 超分辨率神經網絡原理
超分辨率神經網絡原理
在 AlphaGo 對弈李世石、柯潔之后,更多行業開始嘗試通過機器學習優化現有技術方案。其實對于實時音視頻來講,對機器學習的研究已有多年,我們曾分享過的實時圖像識別只是其中一種應用。我們還可以利用深度學習來做超分辨率。我們這次就分享一下用于超分辨率的深度學習基本框架,以及衍生出的各種網絡模型,其中有些網絡在滿足實時性方面也有不錯的表現。
機器學習與深度學習
對于接觸機器學習與深度學習較少的開發者,可能會搞不清兩者的差別,甚至認為機器學習就是深度學習。其實,我們用一張圖可以簡單區分這個概念。
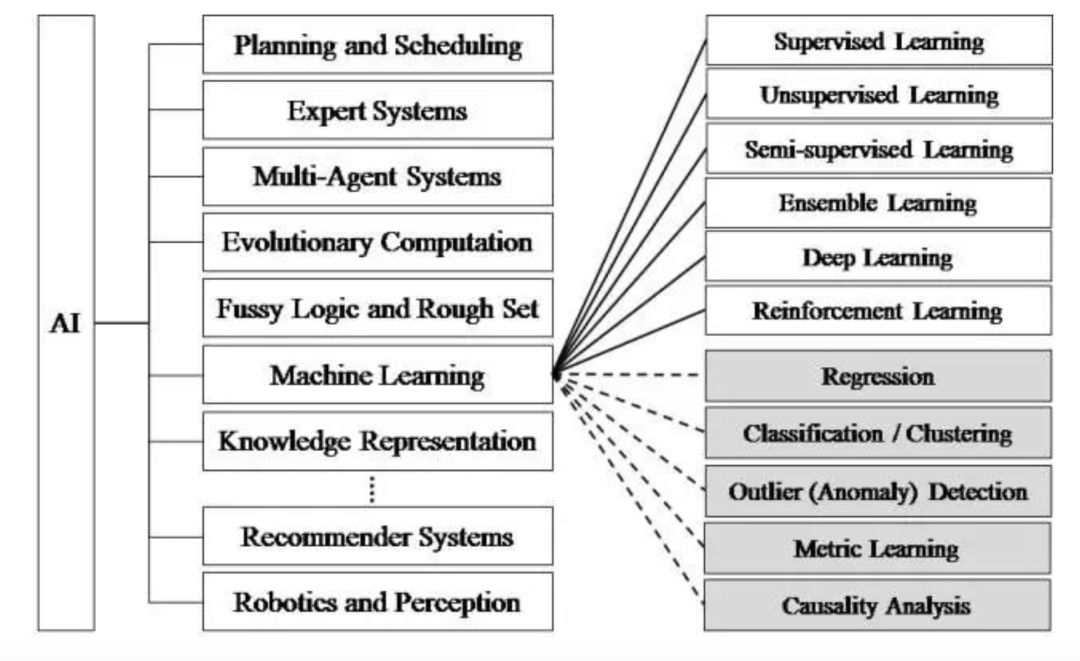
上世紀50年代,就有人工智能的概念,后來也有一些較基礎的應用,比如國際象棋。但到了70年代,由于硬件性能的制約,以及訓練數據集的匱乏,使得人工智能經歷了一段低谷。人工智能包括了很多,比如機器學習、調度算法、專家系統等。到了80年代才開始出現更多機器學習的應用,比如利用算法來分析數據,并進行判斷或預測。機器學習包括了邏輯樹、神經網絡等。而深度學習,則是機器學習中的一種方法,源于神經網絡。
超分辨率是什么?
