 如何能更快地訓練和部署物體檢測模型?
如何能更快地訓練和部署物體檢測模型?
我們如何能更快地訓練和部署物體檢測模型?
我們已經聽到了您的反饋,今天我們很高興地宣布支持在 Cloud TPU 上訓練物體檢測模型,模型量化(模型離散化),同時添加了一些新模型包括 RetinaNet 和 MobileNet。利用 Cloud TPU 我 們可以用前所未有的速度訓練和運行機器學習模型,您可以在 AI 博客上查看公告帖子。在這篇文章中,我們將引導您使用遷移學習在 Cloud TPU 上訓練量化的寵物品種檢測器。
整個過程 - 基于 Android 設備從訓練到推理 - 需要 30 分鐘,Google Cloud 的成本不到5美元。當你完成后,你將擁有一個 Android 應用程序(我們即將推出 iOS 相關教程),可以對狗和貓的品種進行實時檢測,并且此App占用手機上的空間不超過 12Mb。請注意,除了在 Google Cloud 中訓練對象檢測模型之外,您還可以在自己的硬件或 Colab上進行訓練。
注:Colab 鏈接 https://colab.research.google.com
開發環境搭建
首先,我們將安裝訓練以及部署模型所需的一系列庫并滿足一些先決條件。請注意,此過程可能比訓練和部署模型本身花費更長的時間。為方便起見,您可以在此處使用 Dockerfile,它提供安裝Tensorflow 所需的依賴項,并為本教程下載必要的數據集和模型。
注:Dockerfile 鏈接
https://github.com/tensorflow/models/blob/master/research/object_detection/dockerfiles/android/Dockerfile
如果您決定使用 Docker,則應該閱讀 “Google Cloud Setup” 部分,然后跳至 “Uploading dataset to GCS”。Dockerfile 還將為 Tensorflow Lite 構建以及編譯 Android 所需的依賴項。有關更多信息,請參閱隨附的 README 文件。
設置 GoogleCloud
首先,在Google Cloud Console中創建一個項目,并為該項目啟用結算。我們將使用 Cloud Machine Learning Engine 在 Cloud TPU 上運行我們的訓練任務。ML Engine 是 Google Cloud 的 TensorFlow 托管平臺,它簡化了訓練和部署 ML 模型的過程。要使用它,請為剛剛創建的項目啟用必要的 API。
注:
Google Cloud Console 中創建一個項目 鏈接https://console.cloud.google.com/
啟用必要的 API 鏈接
https://console.cloud.google.com/flows/enableapi?apiid=ml.googleapis.com,compute_component&_ga=2.43515109.-1978295503.1509743045
其次,我們將創建一個 Google 云存儲桶(Google Cloud Storage bucket),用于存儲模型的訓練和測試數據,以及模型檢查點。請注意,本教程中的所有命令都假設您運行在 Ubuntu 系統中。對于本教程中的許多命令,來源于 Google Cloud gcloud CLI,同時我們使用 Cloud Storage gsutil CLI 與 GCS 存儲桶進行交互。如果你沒有安裝這些,你可以在這里安裝 gcloud 和 gsutil。
注:
gcloud 鏈接
https://cloud.google.com/sdk/docs/quickstart-debian-ubuntu
gsutil 鏈接
https://cloud.google.com/storage/docs/gsutil_install
運行以下命令將當前項目設置為剛創建的項目,將YOUR_PROJECT_NAME 替換為項目名稱:
1 gcloud config set project YOUR_PROJECT_NAME
然后,我們將使用以下命令創建云存儲桶。請注意,存儲桶名稱必須全局唯一。
1 gsutil mb gs://YOUR_UNIQUE_BUCKET_NAME
這可能會提示您先運行 gcloud auth login,之后您需要提供發送到瀏覽器的驗證碼。
然后設置兩個環境變量以簡化在本教程中使用命令的方式:
1 export PROJECT="YOUR_PROJECT_ID"
2 export YOUR_GCS_BUCKET="YOUR_UNIQUE_BUCKET_NAME"
接下來,為了讓 Cloud TPU 能訪問我們的項目,我們需要添加一個 TPU 特定服務帳戶。首先,使用以下命令獲取服務帳戶的名稱:
1 curl -H "Authorization: Bearer $(gcloud auth print-access-token)"
