 介紹單片機中C語言的數據存儲與程序編寫
介紹單片機中C語言的數據存儲與程序編寫
一、五大內存分區:
內存分成5個區,它們分別是堆、棧、自由存儲區、全局/靜態存儲區和常量存儲區。
1、棧區(stack):FIFO就是那些由編譯器在需要的時候分配,在不需要的時候自動清除的變量的存儲區。里面的變量通常是局部變量、函數參數等。
2、堆區(heap):就是那些由new分配的內存塊,它們的釋放編譯器不去管,由我們的應用程序去控制,一般一個new就要對應一個delete。如果程序員沒有釋放掉,那么在程序結束后,操作系統會自動回收。
3、自由存儲區:就是那些由malloc等分配的內存塊,它和堆是十分相似的,不過它是用free來結束自己的生命。
4、全局/靜態存儲區:全局變量和靜態變量被分配到同一塊內存中,在以前的C語言中,全局變量又分為初始化的和未初始化的,在C++里面沒有這個區分了,他們共同占用同一塊內存區。
5、常量存儲區:這是一塊比較特殊的存儲區,它們里面存放的是常量,不允許修改(當然,你要通過非正當手段也可以修改,而且方法很多)
code/data/stack
內存主要分為代碼段,數據段和堆棧。代碼段放程序代碼,屬于只讀內存。數據段存放全局變量,靜態變量,常量等,堆里存放自己malloc或new出來的變量,其他變量就存放在棧里,堆棧之間空間是有浮動的。數據段的內存會到程序執行完才釋放。調用函數先找到函數的入口地址,然后計算給函數的形參和臨時變量在棧里分配空間,拷貝實參的副本傳給形參,然后進行壓棧操作,函數執行完再進行彈棧操作。字符常量一般放在數據段,而且相同的字符常量只會存一份。
二、C語言程序的存儲區域
1、由C語言代碼(文本文件)形成可執行程序(二進制文件),需要經過編譯-匯編-連接三個階段。編譯過程把C語言文本文件生成匯編程序,匯編過程把匯編程序形成二進制機器代碼,連接過程則將各個源文件生成的二進制機器代碼文件組合成一個文件。
2、C語言編寫的程序經過編譯-連接后,將形成一個統一文件,它由幾個部分組成。在程序運行時又會產生其他幾個部分,各個部分代表了不同的存儲區域:
1)代碼段(Code或Text)
代碼段由程序中執行的機器代碼組成。在C語言中,程序語句執行編譯后,形成機器代碼。在執行程序的過程中,CPU的程序計數器指向代碼段的每一條機器代碼,并由處理器依次運行。
2)只讀數據段(RO data)
只讀數據段是程序使用的一些不會被更改的數據,使用這些數據的方式類似查表式的操作,由于這些變量不需要更改,因此只需要放置在只讀存儲器中即可。
3)已初始化讀寫數據段(RW data)
已初始化數據是在程序中聲明,并且具有初值的變量,這些變量需要占用存儲器的空間,在程序執行時它們需要位于可讀寫的內存區域內,并且有初值,以供程序運行時讀寫。
4)未初始化數據段(BBS)
未初始化數據是在程序中聲明,但是沒有初始化的變量,這些變量在程序運行之前不需要占用存儲器的空間。
5)堆(heap)
堆內存只在程序運行時出現,一般由程序員分配和釋放。在具有操作系統的情況下,如果程序沒有釋放,操作系統可能在程序(例如一個進程)結束后會后內存。
6)棧(statck)
堆內存只在程序運行時出現,在函數內部使用的變量,函數的參數以及返回值將使用棧空間,棧空間由編譯器自動分配和釋放。
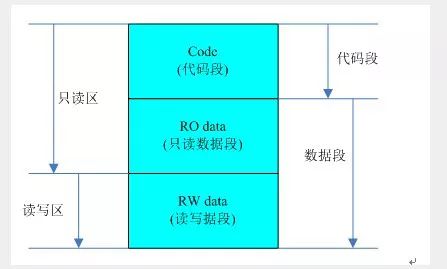
3、代碼段、只讀數據段、讀寫數據段、未初始化數據段屬于靜態區域,而堆和棧屬于動區域。代碼段、只讀數據段和讀寫數據段將在連接之后產生,未初始化數據段將在程序初始化的時候開辟,而對堆和棧將在程序餓運行中分配和釋放。
4、C語言程序分為映像和運行時兩種狀態。在編譯-連接后形成的映像中,將只包含代碼段(Text)、只讀數據段(R0 Data)和讀寫數據段(RW Data)。在程序運行之前,將動態生成未初始化數據段(BSS),在程序的運行時還將動態生成堆(Heap)區域和棧(Stack)區域。
注:
