 decaNLP通用模型誕生,可以輕松搞定十項自然語言任務
decaNLP通用模型誕生,可以輕松搞定十項自然語言任務
目前的NLP領域有一個問題:即使是再厲害的算法也只能針對特定的任務,比如適用于機器翻譯的模型不一定可以拿來做情感分析或摘要。
然而近日,Salesforce發布了一項新的研究成果:decaNLP——一個可以同時處理機器翻譯、問答、摘要、文本分類、情感分析等十項自然語言任務的通用模型。
Salesforce的首席科學家RichardSocher在接受外媒采訪時表示:我們的decaNLP就好比NLP領域的瑞士軍刀!
以下為人工智能頭條對Salesforce的論文概述《The Natural Language Decathlon》的編譯,enjoy!
▌引言
深度學習已經顯著地改善了自然語言處理任務中的最先進的性能,如機器翻譯、摘要、問答和文本分類。每一個任務都有一個特定的衡量標準,它們的性能通常是由一組基準數據集測量的。這也促進了專門設計這些任務和衡量標準的體系的發展,但是它可能不會促使那些能夠在各種自然語言處理(NLP)任務中表現良好的通用自然語言處理模型的涌現。為了探索這種通用模型的可能性以及在優化它們時產生的權衡關系,我們引入了自然語言十項全能(decaNLP)。
這個挑戰涵蓋了十個任務:問答、機器翻譯、摘要、自然語言推理、情感分析、語義角色標注、關系抽取、任務驅動多輪對話、數據庫查詢生成器和代詞消解。自然語言十項全能(decaNLP)的目標是開發出可以整合所有十個任務的模型,并研究這種模型與那些為單一任務訓練而準備的模型有何不同。出于這個原因,十項全能的表現會被一個統一的指標所衡量,該指標集合了所有十項任務的度量標準。
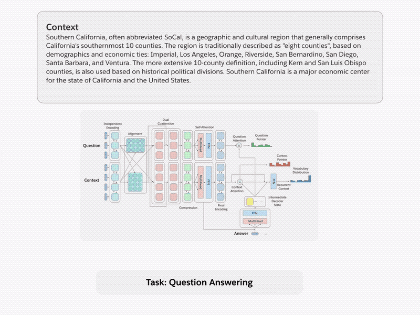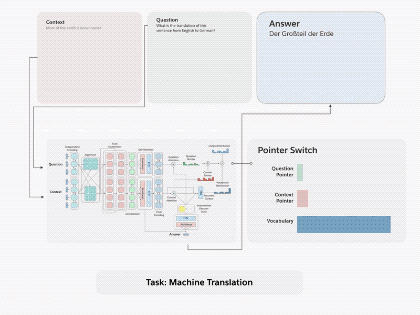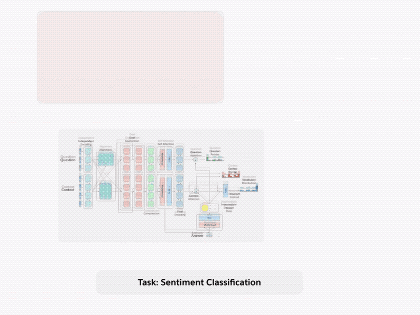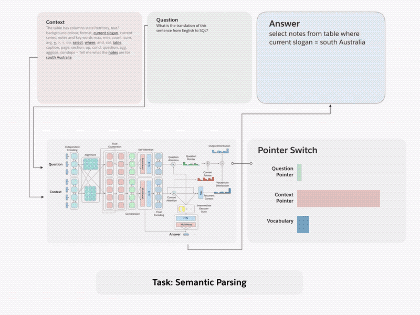
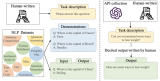
圖1.通過將 decaNLP的所有十個任務整合成問答形式,我們可以訓練一個通用的問答模型