超分辨率是基于人類視覺系統提出的概念。1981年諾貝爾醫學獎獲獎者David Hubel、Torsten Wiesel,發現人類視覺系統的信息處理方式是分層級的。第一層是原始的數據輸入。當人看到一個人臉圖像時,首先會先識別出其中的點、線等邊緣。然后進入第二層,會識別出圖像中一些基本的組成元素,比如眼睛、耳朵、鼻子。最后,會生成一個對象模型,也就是一張張完整的臉。
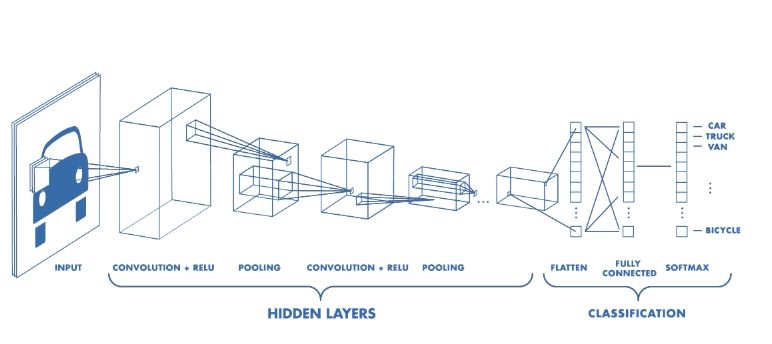
而我們在深度學習中的卷積神經網絡(如下圖為例),就是模仿了人類視覺系統的處理過程。正因此,計算機視覺是深度學習最佳的應用領域之一。超分辨就是計算機視覺中的一個經典應用。
超分辨率是通過軟件或硬件方法,提高圖像分辨率的一種方法。它的核心思想,就是用時間帶寬換取空間分辨率。簡單來講,就是在我無法得到一張超高分辨率的圖像時,我可以多拍幾張圖像,然后將這一系列低分辨率的圖像組成一張高分辨的圖像。這個過程叫超分辨率重建。
為什么超分辨率可以通過多拍幾張圖像,就能提高圖片分辨率呢?
這牽涉到抖動。我們經常說的拍照防抖動,其實防的是較明顯的抖動,但微小的抖動始終存在。在拍攝同一場景的每張圖像之間,都有細微差別,這些微小的抖動其實都包含了這個場景的額外信息,如果將他們合并,就會得到一張更為清晰的圖像。
有人可能會問,我們手機都能前后置兩千萬,為什么需要超分辨率技術呢?這種技術應用場景是不是不多?