2 https://ml.googleapis.com/v1/projects/${PROJECT}:getConfig
當此命令完成時,復制 tpuServiceAccount(它看起來像 your-service-account-12345@cloud-tpu.iam.gserviceaccount.com)的值,然后將其保存為環境變量:
1 export TPU_ACCOUNT=your-service-account
最后,給您的 TPU 服務帳戶授予 ml.serviceAgent 角色:
1 gcloud projects add-iam-policy-binding $PROJECT
2 --member serviceAccount:$TPU_ACCOUNT --role roles/ml.serviceAgent
安裝 Tensorflow
如果您沒有安裝 TensorFlow,請按照此處步驟操作。為了能在設備上進行操作,您需要按照此處說明使用 Bazel 通過源代碼安裝 TensorFlow 。編譯 TensorFlow 可能需要一段時間。如果您只想按照本教程中 Cloud TPU 訓練部分進行操作,則無需從源代碼編譯 TensorFlow,可以通過 pip,Anaconda 等工具直接安裝已發布的版本。
注:步驟操作 鏈接 https://www.tensorflow.org/install/
安裝 TensorFlow 對象檢測
如果這是您第一次使用 TensorFlow 對象檢測,我們將非常歡迎您的首次嘗試! 要安裝它,請按照此處說明進行操作。
注:說明 鏈接
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md
一旦對象檢測安裝完畢,請務必通過運行以下命令來測試是否安裝成功:
1 python object_detection/builders/model_builder_test.py
如果安裝成功,您應該看到以下輸出:
1 Ran 18 tests in 0.079s
2
3 OK
設置數據集
為了簡單起見,我們將使用上一篇文章中相同寵物品種數據集。該數據集包括大約 7,400 張圖像,涉及 37 種不同品種的貓和狗。每個圖像都有一個關聯的注釋文件,其中包括特定寵物在圖像中所在的邊界框坐標。我們無法直接將這些圖像和注釋提供給我們的模型; 所以我們需要將它們轉換為模型可以理解的格式。為此,我們將使用 TFRecord 格式。
為了直接深入到訓練環節,我們公開了文件 pet_faces_train.record 和 pet_faces_val.record,點擊此處這里公開。您可以使用公共 TFRecord 文件,或者如果您想自己生成它們,請按照此處的步驟操作。
注:這里公開 鏈接
http://download.tensorflow.org/models/object_detection/pet_faces_tfrecord.tar.gz
您可以使用以下命令下載并解壓縮公共 TFRecord 文件:
1 mkdir /tmp/pet_faces_tfrecord/
2 cd /tmp/pet_faces_tfrecord/
3curl "http://download.tensorflow.org/models/object_detection/pet_faces_tfrecord.tar.gz" | tar x*** -
請注意,這些 TFRecord 文件是分片的,因此一旦提取它們,您將擁有 10個 pet_faces_train.record 文件和 10 個 pet_faces_val.record 文件。
上傳數據集到 GCS
一旦獲得 TFRecord 文件后,將它們復制到 GCS 存儲桶的data子目錄下:
1 gsutil -m cp -r /tmp/pet_faces_tfrecord/pet_faces* gs://${YOUR_GCS_BUCKET}/data/
使用 GCS 中的 TFRecord 文件,并切換到本地計算機的 models/research 目錄。接下來,您將在 GCS 存儲桶中添加該 pet_label_map.pbtxt 文件。我們將要檢測的 37 個寵物品種一一映射到整數,以便我們的模型可以理解它們。最后,從 models/research 目錄運行以下命令:
1 gsutil cp object_detection/data/pet_label_map.pbtxt gs://${YOUR_GCS_BUCKET}/data/pet_label_map.pbtxt
此時,在 GCS 存儲桶的 data 子目錄中有 21 個文件:其中 20 個分片 TFRecord 文件用于訓練和測試,以及一個標簽映射文件。
使用 SSD MobileNet 檢查點進行遷移學習
為了能識別寵物品種,我們需要利用大量的圖片以及花費數小時或數天的時間從頭開始訓練模型。為了加快這一速度,我們可以利用遷移學習,采用基于大量數據上訓練的模型權重來執行類似的任務,然后在我們自己的數據上訓練模型,對預訓練模型的圖層進行微調。