1、一般來說,在靜態的映像文件中,各個部分稱之為節(Section),而在運行時的各個部分稱之為段(Segment)。如果不詳細區分,統稱為段。
2、C語言在編譯連接后,將生成代碼段(TEXT),只讀數據段(RO Data)和讀寫數據段(RW Data)。在運行時,除了上述三個區域外,還包括未初始化數據段(BBS)區域和堆(heap)區域和棧(Stack)區域。
三、C語言程序的段
1、段的分類
每一個源程序生成的目標代碼將包含源程序所需要表達的所有信息和功能。目標代碼中各段生成情況如下:
1)代碼段(Code)
代碼段由程序中的各個函數產生,函數的每一個語句將最終經過編譯和匯編生成二進制機器代碼
2)只讀數據段(RO Data)
只讀數據段由程序中所使用的數據產生,該部分數據的特點在運行中不需要改變,因此編譯器會將數據放入只讀的部分中。C語言的一些語法將生成只讀數據數據段。
2、只讀數據段(RO Data)
只讀數據段(RO Data)由程序中所使用的數據產生,該部分數據的特點是在運行中不需要改變,因此編譯器會將數據放入只讀的部分中。以下情況將生成只讀數據段。
1)只讀全局變量
定義全局變量const char a[100]=”abcdefg”將生成大小為100個字節的只讀數據區,并使用字符串“abcdefg”初始化。如果定義為const char a[]=”abcdefg”,沒有指定大小,將根據“abcdefgh”字串的長度,生成8個字節的只讀數據段。
2)只讀局部變量
例如:在函數內部定義的變量const char b[100]=”9876543210”;其初始化的過程和全局變量。
3)程序中使用的常量
例如:在程序中使用printf("information\n”),其中包含了字串常量,編譯器會自動把常量“information \n”放入只讀數據區。
注:在const char a[100]={“ABCDEFG”}中,定義了100個字節的數據區,但是只初始化了前面的8個字節(7個字符和表示結束符的‘\0’)。在這種用法中,實際后面的字節米有初始化,但是在程序中也不能寫,實際上沒有任何用處。因此,在只讀數據段中,一般都需要做完全的的初始化。
3、讀寫數據段(RW Data)
讀寫數據段表示了在目標文件中一部分可以讀也可以寫的數據區,在某些場合它們又被稱為已初始化數據段。這部分數據段和代碼,與只讀數據段一樣都屬于程序中的靜態區域,但是具有科協的特點。
1)已初始化全局變量
例如:在函數外部,定義全局的變量char a[100]=”abcdefg”
2)已初始化局部靜態變量
例如:在函數中定義static char b[100]=”9876543210”。函數中由static定義并且已經初始化的數據和數組將被編譯為讀寫數據段。
說明:
讀寫數據區的特點是必須在程序中經過初始化,如果只有定義,沒有初始值,則不會生成讀寫數據區,而會定義為未初始化數據區(BSS)。如果全局變量(函數外部定義的變量)加入static修飾符,寫成static char a[100]的形式,這表示只能在文件內部使用,而不能被其他文件使用。
4、未初始化數據段(BSS)
未初始化數據段常被稱之為BSS(英文名為Block start by symbol的縮寫)。與讀寫數據段類似,它也屬于靜態數據區。但是該段中數據沒有經過初始化。因此它只會在目標文件中被標識,而不會真正稱為目標文件中的一個段,該段將會在運行時產生。未初始化數據段只有在運行的初始化階段才會產生,因此它的大小不會影響目標文件的大小。
四、在C語言的程序中,對變量的使用還有以下注意
1、在函數體中定義的變量通常是在棧上,不需要在程序中進行管理,由編譯器處理。
2、用malloc,calloc,realoc等分配分配內存的函數所分配的內存空間在堆上,程序必須保證在使用后使用后freee釋放,否則會發生內存泄漏。
3、所有函數體外定義的是全局變量,加了static修飾符后的變量不管在函數內部或者外部存放在全局區(靜態區)。
4、使用const定義的變量將放于程序的只讀數據區。
說明:
在C語言中,可以定義static變量:在函數體內定義的static變量只能在該函數體內有效;在所有函數體外定義的static變量,也只能在該文件中有效,不能在其他源文件中使用;對于沒有使用 static修飾的全局變量,可以在其他的源文件中使用。這些區別是編譯的概念,即如果不按要求使用變量,編譯器會報錯。使用static 和沒使用static修飾的全局變量最終都將放置在程序的全局去(靜態去)。
五、程序中段的使用
C語言中的全局區(靜態區),實際上對應著下述幾個段:
只讀數據段:RO Data
讀寫數據段:RW Data
未初始化數據段:BSS Data
一般來說,直接定義的全局變量在未初始化數據區,如果該變量有初始化則是在已初始化數據區(RW Data),加上const修飾符將放置在只讀區域(RO Data).
例如:
const char ro[ ]=”this is a readonlydata”; //只讀數據段,不能改變ro數組中的內容,ro存放在只讀數據段。
char rw1[ ]=”this is global readwrite data”; //已初始化讀寫數據段,可以改變數組rw1中的內容。應為數值/是賦值不是把”this is global readwrite data” 地址給了rw1,不能改變char rw1[ ]=”this is global readwrite data”; //已初始化讀寫數據段,可以改變數組rw1中的內容。應為數值/是賦值不是把”this is global readwrite data” 地址給了rw1,不能改變”this is global readwrite data”的數值。因為起是文字常量放在只讀數據段中
char bss_1[100];//未初始化數據段
const char *ptrconst = “constant data”; //”constant data”放在只讀數據段,不能改變ptrconst中的值,因為其是地址賦值。ptrconst指向存放“constant data”的地址,其為只讀數據段。但可以改變ptrconst地址的數值,因其存放在讀寫數據段中。
實例講解:
int main( )
{
short b;//b放置在棧上,占用2個字節
char a[100];//需要在棧上開辟100個字節,a的值是其首地址
char s[]=”abcde”;
//s在棧上,占用4個字節,“abcde”本身放置在只讀數據存儲區,占6字節。s是一個地址
//常量,不能改變其地址數值,即s++是錯誤的。
char *p1;//p1在棧上,占用4個字節
char *p2 ="123456";//"123456"放置在只讀數據存儲區,占7個字節。p2在棧上,p2指向的內容不能更
//改,但是p2的地址值可以改變,即p2++是對的。
static char bss_2[100]; //局部未初始化數據段
static int c=0 ; //局部(靜態)初始化區
p1 = (char *)malloc(10*sizeof(char)); //分配的內存區域在堆區
strcpy(p1,”xxx”); //”xxx”放置在只讀數據存儲區,占5個字節
free(p1); //使用free釋放p1所指向的內存
return 0;
}
說明:
1、只讀數據段需要包括程序中定義的const型的數據(如:const char ro[]),還包括程序中需要使用的數據如“123456”。對于const char ro[]和const char * ptrconst的定義,它們指向的內存都位于只讀數據據區,其指向的內容都不允許修改。區別在于前者不允許在程序中修改ro的值,后者允許在程序中修改ptrconst本身的值。對于后者,改寫成以下的形式,將不允許在程序中修改ptrconst本身的值:
const char * const ptrconst = “const data”;
2、讀寫數據段包含了已經初始化的全局變量static char rw1[]以及局部靜態變量static char