其實不是。了解攝影的人都知道。在相同的感光元器件上,拍攝的圖像分辨率越高,在感光元器件上,單個像素占的面積越小,那會導致通光率越低,當你的像素密度到達一定程度后,會帶來大量噪聲,直接影響圖像質量。超分辨率就可以解決這種問題。超分辨率有很多應用,比如:
數字高清,通過這種方法來提高分辨率
顯微成像:合成一系列顯微鏡下的低分辨率圖像來得到高分辨率圖像
衛星圖像:用于遙感衛星成像,提升圖像精度
視頻復原:可以通過該技術復原視頻,例如老電影
但是,有很多情況下,我們只有一張圖像,無法拍攝多張,那么如何做超分辨率呢?這就需要用到機器學習了。比較典型的例子,就是在2017年Google 提出的一項“黑科技”。他們可以通過機器學習來消除視頻圖像中的馬賽克。當然,這項黑科技也有一定限制,以下圖為例,它訓練的神經網絡是針對人臉圖像的,那么如果你給的馬賽克圖像不是人臉,就無法還原。
超分辨率神經網絡原理
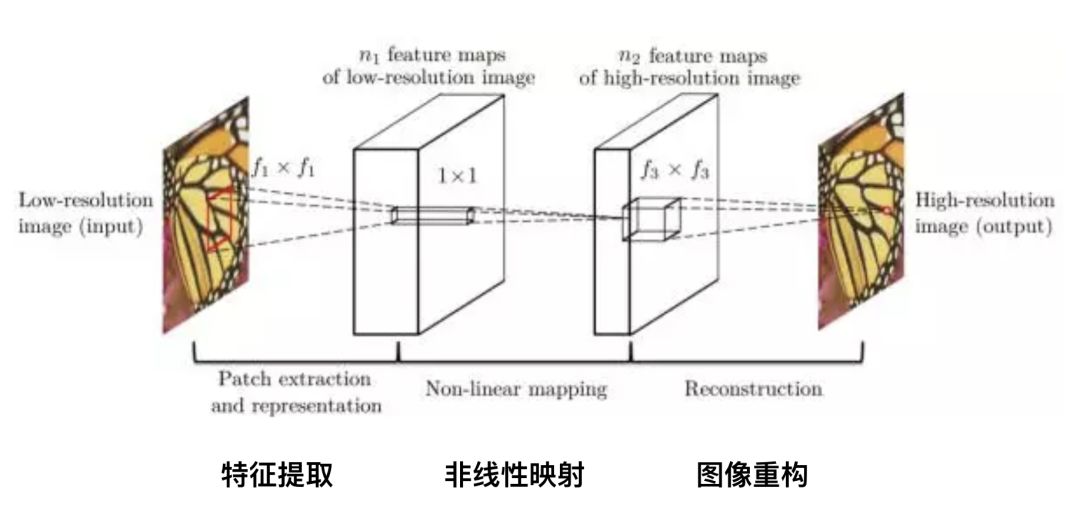
超分辨率神經網絡(Super-Resolution CNN,SRCNN)是深度學習應用在超分辨率領域的首個模型。原理比較簡單。它有三層神經網絡,包括:
特征提取:低分辨率圖像經過二項式差值得到模糊圖像,從中提取圖像特征,Channel 為3,卷積核大小為 f1*f1,卷積核個數為 n1;
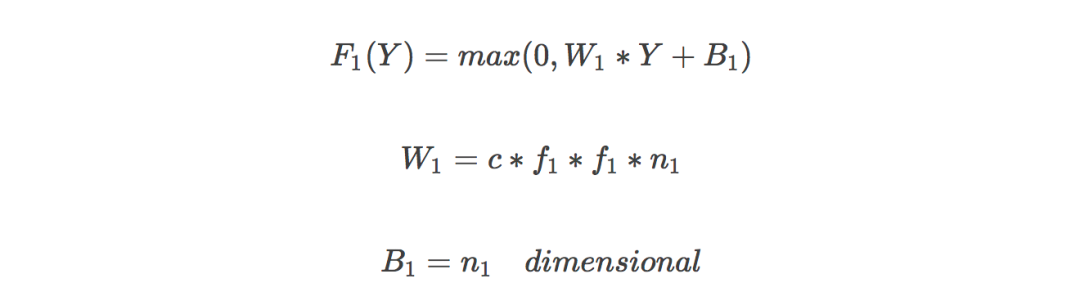