為了識別圖像中的各種物體,我們需要訓練大量的模型。我們可以使用這些訓練模型中的檢查點,然后將它們應用于我們的自定義對象檢測任務。這種方式是可行的,因為對于機器而言,識別包含基本對象(如桌子,椅子或貓)圖像中的像素與識別包含特定寵物品種圖像中的像素沒有太大區別。
針對這個例子,我們將 SSD 與 MobileNe t結合使用,MobileNet 是一種針對移動設備進行優化的對象檢測模型。首先,下載并提取已在 COCO 數據集上預先訓練的最新 MobileNet 檢查點。要查看 Object Detection API 支持的所有模型的列表,請查看 model zoo。
注:最新 MobileNet 檢查點 鏈接
http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_0.75_depth_300x300_coco14_sync_2018_07_03.tar.gz
一旦成功解壓縮檢查點后,將 3 個文件復制到 GCS 存儲桶中。運行以下命令下載檢查點并將其復制到存儲桶中:
1 cd /tmp
2 curl -O http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_0.75_depth_300x300_coco14_sync_2018_07_03.tar.gz
3 tar x*** ssd_mobilenet_v1_0.75_depth_300x300_coco14_sync_2018_07_03.tar.gz
4
5gsutil cp /tmp/ssd_mobilenet_v1_0.75_depth_300x300_coco14_sync_2018_07_03/model.ckpt.* gs://${YOUR_GCS_BUCKET}/data/
當我們訓練模型時,將使用這些檢查點作為訓練的起點。現在,您的 GCS 存儲桶中應該有 24 個文件。目前我們已經準備好開始訓練任務,但我們需要一種方法來告訴 ML Engine 我們的數據和模型檢查點的位置。我們將使用配置文件執行此操作,我們將在下一步中設置該配置文件。我們的配置文件為我們的模型提供了超參數,訓練數據的文件路徑,測試數據和初始模型檢查點。
在 Cloud ML Engine 上使用 Cloud TPU 訓練量化模型
機器學習模型有兩個不同的計算組件:訓練和推理。在此示例中,我們利用 Cloud TPU 來加速訓練。我們在配置文件中對 Cloud TPU 進行設置。
在 Cloud TPU 上進行訓練時,可以使用更大的批量大小,因為它們可以更輕松地處理大型數據集(在您自己的數據集上試驗批量大小時,請確保使用 8 的倍數,因為數據需要均勻分配到 Cloud TPU)。在我們的模型上使用更大的批量大小,可以減少訓練步驟的數量(在本例中我們使用 2000)。
針對于此訓練任務的焦點損失函數也適用于 Cloud TPU,損失函數在配置文件中的定義如下所示:
1 loss {
2 classification_loss {
3 weighted_sigmoid_focal {
4 alpha: 0.75,
5 gamma: 2.0
6 }
7 }
損失函數用于計算數據集中每個示例的損失,然后對其進行重新計算,為錯誤分類的示例分配更多的相對權重。與其他訓練任務中使用的挖掘操作相比,此邏輯更適合 Cloud TPU。你可以在 Lin 等人中閱讀更多關于損失函數的內容(2017)。
初始化預訓練模型檢查點然后添加我們自己的訓練數據的過程稱為遷移學習。配置中的以下幾行告訴我們的模型,我們將從預先訓練的檢查點開始進行轉移學習。
1 fine_tune_checkpoint: "gs://your-bucket/data/model.ckpt"
2 fine_tune_checkpoint_type: "detection"
我們還需要考慮我們的模型在經過訓練后如何使用。假設我們的寵物探測器成為全球熱門,深受廣大動物愛好者喜愛,并在寵物商店隨處可見。我們需要采用一種可擴展、低延遲的方式處理這些推理請求。機器學習模型的輸出是一個二進制文件,其中包含我們模型的訓練權重,這些文件通常非常大,但由于我們需要直接在移動設備上部署此模型,所以需要此二進制文件盡可能小。
這就是模型量化的用武之地。利用量化技術我們可以將模型中的權重壓縮為 8-bit 的定點表示。配置文件中的以下幾行將生成量化模型:
1 graph_rewriter {
2 quantization {
3 delay: 1800
4 activation_bits: 8
5 weight_bits: 8
6 }
7 }
通常經過量化,模型將在切換到量化訓練之前按一定數量的步驟進行全方位精度訓練。配置文件中的 delay 參數告訴 ML Engine 在 1800 步訓練步驟之后開始量化權重并激活。
