") 講解隨機(jī)梯度下降、類別數(shù)據(jù)編碼、Vowpal Wabbit機(jī)器學(xué)習(xí)庫(kù)
講解隨機(jī)梯度下降、類別數(shù)據(jù)編碼、Vowpal Wabbit機(jī)器學(xué)習(xí)庫(kù)
編者按:機(jī)器學(xué)習(xí)開放課程第八課,Mail.Ru數(shù)據(jù)科學(xué)家Yury Kashnitsky講解了隨機(jī)梯度下降、類別數(shù)據(jù)編碼、Vowpal Wabbit機(jī)器學(xué)習(xí)庫(kù)。
這一課我們將從理論和實(shí)踐的角度介紹Vowpal Wabbit訓(xùn)練速度非同尋常的原因,在線學(xué)習(xí)和哈希技巧。我們將在新聞、影評(píng)、StackOverflow問(wèn)題上嘗試Vowpal Wabbit。
概覽
隨機(jī)梯度下降和在線學(xué)習(xí)
SGD
在線學(xué)習(xí)方法
類別數(shù)據(jù)處理
標(biāo)簽編碼
獨(dú)熱編碼
哈希技巧
Vowpal Wabbit
新聞:二元分類
新聞:多元分類
IMDB影評(píng)
分類StackOverflow問(wèn)題
相關(guān)資源
1. 隨機(jī)梯度下降和在線學(xué)習(xí)
1.1 隨機(jī)梯度下降
回顧一下,梯度下降的想法是通過(guò)在下降最快的方向上小步前進(jìn),以最小化某個(gè)函數(shù)。這一方法得名于以下微積分的事實(shí):函數(shù)f(x) = f(x1, ..., xn)的偏導(dǎo)數(shù)向量
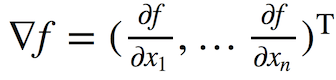
指向函數(shù)增長(zhǎng)最快的方向。這意味著,向相反方向移動(dòng)(逆梯度),可能以最快的速度降低函數(shù)值。
俄羅斯最受歡迎的冬季度假勝地——謝列格什滑雪場(chǎng),踩著滑雪板的人為本文作者
除了宣傳美麗的風(fēng)光,上面的照片描繪了梯度下降的概念。如果你想滑得盡可能快,你需要選擇最陡峭的下降路徑。計(jì)算逆梯度可以看成評(píng)估不同點(diǎn)的坡度。
例子
我們將通過(guò)梯度下降求解一個(gè)成對(duì)回歸問(wèn)題(paired regression problem)。讓我們根據(jù)一個(gè)變量預(yù)測(cè)另一個(gè)變量:根據(jù)體重預(yù)測(cè)身高。我們將假定這些變量是線性相關(guān)的。另外,我們將使用的是SOCR數(shù)據(jù)集。
首先我們導(dǎo)入數(shù)據(jù),并繪制散布圖:
import warnings
warnings.filterwarnings('ignore')
import os
import re
import numpy as np
import pandas as pd
from tqdm import tqdm_notebook
from sklearn.datasets import fetch_20newsgroups, load_files
from sklearn.preprocessing importLabelEncoder, OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model importLogisticRegression
from sklearn.metrics import classification_report, accuracy_score, log_loss
from sklearn.metrics import roc_auc_score, roc_curve, confusion_matrix
from scipy.sparse import csr_matrix
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
PATH_TO_ALL_DATA = '../../data/'
data_demo = pd.read_csv(os.path.join(PATH_TO_ALL_DATA,
'weights_heights.csv'))
plt.scatter(data_demo['Weight'], data_demo['Height']);
plt.xlabel('Weight in lb')
plt.ylabel('Height in inches');
我們有一個(gè)l維向量x(每個(gè)人的體重,也就是訓(xùn)練樣本)和向量y(包含數(shù)據(jù)集中每個(gè)人的身高)。
我們要完成的任務(wù)是:找到滿足以下條件的權(quán)重w0和w1,使預(yù)測(cè)身高yi= w0+ w1xi最小化以下平方誤差(等效于最小化均方誤差,因?yàn)?/l并不會(huì)帶來(lái)什么不同):
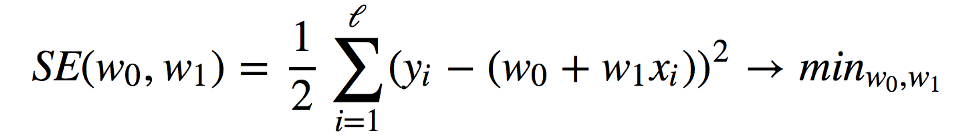
我們將使用梯度下降,利用SE(w0, w1)在權(quán)重w0和w1上的偏導(dǎo)數(shù)。以下簡(jiǎn)單的更新公式定義了迭代訓(xùn)練過(guò)程:
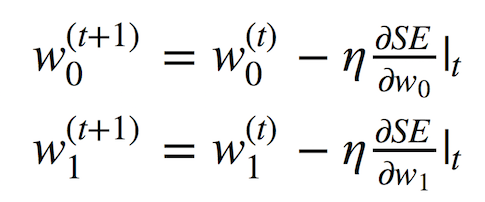
展開偏導(dǎo)數(shù)后,我們得到:
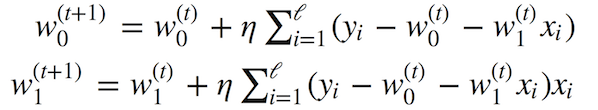
在數(shù)據(jù)量不大的情況下,上面的數(shù)學(xué)效果不錯(cuò)(我們這里不討論局部極小值、鞍點(diǎn)、學(xué)習(xí)率選擇、動(dòng)量等問(wèn)題,請(qǐng)參考《深度學(xué)習(xí)》一書的數(shù)值計(jì)算那一章)。批量梯度下降有一個(gè)問(wèn)題——梯度演算需要累加訓(xùn)練集中所有對(duì)象的值。換句話說(shuō),該算法需要大量迭代,而每次迭代重新計(jì)算權(quán)重的過(guò)程中都包含累加整個(gè)訓(xùn)練集的運(yùn)算。如果我們有數(shù)十億訓(xùn)練樣本,怎么辦?