我們把所有十個任務都統一轉化為問答的方式,提出了一個新的多任務問答網絡(MQAN),它是一個不需要特定任務的模塊或參數而進行共同學習任務的網絡。在機器翻譯和實體識別命名中,MQAN顯示出了遷移學習(Transfer learning)方面的改進。在情感分析和自然語言推理中,MQAN顯示出了在領域適應方面的改進,同時對于文本分類方面也顯示出了其zero-shot的能力。
在與基線的比較中,我們證明了MQAN的多指針編解碼器(multi-pointer-generator decoder)是成功的關鍵,并且使用相反的訓練策略(anti-curriculum training strategy)進一步改進了性能。 盡管該設計用于decaNLP和通用的問答,MQAN恰好也能在單任務設置中表現良好:它在WikiSQL語義解析任務上與單項模型最佳成績旗鼓相當,任務驅動型對話任務中它排名第二,在SQuAD數據集不直接使用跨監督方法的模型中它得分最高,同時在其他任務中也表現良好。decaNLP的從獲取和處理數據、訓練和評估模型到復現實驗的所有代碼已經開源。
▌任務
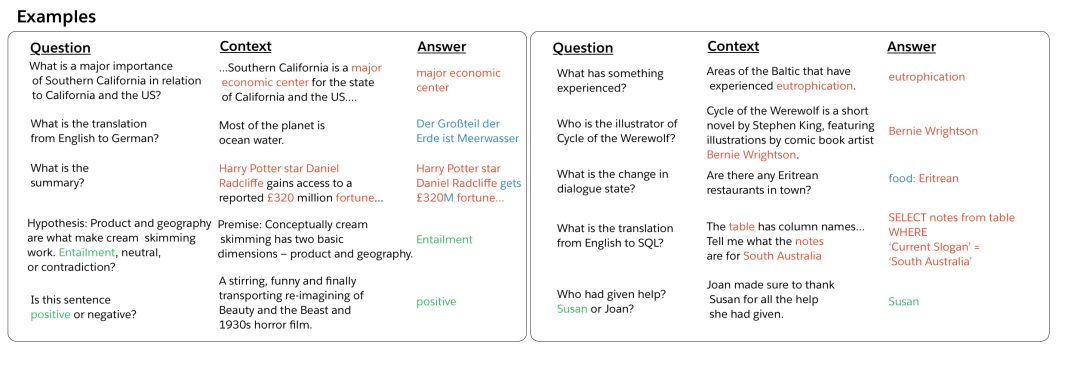
圖2.(問題、上下文、答案)問答、機器翻譯、摘要、自然語言推理、情感分析、詞性標注、關系抽取、目標導向對話、語義解析和代詞解析任務的例子
讓我們首先開始討論這些任務及其相關數據集。我們的論文包含更多的細節,包括對每個任務的歷史背景和最近的工作進行更深入的討論。每個任務的輸入-輸出對示例如上圖所示。
問答。問答(QA)模型接收一個問題以及它所包含的必要的信息的上下文來輸出理想的答案。我們使用斯坦福問答數據集的原始版本(SQuAD)來完成這項任務。該上下文是從英文維基百科中摘取的段落,答案是從文章中復制的單詞序列。
機器翻譯。機器翻譯模型以源語言文本的形式為輸入,輸出為翻譯好的目標語言。我們使用2016年為國際口語翻譯研討會(IWSLT)準備的英譯德數據為訓練數據集,使用2013年和2014年的測試集作為驗證集和測試集。這些例子來自TED演講,涵蓋了會話語言的各種主題。這是一個相對較小的機器翻譯數據集,但是它與其他任務的數據集大致相同。當然你還可以使用額外的訓練資源,比如機器翻譯大賽(WMT)中的數據集。
摘要。摘要模型接收一個文檔并輸出該文檔的摘要。如今在摘要方面最重要的進展是將CNN/DailyMail (美國有線電視新聞網/每日郵報)語料庫轉換成一個摘要數據集。我們在decaNLP中包含這個數據集的非匿名版本。平均來講,這些實例包含了該挑戰賽中最長的文檔,以及從上下文直接提取答案與語境外生成答案之間平衡的force Model。