為了告訴 ML Engine 訓練和測試文件以及模型檢查點的位置,您需要在我們為您創建的配置文件中更新幾行以指向您的存儲桶。 從 research 目錄中,找到文件 object_detection/samples/configs/ssd_mobilenet_v1_0.75_depth_quantized_300x300_pets_sync.config。將所有 PATH_TO_BE_CONFIGURED 字符串更新為 GCS 存儲桶中 data 目錄的絕對路徑。
例如,train_input_reade r 配置部分將如下所示(確保 YOUR_GCS_BUCKET 為您的存儲桶的名稱):
1 train_input_reader: {
2 tf_record_input_reader {
3 input_path: "gs://YOUR_GCS_BUCKET/data/pet_faces_train*"
4 }
5 label_map_path: "gs://YOUR_GCS_BUCKET/data/pet_label_map.pbtxt"
6 }
然后將此量化配置文件復制到您的 GCS 存儲桶中:
1 gsutil cp object_detection/samples/configs/ssd_mobilenet_v1_0.75_depth_quantized_300x300_pets_sync.config gs://${YOUR_GCS_BUCKET}/data/pipeline.config
在我們啟動 Cloud ML Engine 的訓練工作之前,我們需要打包 Object Detection API,pycocotools 和 TF Slim。我們可以使用以下命令執行此操作(從 research / 目錄運行此命令,并注意括號是命令的一部分):
1 bash
2 object_detection/dataset_tools/create_pycocotools_package.sh /tmp/pycocotools
python setup.py sdist
3 (cd slim && python setup.py sdist)
至此,我們已經準備好開始訓練我們的模型了!要啟動訓練,請運行以下 gcloud 命令:
1 gcloud ml-engine jobs submit training `whoami`_object_detection_`date +%s`
2 --job-dir=gs://${YOUR_GCS_BUCKET}/train
3 --packages dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz,/tmp/pycocotools/pycocotools-2.0.tar.gz
4 --module-name object_detection.model_tpu_main
5 --runtime-version 1.8
6 --scale-tier BASIC_TPU
7 --region us-central1
8 --
9 --model_dir=gs://${YOUR_GCS_BUCKET}/train
10 --tpu_zone us-central1
11 --pipeline_config_path=gs://${YOUR_GCS_BUCKET}/data/pipeline.config
請注意,如果您收到錯誤消息,指出沒有可用的 Cloud TPU,我們建議您在另一個區域進行重試(Cloud TPU 目前可用于 us-central1-b, us-central1-c, europe-west4-a, asia-east1-c)。
在啟動訓練工作之后,運行以下命令開始評估:
1 gcloud ml-engine jobs submit training `whoami`_object_detection_eval_validation_`date +%s`
2 --job-dir=gs://${YOUR_GCS_BUCKET}/train
3 --packages dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz,/tmp/pycocotools/pycocotools-2.0.tar.gz
4 --module-name object_detection.model_main
5 --runtime-version 1.8
6 --scale-tier BASIC_GPU
7 --region us-central1
8 --
9 --model_dir=gs://${YOUR_GCS_BUCKET}/train
10 --pipeline_config_path=gs://${YOUR_GCS_BUCKET}/data/pipeline.config
11 --checkpoint_dir=gs://${YOUR_GCS_BUCKET}/train
訓練和評估都應在大約 30 分鐘內完成。在運行時,您可以使用 TensorBoard 查看模型的準確性。要啟動 TensorBoard,請運行以下命令:
1 tensorboard --logdir=gs://${YOUR_GCS_BUCKET}/train
