 用兩個日常的例子為我們講解了決策樹的原理
用兩個日常的例子為我們講解了決策樹的原理
編者按:作為機器學習兩大重要算法——隨機森林和梯度樹提升的基礎,決策樹是每位機器學習從業者都應該理解的概念。本文作者Brandon Rohrer用兩個日常的例子為我們講解了決策樹的原理,過程清晰易讀,適合入門學習。文末附有原文鏈接,感興趣的讀者可移步原文觀看視頻版本。以下是論智的編譯。
決策樹是我最喜歡的模型之一,它們非常簡單但是很強大。事實上,Kaggle中大多數表現優秀的項目都是XGBoost和一些非常絕妙的特征工程的結合,XGBoost是決策樹的一種變體。決策樹背后的概念非常簡潔明了,下面就用具體案例解釋一下。
早上幾點出門才能不遲到?
假設我們現在要創建一個數據集,記錄每天上班離開家的時間以及能否準時到達公司。下圖就記錄了一些情況,可以看到大多數情況下,只要在8:15之前出門就能準時上班,在這之后就會經常遲到。
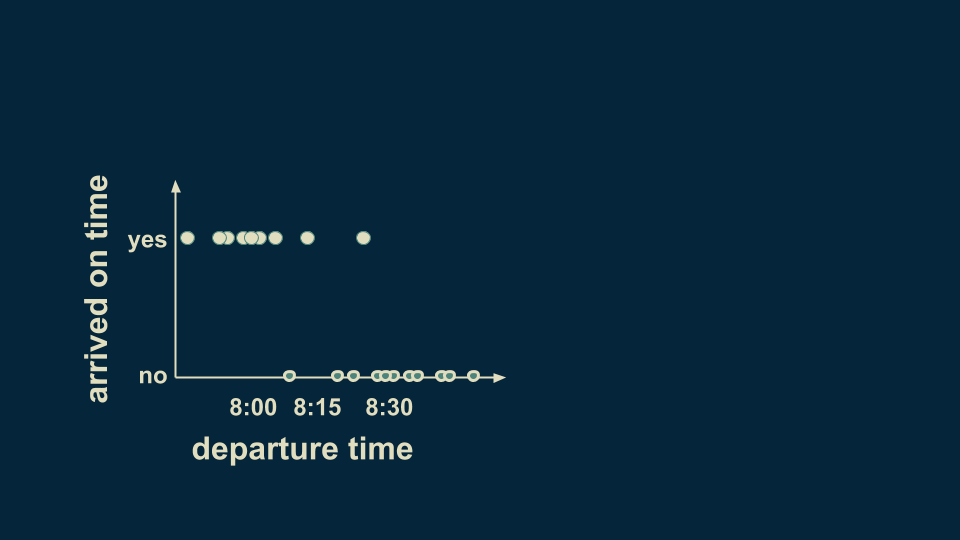
你可以在決策樹中總結出這一情況。首先第一個分叉點可以問:“是否在8:15之前離開?”這里有兩種回答:“是”或“否”。根據習慣我們將“是”放在左邊,然后將數據分為兩組,雖然有一些例外情況,但總體看來8:15是一個分水嶺。如果在這之前出門,大概率不會遲到,反之亦然。