rw2[]。rw1和rw2的差別在于編譯時,是在函數內部使用的還是可以在整個文件中使用。對于前者,static修飾在于控制程序的其他文件時候可以訪問rw1變量,如果有static修飾,將不能在其他的C語言源文件中使用rw1,這種影響針對編譯-連接的特性,但無論有static,變量rw1都將被放置在讀寫數據段。對于后者rw2,它是局部的靜態變量,放置在讀寫數據區;如果不使用static修飾,其意義將完全改變,它將會是開辟在棧空間局部變量,而不是靜態變量。
3、未初始化數據段,事例1中的bss_1[100]和 bss_2[200]在程序中代表未初始化的數據段。其區別在于前者是全局的變量,在所有文件中都可以使用;后者是局部的變量,只在函數內部使用。未初始化數據段不設置后面的初始化數值,因此必須使用數值指定區域的大小,編譯器將根據大小設置BBS中需要增加的長度。
4、棧空間包括函數中內部使用的變量如short b和char a[100],以及char *p1中p1這個變量的值。
1)變量p1指向的內存建立在堆空間上,堆空間只能在程序內部使用,但是堆空間(例如p1指向的內存)可以作為返回值傳遞給其他函數處理。
2)棧空間主要用于以下3類數據的存儲:
a、函數內部的動態變量
b、函數的參數
c、函數的返回值
3)棧空間主要的用處是供函數內部的動態變量使用,變量的空間在函數開始之前開辟,在函數退出后由編譯器自動回收。看一個例:
int main( )
{
char *p = "tiger";
p[1] = 'I';
p++;
printf("%s\n",p);
}
編譯后提示:段錯誤
分析:
char *p = "tiger";系統在棧上開辟了4個字節存儲p的數值。"tiger"在只讀存儲區中存儲,因此"tiger"的內容不能改變,*p="tiger",表示地址賦值,因此,p指向了只讀存儲區,因此改變p指向的內容會引起段錯誤。但是因為p是存放在棧上,因此p的數值是可以改變的,因此p++是正確的。
六、const的使用
1、前言:
const是一個C語言的關鍵字,它限定一個變量不允許被改變。使用const在一定程序上可以提高程序的健壯性,另外,在觀看別人代碼的時候,清晰理解const所起的作用,對理解別人的程序有所幫助。
2、const變量和常量
1)const修飾的變量,其值存放在只讀數據段中,其值不能被改變。稱為只讀變量。
其形式為 const int a=5;此處可以用a代替5
2)常量:其也存在只讀數據段中,其數值也不能被改變。其形式為"abc" ,5
3、const 變量和const限定的內容,先看一個事例:
typedef char* pStr;
int main( )
{
char string[6] = “tiger”;
const char *p1 = string;
const pStr p2 = string;
p1++;
p2++;
printf(“p1=%s\np2=%s\n”,p1,p2);
}
程序經過編譯后,提示錯誤為
error:increment of read-only variable ‘p2’
1)const 使用的基本形式為:const char m;
//限定m 不可變
2)替換1式中的m,const char *pm;
//限定*pm不可變,當然pm是可變的,因此p1++是對的。
3)替換1式中的char,const newType m;
//限定m不可變,問題中的pStr是一種新類型,因此問題中p2不可變,p2++是錯誤的。
4、const 和指針
類型聲明中const用來修飾一個常量,有如下兩種寫法:
1)const在前面
const int nValue;//nValue是const
const char *pContent;//*pContent是const,pConst可變
const (char *)pContent;//pContent是const,*pContent可變