請注意,您可能需要先運行 gcloud auth application-default login。
在瀏覽器地址欄中輸入 localhost:6006,從而查看您的 TensorBoard 輸出。在這里,您將看到一些常用的 ML 指標,用于分析模型的準確性。請注意,這些圖表僅繪制了 2 個點,因為我們的模型是在很少的步驟中快速訓練。這里的第一個點代表訓練過程的早期,最后一個點顯示最后一步的指標。
首先,讓我們看一下 0.5 IOU(mAP @ .50IOU)平均精度的圖表:
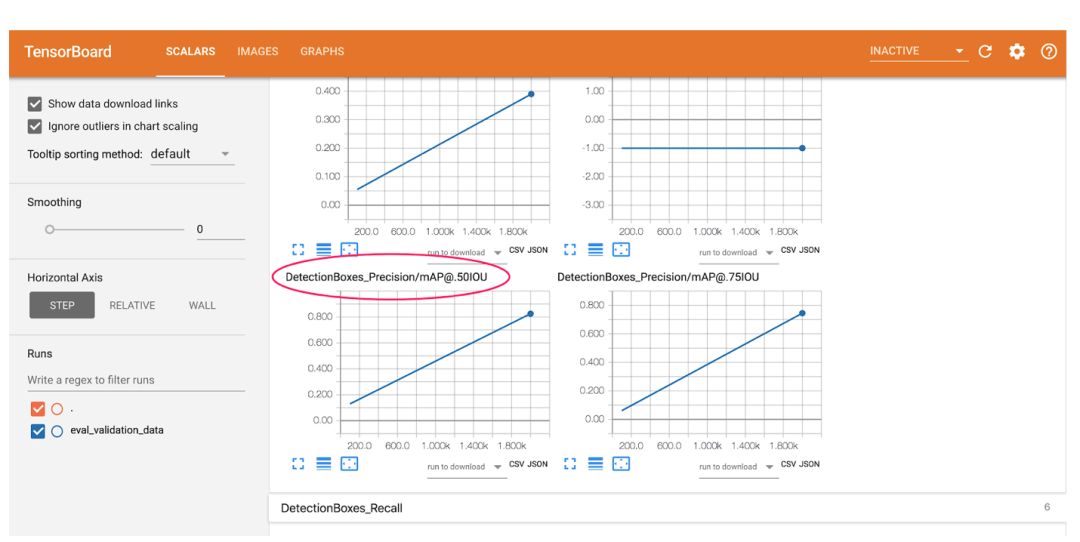
平均精度衡量模型會對所有 37 個標簽的正確性預測百分比。IoU 特定于對象檢測模型,代表 Intersection-over-Union。我們用百分比表示測量模型生成的邊界框與地面實況邊界框之間的重疊度。 此圖表展示的是測量模型返回的正確邊界框和標簽的百分比,在這種情況下 “正確” 指的是與其對應的地面實況邊界框重疊 50% 或更多。 訓練后,我們的模型實現了 82% 的平均精確度。
接下來,查看 TensorBoard 中的 Images 選項卡:
在左圖中,我們看到了模型對此圖像的預測,在右側我們看到了正確的地面實況框。邊界框非常準確,在本案例中,我們模型的標簽預測是不正確的。沒有 ML 模型是完美的。
使用 TensorFlow Lite 在移動設備上運行
至此,您將擁有一個訓練有素的寵物探測器,您可以使用 this Colab notebook 在零設置的情況下在瀏覽器中測試圖像。
注:this Colab notebook 鏈接
https://colab.research.google.com/github/tensorflow/models/blob/master/research/object_detection/object_detection_tutorial.ipynb
在手機上實時運行此模型需要一些額外的工作---在本節中,將向您展示如何使用 TensorFlow Lite 獲得更小的模型,并允許您充分利用針對移動設備進行的優化操作。 TensorFlow Lite 是 TensorFlow 針對移動和嵌入式設備的輕量級解決方案。它可以在移動設備中以低延遲和較小二進制文件的方式進行機器學習推理。TensorFlow Lite 使用了許多技術,例如量化內核。
如上所述,對于本節,您需要使用提供的 Dockerfile,或者從源代碼構建 TensorFlow(支持 GCP)并安裝 bazel 構建工具。請注意,如果您只想在不訓練模型的情況下完成本教程的第二部分,我們已為您制作了預訓練的模型。
為了使這些命令更容易運行,讓我們設置一些環境變量:
1 export CONFIG_FILE=gs://${YOUR_GCS_BUCKET}/data/pipeline.config
2 export CHECKPOINT_PATH=gs://${YOUR_GCS_BUCKET}/train/model.ckpt-2000
3 export OUTPUT_DIR=/tmp/tflite
我們首先獲得一個 TensorFlow 凍結圖,其中包含我們可以與 TensorFlow Lite 一起使用的兼容操作。首先,您需要安裝這些 python 庫。然后,為了獲取凍結的圖形,在 models/research 目錄下運行腳本 export_tflite_ssd_graph.py:
1 python object_detection/export_tflite_ssd_graph.py
2--pipeline_config_path=$CONFIG_FILE
3 --trained_checkpoint_prefix=$CHECKPOINT_PATH
4 --output_directory=$OUTPUT_DIR
5 --add_postprocessing_op=true
在 / tmp / tflite 目錄中,可以看到兩個文件:
tflite_graph.pb 和 tflite_graph.pbtxt(樣本凍結圖在這里)。請注意,該 add_postprocessing 標志使模型能夠利用自定義優化的后續檢測處理操作,該操作可被視為替代 tf.image.non_max_suppression。請務必不要混淆 export_tflite_ssd_graph 與 export_inference_graph。這兩個腳本都輸出了凍結的圖形: export_tflite_ssd_graph 將輸出我們可以直接輸入到 TensorFlow Lite 的凍結圖形,并且是我們將要使用的圖形。
接下來,我們將使用 TensorFlow Lite 通過優化轉換器來優化模型。我們將通過以下命令將生成的凍結圖形(tflite_graph.pb)轉換為 TensorFlow Lite Flatbuffer 格式(detect.tflite)。
1 bazel run -c opt tensorflow/contrib/lite/toco:toco --