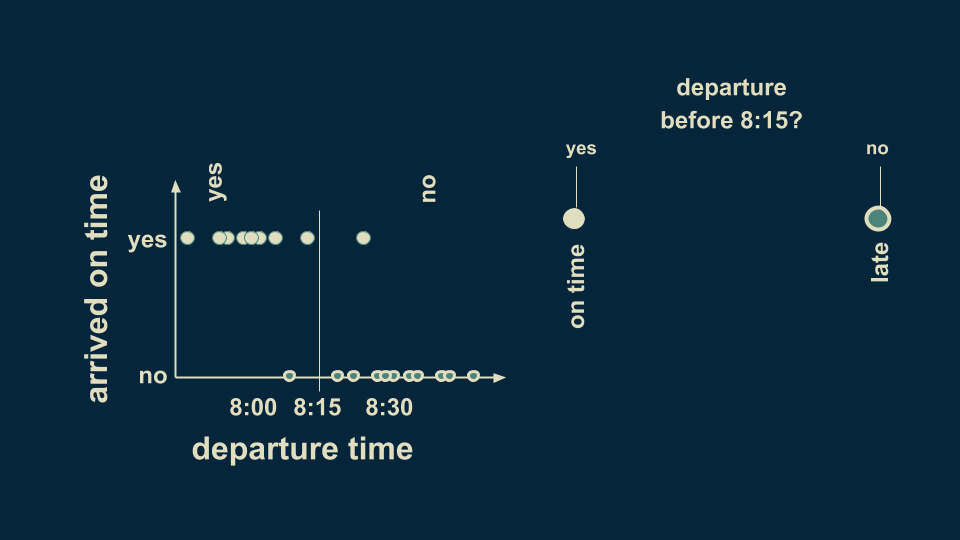
這就是最簡單的決策樹模型,只有一對選擇分支。
接下來我們可以對這個模型進行微調,在兩個分支上分別再進行分類,即加入8:00和8:30兩個時間點,這樣可以更全面地分析到達時間。下表顯示,8:00之前出門絕對能準時到達,而8:00到8:15之間出門可能會準時到。而在8:15之后8:30之前幾乎每次都會遲到,但也有可能不遲到。而8:30之后一定會遲到。
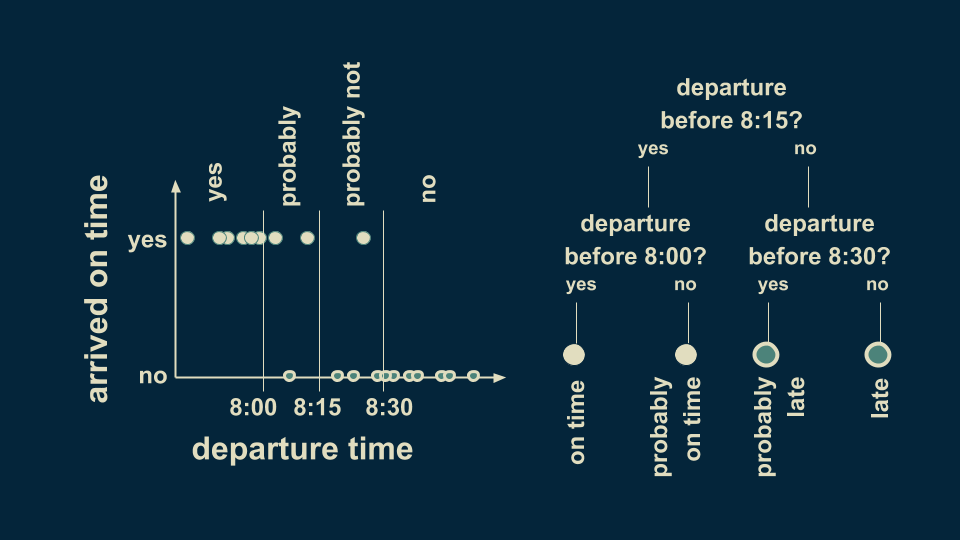
這樣一來,決策樹就變成了兩層,你還可以根據自己的需要繼續分層下去。大多數情況下,每個決策點只有兩個分支。
上面的案例只有一個預測變量,以及一個類別目標變量。預測變量是“我們出門的時間”,目標變量是“是否準時上班”。由于只有兩種明確的可能(是或不是),所以是分類的。有分類目標的決策樹也被稱為分類樹。
我們可以將這一例子繼續擴展,把它變成兩個決策變量。將出門時間和工作日加入進去,將周一定為1,以此類推,周六為6,周日為7。數據顯示,在周六和周日,綠色的點要更靠近左邊一些。這說明在工作日,8:10出門也許足夠了,但是周末可能會遲到。