自然語言推理。自然語言推理(NLI)模型接受兩個輸入句子:一個前提和一個假設。模型必須將前提和假設之間的推理關系歸類為支持、中立或矛盾。我們使用的是多體裁自然語言推理語料庫(MNLI),它提供來自多個領域的訓練示例(轉錄語音、通俗小說、政府報告)和來自各個領域的測試對。
情感分析。情感分析模型被訓練用來對輸入文本表達的情感進行分類。斯坦福情感樹庫(SST)由一些帶有相應的情緒(積極的,中立的,消極的)的影評所組成。我們使用未解析的二進制版本,以便明確對decaNLP模型的解析依賴。
語義角色標注。語義角色標注(SRL)模型給出一個句子和謂語(通常是一個動詞),并且必須確定“誰對誰做了什么”、“什么時候”、“在哪里”。我們使用一個SRL數據集,該數據集將任務視為一種問答:QA-SRL。這個數據集涵蓋了新聞和維基百科的領域,但是為了確保decaNLP的所有數據都可以自由下載,我們只使用了后者。
關系抽取。關系抽取系統包含文本文檔和要從該文本中提取的關系類型。在這種情況下,模型需要先識別實體間的語義關系,再判斷是不是屬于目標種類。與SRL一樣,我們使用一個數據集,該數據集將關系映射到一組問題,以便關系抽取可以被視為一種問答形式:QA-ZRE。對數據集的評估是為了在新的關系上測量零樣本性能——數據集是分開的使得測試時看到的關系在訓練時是無法看到的。這種零樣本的關系抽取,以問答為框架,可以推廣到新的關系之中。
任務驅動多輪對話。對話狀態跟蹤是任務驅動多輪對話系統的關鍵組成部分。根據用戶的話語和系統動作,對話狀態跟蹤器會跟蹤用戶為對話系統設定了哪些事先設定目標,以及用戶在系統和用戶交互過程中發出了哪些請求。我們使用的是英文版的WOZ餐廳預訂服務,它提供了事先設定的關于食物、日期、時間、地址和其他信息的本體,可以幫助代理商為客戶進行預訂。
語義解析。SQL查詢生成與語義解析相關。基于WikiSQL數據集的模型將自然語言問題轉換為結構化SQL查詢,以便用戶可以使用自然語言與數據庫交互。
代詞消解。我們的最后一個任務是基于要求代詞解析的Winograd模式:“Joan一定要感謝Susan的幫助(給予/收到)。誰給予或者收到了幫助?Joan還是Susan?”。我們從Winograd模式挑戰中的示例開始,并對它們進行了修改(導致了修訂的Winograd模式挑戰,即MWSC),以確保答案是上下文中的單個單詞,并且分數不會因上下文、問題和答案之間的措辭或不一致而增加或者減少。
十項全能得分(decaScore)