這正是隨機(jī)梯度下降的動(dòng)機(jī)!簡(jiǎn)單來(lái)說(shuō),我們?nèi)拥衾奂臃?hào),僅僅根據(jù)單個(gè)訓(xùn)練樣本或一小部分訓(xùn)練樣本更新權(quán)重:
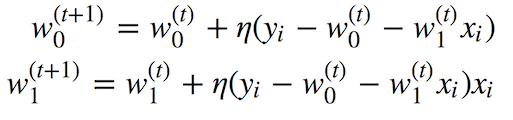
這個(gè)方法無(wú)法保證我們?cè)诿看蔚幸宰罴训姆较蛞苿?dòng)。因此,我們可能需要更多的迭代,不過(guò)我們的權(quán)重更新會(huì)快很多。
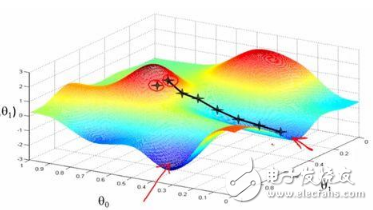
吳恩達(dá)的機(jī)器學(xué)習(xí)課程很好地講解了這一點(diǎn)。讓我們來(lái)看一下。
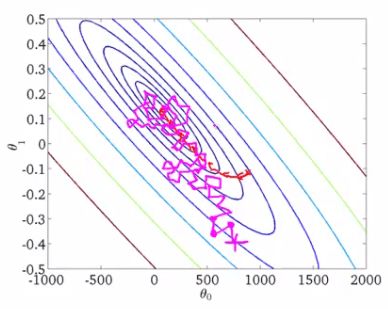
這是某個(gè)函數(shù)的等值線圖,我們想要找出該函數(shù)的全局最小值。紅線展示了權(quán)重變動(dòng)(圖中的θ0和θ1相當(dāng)于我們的w0和w1)。根據(jù)梯度的性質(zhì),每點(diǎn)的變動(dòng)方向垂直于等值線。隨機(jī)梯度下降時(shí),權(quán)重以更難預(yù)測(cè)的方式變動(dòng)(紫線),我們甚至可以看到,有些步驟是錯(cuò)誤的,正遠(yuǎn)離最小值;然而,梯度下降和隨機(jī)梯度下降這兩個(gè)過(guò)程均收斂于同一解。
1.2 在線學(xué)習(xí)方法
在隨機(jī)梯度下降的實(shí)踐指導(dǎo)下,我們可以在多達(dá)數(shù)百GB的數(shù)據(jù)上訓(xùn)練分類器和回歸器。
考慮成對(duì)回歸的情形,我們可以將訓(xùn)練數(shù)據(jù)集(X, y)保存在硬盤上,而不是將整個(gè)訓(xùn)練數(shù)據(jù)集載入內(nèi)存(內(nèi)存放不下),然后逐個(gè)讀取數(shù)據(jù),更新模型的權(quán)重:
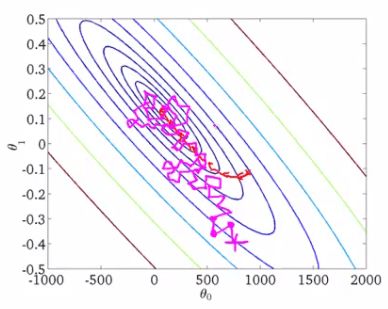
在處理完整個(gè)訓(xùn)練數(shù)據(jù)集后,我們的損失函數(shù)會(huì)下降,不過(guò)通常需要幾十個(gè)epoch之后損失函數(shù)的值才足夠小。
這一學(xué)習(xí)的方法稱為在線學(xué)習(xí),早在機(jī)器學(xué)習(xí)MOOC成為主流之前,這一術(shù)語(yǔ)就出現(xiàn)了。
這里我們沒(méi)有討論SGD的很多細(xì)節(jié)。如果你想要深入這一理論,我強(qiáng)烈推薦Stephen Boyd寫的《Convex Optimization》一書。現(xiàn)在,我們將介紹Vowpal Wabbit庫(kù),感謝隨機(jī)優(yōu)化和特征哈希,它非常擅長(zhǎng)在大規(guī)模數(shù)據(jù)集上訓(xùn)練簡(jiǎn)單模型。
在scikit-learn中,基于SGD訓(xùn)練的分類器和回歸器稱為SGDClassifier和SGDRegressor(見(jiàn)sklearn.linear_model)。這些是很好的SGD實(shí)現(xiàn),不過(guò)我們將使用VW,因?yàn)樵谠S多方面,它的性能比sklean的SGD模型要好。
2. 類別數(shù)據(jù)處理
2.1 標(biāo)簽編碼
許多分類算法和回歸算法基于歐幾里得空間運(yùn)作,這意味著數(shù)據(jù)表示為由實(shí)數(shù)組成的向量。然而,真實(shí)數(shù)據(jù)中我們常常碰到具有離散值的類別變量,比如是/否,一月/二月/.../十二月。下面我們將討論如何處理這類數(shù)據(jù),特別是配合線性模型使用的情況下。
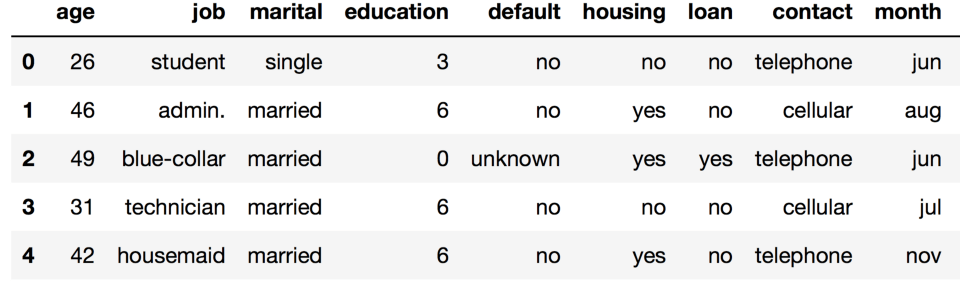
讓我們探索一下UCI bank marketing數(shù)據(jù)集,其中大部分特征是類別特征。
df = pd.read_csv(os.path.join(PATH_TO_ALL_DATA, 'bank_train.csv'))
labels = pd.read_csv(os.path.join(PATH_TO_ALL_DATA,
'bank_train_target.csv'), header=None)
df.head()
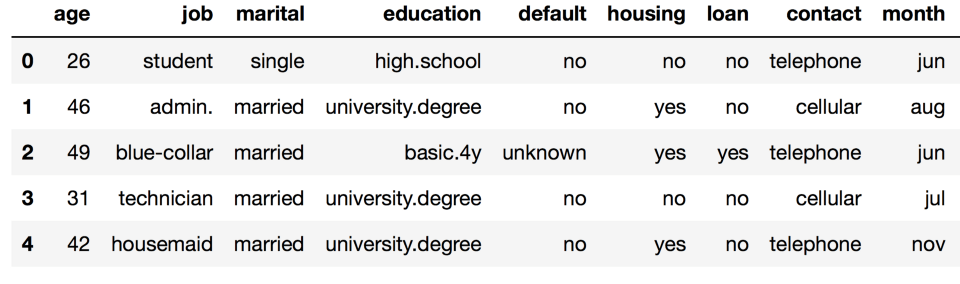
你可以看到,大部分特征并不由數(shù)字表示。這就帶來(lái)了一個(gè)問(wèn)題,我們無(wú)法直接使用大多數(shù)機(jī)器學(xué)習(xí)方法(至少就那些scikit-learn實(shí)現(xiàn)的而言)。
讓我們深入查看一下“教育”特征。
df['education'].value_counts().plot.barh();
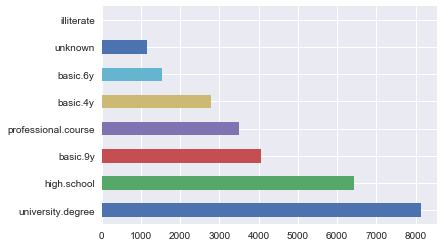
最直截了當(dāng)?shù)姆桨甘菍⑦@一特征的每個(gè)值映射為唯一的數(shù)字。例如,我們可以將university.degree映射為0,basic.9y映射為1,等等。我們可以使用sklearn.preprocessing.LabelEncoder進(jìn)行這一映射。
label_encoder = LabelEncoder()
mapped_education = pd.Series(label_encoder.fit_transform(
df['education']))