為了在決策樹中表示這一點,我們可以像之前一樣,再在8:15時加上分界線,在這之后出發可能會遲到,但是在這之前卻不好說,此前我們判斷的是不會遲到,但現在看來這個推斷不完全準確。

為了讓我們更好地估計周末情況,我們可以進一步將8:15之前分為工作日和周末兩種情況。工作日如果在8:15之前出發,那么一定不會遲到。但是周末如果在8:15之前出發,大多數情況會準時到達,但是也有例外。于是決策樹可以如下圖表示:

繼續分類,將周末的8:15分繼續分為8:00前和8:00后。如果8:00前出發,幾乎每次都能準點到達,8:00至8:15之間出發,大部分都會遲到。現在我們有了一個二維決策樹,將數據分成了四個不同區域。其中兩個表示準點到達,另外兩個表示遲到。

這是一個三層決策樹,注意,并不是每個分支都需要繼續細分下去(例如最右邊的一支)。
現在我們可以分析一個具有連續目標變量的案例了。當模型對連續變量做出預測時,這也被稱為回歸樹。我們已經解釋了一維或二維的分類樹了,接下來我們分析回歸樹。
你幾點起床?
現在我們要加入某人的年齡以及他起床的時間。我們回歸樹模型的根節點就是對整個數據集的估計。在這種情況下,如果你不知道某人的年齡但還要估計他的起床時間,那么可能的時間是6:25,我們假設這是決策樹的根節點。
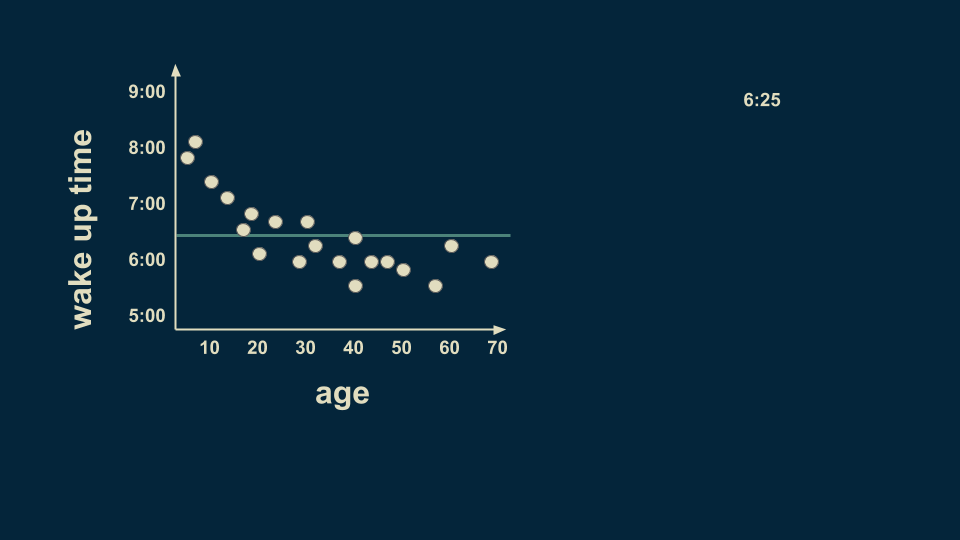
