 一種新的高效神經架構搜索方法,解決了當前網絡變換方法的局限性
一種新的高效神經架構搜索方法,解決了當前網絡變換方法的局限性
利用機器學習技術代替人類專家來自動設計神經網絡架構近期成為了一個熱門研究話題。上海交大和MIT的研究團隊提出一種新的高效神經架構搜索方法,解決了當前網絡變換方法的局限性,且在十分有限的GPU算力下,達到了谷歌AutoML搜索神經網絡架構的效果。
最近,利用機器學習技術代替人類專家自動設計神經網絡架構(即神經架構搜索)成為一個熱門話題。但是,目前的資源密集型的方法實際上并不適用于大公司之外的一般研究團隊。
來自上海交大APEX數據與知識管理實驗室和MIT韓松老師在今年ICML 2018上發表的新研究“Path-Level Network Transformation for Efficient Architecture Search”表明,利用現有的成功的人工設計的架構來設計高效的網絡架構會容易得多。通過將現有成功的人工設計的架構與神經架構搜索方法在設計有效的路徑拓撲方面的強大能力相結合,可以在有限的計算資源下獲得更好的結果。
研究人員表示,他們的方法用更少的GPU達到了谷歌AutoML自動搜索神經網絡結構的效果。
對于這一系列工作,上海交通大學APEX實驗室和約翰霍普克羅夫特中心的張偉楠助理教授表示:“在當今大型科技公司憑借超高算力持續做出AutoML領域的高質量工作的大背景下,高校團隊可以將注意力集中在如何在低成本低算力的限制下巧妙設計AutoML新方法,這樣的解決方法其實更加親民,從而帶來更大的影響力和更廣泛的使用場景。”
麻省理工大學HAN Lab的韓松助理教授表示,“算力換算法”是當今AutoML系列工作的熱點話題。傳統AutoML需要上千塊GPU的大量算力,然而硬件算力是深度學習的寶貴資源。本文通過提出路徑級別的網絡變換、樹形的架構搜索空間和樹形的元控制器,可以在同樣性能的情況下將AutoML的硬件算力節省240倍(48,000 GPU-hours v.s. 200 GPU-hours)。在摩爾定律放緩、而數據集卻在不斷變大的時代,深度學習研究者值得關注算法性能和算力資源的協同優化。
結論和貢獻
本研究的貢獻包括:
提出路徑級變換(path-level transformation),以在神經網絡中實現路徑拓撲修改;
提出了樹形結構的RL元控制器來探索樹形結構的架構空間;
在計算資源顯著更少的情況下,在CIFAR-10和ImageNet(移動設置)上獲得了更好的結果。
從人工設計到自動架構搜索
在應用深度學習技術時,神經網絡架構往往是我們需要優化的一個非常重要的部分。傳統上,這項工作是由人類專家完成的,但這十分緩慢并且往往是次優的。因此,隨著計算資源的增加,研究人員開始使用機器學習工具,例如強化學習和神經網絡進化(neuro-evolution)來自動化架構設計的過程,這就是“神經架構搜索”(neural architecture search)。
從頭開始進行神經架構搜索
當前的大多數神經架構搜索方法都遵循一種類似的模式,即在驗證信號(validation signals)的指導下,從零開始探索給定的架構空間。
一個典型的例子(Google Brain在ICLR 2017發表的“Neural Architecture Search with Reinforcement Learning”)是使用一個隨機初始化的自回歸遞歸神經網絡(Auto-regressive RNN)來生成與特定網絡架構相對應的整個字符串。并通過策略梯度算法來訓練這個遞歸神經網絡,以最大化預期驗證性能。
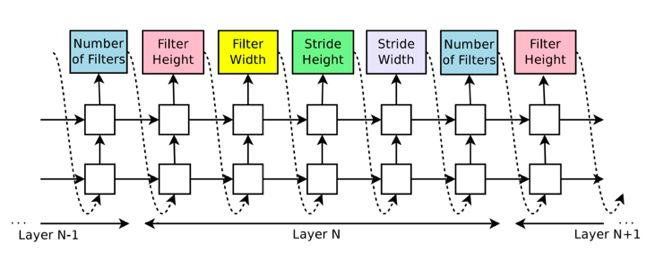
谷歌大腦提出的NAS上的Auto-regressive RNN
該模式具有如下優點:
首先,這是一個靈活的框架(可應用于自動化設計神經網絡架構、神經優化器、設備配置、數據增強策略等)。
其次,這種方法在CIFAR和ImageNet等基準數據集上取得了當時最佳的結果。
缺點:
首先,這一模式通常依賴于大量的計算資源來取得好的結果(例如,NASNet使用了48000 GPU-hours)。
其次,遵循這一模式的許多方法仍然無法擊敗人工設計的最佳架構,尤其在計算資源受限的情況下。
基于網絡變換( Network Transformation)的神經結構搜索
在這種情況下,一個想法便是:既然我們已經有許多成功的人工設計的架構,現有的神經架構搜索方法都無法輕易超越它們,那么為什么不利用它們呢?
