") 深度學習在自然語言處理方面的研究進展
深度學習在自然語言處理方面的研究進展
要是關注深度學習在自然語言處理方面的研究進展,我相信你一定聽說過Attention Model(后文有時會簡稱AM模型)這個詞。AM模型應該說是過去一年來NLP領域中的重要進展之一,在很多場景被證明有效。聽起來AM很高大上,其實它的基本思想是相當直觀簡潔的。
Encoder-Decoder框架
本文只談談文本處理領域的AM模型,在圖片處理或者(圖片-圖片標題)生成等任務中也有很多場景會應用AM模型,但是我們此處只談文本領域的AM模型,其實圖片領域AM的機制也是相同的。
要提文本處理領域的AM模型,就不得不先談Encoder-Decoder框架,因為目前絕大多數文獻中出現(xiàn)的AM模型是附著在Encoder-Decoder框架下的,當然,其實AM模型可以看作一種通用的思想,本身并不依賴于Encoder-Decoder模型,這點需要注意。
Encoder-Decoder框架可以看作是一種文本處理領域的研究模式,應用場景異常廣泛,本身就值得非常細致地談一下,但是因為本文的注意力焦點在AM模型,所以此處我們就只談一些不得不談的內容,詳細的Encoder-Decoder模型以后考慮專文介紹。
下圖是文本處理領域里常用的Encoder-Decoder框架最抽象的一種表示:
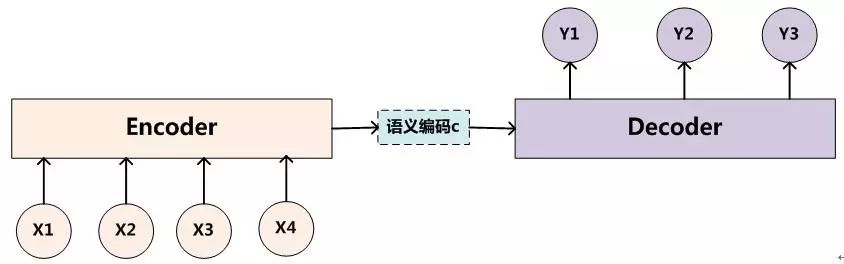
圖1:抽象的Encoder-Decoder框架
Encoder-Decoder框架可以這么直觀地去理解:可以把它看作適合處理由一個句子(或篇章)生成另外一個句子(或篇章)的通用處理模型。對于句子對
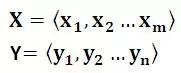
Encoder顧名思義就是對輸入句子X進行編碼,將輸入句子通過非線性變換轉化為中間語義表示C:
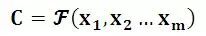
對于解碼器Decoder來說,其任務是根據句子X的中間語義表示C和之前已經生成的歷史信息y1,y2….yi-1來生成i時刻要生成的單詞yi
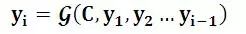
每個yi都依次這么產生,那么看起來就是整個系統(tǒng)根據輸入句子X生成了目標句子Y。
Encoder-Decoder是個非常通用的計算框架,至于Encoder和Decoder具體使用什么模型都是由研究者自己定的,常見的比如CNN/RNN/BiRNN/GRU/LSTM/Deep LSTM等,這里的變化組合非常多,而很可能一種新的組合就能攢篇論文,所以有時候科研里的創(chuàng)新就是這么簡單。比如我用CNN作為Encoder,用RNN作為Decoder,你用BiRNN做為Encoder,用深層LSTM作為Decoder,那么就是一個創(chuàng)新。所以正準備跳樓的憋著勁想攢論文畢業(yè)的同學可以從天臺下來了,當然是走下來,不是讓你跳下來,你可以好好琢磨一下這個模型,把各種排列組合都試試,只要你能提出一種新的組合并被證明有效,那恭喜你:施主,你可以畢業(yè)了。