char *const pContent;//pContent是const,*pContent可變
const char * const pContent;//pContent和*pContent都是const
2)const 在后面與上面的聲明對等
int const nValue; // nValue是const
char const *pContent;//*pContent是const, pContent可變
(char *) constpContent;//pContent是const, *pContent可變
char* const pContent;// pContent是const, *pContent可變
char const* const pContent;//pContent和*pContent都是const
說明:const和指針一起使用是C語言中一個很常見的困惑之處,下面是兩天規則:
1)沿著*號劃一條線,如果const位于*的左側,則const就是用來修飾指針所指向的變量,即指針指向為常量;如果const位于*的右側,const就是修飾指針本身,即指針本身是常量。你可以根據這個規則來看上面聲明的實際意義,相信定會一目了然。
2)對于const (char *) ; 因為char *是一個整體,相當于一個類型(如char),因此,這是限定指針是const。
七、單片機C語言中的data,idata,xdata,pdata,code
從數據存儲類型來說,8051系列有片內、片外程序存儲器,片內、片外數據存儲器,片內程序存儲器還分直接尋址區和間接尋址類型,分別對應code、data、xdata、idata以及根據51系列特點而設定的pdata類型,使用不同的存儲器,將使程序執行效率不同,在編寫C51程序時,最好指定變量的存儲類型,這樣將有利于提高程序執行效率(此問題將在后面專門講述)。與ANSI-C稍有不同,它只分SAMLL、COMPACT、LARGE模式,各種不同的模式對應不同的實際硬件系統,也將有不同的編譯結果。
在51系列中data,idata,xdata,pdata的區別:
data:固定指前面0x00-0x7f的128個RAM,可以用acc直接讀寫的,速度最快,生成的代碼也最小。
idata:固定指前面0x00-0xff的256個RAM,其中前128和data的128完全相同,只是因為訪問的方式不同。idata是用類似C中的指針方式訪問的。匯編中的語句為:mox ACC,@Rx.(不重要的補充:c中idata做指針式的訪問效果很好)
xdata:外部擴展RAM,一般指外部0x0000-0xffff空間,用DPTR訪問。
pdata:外部擴展RAM的低256個字節,地址出現在A0-A7的上時讀寫,用movx ACC,@Rx讀寫。這個比較特殊,而且C51好象有對此BUG,建議少用。但也有他的優點,具體用法屬于中級問題,這里不提。
單片機C語言unsigned char code table[]code 是什么作用?
code的作用是告訴單片機,我定義的數據要放在ROM(程序存儲區)里面,寫入后就不能再更改,其實是相當與匯編里面的尋址MOVX(好像是),因為C語言中沒辦法詳細描述存入的是ROM還是RAM(寄存器),所以在軟件中添加了這一個語句起到代替匯編指令的作用,對應的還有data是存入RAM的意思。
程序可以簡單的分為code(程序)區,和data (數據)區,code區在運行的時候是不可以更改的,data區放全局變量和臨時變量,是要不斷的改變的,cpu從code區讀取指令,對data區的數據進行運算處理,因此code區存儲在什么介質上并不重要,象以前的計算機程序存儲在卡片上,code區也可以放在rom里面,也可以放在ram里面,也可以放在flash里面(但是運行速度要慢很多,主要讀flash比讀ram要費時間),因此一般的做法是要將程序放到flash里面,然后load到 ram里面運行的;DATA區就沒有什么選擇了,肯定要放在RAM里面,放到rom里面改動不了。
bdata如何使用它呢?