mapped_education.value_counts().plot.barh()
print(dict(enumerate(label_encoder.classes_)))
輸出:
{0: 'basic.4y', 1: 'basic.6y', 2: 'basic.9y', 3: 'high.school', 4: 'illiterate', 5: 'professional.course', 6: 'university.degree', 7: 'unknown'}
df['education'] = mapped_education
df.head()
同樣,我們轉(zhuǎn)換其他列:
categorical_columns = df.columns[df.dtypes
== 'object'].union(['education'])
for column in categorical_columns:
df[column] = label_encoder.fit_transform(df[column])
df.head()
這種方法的主要問(wèn)題是我們現(xiàn)在引入了一些可能并不存在的相對(duì)順序。
例如,我們隱式地引入了職業(yè)特征的代數(shù),我們現(xiàn)在可以從客戶一的職業(yè)中減去客戶二的職業(yè):
df.loc[1].job - df.loc[2].job # -1.0
這樣的操作有意義嗎?沒(méi)有。讓我們嘗試基于這一特征轉(zhuǎn)換訓(xùn)練邏輯回歸。
def logistic_regression_accuracy_on(dataframe, labels):
features = dataframe.as_matrix()
train_features, test_features, train_labels, test_labels =
train_test_split(features, labels)
logit = LogisticRegression()
logit.fit(train_features, train_labels)
return classification_report(test_labels,
logit.predict(test_features))
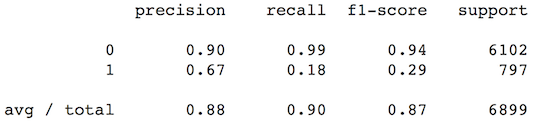
print(logistic_regression_accuracy_on(df[categorical_columns],
labels))

我們可以看到,邏輯回歸從未預(yù)測(cè)分類1. 為了在類別特征上使用線性模型,我們需要使用一種不同的方法:獨(dú)熱編碼(One-Hot Encoding)。
2.2 獨(dú)熱編碼
假設(shè)某項(xiàng)特征可能有10個(gè)唯一值。獨(dú)熱編碼為每個(gè)唯一值創(chuàng)建一個(gè)新特征,這10個(gè)特征中,除了一個(gè)特征以外,所有特征的值為零。

sklearn.preprocessing的OneHotEncoder類實(shí)現(xiàn)了獨(dú)熱編碼。默認(rèn)情況下,OneHotEncoder將數(shù)據(jù)轉(zhuǎn)換為一個(gè)稀疏矩陣,以節(jié)約內(nèi)存空間。不過(guò),在這一特定問(wèn)題中,我們沒(méi)有碰到內(nèi)存問(wèn)題,所以我們將使用“密集”矩陣表示。
onehot_encoder = OneHotEncoder(sparse=False)
encoded_categorical_columns =
pd.DataFrame(onehot_encoder.fit_transform(
df[categorical_columns]))
encoded_categorical_columns.head()
轉(zhuǎn)換維獨(dú)熱編碼之后,就可以使用線性模型了:
print(logistic_regression_accuracy_on(encoded_categorical_columns, labels))
2.3 哈希技巧
真實(shí)數(shù)據(jù)可能是易變的,意味著我們無(wú)法保證類別特征不會(huì)出現(xiàn)新值。這一問(wèn)題阻礙了訓(xùn)練好的模型在新數(shù)據(jù)上的應(yīng)用。除此以外,LabelEncoder需要對(duì)整個(gè)數(shù)據(jù)集進(jìn)行初步分析,并將構(gòu)建的映射保存在內(nèi)存中,這使得在大型數(shù)據(jù)集上運(yùn)用標(biāo)簽編碼變得困難。
有一個(gè)基于哈希的向量化類別數(shù)據(jù)的簡(jiǎn)單方法,毫不意外地,它被稱為哈希技巧。
哈希函數(shù)可以幫助我們?yōu)椴煌奶卣髦嫡业轿ㄒ坏木幋a,例如:
for s in ('university.degree', 'high.school', 'illiterate'):
print(s, '->', hash(s))
結(jié)果:
university.degree -> -6241459093488141593
high.school -> 7728198035707179500
illiterate -> -7360093633803373451
我們不打算使用負(fù)值,或者數(shù)量級(jí)很大的值,所以我們將限制哈希值的范圍:
hash_space = 25
for s in ('university.degree', 'high.school', 'illiterate'):