扯遠了,再拉回來。
Encoder-Decoder是個創(chuàng)新游戲大殺器,一方面如上所述,可以搞各種不同的模型組合,另外一方面它的應用場景多得不得了,比如對于機器翻譯來說,
Attention Model
圖1中展示的Encoder-Decoder模型是沒有體現(xiàn)出“注意力模型”的,所以可以把它看作是注意力不集中的分心模型。為什么說它注意力不集中呢?請觀察下目標句子Y中每個單詞的生成過程如下:
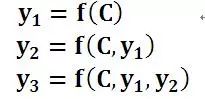
其中f是decoder的非線性變換函數。從這里可以看出,在生成目標句子的單詞時,不論生成哪個單詞,是y1,y2也好,還是y3也好,他們使用的句子X的語義編碼C都是一樣的,沒有任何區(qū)別。而語義編碼C是由句子X的每個單詞經過Encoder 編碼產生的,這意味著不論是生成哪個單詞,y1,y2還是y3,其實句子X中任意單詞對生成某個目標單詞yi來說影響力都是相同的,沒有任何區(qū)別(其實如果Encoder是RNN的話,理論上越是后輸入的單詞影響越大,并非等權的,估計這也是為何Google提出Sequence to Sequence模型時發(fā)現(xiàn)把輸入句子逆序輸入做翻譯效果會更好的小Trick的原因)。這就是為何說這個模型沒有體現(xiàn)出注意力的緣由。這類似于你看到眼前的畫面,但是沒有注意焦點一樣。如果拿機器翻譯來解釋這個分心模型的Encoder-Decoder框架更好理解,比如輸入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文單詞:“湯姆”,“追逐”,“杰瑞”。在翻譯“杰瑞”這個中文單詞的時候,分心模型里面的每個英文單詞對于翻譯目標單詞“杰瑞”貢獻是相同的,很明顯這里不太合理,顯然“Jerry”對于翻譯成“杰瑞”更重要,但是分心模型是無法體現(xiàn)這一點的,這就是為何說它沒有引入注意力的原因。沒有引入注意力的模型在輸入句子比較短的時候估計問題不大,但是如果輸入句子比較長,此時所有語義完全通過一個中間語義向量來表示,單詞自身的信息已經消失,可想而知會丟失很多細節(jié)信息,這也是為何要引入注意力模型的重要原因。
上面的例子中,如果引入AM模型的話,應該在翻譯“杰瑞”的時候,體現(xiàn)出英文單詞對于翻譯當前中文單詞不同的影響程度,比如給出類似下面一個概率分布值:
(Tom,0.3)(Chase,0.2)(Jerry,0.5)
每個英文單詞的概率代表了翻譯當前單詞“杰瑞”時,注意力分配模型分配給不同英文單詞的注意力大小。這對于正確翻譯目標語單詞肯定是有幫助的,因為引入了新的信息。同理,目標句子中的每個單詞都應該學會其對應的源語句子中單詞的注意力分配概率信息。這意味著在生成每個單詞Yi的時候,原先都是相同的中間語義表示C會替換成根據當前生成單詞而不斷變化的Ci。理解AM模型的關鍵就是這里,即由固定的中間語義表示C換成了根據當前輸出單詞來調整成加入注意力模型的變化的Ci。增加了AM模型的Encoder-Decoder框架理解起來如圖2所示。