另一個關于年齡的分支我們定在25歲,經過數據收集,平均來說,25歲以下的人會在7:05起床,25歲以上的人會在6點鐘起床。
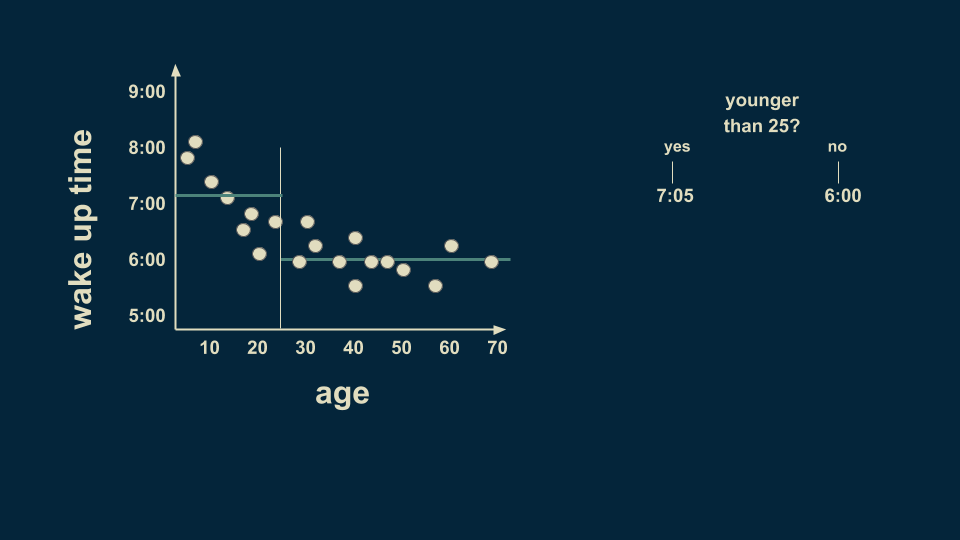
但是年輕人群體中也有變數,所以我們可以在進行分類。我們預計,12歲以下的人會在7:45起床,而12至25歲的人會在6:40起床。
25歲以上的人也可以進行細分。例如25至40歲的人平均在6:10起床,而40至70歲的人平均5:50起床。
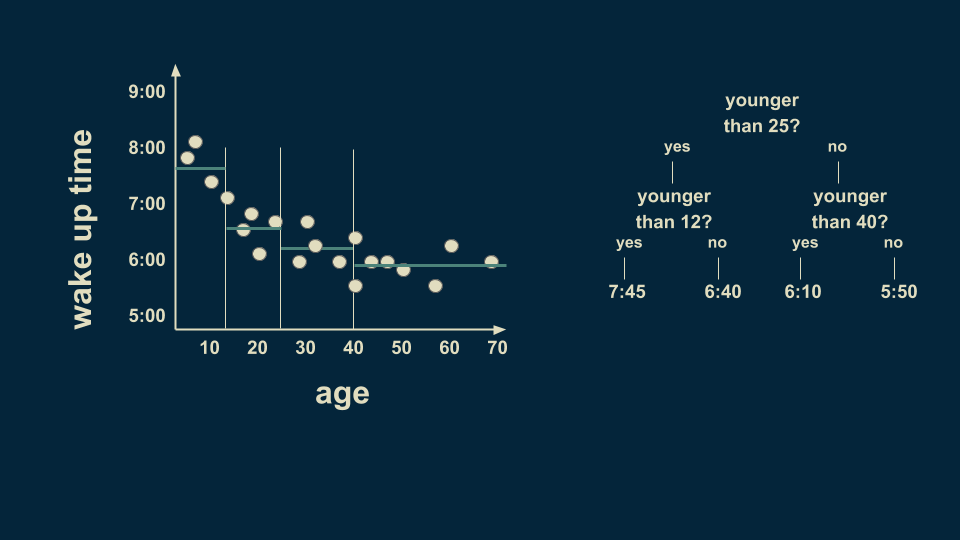
但是,年輕人群體中仍然有很多種情況,繼續細分,以8歲為分界點,可以讓預測的值更準確。我們也可以在40歲至70歲之間以58歲為分界點。注意,我們現在的某些“樹葉”上只有一或兩個數據點,這種情況很可能導致過度擬合,稍后我們會對其進行處理。
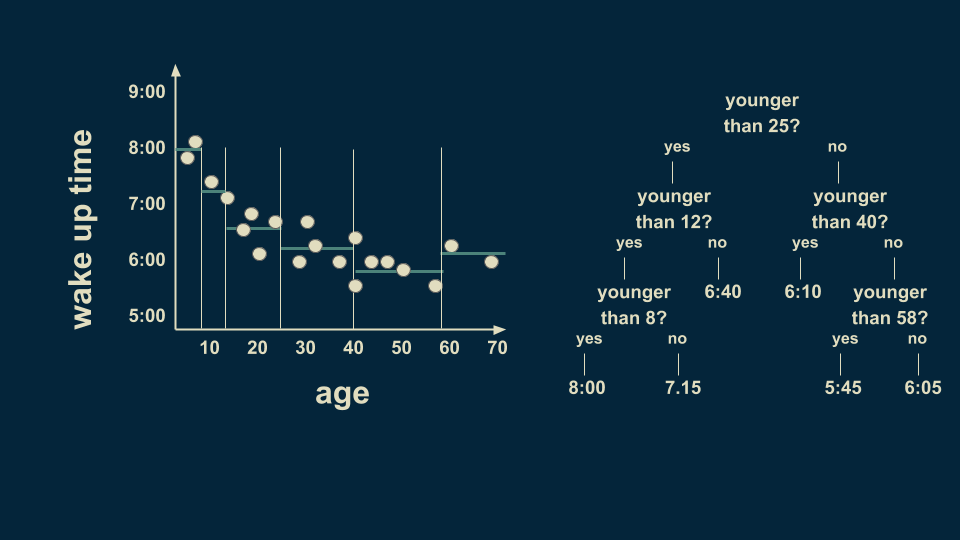
根據年齡,決策樹能讓我們做出多種判斷。如果我要判斷一名36歲的實驗對象的起床時間,那么我可以從樹的頂端開始。
他是否小于25歲?否,向右。低于40歲?是的,向左。最終估計的起床時間為6:10。
決策樹的結構能讓你將任何年齡的人分到各自的類別中,并且預測出他們的起床時間。