print(s, '->', hash(s) % hash_space)
university.degree -> 7
high.school -> 0
illiterate -> 24
想象下我們的數(shù)據(jù)集包含一個(gè)單身學(xué)生,他在周一接到一個(gè)電話。他的特征向量會(huì)類似于通過(guò)獨(dú)熱編碼創(chuàng)建的向量:
hashing_example = pd.DataFrame([{i: 0.0for i in range(hash_space)}])
for s in ('job=student', 'marital=single', 'day_of_week=mon'):
print(s, '->', hash(s) % hash_space)
hashing_example.loc[0, hash(s) % hash_space] = 1
hashing_example
job=student -> 20
marital=single -> 23
day_of_week=mon -> 9

我們哈希的不是特征值,而是特征名 + 特征值對(duì)。這樣我們就可以區(qū)分不同特征的相同值。
使用哈希編碼可能會(huì)遇到碰撞嗎?當(dāng)然有可能,不過(guò)只要哈希空間足夠大,碰撞很罕見(jiàn)。即使碰撞真的發(fā)生了,回歸或分類表現(xiàn)也不會(huì)受多大影響。在這一情形下,哈希碰撞就像是一種正則化的形式。
你也許會(huì)說(shuō)“尼瑪這什么玩意?”;哈希看起來(lái)就違背直覺(jué)。然而,事實(shí)上,有時(shí)這是唯一可行的處理類別數(shù)據(jù)的方法。而且,這一技術(shù)已被證實(shí)就是好使。等你處理了足夠多的數(shù)據(jù)之后,你可能自己意識(shí)到這一點(diǎn)。
3. Vowpal Wabbit
Vowpal Wabbit(VW)是業(yè)界使用最廣泛的機(jī)器學(xué)習(xí)庫(kù)之一。它的訓(xùn)練速度很快,支持許多訓(xùn)練模式,特別是在大數(shù)據(jù)和高維數(shù)據(jù)方面表現(xiàn)出色。同時(shí),由于VM實(shí)現(xiàn)了哈希技巧,它是一個(gè)處理文本數(shù)據(jù)的完美選擇。
VW可以作為命令行工具使用。輸入以下命令訪問(wèn)VW的幫助頁(yè)面:
vw --help
vw可以從文件或stdin讀取數(shù)據(jù),數(shù)據(jù)格式如下:
[Label] [Importance] [Tag]|NamespaceFeatures |NamespaceFeatures ... |NamespaceFeatures
Namespace=String[:Value]
Features=(String[:Value] )*
其中,[]表示可選元素,(...)*表示接受多個(gè)輸入。
Label(標(biāo)簽)是一個(gè)數(shù)字。在分類問(wèn)題中,它通常是1或-1;在回歸問(wèn)題中,它是一個(gè)實(shí)數(shù)(浮點(diǎn)數(shù))。
Importance(重要性)是一個(gè)數(shù)字。它指明了樣本的權(quán)重。處理失衡數(shù)據(jù)時(shí),設(shè)定Importance很有用。
Tag(標(biāo)記)是不含空格的字符串。它是樣本的“名稱”。
Namespace(命名空間)用于創(chuàng)建不同的特征空間。
Features是給定Namespace中的特征。特征默認(rèn)權(quán)重為1.0,但可以調(diào)整,例如feature:0.1
例如,以下字符串匹配VW格式:
11.0 |Subject WHAT car isthis |OrganizationUniversity of Maryland:0.5CollegePark
我們可以將其傳給vw:
echo '1 1.0 |Subject WHAT car is this |Organization University of Maryland:0.5 College Park' | vw
VW是一個(gè)非常棒的處理文本數(shù)據(jù)的工具。我們將通過(guò)20newsgroups數(shù)據(jù)集展示這一點(diǎn),該數(shù)據(jù)集包含來(lái)自20種不同新聞組的信息。
3.1 新聞:二元分類
使用sklearn函數(shù)加載數(shù)據(jù):
newsgroups = fetch_20newsgroups(PATH_TO_ALL_DATA)
newsgroups['target_names']
新聞組的20項(xiàng)主題為:
['alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc']
讓我們看下第一封消息:
text = newsgroups['data'][0]
target = newsgroups['target_names'][newsgroups['target'][0]]
print('-----')
print(target)
print('-----')
print(text.strip())
print('----')
輸出:
-----
rec.autos
-----
From: lerxst@wam.umd.edu (where's my thing)
Subject: WHAT car is this!?