在decaNLP上競爭的模型是被特定任務中度量標準的附加組合來評估的。所有的度量值都在0到100之間,因此十項全能得分在10個任務中的度量值在0到1000之間。使用附加組合可以避免我們在權衡不同指標時可能產生的隨意性。所有指標都不區分大小寫。我們將標準化的F1(nF1)用于問答、自然語言推理、情感分析、詞性標注和MWSC;平均值ROUGE-1、ROUGE-2、ROUGE-L作為摘要的評分等級;語料BLEU水平得分用于對機器翻譯進行評分;聯合目標跟蹤精確匹配分數和基于回合的請求精確匹配得分的平均值用于對目標導向進行評分;邏輯形式精確匹配得分用于WikiSQL上的語義解析;以及語料庫級F1評分等級,用于QA-ZRE的關系提取。
為了代替標準的驗證數據,我們選擇了按要求的decaNLP模型提交到原始的小組平臺進行測試。類似地,MNLI測試集不是公開的,decaNLP模型必須通過一個Kaggle系統來評估MNLI的測試性能。
▌多任務問答網絡(MQAN)
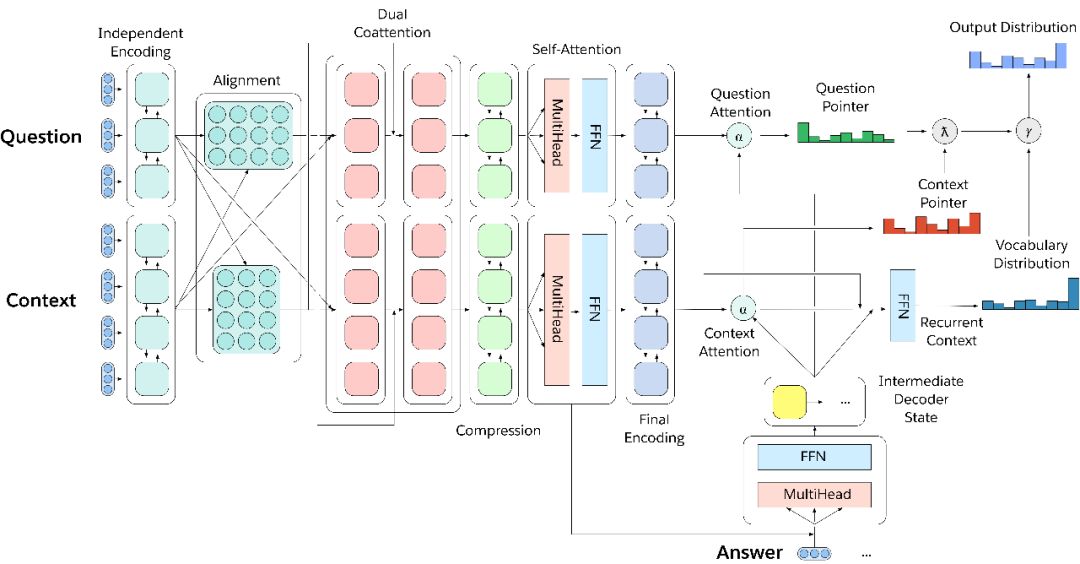
圖3.多任務問答網絡
為了有效地在所有decaNLP中進行多任務處理,我們引入了MQAN,一個多任務問題回答網絡,它沒有任何針對特定任務的參數和模塊。
簡單地說,MQAN采用一個問題和一個上下文背景文檔,用BiLSTM編碼,使用額外的共同關注對兩個序列的條件進行表示,用另兩個BiLSTM壓縮所有這些信息,使其能夠更高層進行計算,用自我關注的方式來收集這種長距離依賴關系,然后使用兩個BiLSTM對問題和背景環境的進行最終的表示。多指針生成器解碼器著重于問題、上下文以及先前輸出象征來決定是否從問題中復制,還是從上下文復制,或者從有限的詞匯表中生成。關于我們的模型的其他細節可以在我們的文章的第3節中找到。
▌基線和結果
除了MQAN,我們還嘗試了幾種基線方法并計算了它們的十項全能得分。第一個基線,S2S,是具有注意力和指針生成器的序列到序列的網絡。我們的第二基線,S2S w/SAtt,是一個S2S網絡,它在編碼器側的BiLTM層和解碼器側的LSTM層之間添加了自注意(Transformer)層。我們的第三個基線,+CAtt,將上下文和問題分成兩個序列,并在編碼器側添加一個額外的共同關注層。MQAN是一個種帶有附加問題指針的+CAtt模型,在我們的基線/消融研究中,它被稱為+QPtr。針對每一個模型,我們都提出了兩種實驗。第一,我們報告出十個任務模型中的單任務性能。第二,我們提出多任務性能,即模型在所有任務中被聯合訓練所體現出的性能。