我們還可以將回歸樹模型擴展到有兩個預測變量的形式。如果我們不僅考慮某人的年齡,還要考慮月份,那么我們會找到更加豐富的模式。目前北半球是夏季,晝長夜短,太陽日出時間較冬季更早。假設學生們沒有課業壓力(當然只是假設),他們的起床時間受太陽升起的影響,另一方面,成年人的起床時間就更加規律,只會隨著季節變化進行輕微波動。另外,老年人在這個情況下會起的稍早。
我們創建的這個決策樹和上一個很像。從根節點6:30開始(這里是用matplotlib進行的可視化)
之后我們尋找一個適合加入邊界的地方,以35歲為分界線,35歲以下的人在7:06起床,35歲以下的人在6:12起床。
重復之前的過程,在年輕群體中細分時間,判斷是否是9月中旬、是否是3月中旬。若在9月中旬之后,那么就判定為冬季,35歲以下的人起床時間估計為7:30,而夏季預計為6:56。
接著,我們可以在大于35歲的群體中繼續以48歲為界線進行精確的分析。
我們同樣還可以回過頭,在35歲以下群體中分析18歲人群冬季的起床時間,如下圖。18歲以下的人冬季在7:54起床,而18歲以上的人在6:48起床。
從這里,我們看到隨著分支的增加,決策樹模型的形狀越來越接近原始數據的形狀。同樣,我們也會注意到決策樹所區分的各個區域,顏色也越來越相近。