非線性映射:將低分辨率圖片特征映射到高分辨率,卷積核大小1*1;
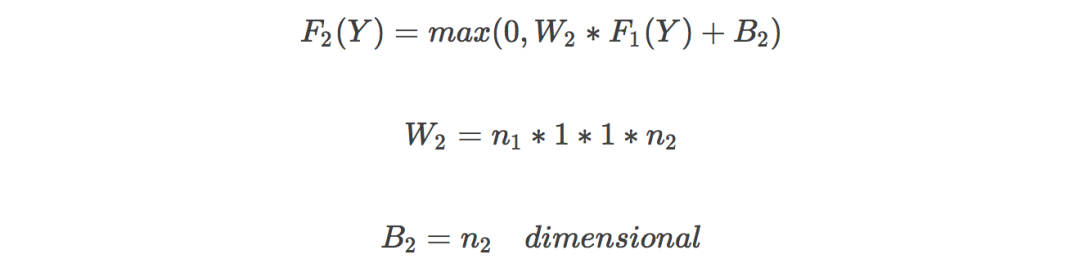
圖像重構:恢復細節,得到清晰的高分辨率圖像,卷積核為f3*f3;
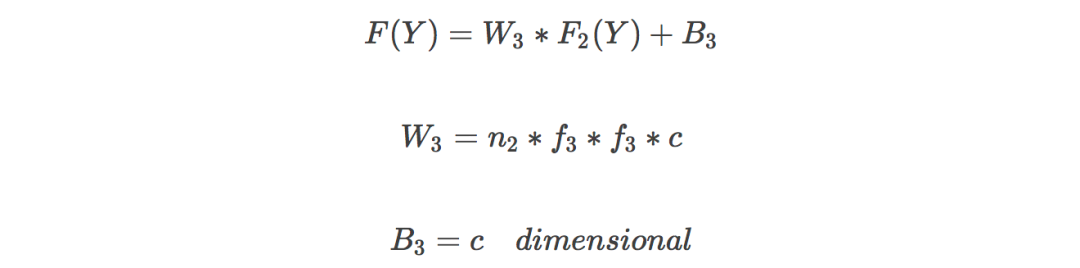
參數調節是神經網絡中比較玄的部分,也是最為人詬病的部分。很多人認為參數調節很像老中醫看病,通常缺少理論依據。在這里列出了幾個在 n1 取不同值的時候,所用的訓練時間和峰值信噪比(PSNR,用于判斷圖片質量的參數,越高越好)。

在訓練中,使用均方誤差(Mean Squared Error, MSE)作為損失函數,有利于獲得較高的PSNR。
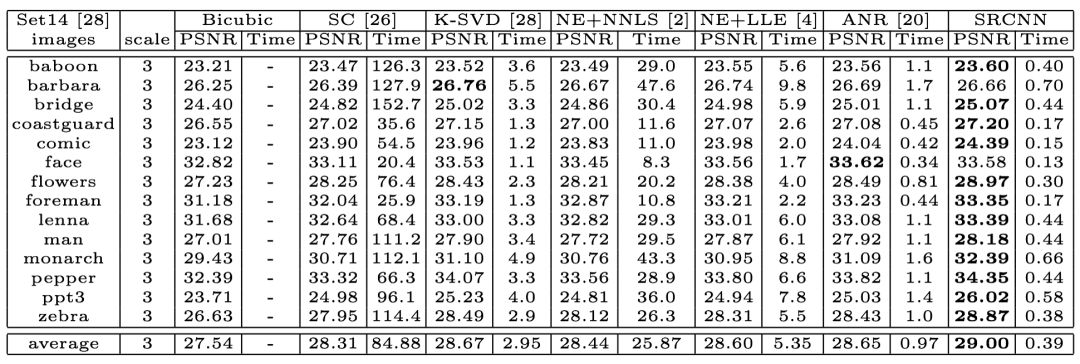
訓練結果如何呢?在下表中,列出了幾個傳統方法與 SRCNN 方法的結果對比。最左一列是圖片集,右側分別列出了每個方法的所用訓練時間和圖片峰值信噪比。可以看出,盡管有些圖片,傳統方法得出的結果更優于深度學習,但是總體來講,深度學習稍勝一籌,甚至所需時間更短。
有人說一圖勝千言。那么實際圖片效果如何呢?我們可以看下面兩組圖片。每組第一張是小分辨率的原圖,后面通過不同的方法來實現高分辨率的大圖。相比傳統方法,SRCNN 的圖片邊緣更加清晰,細節恢復的更好一些。以上就是最初的超分辨率的深度學習模型。