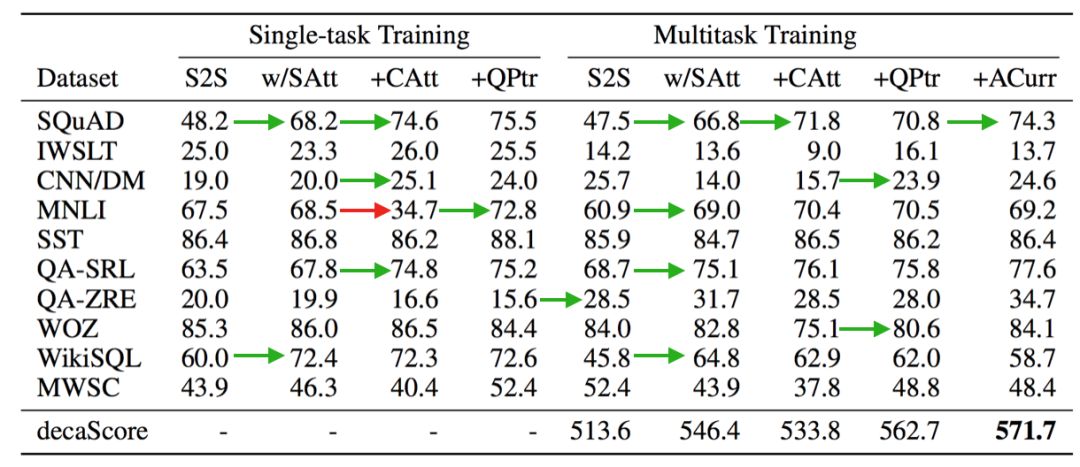
圖4.單任務和多任務實驗對不同模型和訓練策略的驗證結果
比較這些實驗的結果突出了在序列到序列和通用NLP問答方法之間的多任務和單任務之間的權衡關系。從S2S到S2S w/ SAtt提供了一種模型,該模型在混合上下文和輸入的系列問題中添加了附加關注層。這大大提高了 SQuAD和WiKISQL的性能,同時也提高了QA-SRL的性能。僅此一點就足以實現WiKISQL的最新技術性能。這也表明,如果不隱性地學習如何分離它們的表示方法,而顯性地去分離上下文和問題會使模型建立更豐富的表示方法。
下一個基線使用上下文和問題作為單獨的輸入序列,相當于使用一個共同關注機制(+CAT)來增強S2S模型,該機制分別構建了兩個序列表示。 使得每個SQuAD和QA-SRL的性能增加了 5 nF1。但遺憾的是,這種分離不能改善其他任務,并且極大地損害了MNLI和MWSC的性能。對于這兩個任務,可以直接從問題中復制答案,而不是像大多數其他任務那樣從上下文中復制答案。由于兩個S2S基線都將問題連接到上下文,所以指針生成器機制能夠直接從問題中復制。當上下文和問題被分成兩個不同的輸入時,模型就失去了這種能力。
為了補救這個問題,我們在前面的基線中添加了一個問題指針(+QPTR),一種在之前添加給MQAN的指針。這提高了MNLI和MWSC的性能,甚至能夠比S2S基線達到更高的分數。它也改善了在SQuAD,IWSLT和 CNN/DM上的性能,該模型在WiKISQL上實現了最新的成果,是面向目標的對話數據集的第二高執行模型,并且是非顯式地將問題建模為跨度提取的最高性能模型。因為當使用直接跨度監督時,我們會看到應用在通用問答中的一些局限性。
在多任務設置中,我們看到了類似的結果,但我們還注意到一些額外的顯著特性。在QA-ZRE中,零樣本關系提取,性能比最高的單任務模型提高11個點,這支持了多任務學習即使在零樣本情況下也能得到更好的泛化的假設。在需要大量使用S2S基線的指針生成器解碼器的生成器部分的任務上,性能下降了50%以上,直到問題指針再次添加到模型中。我們認為這在多任務設置中尤為重要。原因有二:首先,問題指針除了在一個共同參與的上下文語境環境之外,還有一個共同參與的問題。這種分離允許有關問題的關鍵信息直接流入解碼器,而不是通過共同參與的上下文。其次,通過更直接地訪問這個問題,模型能夠更有效地決定何時生成輸出令牌比直接復制更合適。