這一過程如果繼續下去,模型就會不斷接近數據原始形狀,每個決策區域會變得越來越小,對數據的估計也會越來越準確。
如何處理過擬合
然而,決策樹需要注意的一個重點是過度擬合。回到我們只有單一變量的回歸樹案例,即年齡對起床時間的影響中,假設我們繼續細分年齡,直到每個類別中只有一兩個數據。
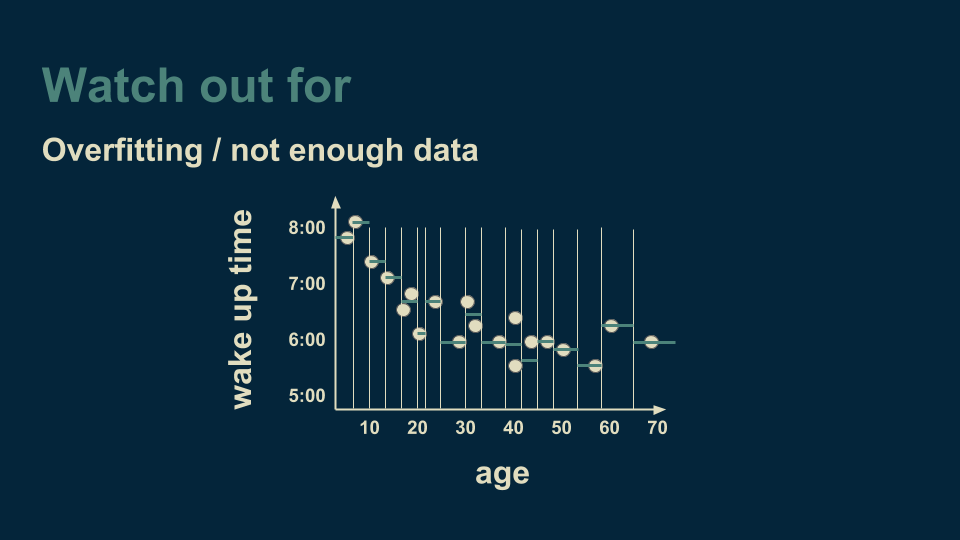
到了這時,決策樹能非常好地解釋并擬合數據,它不僅能掌握基本趨勢,還能捕捉噪聲。如果用該模型對新數據進行預測,那么訓練數據中的噪聲會讓預測精確度降低。理想情況下,我們想讓決策樹捕捉趨勢但不要夾雜噪聲。要達到這一效果,比較有保障的方法就是在每片“樹葉”上有多個數據,這樣一來,噪聲就會被平均掉。
另一種需要警惕的現象是變量過多的情況。我們一開始的回歸樹是一維的,后來加上了“月份”數據,成為了二維回歸樹。但是決策樹不在乎有多少個維度,我們甚至可以加上地區緯度、某人鍛煉量、身體的大數據或任何可能想到的變量。
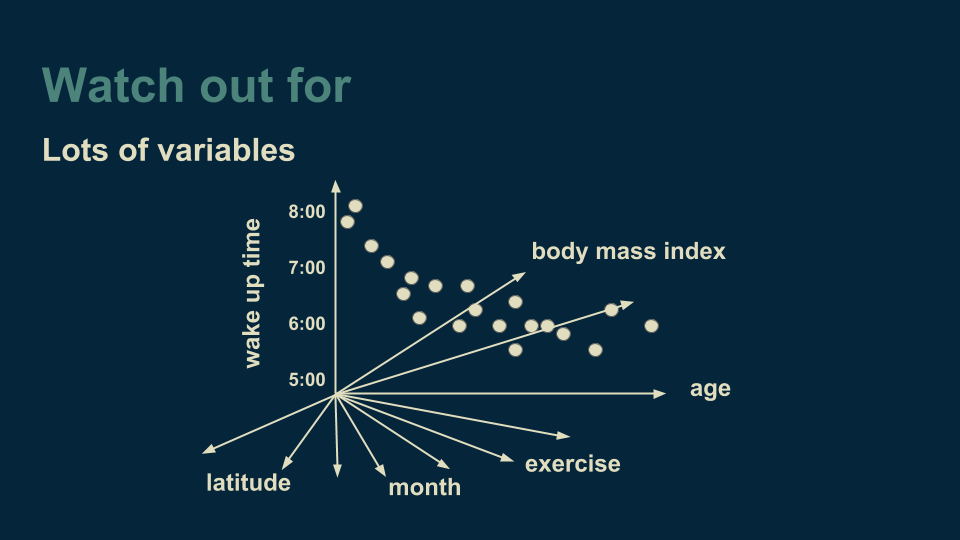
變量一多,接下來就要考慮細分哪些變量了。如果變量很多,就需要大量計算。同時我們加入的變量越多,所需要的數據就越多,所以處理起來要耗費大量精力。