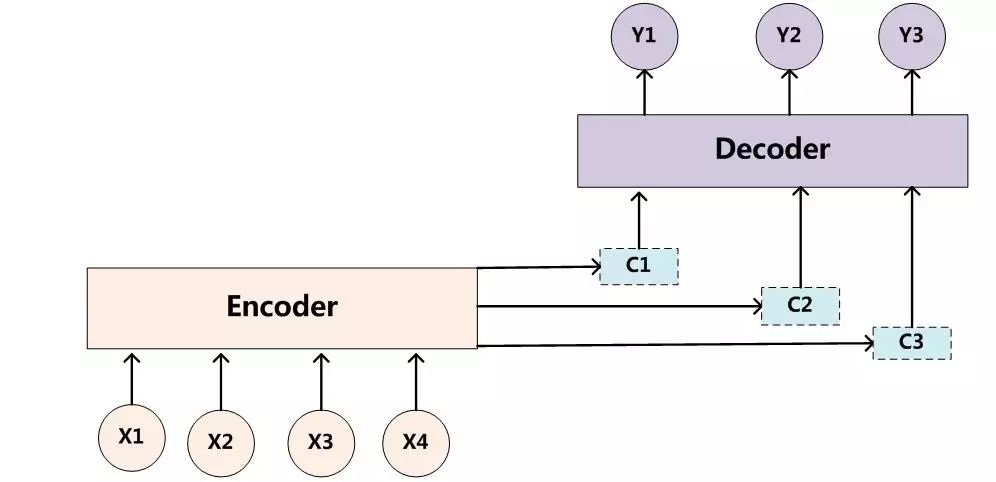
圖2:引入AM模型的Encoder-Decoder框架
即生成目標句子單詞的過程成了下面的形式:
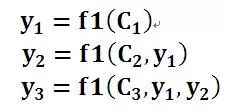
而每個Ci可能對應著不同的源語句子單詞的注意力分配概率分布,比如對于上面的英漢翻譯來說,其對應的信息可能如下:

其中,f2函數代表Encoder對輸入英文單詞的某種變換函數,比如如果Encoder是用的RNN模型的話,這個f2函數的結果往往是某個時刻輸入xi后隱層節(jié)點的狀態(tài)值;g代表Encoder根據單詞的中間表示合成整個句子中間語義表示的變換函數,一般的做法中,g函數就是對構成元素加權求和,也就是常常在論文里看到的下列公式:
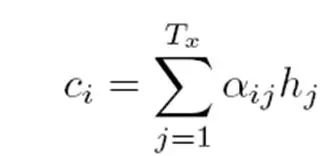
假設Ci中那個i就是上面的“湯姆”,那么Tx就是3,代表輸入句子的長度,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”),對應的注意力模型權值分別是0.6,0.2,0.2,所以g函數就是個加權求和函數。如果形象表示的話,翻譯中文單詞“湯姆”的時候,數學公式對應的中間語義表示Ci的形成過程類似下圖:
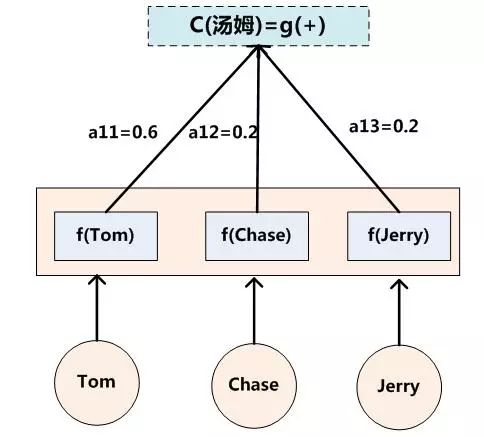
圖3:Ci的形成過程
這里還有一個問題:生成目標句子某個單詞,比如“湯姆”的時候,你怎么知道AM模型所需要的輸入句子單詞注意力分配概率分布值呢?就是說“湯姆”對應的概率分布:
(Tom,0.6)(Chase,0.2)(Jerry,0.2)
是如何得到的呢?
為了便于說明,我們假設對圖1的非AM模型的Encoder-Decoder框架進行細化,Encoder采用RNN模型,Decoder也采用RNN模型,這是比較常見的一種模型配置,則圖1的圖轉換為下圖:
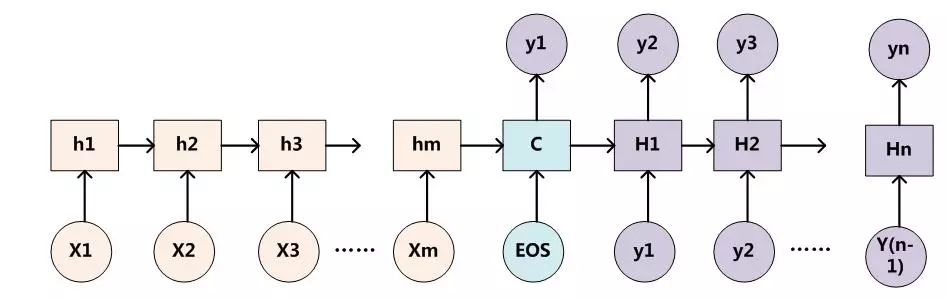
圖4:RNN作為具體模型的Encoder-Decoder框架
那么用下圖可以較為便捷地說明注意力分配概率分布值的通用計算過程:
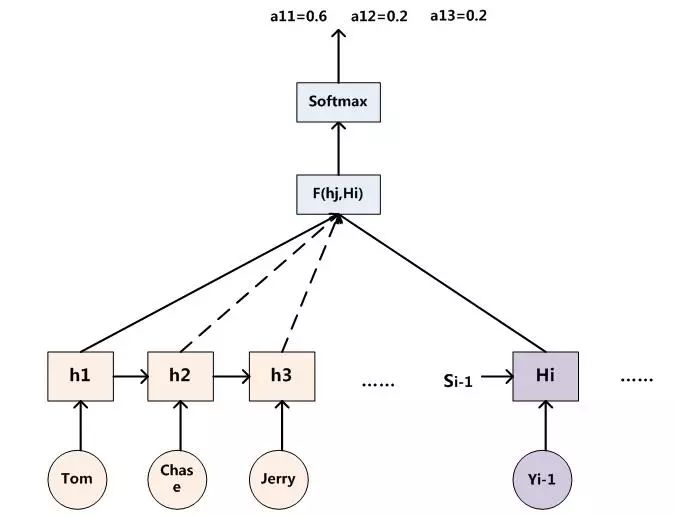
圖5:AM注意力分配概率計算