為了實現這點,上交大團隊在AAAI 2018大會上發表的工作EAS(“Efficient Architecture Search by Network Transformation”)中提出:可以不從頭開始進行神經架構搜索,而是使用現有的網絡作為起點,通過網絡變換(Network Transformation)的方式來探索架構空間。具體的,他們使用了Net2Net操作(一類 function-preserving的網絡變換操作)來探索架構空間。
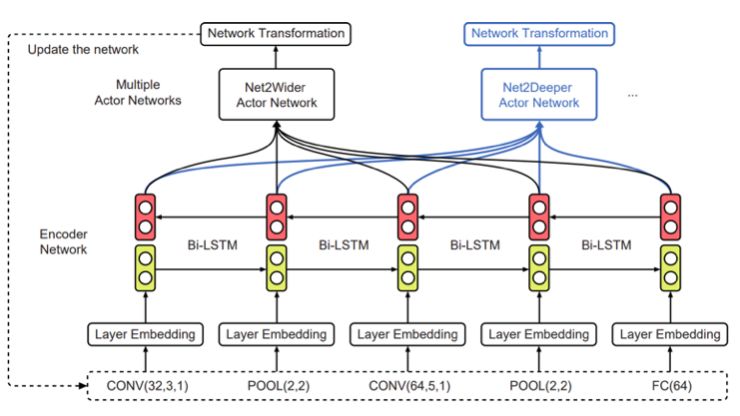
EAS的Meta-controller
而在之后的ICLR 2018上,來自CMU的研究人員提出了“N2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning”,即利用網絡壓縮操作來自動化地壓縮一個訓練好的網絡。
當前網絡變換方法的局限性
Net2Net和網絡壓縮操作的局限性在于他們都是layer-level的操作,例如添加(修剪)過濾器和插入(刪除)層。通過應用這些layer-level的操作僅能改變網絡的深度和寬度,而不能修改網絡的拓撲結構。這意味著在給定一個鏈式結構的起點時,它們總是會導致鏈式結構網絡。
然而,考慮到當前最先進的人工設計的架構(例如Inception模型、ResNets和DenseNets等)已經超越了簡單的鏈式結構布局,并且顯示出精心定制的路徑拓撲(path topology)的好處,因此對于這些基于變換的方法來說,這將是一個關鍵的需要解決的問題。
上交大和MIT的研究人員在ICML 2018發表的“Path-Level Network Transformation for Efficient Architecture Search”的主要目的便是解決這個問題。
路徑級網絡變換
研究人員提出將網絡變換從層級(layer-level)擴展到路徑級(path-level)。
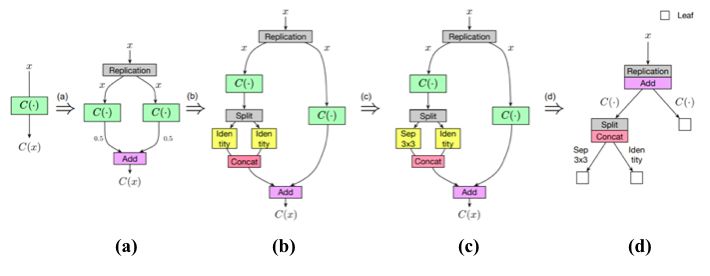
解決方案是從一些簡單的觀察開始。考慮一個卷積層,如果我們把多分支結構( multi-branch structure)中的每一個分支都設為該層的復制,那么給定相同的輸入,每個分支必然會產生相同的輸出,這些輸出的平均值也等于卷積層的輸出。
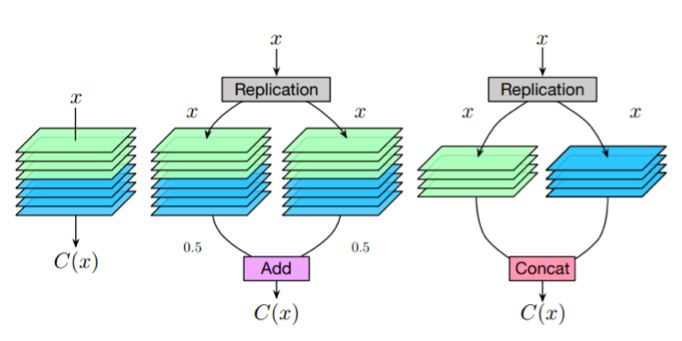
卷積層和等價的multi-branch結構
因此,我們可以構造一個等效的多分支結構(multi-branchstructure),并通過add操作合并卷積層。類似地,為了構造一個通過串聯合并的等效多分支結構,可以將卷積層沿著輸出通道維度分割為幾個部分,并將每個部分分配給相應的分支。這樣,它們輸出的串聯就等于卷積層的輸出。
