 中國團隊Getmax為何能在高手如云的KDD Cup中脫穎而出?
中國團隊Getmax為何能在高手如云的KDD Cup中脫穎而出?
近日,有數據挖掘領域“奧運會”之稱的KDD Cup 2018比賽結果出爐。今年的主題為空氣質量預測,中國團隊Getmax包攬三項大獎,獲得兩項第一,一項第二的好成績。本文帶來該團隊親述算法思路與技術細節。
KDD Cup是由 ACM 的數據挖掘及知識發現專委會(SIGKDD)主辦的數據挖掘研究領域的國際頂級賽事,從1997年至今已有 21 年的歷史。作為目前數據挖掘領域最有影響力、最高水平的國際頂級賽事,KDD Cup 每年都會吸引來自世界各地數據挖掘領域的頂尖專家、學者和工程師參賽,因此也有“大數據奧運會”之名。
與往年只有最終成績獎項不同,KDD Cup 2018計算了比賽過程中的成績并設立了三項大獎——“The General Track”、“最后10天專項獎”、“最佳長期預測獎”,從三個維度來獎勵比賽中表現突出的隊伍。而“Getmax”也因全面而突出的表現,從4000多個參賽隊伍中脫穎而出,成為唯一包攬三項大獎的隊伍,分別取得一項亞軍、兩項冠軍的成績。
如何在KDD Cup這樣高手如云的國際賽事中脫穎而出?Getmax團隊向新智元詳細介紹了他們今年的參賽解決方案,包括如何理解空氣質量問題,分析數據,特征工程,以及如何針對應用特點進行深度學習建模與優化。
背景介紹:KDD CUP 2018預測空氣質量
KDD Cup 2018關注空氣質量問題。在過去幾年中,空氣質量問題已經影響了很多發展中國家的大城市。2011年,康奈爾大學空氣質量專家Dane Westerdahl在接受《洛杉磯時報》的采訪時表示,有些時候,發展中國家城市的空氣質量和“森林大火下風口的空氣質量”相當。
在眾多空氣污染物中,懸浮顆粒(particulate matters,簡稱PM)是最致命的一種之一。直徑小于或等于2.5 μm的懸浮顆粒可以進入肺部深處,進入血管,導致 DNA 突變和癌癥,中樞神經系統損傷和過早死亡。
主辦方在比賽中提供中國北京和英國倫敦的數據。比賽選手需要預測未來48小時內 PM2.5, PM10和O3的濃度(倫敦只需要預測PM2.5和PM10)。
Getmanx團隊介紹:
羅志鵬微軟Bing搜索廣告算法工程師,北京大學軟件工程專業碩士,專注于深度學習技術在NLP, 廣告相關性匹配,CTR預估等方面的研究及應用。
胡可阿里媽媽搜索直通車團隊算法專家,碩士畢業于香港中文大學機器學習方向。工作技術方向為深度學習與廣告算法。
黃堅強北京大學軟件工程專業碩士在讀,擅長特征工程、自然語言處理、深度學習。
評測指標
每天,提交的結果將會和真實空氣質量數據(也就是空氣監測站測量的污染物濃度)比較,并根據Symmetric mean absolute percentage error評分:

At是真實值,Ft是預測值。
題目特點以及常用方法
空氣質量相關預測問題相對比較新,涉及的領域包括環境科學、統計學、計算機科學,近年也有機器學習方面的研究工作。國內外多個網站,APP都有對空氣質量預測的應用。現有的方法主要集中于統計學以及線性回歸等機器學習模型,近年也有RNN相關的研究[1],現有的模型主要預測時間段在8~24小時以內。
空氣質量預測具有規律性弱,不穩定,易突變的特點。因為比賽要預測48小時時間序列以及北京/倫敦城市內幾十個預測地點,建模更長的時間序列以及地理拓撲關系給機器學習模型帶來挑戰。
現有的方法針對的預測的時間段較短,沒有基于位置拓撲以及利用天氣預報進行建模,在機器學習尤其深度學習模型的運用也處于探索階段。并且,由于比賽賽制每天需提交未來結果,相對于很多基于固定測試集的方案或比賽更接近真實工業界,對模型的穩定性以及迭代開銷也有很多挑戰。
比賽數據與數據分析
本題提供主要三方面數據:
空氣質量數據, 主要包括以下幾種重要的空氣污染物:PM2.5, PM10, O3
天氣氣象數據:地理網格數據點的天氣,溫度,氣壓,濕度,風速,風向
未來48小時天氣預報:與天氣氣象數據相同網格點的天氣,溫度,氣壓,濕度,風速,風向預報值
其中過去一年的數據有空氣質量數據與天氣數據,過去一個月的數據有天氣預報數據。
首先,我們觀察了北京站點2018年2月到5月之間的空氣污染物(PM2.5)濃度變化情況,以北京奧體中心站點PM2.5為例,下圖顯示了PM2.5隨時間的變化,從圖中可以看出,北京的PM2.5濃度變化不定,最低能達到10以內,最高能達到350左右。并且在數小時就可以產生劇烈的變換,為預測增加了很大的難度。