使用這種反課程訓練策略,最初只針對問答進行訓練,在decaNLP上的性能也進一步有所提高。
▌零樣本和遷移學習能力
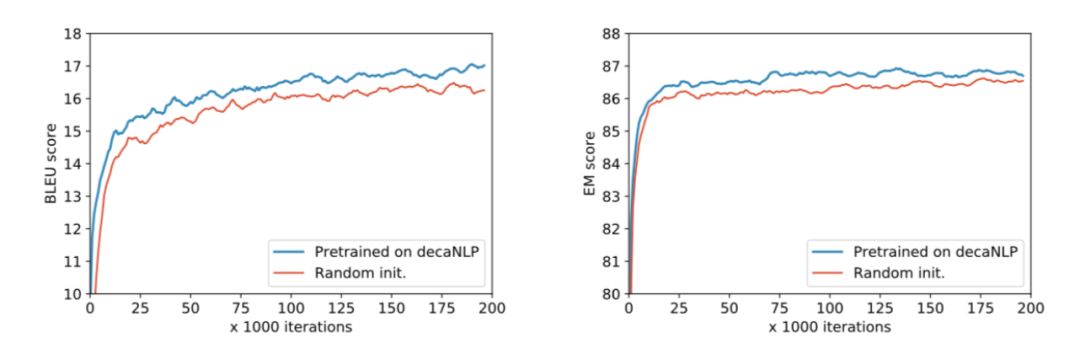
圖5.在適應新域和學習新任務時,MQAN對decaNLP的預訓練優于隨機初始化。左:一個新的語言對的訓練-英文到捷克語,右:訓練一個新的任務-實體識別命名(NER)
考慮到我們的模型是在豐富和多樣的數據上進行訓練的,它構建了強大的中間表示方法,從而實現了遷移學習。相對于一個隨機初始化的模型,我們的模型在decaNLP上進行了預先訓練,使得在幾個新任務上更快的收斂并且也提高了分數。我們在上圖中給出了兩個這樣的任務:命名實體識別和英文到捷克語的翻譯。 我們的模型也具有領域適應的零樣本能力。
我們的模型在decaNLP上接受過訓練,在沒有看過訓練數據的情況下,我們將SNLI數據集調整到62%的精確匹配分數。因為decaNLP包含SST,它也可以在其他二進制情感分析任務中執行得很好。在亞馬遜和Yelp的評論中,MQAN在decaNLP上進行了預先培訓,分別獲得了82.1%和80.8%的精確匹配分數。此外,用高興/憤怒或支持/不支持來替換訓練標簽的符號來重新表示問題,只會導致性能的輕微下降,因為模型主要依賴于SST的問題指針。這表明,這些多任務模型對于問題和任務中的微小變化更加可靠,并且可以推廣到新的和不可見的類。
-
深度學習
+關注
關注
73文章
5422瀏覽量
120583 -
自然語言
+關注
關注
1文章
279瀏覽量
13295 -
nlp
+關注
關注
1文章
481瀏覽量
21932
原文標題:NLP通用模型誕生?一個模型搞定十大自然語言常見任務
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
2023年科技圈熱詞“大語言模型”,與自然語言處理有何關系
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【推薦體驗】騰訊云自然語言處理

自然語言處理怎么最快入門_自然語言處理知識了解
Salesforce發布了一項新的研究成果:decaNLP十項自然語言任務的通用模型

decaNLP——同時處理十項自然語言任務的通用模型

自然語言和ChatGPT的大模型調教攻略
亞馬遜云科技結合大語言模型和自然語言問答,加速的數據決策





 工商網監
工商網監
評論