Nntp-Posting-Host: rac3.wam.umd.edu
Organization: University of Maryland, College Park
Lines: 15
I was wondering if anyone out there could enlighten me on this car I saw
the other day. It was a 2-door sports car, looked to be from the late 60s/
early 70s. It was called a Bricklin. The doors were really small. In addition,
the front bumper was separate from the rest of the body. This is
all I know. If anyone can tellme a model name, engine specs, years
of production, where this car is made, history, or whatever info you
have on this funky looking car, please e-mail.
Thanks,
- IL
---- brought to you by your neighborhood Lerxst ----
----
現(xiàn)在我們將把數(shù)據(jù)轉(zhuǎn)換為Vowpal Wabbit可以理解的格式。我們將丟棄所有短于3個(gè)符號(hào)的單詞。這里,我們跳過(guò)了一些重要的NLP步驟,像是詞干提取和詞形還原;不過(guò),我們之后將看到,即使沒(méi)有這些步驟,VW仍然解決了問(wèn)題。
def to_vw_format(document, label=None):
return str(label or'') + ' |text ' + ' '.join(re.findall('w{3,}',
document.lower())) + ' '
to_vw_format(text, 1if target == 'rec.autos'else -1)
輸出:
'1 |text from lerxst wam umd edu where thing subject what car this nntp posting host rac3 wam umd edu organization university maryland college park lines was wondering anyone out there could enlighten this car saw the other day was door sports car looked from the late 60s early 70s was called bricklin the doors were really small addition the front bumper was separate from the rest the body this all know anyone can tellme model name engine specs years production where this car made history whatever info you have this funky looking car please mail thanks brought you your neighborhood lerxst '
我們將數(shù)據(jù)集分為訓(xùn)練集和測(cè)試集,并將其分別寫入不同的文件。如果一份文檔和rec.autos相關(guān),那么我們就將它視作正面樣本。所以,我們正構(gòu)建一個(gè)模型,區(qū)分出汽車有關(guān)的文章:
all_documents = newsgroups['data']
all_targets = [1if newsgroups['target_names'][target] == 'rec.autos'
else -1for target in newsgroups['target']]
train_documents, test_documents, train_labels, test_labels =
train_test_split(all_documents, all_targets, random_state=7)
with open(os.path.join(PATH_TO_ALL_DATA, '20news_train.vw'), 'w') as vw_train_data:
for text, target in zip(train_documents, train_labels):
vw_train_data.write(to_vw_format(text, target))
with open(os.path.join(PATH_TO_ALL_DATA, '20news_test.vw'), 'w') as vw_test_data:
for text in test_documents:
vw_test_data.write(to_vw_format(text))
現(xiàn)在,我們將創(chuàng)建的訓(xùn)練文件傳給Vowpal Wabbit。我們通過(guò)鉸鏈(hinge)損失函數(shù)(線性SVM)求解這一分類問(wèn)題。訓(xùn)練好的模型將保存在20news_model.vw文件中:
vw -d $PATH_TO_ALL_DATA/20news_train.vw
--loss_function hinge -f $PATH_TO_ALL_DATA/20news_model.vw
輸出:
final_regressor = ../../data//20news_model.vw
Num weight bits = 18
learning rate = 0.5
initial_t = 0
power_t = 0.5
usingno cache
Reading datafile = ../../data//20news_train.vw
num sources = 1
average since example example current current current
loss last counter weight label predict features
1.0000001.000000 1 1.0 -1.0000 0.0000 157
0.9112760.822551 2 2.0 -1.0000 -0.1774 159
0.6057930.300311 4 4.0 -1.0000 -0.3994 92
0.4195940.233394 8 8.0 -1.0000 -0.8167 129
0.3139980.208402 16 16.0 -1.0000 -0.6509 108
0.1960140.078029 32 32.0 -1.0000 -1.0000 115
0.1831580.170302 64 64.0 -1.0000 -0.7072 114
0.2610460.338935 128 128.0 1.0000 -0.7900 110
0.2629100.264774 256 256.0 -1.0000 -0.6425 44
0.2166630.170415 512 512.0 -1.0000 -1.0000 160
0.1767100.136757 1024 1024.0 -1.0000 -1.0000 194
0.1345410.092371 2048 2048.0 -1.0000 -1.0000 438
0.1044030.074266 4096 4096.0 -1.0000 -1.0000 644
0.0813290.058255 8192 8192.0 -1.0000 -1.0000 174
finished run
number of examples per pass = 8485
passes used = 1
weighted example sum = 8485.000000
weighted label sum = -7555.000000
average loss = 0.079837
best constant = -1.000000
best constant's loss = 0.109605
total feature number = 2048932