若程序需要8個或者更多的bit變量,如果你想一次性給8個變量賦值的話就不方便了,(舉個例子說說它的方便之處,想更深入的了解請在應用中自己琢磨)又不可以定義bit數組,只有一個方法
char bdata MODE;
sbit MODE_7 = MODE^7;
sbit MODE_6 = MODE^6;
sbit MODE_5 = MODE^5;
sbit MODE_4 = MODE^4;
sbit MODE_3 = MODE^3;
sbit MODE_2 = MODE^2;
sbit MODE_1 = MODE^1;
sbit MODE_0 = MODE^0;
8個bit變量MODE_n 就定義好了
這是定義語句,Keilc 的特殊數據類型。記住一定要是sbit
不能 bit MODE_0 = MODE^0;
賦值語句要是這么寫C語言就視為異或運算。
Flash相對單片機里的RAM屬于外部存取器,雖其結構位置裝在單片機中,其實xdata是放在相對RAM的外面,而flash正是相對RAM外面。
inta變量定義在內部RAM,xdatainta定義在外部RAM或flash,uchar codea定義在flash。
uchar code duma[]={0x3f,0x06,0x5b,0x4f,0x66,0x6d,0x7d,0x07,0x7f,0x6f,0x40,0x00}; //共陰的數碼管段選,P2口要取的數值
若定義 uchar aa[5],aa[5]中的內容是存放在數據存儲區(RAM)中的,在程序運行工程中各個數組元素的值可以被修改,掉電后aa[5]中的數據無法保存。
若定義 uchar code bb[5]中的內容是存放在程序存儲區(如flash)中的,只有在燒寫程序時,才能改變bb[5]中的各元素的值,在程序運行工程中無法修改,并且掉電后bb[5]中的數據不消失。
八、C語言中堆和棧的區別
C語言程序經過編譯連接后形成編譯、連接后形成的二進制映像文件由棧、堆、數據段(由三部分部分組成:只讀數據段,已經初始化讀寫數據段,未初始化數據段即BBS)和代碼段組成,如下圖所示:
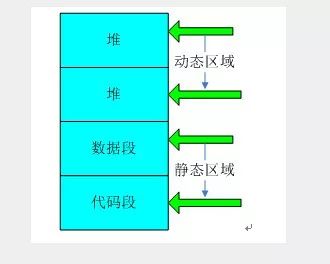
1、棧區(stack):由編譯器自動分配釋放,存放函數的參數值,局部變量等值。其操作方式類似于數據結構中的棧。
2、堆區(heap):一般由程序員分配釋放,若程序員不釋放,則可能會引起內存泄漏。注堆和數據結構中的堆棧不一樣,其類是與鏈表。
3、程序代碼區:存放函數體的二進制代碼。
4、數據段:由三部分組成:
1)只讀數據段:
只讀數據段是程序使用的一些不會被更改的數據,使用這些數據的方式類似查表式的操作,由于這些變量不需要更改,因此只需要放置在只讀存儲器中即可。一般是const修飾的變量以及程序中使用的文字常量一般會存放在只讀數據段中。
2)已初始化的讀寫數據段:
已初始化數據是在程序中聲明,并且具有初值的變量,這些變量需要占用存儲器的空間,在程序執行時它們需要位于可讀寫的內存區域內,并且有初值,以供程序運行時讀寫。在程序中一般為已經初始化的全局變量,已經初始化的靜態局部變量(static修飾的已經初始化的變量)
3)未初始化段(BSS):
未初始化數據是在程序中聲明,但是沒有初始化的變量,這些變量在程序運行之前不需要占用存儲器的空間。與讀寫數據段類似,它也屬于靜態數據區。但是該段中數據沒有經過初始化。未初始化數據段只有在運行的初始化階段才會產生,因此它的大小不會影響目標文件的大小。在程序中一般是沒有初始化的全局變量和沒有初始化的靜態局部變量。
堆和棧的區別
1、申請方式
(1)棧(satck):由系統自動分配。例如,聲明在函數中一個局部變量int b;系統自動在棧中為b開辟空間。
(2)堆(heap):需程序員自己申請(調用malloc,realloc,calloc),并指明大小,并由程序員進行釋放。容易產生memory leak.