特征工程
我們首先提取了每個站點過去72小時的空氣質量,以及每個站點最近網格過去72小時的氣象數據來作為站點的氣象特征,使用這些特征構建了第一個模型。
我們發現,基于歷史統計量的模型對于長期預測尤其是突變效果并不理想。以 5 月 7 號對于未來兩天預測為例,下圖可以看出,在 5 月 8 日到 5 月 9 日模型一的 PM2.5 濃度從 40 上升到 80 又下降到 40,而我們基于歷史統計量特征的模型始終保持在 50 左右,經過數據分析我們發現,這段時間的天氣發生了一定的變化,我們分析未來天氣預報是問題的關鍵并構建相關特征。

北京奧體中心站點5月8號-5月9號的PM2.5預測值及真實值
而天氣預報數據只有 2018 年 4 月 10 號后約一個月的數據,在此前一年的訓練數據缺失天氣預報,沒法做有效的訓練。所以我們使用 2018 年 4 月 10 號以前的真實氣象數據代替此時段天氣預報數據。
然而,由于真實天氣數據與預測天氣數據分布并不一致,我們采取對訓練數據中的真實數據引入高斯噪聲,并且考慮到短期預報與長期預報估計誤差的不同,針對于不同的預測小時段進行了不同的參數估計,緩解了訓練集與預測集合不一致所造成的過擬合問題。
針對于某些特殊時段天氣預報預測偏差過大造成的不穩定問題,我們進一步使用分箱平滑。參照真實天氣預報一個月數據的樹模型訓練集上的特征重要性與測試集效果進行了超參數確定。并且我們也嘗試transfer learning等方法優化分布不一致問題,但由于最后一個月數據太少效果不穩定,并且迭代開銷大沒有采用。
在基于單點構建天氣預報特征后,我們發現很多周圍方位的天氣預報信息對于當前點也有很大影響。我們由利用幾百個網格數據點進行拓撲信息特征構建。首先我們針對每個城市的每個站點的 8 個臨近方位角去提取 8 個網格數據點的天氣預報特征。考慮到其他位置的天氣如風速等會影響到當前方位的污染狀況,我們也針對北京 12 個經緯度跨度較大的網格數據點作為全局預報特征,取得了較大的提升。Model1 是基于歷史統計量以及初步天氣預報特征模型,Model2 是細化天氣預報特征與地理位置特征的模型。

北京奧體中心站點5月8號到5月9號的PM2.5預測值及真實值
我們也在其他預測日驗證了模型效果。下圖為兩個模型在 5 月 28 號和 29 號的效果圖(29 日后面有數據缺失),我們的細粒度天氣預報特征也可以更好的預測趨勢。圖中空氣質量有較大的突變,而我們的模型也捕捉到了突變趨勢。突變是對于實際應用有重要應用價值的場景,在這次突變天氣提交我們成績為0.48,同當日第二名成績 0.54 相比有明顯優勢。
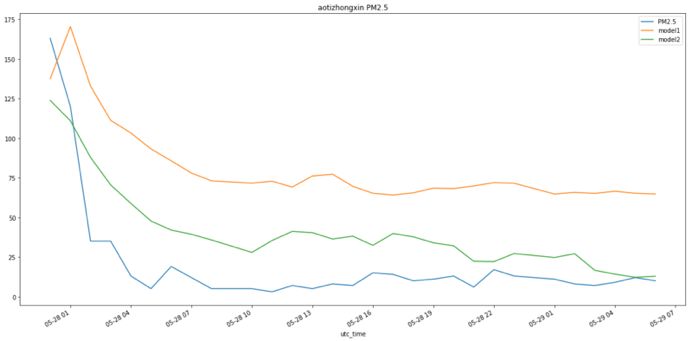
北京奧體中心站點5月28號到5月29號的PM2.5預測值及真實值
最終,特征主要分為六類:
基本特征:需預測的第幾個小時,樣本是在當天的第幾小時,所在的經緯度等
空氣質量特征:過去1,3,5……72小時的污染物濃度/過去1,3,5, 7天同小時時間污染物濃度均值,中位數,最大值,最小值等統計值,不同小時之間rate/diff等趨勢特征等
天氣特征:過去1,3,5……48小時平均風速,風向分箱聚合等
天氣預報特征:預測時間所在小時風速風向,預測時間之前1,3,6,12小時風速平滑統計量累計值、極值等,按照風向分箱聚合等統計量等
拓撲位置相關特征:全局統計量,離當前位置最近的 8 個方位統計量,該城市 12 個方位統計量等
歷史突變相關特征:歷史最大/最小統計量距離當前隔多久,相隔的時間內平均統計量,極值的差,以及歷史的極值之間的時間差等
我們從 2027 個特征中采用較為重要的 885 個特征,訓練數據共 75 萬條。
實驗模型:GBDT、DNN、RNN
我們主要用采用3種模型,GBDT, DNN與RNN(Seq2Seq-GRU) 模型。由于數據分布差異很大,我們對于不同城市以及不同污染物分別建模。針對時間序列問題我們一共有 2 種建模方式,序列模型 (RNN) 是每條樣本未來 48 小時的空氣質量為 48 個label,而常規回歸模型(GBDT/DNN)是將一條序列樣本根據預測未來的 48 小時序列數展開為48條樣本,每條樣本預測一個狀態,48 條樣本間歷史統計特征相同,存在二個區別:1)用hour flag標識是第幾個樣本;2)天氣預報特征。
GBDT模型用 LightGBM 兩種模型,主要用于特征迭代。針對問題特點對 DNN 模型和RNNSeq2Seq-GRU 模型進行了優化。
DNN模型相對于 GBDT 模型有更強的特征交叉關系學習能力,并且可以學習到一些在訓練集中沒有出現的交叉關系,下圖為 DNN 模型的結構圖。