VW在訓(xùn)練時(shí)會(huì)打印很多信息(你可以通過(guò)--quiet參數(shù)讓VW少輸出信息)。關(guān)于VW輸出信息的說(shuō)明,可以參考GitHub上的文檔。就目前而言,我們可以看到,隨著訓(xùn)練的進(jìn)行,平均損失下降了。VW使用之前未見(jiàn)的樣本計(jì)算損失,所以VW的平均損失通常比較準(zhǔn)確。現(xiàn)在,我們將訓(xùn)練好的模型應(yīng)用于測(cè)試集,并將預(yù)測(cè)保存到由-p指定的文件:
vw -i $PATH_TO_ALL_DATA/20news_model.vw -t -d $PATH_TO_ALL_DATA/20news_test.vw
-p $PATH_TO_ALL_DATA/20news_test_predictions.txt
現(xiàn)在我們加載預(yù)測(cè),計(jì)算AUC,并繪制ROC曲線:
with open(os.path.join(PATH_TO_ALL_DATA,
'20news_test_predictions.txt')) as pred_file:
test_prediction = [float(label)
for label in pred_file.readlines()]
auc = roc_auc_score(test_labels, test_prediction)
roc_curve = roc_curve(test_labels, test_prediction)
with plt.xkcd():
plt.plot(roc_curve[0], roc_curve[1]);
plt.plot([0,1], [0,1])
plt.xlabel('FPR'); plt.ylabel('TPR');
plt.title('test AUC = %f' % (auc));
plt.axis([-0.05,1.05,-0.05,1.05]);
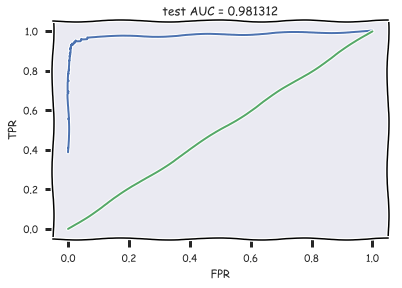
可以看到,我們達(dá)到了很高的分類質(zhì)量。
3.2 新聞:多元分類
我們?nèi)詫⑹褂弥暗男侣劷M數(shù)據(jù)集。不過(guò),這次我們將解決一個(gè)多元分類問(wèn)題。VW要求標(biāo)簽從1開始,而sklearn的LabelEncoder的標(biāo)簽則從0開始。因此,我們需要在LabelEncoder的編碼上加1:
all_documents = newsgroups['data']
topic_encoder = LabelEncoder()
all_targets_mult = topic_encoder.fit_transform(newsgroups['target']) + 1
仍然像之前一樣,我們切分訓(xùn)練集和測(cè)試集,并保存到不同文件。
train_documents, test_documents, train_labels_mult, test_labels_mult =
train_test_split(all_documents, all_targets_mult, random_state=7)
with open(os.path.join(PATH_TO_ALL_DATA,
'20news_train_mult.vw'), 'w') as vw_train_data:
for text, target in zip(train_documents, train_labels_mult):
vw_train_data.write(to_vw_format(text, target))
with open(os.path.join(PATH_TO_ALL_DATA,
'20news_test_mult.vw'), 'w') as vw_test_data:
for text in test_documents:
vw_test_data.write(to_vw_format(text))
我們將在多元分類模式下訓(xùn)練Vowpal Wabbit,在oaa參數(shù)中傳入分類的數(shù)目。同時(shí),讓我們看下模型的一些參數(shù)(更多信息可以在Vowpal Wabbit的官方教程中找到):
學(xué)習(xí)率(-l,默認(rèn)0.5)每步權(quán)重改變的比率
學(xué)習(xí)率衰減(--power_t,默認(rèn)0.5)實(shí)踐表明,如果學(xué)習(xí)率隨著隨機(jī)梯度下降的推進(jìn)而下降,我們能更好地逼近損失的最小值
損失函數(shù)(--loss_function)整個(gè)訓(xùn)練算法取決于損失函數(shù)的選擇。可以參考損失函數(shù)的文檔。
正則化(-l1)注意VW為每個(gè)對(duì)象計(jì)算正則化。所以我們通常將正則值設(shè)為10-20左右。
此外,你也可以嘗試使用Hyperopt自動(dòng)調(diào)整Vowpal Wabbit參數(shù)。
vw — oaa 20 $PATH_TO_ALL_DATA/20news_train_mult.vw -f $PATH_TO_ALL_DATA/20news_model_mult.vw
— loss_function=hinge
vw -i $PATH_TO_ALL_DATA/20news_model_mult.vw -t -d $PATH_TO_ALL_DATA/20news_test_mult.vw
-p $PATH_TO_ALL_DATA/20news_test_predictions_mult.txt
讓我們看看結(jié)果如何:
with open(os.path.join(PATH_TO_ALL_DATA,
'20news_test_predictions_mult.txt')) as pred_file:
test_prediction_mult = [float(label)
for label in pred_file.readlines()]
accuracy_score(test_labels_mult, test_prediction_mult)
輸出:
0.8734535171438671
在測(cè)試集上的精確度超過(guò)87%,還不錯(cuò)。
3.3 IMDB影評(píng)
這一節(jié)中,我們將對(duì)IMDB影評(píng)進(jìn)行二元分類。影評(píng)數(shù)據(jù)可從Google網(wǎng)盤下載:
https://drive.google.com/file/d/1xq4l5c0JrcxJdyBwJWvy0u9Ad_pvkJ1l/view
我們使用sklearn.datasets的load_files函數(shù)加載影評(píng)。數(shù)據(jù)集已經(jīng)分為訓(xùn)練集、測(cè)試集兩部分,各包含12500好評(píng)、12500差評(píng)。首先,我們將分割文本和標(biāo)簽:
import pickle
path_to_movies = os.path.expanduser('imdb_reviews')
reviews_train = load_files(os.path.join(path_to_movies, 'train'))
text_train, y_train = reviews_train.data, reviews_train.target
reviews_test = load_files(os.path.join(path_to_movies, 'test'))
text_test, y_test = reviews_test.data, reviews_train.target
查看一些影評(píng)的例子和相應(yīng)的標(biāo)簽:
text_train[0]
輸出:
b"Zero Day leads you to think, even re-think why two boys/young men would do what they did - commit mutual suicide via slaughtering their classmates. It captures what must be beyond a bizarre mode of being for two humans who have decided to withdraw from common civility in order to define their own/mutual world via coupled destruction.