9個超分辨率神經網絡模型
SRCNN 是第一個超分辨率的神經網絡模型。在 SRCNN 這個模型出現后,更多應用于超分辨率的神經網絡模型。我們以下分享幾個:
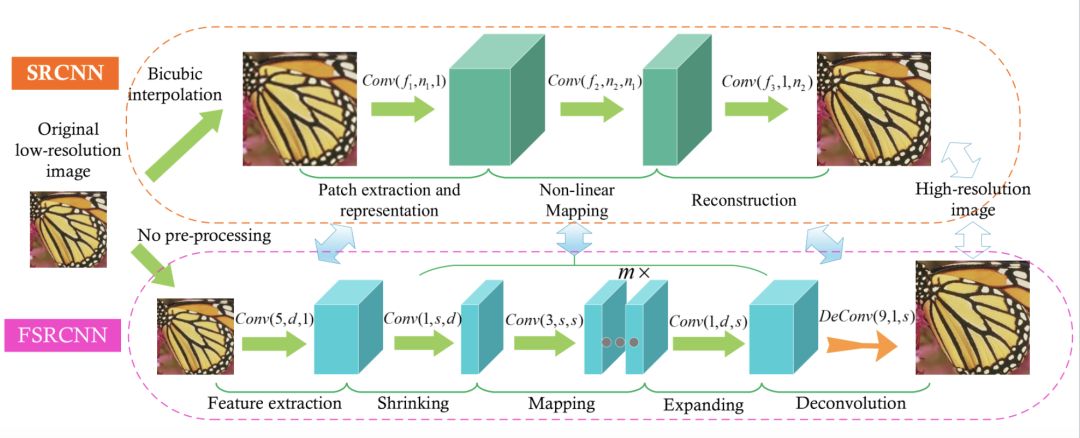
FSRCNN
相對 SRCNN,這個方法不需要對原始圖片使用二項式差值,可以直接對小分辨率圖像進行處理。在提取特征值之后,縮小圖片,然后經過 mapping、expending、反卷積層,然后得到高分辨率圖片。它好處是,縮小圖片可以降低訓練的時間。同時,如果你需要得到不同分辨率的圖片,單獨訓練反卷積層即可,更省時。
ESPCN
這個模型是基于小圖進行訓練。最后提取了 r2 個 Channel。比如說,我想將圖片擴大到原圖的3倍,那么 r 就是縮放因子 3,Channel 為9。通過將一個像素擴充為一個3x3的矩陣,模擬為一個像素的矩陣,來達到超分辨率的效果。
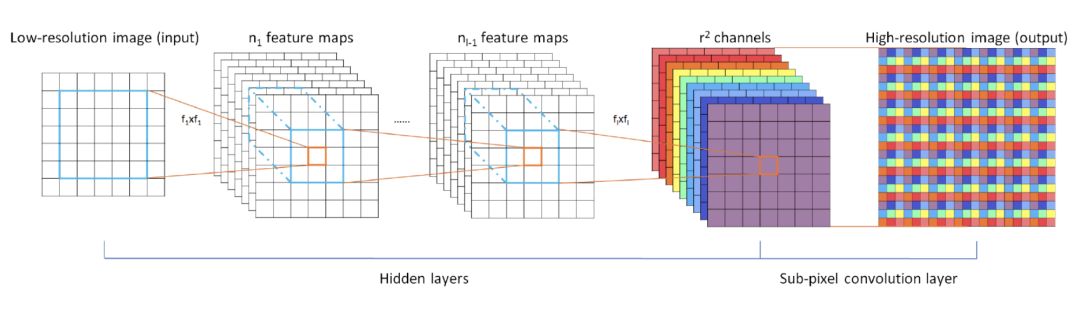
對實時視頻進行超分辨率處理的實驗結果也非常理想。對 1080 HD 格式的視頻進行3倍放大,SRCNN 每幀需要0.435s,而 ESPCN 則只需0.038s。
VDSR
這是2016年獲獎的一個模型。我們做視頻編解碼的都知道,圖像之間是存在殘差的。它認為原始的低分辨率圖片與高分辨率圖片之間,低頻分量幾乎一樣,缺失的是高頻分量,即圖片細節。那么訓練的時候,只需要針對高頻分量進行訓練就行了。