2 --input_file=$OUTPUT_DIR/tflite_graph.pb
3 --output_file=$OUTPUT_DIR/detect.tflite
4 --input_shapes=1,300,300,3
5 --input_arrays=normalized_input_image_tensor
6 --output_arrays='TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1','TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3'
7 --inference_type=QUANTIZED_UINT8
8 --mean_values=128
9 --std_values=128
10 --change_concat_input_ranges=false
11 --allow_custom_ops
將每個攝像機圖像幀調整為 300x300 像素后,此命令采用輸入張量 normalized_input_image_tensor。
量化模型的輸出被命名為 'TFLite_Detection_PostProcess', 'TFLite_Detection_PostProcess:1', 'TFLite_Detection_PostProcess:2', 和 'TFLite_Detection_PostProcess:3',分別表示四個數組:detection_boxes,detection_classes,detection_scores 和 num_detections。如果運行成功,您現在應該在 / tmp / tflite 目錄中看到名為 detect.tflite 的文件。 此文件包含圖形和所有模型參數,可以通過 Android 設備上的 TensorFlow Lite 解釋器運行,并且文件小于 4 Mb。
在 Android 設備上運行模型
要在設備上運行我們的最終模型,我們需要使用提供的 Dockerfile,或者安裝 Android NDK 和 SDK。目前推薦的 Android NDK 版本為 14b ,可以在 NDK Archives 頁面上找到。請注意,Bazel 的當前版本與 NDK 15 及更高版本不兼容。Android SDK 和構建工具可以單獨下載,也可以作為 Android Studio 的一部分使用。為了編譯 TensorFlow Lite Android Demo,構建工具需要 API > = 23(但它將在 API > = 21 的設備上運行)。其他詳細信息可在 TensorFlow Lite Android App 頁面上找到。
在嘗試獲得剛訓練的寵物模型之前,首先運行帶有默認模型的演示應用程序,該模型是在 COCO 數據集上訓練的。要編譯演示應用程序,請從 tensorflow 目錄下運行此 bazel 命令:
1 bazel build -c opt --config=android_arm{,64} --cxxopt='--std=c++11'
2 //tensorflow/contrib/lite/examples/android:tflite_demo
上面的 apk 針對 64 位架構而編譯。為了支持 32 位架構,可以修改編譯參數為 -- config=android_arm。現在可以通過 Android Debug Bridge(adb)在支持調試模式的 Android 手機上安裝演示:
1 adb install bazel-bin/tensorflow/contrib/lite/examples/android/tflite_demo.apk
嘗試啟動該應用程序(稱為 TFLDetect)并將相機對準人,家具,汽車,寵物等。您將在檢測到的對象周圍看到帶有標簽的框。此應用程序使用 COCO 數據集進行訓練。
一旦成功運行通用檢測器,將其替換為您的定制寵物檢測器將會非常簡單。我們需要做的就是將應用程序指向我們新的 detect.tflite 文件,并為其指定新標簽的名稱。具體來說,我們將使用以下命令將 TensorFlow Lite Flatbuffer 資源復制到 app assets 目錄:
1 cp /tmp/tflite/detect.tflite
2 tensorflow/contrib/lite/examples/android/app/src/main/assets
我們現在將編輯 BUILD 文件以指向新模型。首先,在目錄 tensorflow / contrib / lite / examples / android / 中打開 BUILD 文件。然后找到 assets section,并將該行 “@tflite_mobilenet_ssd_quant//:detect.tflite” (默認情況下指向 COCO 預訓練模型)替換為您的 TFLite 寵物模型路徑(“ //tensorflow/contrib/lite/examples/android/app/src/main/assets:detect.tflite”) 。最后,更改 assets section 的最后一行以使用新的標簽映射。如下所示:
