實不包括交通標志子類。
圖6.GTSDB測試分割圖像示例。網絡預測包括來自層次結構的L1-L3級別的決策。請注意,基本事實僅包括交通標志邊界框,因為其余像素未標記。
從表IV中,我們觀察到相對于平面分類器的mPA(+ 26.0%)和mIoU(+ 16.1%)層次分類顯著增加了L2類(即GTSDB交通標志子類),而對于L1類(即Cityscapes類) mPA和IoU的增幅均超過+ 6%。
我們得出的結論是,即使是在單個數據集中使用每個像素的注釋,分層分類對于類的不平衡是穩健的,因為它在每個級別的類中都有相同的示例順序。
表四
在Cityscapes Extended上的平面與建議的分級分類性能。(在括號內表現為交通標志L1類)。
第六節,結論與未來工作
在本論文中,我們考慮了對三個異構但語義相連的數據集進行同時訓練的挑戰,以解決每個像素的語義分割問題。主要動機是最大限度地重用資源(數據集和計算)并消除人類標記工作。為了實現這一點,我們利用數據集標簽之間的語義關系來構建分類器的層次結構,并介紹相應的分層訓練和推理規則。我們最終的網絡可以將一個輸入圖像從8個高級的街道場景類別中分成108個類。結果表明,采用層次分類方法進行多異構數據集訓練具有明顯的優越性。在未來的工作中,我們將擴展我們的成果,包括更多具有更多不同特征的數據集,以展示我們方法的可擴展性。
-
數據集
+關注
關注
4文章
1197瀏覽量
24532 -
自動駕駛
+關注
關注
781文章
13449瀏覽量
165251 -
深度學習
+關注
關注
73文章
5422瀏覽量
120587
原文標題:IEEE IV2018論文:基于多異構數據集的卷積網絡街道場景語義分割
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NLPIR大數據語義智能分析平臺先精準分詞才語義分析
NLPIR語義分析是對自然語言處理的完美理解
一個benchmark實現大規模數據集上的OOD檢測
一種從零搭建汽車知識的語義網絡及圖譜思路
基于本體的多源異構數據集成方法研究
DeepLab進行語義分割的研究分析
語義分割數據集:從理論到實踐

PyTorch教程-13.5。在多個 GPU 上進行訓練






 工商網監
工商網監
評論