當你相對數據進行必要解讀時,決策樹真的非常有用,它們很普遍,可以處理預測變量和目標變量之間非線性的關系。二次方程、指數關系、周期循環等等關系都能在決策樹中表示,只要你有足夠的數據支持。決策樹同樣可以發現不平滑的趨勢,例如突然下降或上升,或者其他人工神經網絡等模型的隱藏趨勢。作為數據分析的工具,決策樹的優勢還是很明顯的。
-
機器學習
+關注
關注
66文章
8381瀏覽量
132429 -
決策樹
+關注
關注
2文章
96瀏覽量
13539
原文標題:在茫茫決策樹入門帖里,我強推這篇(附可視化圖)
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于決策樹,這些知識點不可錯過
介紹支持向量機與決策樹集成等模型的應用
決策樹的生成資料
一個基于粗集的決策樹規則提取算法
決策樹的原理和決策樹構建的準備工作,機器學習決策樹的原理
決策樹和隨機森林模型
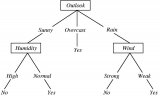
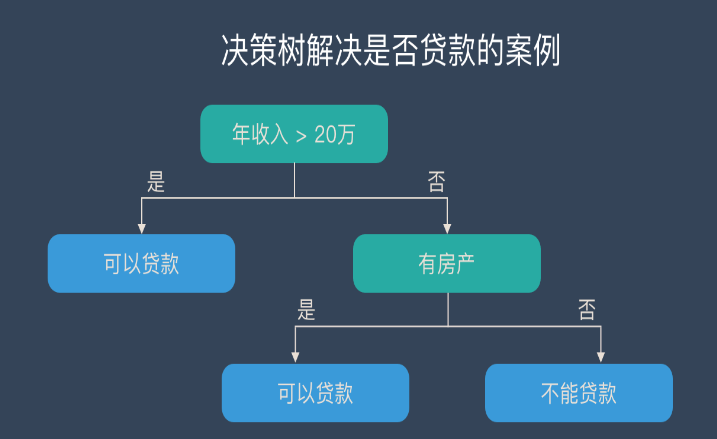
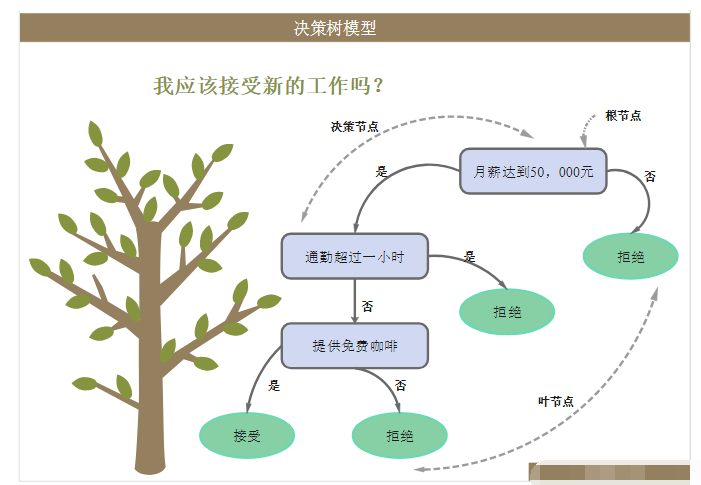
什么是決策樹模型,決策樹模型的繪制方法





 工商網監
工商網監
評論