對于采用RNN的Decoder來說,如果要生成yi單詞,在時刻i,我們是可以知道在生成Yi之前的隱層節(jié)點i時刻的輸出值Hi的,而我們的目的是要計算生成Yi時的輸入句子單詞“Tom”、“Chase”、“Jerry”對Yi來說的注意力分配概率分布,那么可以用i時刻的隱層節(jié)點狀態(tài)Hi去一一和輸入句子中每個單詞對應的RNN隱層節(jié)點狀態(tài)hj進行對比,即通過函數F(hj,Hi)來獲得目標單詞Yi和每個輸入單詞對應的對齊可能性,這個F函數在不同論文里可能會采取不同的方法,然后函數F的輸出經過Softmax進行歸一化就得到了符合概率分布取值區(qū)間的注意力分配概率分布數值。圖5顯示的是當輸出單詞為“湯姆”時刻對應的輸入句子單詞的對齊概率。絕大多數AM模型都是采取上述的計算框架來計算注意力分配概率分布信息,區(qū)別只是在F的定義上可能有所不同。
上述內容就是論文里面常常提到的Soft Attention Model的基本思想,你能在文獻里面看到的大多數AM模型基本就是這個模型,區(qū)別很可能只是把這個模型用來解決不同的應用問題。那么怎么理解AM模型的物理含義呢?一般文獻里會把AM模型看作是單詞對齊模型,這是非常有道理的。目標句子生成的每個單詞對應輸入句子單詞的概率分布可以理解為輸入句子單詞和這個目標生成單詞的對齊概率,這在機器翻譯語境下是非常直觀的:傳統(tǒng)的統(tǒng)計機器翻譯一般在做的過程中會專門有一個短語對齊的步驟,而注意力模型其實起的是相同的作用。在其他應用里面把AM模型理解成輸入句子和目標句子單詞之間的對齊概率也是很順暢的想法。
當然,我覺得從概念上理解的話,把AM模型理解成影響力模型也是合理的,就是說生成目標單詞的時候,輸入句子每個單詞對于生成這個單詞有多大的影響程度。這種想法也是比較好理解AM模型物理意義的一種思維方式。
圖6是論文“A Neural Attention Model for Sentence Summarization”中,Rush用AM模型來做生成式摘要給出的一個AM的一個非常直觀的例子。
圖6:句子生成式摘要例子
這個例子中,Encoder-Decoder框架的輸入句子是:“russian defense minister ivanov called sunday for the creation of a joint front for combating global terrorism”。對應圖中縱坐標的句子。系統(tǒng)生成的摘要句子是:“russia calls for joint front against terrorism”,對應圖中橫坐標的句子。可以看出模型已經把句子主體部分正確地抽出來了。矩陣中每一列代表生成的目標單詞對應輸入句子每個單詞的AM分配概率,顏色越深代表分配到的概率越大。這個例子對于直觀理解AM是很有幫助作用的。
-
gpu
+關注
關注
27文章
4586瀏覽量
128126 -
人工智能
+關注
關注
1787文章
46032瀏覽量
234866 -
深度學習
+關注
關注
73文章
5422瀏覽量
120583
原文標題:自然語言處理中的Attention Model:是什么及為什么
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦





 工商網監(jiān)
工商網監(jiān)
評論