所以它的輸入分為兩部分,一是將整張原圖作為一個輸入,另一部分則是對殘差進行訓練然后得到一個輸入,將兩者加起來就得到一張高分辨率圖像。這樣就大大加快了訓練速度,收斂效果也更好。
DRCN
它還是分為三層。但是在非線性映射這一層,它使用了一個遞歸網絡,也就是說,數據循環多次地通過該層。將這個循環展開的話,等效于使用同一組參數的多個串聯的卷積層。
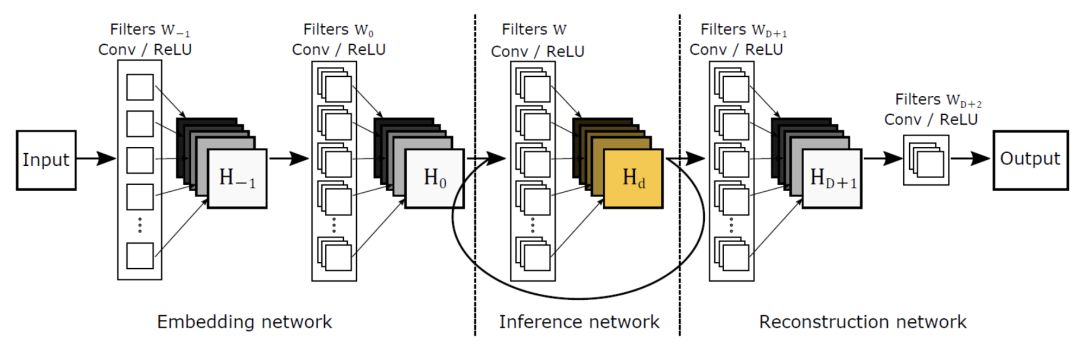
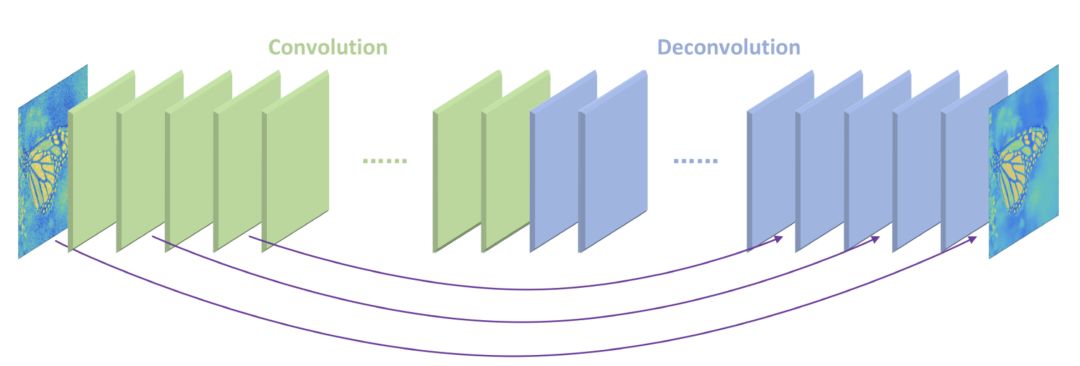
RED
每一個卷積層都對應一個非卷積層。簡單來講,可以理解為是將一張圖片進行了編碼,然后緊接著進行解碼。它的優勢在于解決了梯度消失的問題,而且能恢復出更干凈的圖片。它和 VDSR 有相似的思路。中間卷積層與反卷積層的訓練是針對原始圖片與目標圖片的殘差。最后原圖會與訓練輸出結果相加,得到高分辨率的圖片。
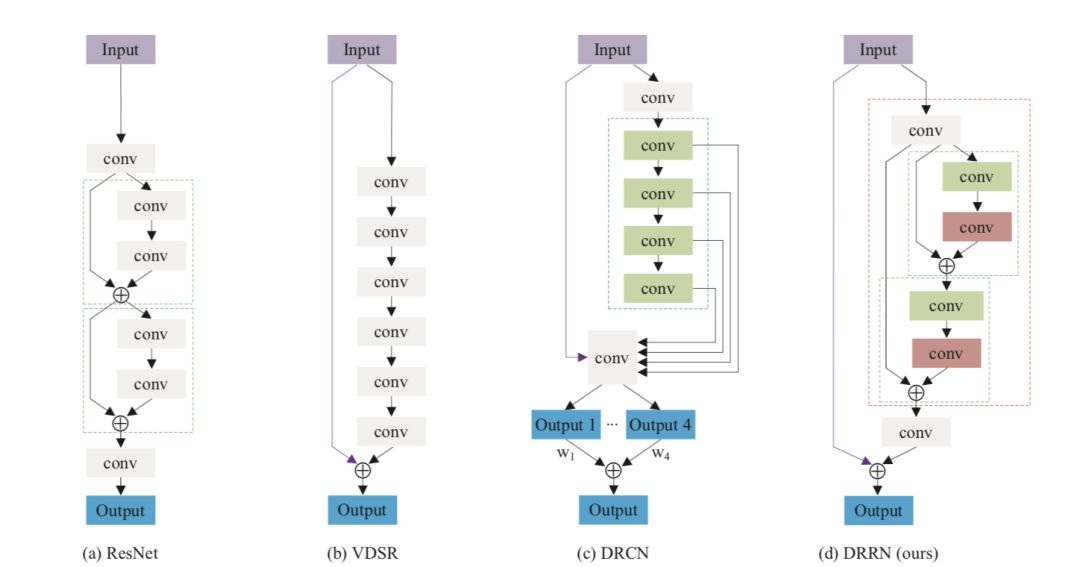
DRRN
在這個模型里你可以看到DRCN、VDSR的影子。它采用了更深的網絡結構來提升性能。其中有很多個圖片增強層。可以理解為,一張模糊的圖片,經過多個增強層,一級級變得更加清晰,最終得出高清圖片。大家可以在名為tyshiwo的 Github 上找到源碼。
LapSRN