eg:charp;
p = (char *)malloc(sizeof(char));//但是,p本身是在棧中。
2、申請大小的限制
1)棧:在windows下棧是向底地址擴展的數據結構,是一塊連續的內存區域(它的生長方向與內存的生長方向相反)。棧的大小是固定的。如果申請的空間超過棧的剩余空間時,將提示overflow。
2)堆:堆是高地址擴展的數據結構(它的生長方向與內存的生長方向相同),是不連續的內存區域。這是由于系統使用鏈表來存儲空閑內存地址的,自然是不連續的,而鏈表的遍歷方向是由底地址向高地址。堆的大小受限于計算機系統中有效的虛擬內存。
3、系統響應:
1)棧:只要棧的空間大于所申請空間,系統將為程序提供內存,否則將報異常提示棧溢出。
2)堆:首先應該知道操作系統有一個記錄空閑內存地址的鏈表,但系統收到程序的申請時,會遍歷該鏈表,尋找第一個空間大于所申請空間的堆結點,然后將該結點從空閑鏈表中刪除,并將該結點的空間分配給程序,另外,對于大多數系統,會在這塊內存空間中的首地址處記錄本次分配的大小,這樣,代碼中的free語句才能正確的釋放本內存空間。另外,找到的堆結點的大小不一定正好等于申請的大小,系統會自動的將多余的那部分重新放入空閑鏈表中。
說明:對于堆來講,對于堆來講,頻繁的new/delete勢必會造成內存空間的不連續,從而造成大量的碎片,使程序效率降低。對于棧來講,則不會存在這個問題,
4、申請效率
1)棧由系統自動分配,速度快。但程序員是無法控制的
2)堆是由malloc分配的內存,一般速度比較慢,而且容易產生碎片,不過用起來最方便。
5、堆和棧中的存儲內容
1)棧:在函數調用時,第一個進棧的主函數中后的下一條語句的地址,然后是函數的各個參數,參數是從右往左入棧的,然后是函數中的局部變量。注:靜態變量是不入棧的。
當本次函數調用結束后,局部變量先出棧,然后是參數,最后棧頂指針指向最開始存的地址,也就是主函數中的下一條指令,程序由該點繼續執行。
2)堆:一般是在堆的頭部用一個字節存放堆的大小。
6、存取效率
1)堆:char *s1=”hellowtigerjibo”;是在編譯是就確定的
2)棧:char s1[]=”hellowtigerjibo”;是在運行時賦值的;用數組比用指針速度更快一些,指針在底層匯編中需要用edx寄存器中轉一下,而數組在棧上讀取。
補充:
棧是機器系統提供的數據結構,計算機會在底層對棧提供支持:分配專門的寄存器存放棧的地址,壓棧出棧都有專門的指令執行,這就決定了棧的效率比較高。堆則是C/C++函數庫提供的,它的機制是很復雜的,例如為了分配一塊內存,庫函數會按照一定的算法(具體的算法可以參考數據結構/操作系統)在堆內存中搜索可用的足夠大小的空間,如果沒有足夠大小的空間(可能是由于內存碎片太多),就有可能調用系統功能去增加程序數據段的內存空間,這樣就有機會分到足夠大小的內存,然后進行返回。顯然,堆的效率比棧要低得多。
7、分配方式:
1)堆都是動態分配的,沒有靜態分配的堆。
2)棧有兩種分配方式:靜態分配和動態分配。靜態分配是編譯器完成的,比如局部變量的分配。動態分配由alloca函數進行分配,但是棧的動態分配和堆是不同的。它的動態分配是由編譯器進行釋放,無需手工實現。
-
C語言
+關注
關注
180文章
7600瀏覽量
136229 -
數據存儲
+關注
關注
5文章
964瀏覽量
50860
原文標題:單片機中C語言的程序與數據存儲
文章出處:【微信號:changxuemcu,微信公眾號:暢學單片機】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
單片機編程語言有哪些選擇
單片機怎么寫入程序
keil可以讀出單片機的程序嗎
藍牙模塊如何實現單片機和手機端數據互傳





 工商網監
工商網監
評論