It is not a perfect movie but given what money/time the filmmaker and actors had - it is a remarkable product. In terms of explaining the motives and actions of the two young suicide/murderers it is better than 'Elephant' - in terms of being a film that gets under our 'rationalistic' skin it is a far, far better film than almost anything you are likely to see.
Flawed but honest with a terrible honesty."
這是好評(píng)還是差評(píng)?
y_train[0]
輸出:
1
看來(lái)是好評(píng)。
再看一條:
text_train[1]
輸出:
b'Words can't describe how bad this movie is. I can't explain it by writing only. You have too see it for yourself to get at grip of how horrible a movie really can be. Not that I recommend you to do that. There are so many clichxc3xa9s, mistakes (and all other negative things you can imagine) here that will just make you cry. To start with the technical first, there are a LOT of mistakes regarding the airplane. I won't list them here, but just mention the coloring of the plane. They didn't even manage to show an airliner in the colors of a fictional airline, but instead used a 747 painted in the original Boeing livery. Very bad. The plot is stupid and has been done many times before, only much, much better. There are so many ridiculous moments here that i lost count of it really early. Also, I was on the bad guys' side all the time in the movie, because the good guys were so stupid. "Executive Decision" should without a doubt be you're choice over this one, even the "Turbulence"-movies are better. In fact, every other movie in the world is better than this one.'
這條是好評(píng)還是差評(píng)?
y_train[1]
輸出:
0
嗯,這條是差評(píng)。
如前所述,數(shù)據(jù)集已經(jīng)分成訓(xùn)練集和測(cè)試集兩部分。現(xiàn)在我們?cè)購(gòu)挠?xùn)練集中切分30%出來(lái)作為驗(yàn)證集。
train_share = int(0.7 * len(text_train))
train, valid = text_train[:train_share], text_train[train_share:]
train_labels, valid_labels = y_train[:train_share], y_train[train_share:]
同樣,我們將它們保存到文件:
with open(os.path.join(PATH_TO_ALL_DATA, 'movie_reviews_train.vw'), 'w') as vw_train_data:
for text, target in zip(train, train_labels):
vw_train_data.write(to_vw_format(str(text), 1if target == 1else -1))
with open(os.path.join(PATH_TO_ALL_DATA, 'movie_reviews_valid.vw'), 'w') as vw_train_data:
for text, target in zip(valid, valid_labels):
vw_train_data.write(to_vw_format(str(text), 1if target == 1else -1))
with open(os.path.join(PATH_TO_ALL_DATA, 'movie_reviews_test.vw'), 'w') as vw_test_data:
for text in text_test:
vw_test_data.write(to_vw_format(str(text)))
然后運(yùn)行Vowpal Wabbit(我們?nèi)匀皇褂勉q鏈損失,不過(guò)你可以試驗(yàn)其他算法):
vw -d $PATH_TO_ALL_DATA/movie_reviews_train.vw --loss_function hinge -f $PATH_TO_ALL_DATA/movie_reviews_model.vw --quiet
訓(xùn)練完成后,讓我們?cè)诹糁玫尿?yàn)證集上測(cè)試一下表現(xiàn):
vw -i $PATH_TO_ALL_DATA/movie_reviews_model.vw -t
-d $PATH_TO_ALL_DATA/movie_reviews_valid.vw -p $PATH_TO_ALL_DATA/movie_valid_pred.txt --quiet
從文件讀取預(yù)測(cè),并估計(jì)精確度和AUC。
with open(os.path.join(PATH_TO_ALL_DATA, 'movie_valid_pred.txt')) as pred_file:
valid_prediction = [float(label)
for label in pred_file.readlines()]
print("Accuracy: {}".format(round(accuracy_score(valid_labels,
[int(pred_prob > 0) for pred_prob in valid_prediction]), 3)))
print("AUC: {}".format(round(roc_auc_score(valid_labels, valid_prediction), 3)))
輸出:
Accuracy: 0.885
AUC: 0.942
在測(cè)試集上如法炮制:
vw -i $PATH_TO_ALL_DATA/movie_reviews_model.vw -t -d $PATH_TO_ALL_DATA/movie_reviews_test.vw -p $PATH_TO_ALL_DATA/movie_test_pred.txt --quiet
with open(os.path.join(PATH_TO_ALL_DATA, 'movie_test_pred.txt')) as pred_file:
test_prediction = [float(label)
for label in pred_file.readlines()]
print("Accuracy: {}".format(round(accuracy_score(y_test,
[int(pred_prob > 0) for pred_prob in test_prediction]), 3)))
print("AUC: {}".format(round(roc_auc_score(y_test, test_prediction), 3)))
和我們期望的一樣,精確度和AUC幾乎和驗(yàn)證集上一樣:
Accuracy: 0.88
AUC: 0.94
讓我們嘗試下n元語(yǔ)法,看看能不能提高精確度:
vw -d $PATH_TO_ALL_DATA/movie_reviews_train.vw --loss_function hinge --ngram 2 -f $PATH_TO_ALL_DATA/movie_reviews_model2.vw --quiet
vw -i$PATH_TO_ALL_DATA/movie_reviews_model2.vw -t -d $PATH_TO_ALL_DATA/movie_reviews_valid.vw -p $PATH_TO_ALL_DATA/movie_valid_pred2.txt --quiet
vw -i $PATH_TO_ALL_DATA/movie_reviews_model2.vw -t -d $PATH_TO_ALL_DATA/movie_reviews_test.vw -p $PATH_TO_ALL_DATA/movie_test_pred2.txt --quiet
效果不錯(cuò):
# 驗(yàn)證集
Accuracy: 0.894
AUC: 0.954
# 測(cè)試集
Accuracy: 0.888
AUC: 0.952
3.4 分類StackOverflow問(wèn)題
現(xiàn)在,讓我們看看Vowpal Wabbit在大型數(shù)據(jù)集上的表現(xiàn)。我們將使用一個(gè)10GB的StackOverflow問(wèn)答數(shù)據(jù)集:
https://drive.google.com/file/d/1ZU4J3KhJDrHVMj48fROFcTsTZKorPGlG/view?usp=sharing
原始數(shù)據(jù)集由一千萬(wàn)問(wèn)題組成,每個(gè)問(wèn)題有多個(gè)標(biāo)簽。數(shù)據(jù)相當(dāng)整潔,所以別叫它“大數(shù)據(jù)”,即使是在酒館中。:)
我們僅僅選取了10個(gè)標(biāo)簽:javascript、java、python、ruby、php、c++、c#、go、scala、swift。讓我們解決這一十元分類問(wèn)題:我們想根據(jù)問(wèn)題的文本預(yù)測(cè)這個(gè)問(wèn)題的標(biāo)簽是10個(gè)流行的編程語(yǔ)言中的哪一個(gè)。
選取10個(gè)標(biāo)簽后,我們得到了一個(gè)4.7G的數(shù)據(jù)集,并將其切分為訓(xùn)練集和測(cè)試集。
我們將用Vowpal Wabbit處理訓(xùn)練集(3.1 GiB):
vw --oaa 10 -d $PATH_TO_STACKOVERFLOW_DATA/stackoverflow_train.vw -f vw_model1_10mln.vw -b 28 --random_seed 17 --quiet
其中,--oaa 10表示我們有10個(gè)分類,-b 28表示我們將使用28位哈希,也就是228特征空間,--random_seed 17固定隨機(jī)數(shù)種子,以便復(fù)現(xiàn)。
訓(xùn)練完成之后,看看模型在測(cè)試集上的表現(xiàn):
vw -t -i vw_model1_10mln.vw -d $PATH_TO_STACKOVERFLOW_DATA/stackoverflow_test.vw -p vw_test_pred.csv --random_seed 17 --quiet
vw_pred = np.loadtxt(os.path.join(PATH_TO_STACKOVERFLOW_DATA,
'vw_test_pred.csv'))
test_labels = np.loadtxt(os.path.join(PATH_TO_STACKOVERFLOW_DATA,
'stackoverflow_test_labels.txt'))
accuracy_score(test_labels, vw_pred)
結(jié)果:
0.91728604842865913
模型的訓(xùn)練和預(yù)測(cè)在不到1分鐘內(nèi)就完成了(我使用的是2015年中期的MacBook Pro,2.2 GHz Intel Core i7,16GB RAM)。精確度差不多達(dá)到了92%。我們沒(méi)有使用什么Hadoop集群就做到了這一點(diǎn)。:) 令人印象深刻,不是嗎?
4. 相關(guān)資源
VW的官方文檔
Deep Learning(《深度學(xué)習(xí)》)一書的數(shù)值計(jì)算那一章
Stephen Boyd寫的Convex Optimization一書
Adam Drake寫的博客文章Command-line Tools can be 235x Faster than your Hadoop Cluster
GitHub上的多種ML算法在Criteo 1TB數(shù)據(jù)集上的評(píng)測(cè)rambler-digital-solutions/criteo-1tb-benchmark
FastML博客上VW分類的帖子
-
函數(shù)
+關(guān)注
關(guān)注
3文章
4304瀏覽量
62429 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8377瀏覽量
132406 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24641
原文標(biāo)題:機(jī)器學(xué)習(xí)開放課程(八):使用Vowpal Wabbit高速學(xué)習(xí)大規(guī)模數(shù)據(jù)集
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
分享一個(gè)自己寫的機(jī)器學(xué)習(xí)線性回歸梯度下降算法
機(jī)器學(xué)習(xí)新手必學(xué)的三種優(yōu)化算法(牛頓法、梯度下降法、最速下降法)
數(shù)據(jù)編碼技術(shù)
機(jī)器學(xué)習(xí):隨機(jī)梯度下降和批量梯度下降算法介紹
一文看懂常用的梯度下降算法
機(jī)器學(xué)習(xí)中梯度下降法的過(guò)程
梯度下降算法及其變種:批量梯度下降,小批量梯度下降和隨機(jī)梯度下降
機(jī)器學(xué)習(xí)之感知機(jī)python是如何實(shí)現(xiàn)的
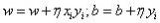
基于分布式編碼的同步隨機(jī)梯度下降算法

梯度下降法在機(jī)器學(xué)習(xí)中的應(yīng)用
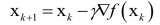
PyTorch教程12.4之隨機(jī)梯度下降

PyTorch教程12.5之小批量隨機(jī)梯度下降
PyTorch教程-12.4。隨機(jī)梯度下降

PyTorch教程-12.5。小批量隨機(jī)梯度下降






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論