LapSRN 的特別之處在于引入了一個分級的網絡。每一級都只對原圖放大兩倍,然后加上殘差獲得一個結果。如果對圖片放大8倍的話,這樣處理的性能會更高。同時,在每一級處理時,都可以得到一個輸出結果。
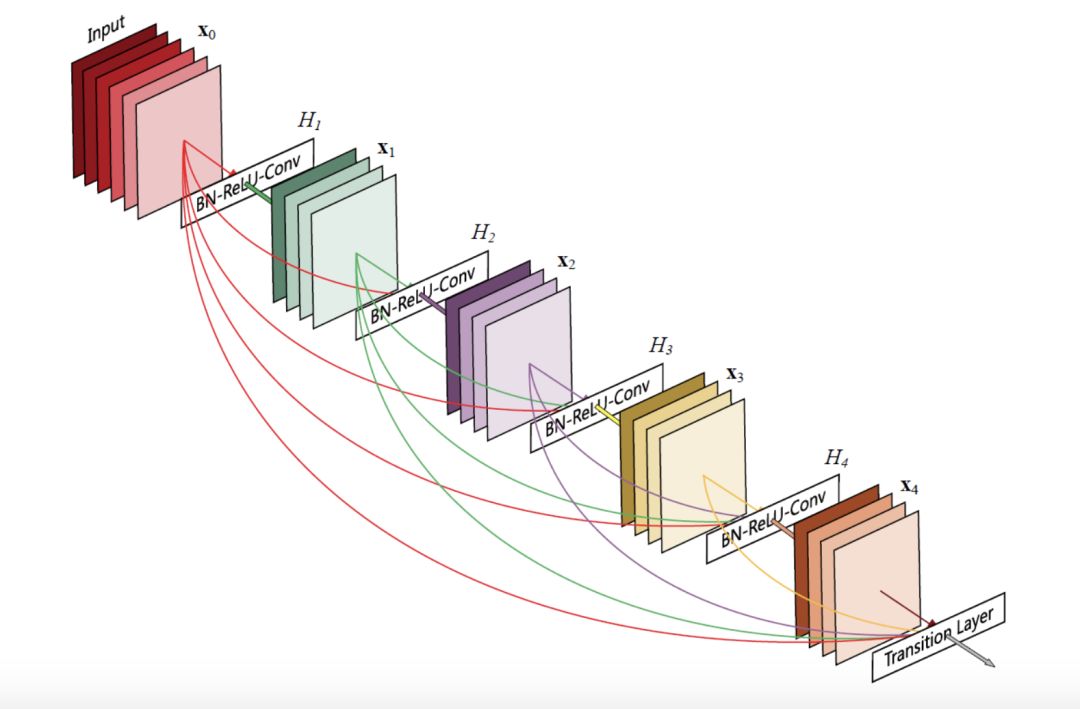
SRDenseNet
它引入了一個 Desent Block 的結構。上一層網絡訓練出的特征值會傳遞到下一層網絡,所有特征串聯起來。這樣做的好處是減輕梯度消失問題、減少參數數量。而且,后面的層可以復用之前訓練得出的特征值,不需要重復訓練。
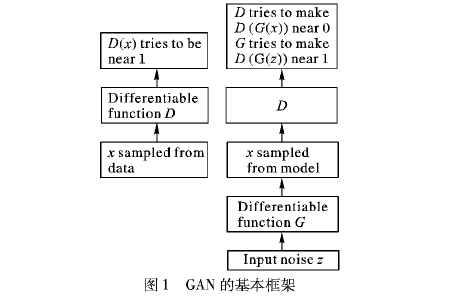
SRGAN
它可以利用感知損失(perceptual loss)和對抗損失(adversarial loss)來提升恢復出的圖片的。
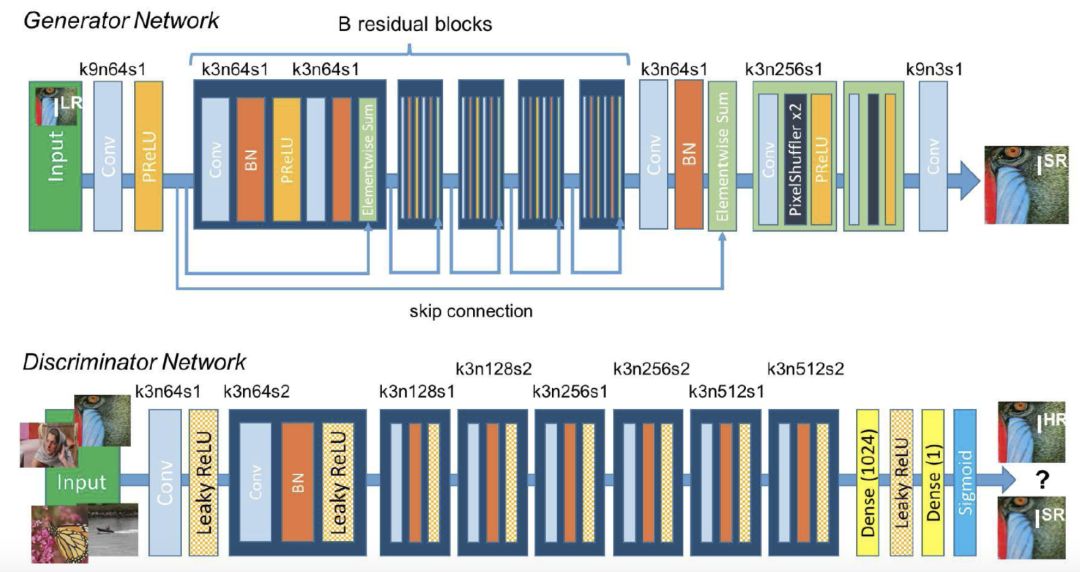
在這個模型中有兩個網絡,一個是生成網絡,另一個是判別網路,前者會生成高分辨率圖片,后者則會判斷這張圖是否是原圖,如果結果為“否”,那么前者會再次進行訓練、生成,直到可以騙過判別網絡。
以上這些神經網絡模型都可以應用于視頻處理中,但實際應用還需要考慮很多因素,比如系統平臺、硬件配置、性能優化。其實,除了超分辨率,機器學習與實時音視頻有很多可結合的應用場景,比如音視頻體驗優化、鑒黃、QoE 改進等。我們將在今年9月的 RTC 2018 實時互聯網大會上,將邀請來自 Google、美圖、搜狗等公司技術專家分享更多實踐經驗與干貨。
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100568 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45930 -
深度學習
+關注
關注
73文章
5493瀏覽量
121000
原文標題:普通視頻轉高清:10個基于深度學習的超分辨率神經網絡
文章出處:【微信號:shengwang-agora,微信公眾號:聲網Agora】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
詳解深度學習、神經網絡與卷積神經網絡的應用

基于POCS算法的圖像超分辨率重建
基于并列卷積神經網絡的超分辨率重建方法
數據外補償的深度網絡超分辨率重建
如何使用深度殘差生成對抗網絡設計醫學影像超分辨率算法
使用單幅圖像超分辨率算法解決SR資源不足和抗噪性差的問題說明
MIT:使用深度卷積神經網絡提高稀疏3D激光雷達的分分辨率
基于結構自相似性和形變塊特征的單幅圖像超分辨率算法
新思科技DesignWare ARC EV系列處理器IP實現超分辨率
基于復合的深度神經網絡的圖像超分辨率重建
單張圖像超分辨率和立體圖像超分辨率的相關工作






 工商網監
工商網監
評論