1 assets = [
2 "http://tensorflow/contrib/lite/examples/android/app/src/main/assets:labels_mobilenet_quant_v1_224.txt",
3 "@tflite_mobilenet//:mobilenet_quant_v1_224.tflite",
4 "@tflite_conv_actions_frozen//:conv_actions_frozen.tflite",
5 "http://tensorflow/contrib/lite/examples/android/app/src/main/assets:conv_actions_labels.txt",
6 "@tflite_mobilenet_ssd//:mobilenet_ssd.tflite",
7 "http://tensorflow/contrib/lite/examples/android/app/src/main/assets:detect.tflite",
8 "http://tensorflow/contrib/lite/examples/android/app/src/main/assets:box_priors.txt",
9 "http://tensorflow/contrib/lite/examples/android/app/src/main/assets:pets_labels_list.txt",
10 ],
我們還需要告訴我們的應用程序使用新的標簽映射。為此,在文本編輯器中打開 tensorflow / contrib / lite / examples / android / app / src / main / java / org / tensorflow / demo / DetectorActivity.java 文件,并找到變量 TF_OD_API_LABELS_FILE。更新此變量為:“ file:///android_asset/pets_labels_list.txt”,以指向您的寵物標簽映射文件。請注意,為了方便操作,我們已經制作了 pets_labels_list.txt 文件。
DetectorActivity.java 修改如下所示:
1 // Configuration values for the prepackaged SSD model.
2 private static final int TF_OD_API_INPUT_SIZE = 300;
private static final boolean TF_OD_API_IS_QUANTIZED = true;
3 private static final String TF_OD_API_MODEL_FILE = "detect.tflite";
4 private static final String TF_OD_API_LABELS_FILE = "file:///android_asset/pets_labels_list.txt";
一旦我們復制完 TensorFlow Lite 文件并編輯 BUILD 和 DetectorActivity.java 文件后,可以使用以下命令重新編譯并安裝應用程序:
1 bazel build -c opt --config=android_arm{,64} --cxxopt='--std=c++11'
2 //tensorflow/contrib/lite/examples/android:tflite_demo
3 adb install -r bazel-bin/tensorflow/contrib/lite/examples/android/tflite_demo.apk
現在到了見證奇跡的時刻:找到離您最近的阿貓阿狗,試著去檢測它們吧。
-
Android
+關注
關注
12文章
3923瀏覽量
127146 -
Google
+關注
關注
5文章
1758瀏覽量
57415 -
TPU
+關注
關注
0文章
138瀏覽量
20698
原文標題:使用 Cloud TPU 在 30 分鐘內訓練并部署實時移動物體探測器
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
華為云ModelArts入門開發(完成物體分類、物體檢測)

設計一個紅外物體檢測設備
部署基于嵌入的機器學習模型
如何使用eIQ門戶訓練人臉檢測模型?
基于運動估計的運動物體檢測技術研究
自動化所在視覺物體檢測與識別領域取得系列進展
Google發布新API,支持訓練更小更快的AI模型
傳統檢測、深度神經網絡框架、檢測技術的物體檢測算法全概述
華為物體檢測系統助力智慧安防
使用跨界模型Transformer來做物體檢測!







 工商網監
工商網監
評論