基于DNN模型,我們有如下調整與優化:
對特征進行標準化處理,計算均值和方差的時候對缺失值暫不做處理
標準化后進行特征值clip,減少離群特征值對模型的影響
對缺失值填充 0,并添加缺失標志位
使用b-swish激活函數[2],其公式為 b-swish(x) = x*sigmoid(b*x),b為可訓練參數;b-swish 擁有不飽和、光滑、非單調性的特征
參考 product neural network[3]概念以及 LSTM 中的 Gate 設計,對時間與位置信息 embedding 進行了 product 以及后面 sigmoid 激活,再與模型本身的統計特征進行組合
傳統的回歸損失函數MSE與比賽的評分函數SMAPE有較大的差異,直接優化MSE會導致與評測目標不一致。而SMAPE在0點不可導且有臨近點不穩定問題,我們為了直接優化SMAPE參照kaggle web traffic prediction比賽分享進行了損失函數逼近[4],使得模型優化與評測更一致:
epsilon = 0.1
summ = tf.maximum(tf.abs(true) + tf.abs(predicted) + epsilon, 0.5 + epsilon)
smape = tf.abs(predicted - true) / summ * 2.0
由于空氣質量預測特征的噪音較大,神經網絡相對于樹模型對于異常值更敏感,我們做了更多的數據處理(a/b/c)。并且由于傳統回歸模型由于基于歷史統計量相同,會有序列間預測值接近問題,以及不能很好的利用其他拓撲方位的統計信息。我們針對時間與空間概念,參考了LSTM中的 Gate,通過點乘與后續連接,增強時間/空間特征在模型中的區分度,并且相對于普通全連接網絡更好建模了時間/空間信息與統計特征的組合能力。最終結果序列間預測值方差顯著增加,提升了模型精度與相對于樹模型的模型差異性。
同時,在基于時間/空間的點乘優化時間序列取得增益后,我們為了進一步建模時間序列,進行了 RNN 模型的嘗試。使用 RNN 模型的主要好處是,能夠根據上一步的模型預測信息結合當前步的輸入特征進行預測當前步,并且可以對不同狀態學習不同的權重。這樣可以進一步使得序列間結果的方差,與常規回歸建模方式形成很好的融合差異性。
下圖為RNN (Seq2Seq-GRU)模型結構:

在RNN每一步從上一步獲得預測結果,并加入到當前時間步的輸入特征中(以天氣預報特征為主)。考慮到了模型精度以及訓練速度,模型在 Encoder 和 Decoder 中均使用 GRU。
除采用在 DNN 模型中的 a/b/c/d/g 優化方法,RNN 模型有如下優化:
在 Seq2Seq 網絡中加入狀態間隱藏層正則項[5],解決模型不穩定的問題。
傳統的 Seq2Seq 模型中 decoder 的輸入信息主要來自 encoder, 由于本次任務的預測序列比較長,并且我們有天氣預報這種未來信息可以用,因此我們針對decoder 的每個時態設計了特定的特征 T1-T48(當前時態的天氣預報等其他空氣質量特征)。
Seq2Seq 模型訓練開銷大并且對于參數更敏感,我們使用 Cocob優化器[6],結合梯度截斷進行訓練。主要可以通過預測學習率加快收斂速度,對迭代的速度有一定幫助,也可以少量提高模型精度。
由于我們預測序列含有 48 狀態,每個狀態都依賴于之前狀態學習,而空氣質量以及天氣預報數據含有大量噪音,前面序列預測不準確經常會導致后面預測偏移較大,我們使用狀態間正則項,可以使得模型更穩定,提升模型精度。
由于未來每個狀態均有天氣預報特征,我們不同于傳統的 decoder,在未來時態也輸入了本狀態特征(空氣預報等特征),這樣相對于把這些特征直接輸入到 encoder 端具有更強的表達能力,并且可以緩解長序列梯度消失等問題。
模型融合
模型融合是算法大賽中常用的提高模型精度方法,有些比賽在競爭激烈的后期用了幾十甚至上百模型。由于本次比賽賽制是每天早上 8 點提交,預測未來 2 天成績,相對于靜態測試集更接近真實工業屆天級更新模型場景。為了平衡模型精度和迭代成本,我們用了 5 個基模型,融合結構主要是 2 層 stacking 結構[7],第1層(L1) 是基模型,主要包括 GBDT/DNN/Seq2Seq 等模型差異以及特征差異,第2層(L2) 模型 L1 模型之后的 7 天數據進行訓練。基于非線性模型的L2 模型有更強的表達能力,也是我們之前比賽最常用方案之一。
由于天氣數據噪音重等數據特點,采用非線性模型如GBDT易引起模型過擬合。我們最終根據融合建模特點采用基于約束的線性模型,并且我們基于時間,地點等多個維度進行了統計,發現不同模型在不同預測段之間的相對精度有一定差異,不同于一個整體的L2模型,我們對每一個預測小時分別求解一個L2模型,精度有進一步提升。相對于L2在基于約束的線性模型的基礎上基于統計適當引入非線性,取得表達能力與泛化能力的一個平衡。
下面是單模型和融合模型的結果,相對于更依賴網絡調優的深度學習模型, GBDT 模型更依賴于特征工程,深度學習與樹模型本身有較強的差異性產生較大的融合增益。

空氣質量預測問題不同于KDD Cup 早年的一些廣告、推薦類題目,已經在工業屆有了大量應用,我們的努力也是做了初步探索。我們先是從數據與特征角度出發,對天氣預報做了大量特征以及添加高斯噪音都處理,同時又在時間與空間維度進行進一步添加特征。而單純從特征角度解決問題也逐漸遇到瓶頸,我們進一步運用深度學習模型角度對時間以及空間角度進行進一步建模,可以與本身基于大量特征工程的樹模型有很好的補充,為后續融合打下很好的基礎。之后我們基于多個單模型優化最終的第二層融合模型。
在比賽中做了很多嘗試,我們認為這次過程中比較重要是基于空氣質量問題的理解以及找到問題的關鍵點,在建模過程中盡量從多方面(如特征+特征)對關鍵問題進行求解,從多個角度優化到高精度的模型是最終融合模型取得效果的基礎與關鍵。
進一步工作
我們曾嘗試用CNN建模地理位置拓撲關系,沒有取得明顯增益,考慮到地理數據不夠充足以及時間有限放棄此嘗試,考慮到基于地理位置的特征帶來了一定的增益,地理位置的進一步建模也是有意思的進一步嘗試點。
同時,在比賽中也提供了 5 年的北京歷史空氣質量數據,由于時間有限我們沒有使用,數據的增加,以及以年為單位進行建立周期性特征也是后面的一個嘗試點。
-
機器學習
+關注
關注
66文章
8377瀏覽量
132410 -
數據分析
+關注
關注
2文章
1427瀏覽量
34015
原文標題:中國團隊兩冠一亞包攬KDD CUP三項大獎,作者親述技術細節
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
冠軍說|第二屆OpenHarmony競賽訓練營冠軍團隊專訪
國產MCU廠商,靠什么從內卷中脫穎而出?
捷報 | 美格智能成功中標中國電信云芯AI模組招標項目

TE Connectivity AI Cup 第五屆全球競賽結果揭曉 中國高校團隊連續兩年奪得桂冠

NAS設備鐵威馬F4-424是如何從市場中脫穎而出的
解析中國儲能產業格局 探索背后發展之道
易特馳榮獲2024世界智能駕駛挑戰賽(WIDC)銀獎
運動相機為什么會脫穎而出
新一代驅動器產品,PI SCALE-iFlex? XLT如何脫穎而出?

慧視圖像處理板 究竟憑什么脫穎而出?

大模型推理顯卡選購指南:4090顯卡為何成為不二之選
歷史中的佼佼者,FPGA為何能夠脫穎而出?
回流焊爐選購指南:這些國內廠家為何能脫穎而出?

無刷電機技術演進與高速風筒行業現狀【其利天下高速風筒PCBA方案】






 工商網監
工商網監
評論