對于其他類型的層,例如 identity 層和深度可分離卷積層(depth-wise separable convolution layer,),可以類似地進行這種等價的替換。
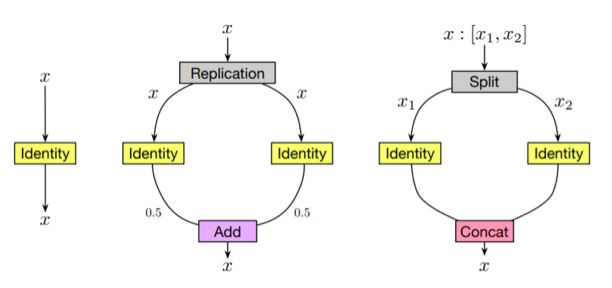
identity層和等價的multi-branch結構
更進一步,通過將這些等價替換與Net2Net操作相結合,就可以任意修改神經網絡的路徑拓撲。
樹形結構的架構空間
在路徑級網絡變換的基礎上,研究人員探索了一個樹形的結構空間(即多分支結構的一個簡單的擴展)。
形式上,樹形結構單元由節點和邊組成。在每個節點,定義有一個分配方案,用于確定如何為每個分支分配輸入特性映射(feature map);還有一個合并方案,用于確定如何合并分支的輸出。節點通過邊(edge)連接到每個子節點,而邊被定義為一個單元操作(例如卷積、池化、 identity等)。
給定輸入特性映射x,節點的輸出將基于其子節點的輸出遞歸地定義。首先將輸入特性映射分配給每個分支。然后在每個分支上,分配的特征映射由相應的邊和子節點處理。最后,合并它們以產生輸出。
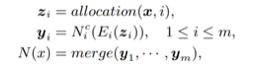
樹形結構的強化學習元控制器(RLMeta-Controller)
為了探索樹形結構空間,研究人員使用了一個強化學習元控制器。這里的策略網絡包括一個編碼器網絡,用于將輸入架構編碼成一個低維向量,以及各種softmax分類器,用于生成相應的網絡變換操作。
此外,由于輸入架構現在具有樹形結構,無法簡單用一個字符串序列來表示,因此這里使用了樹形結構編碼器網絡( tree-structured encoder network)。
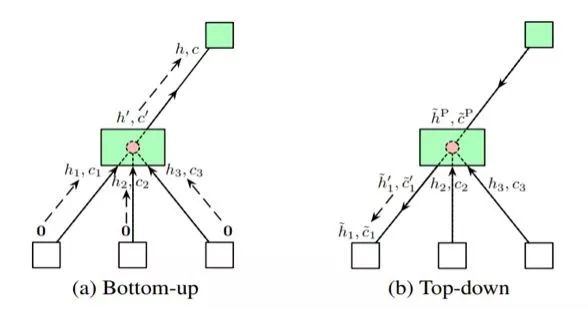
樹形結構的編碼器網絡
具體來說,除了用于在邊上執行隱藏狀態變換的普通LSTM單元之外,還引入了兩個額外的樹結構LSTM單元,以在節點上執行隱藏狀態轉換。如上圖所示,使用這3個LSTM單元,整個過程以自下而上和自上而下的方式進行,使每個節點中的隱藏狀態包含架構的所有信息,類似于雙向LSTM。
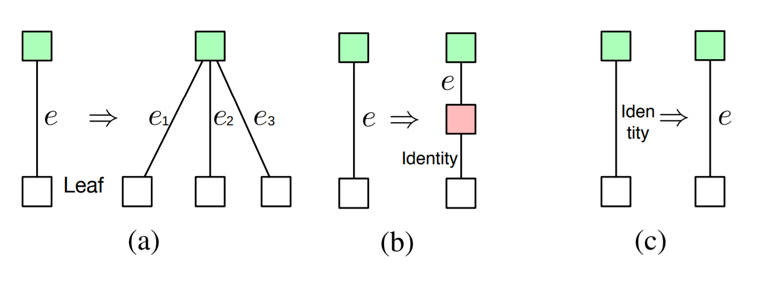
三種不同類型的決策
然后,給定每個節點的隱藏狀態,做出三種不同類型的決策。第一種類型是確定是否要將一個節點轉換為多個子節點。合并方案和分支數量都是預測的。第二種類型是確定是否插入新節點。第三種類型是用從一組可能的原始操作中選擇的層來替換 identity 映射。
實驗和結果
以下是論文中提供的受限的計算資源下(大約200 GPU-hours)找到的最好的樹形單元(TreeCell-A):
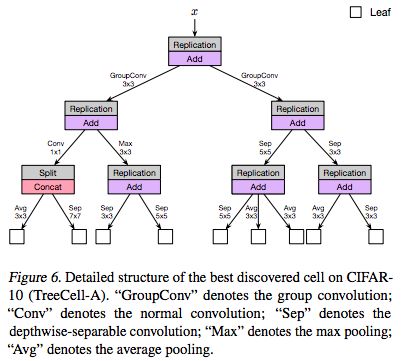
我們可以將這樣的樹形單元嵌入到已有的人類設計的網絡架構(例如DenseNet,PyramidNet)當中,而在CIFAR-10上的結果如下表所示
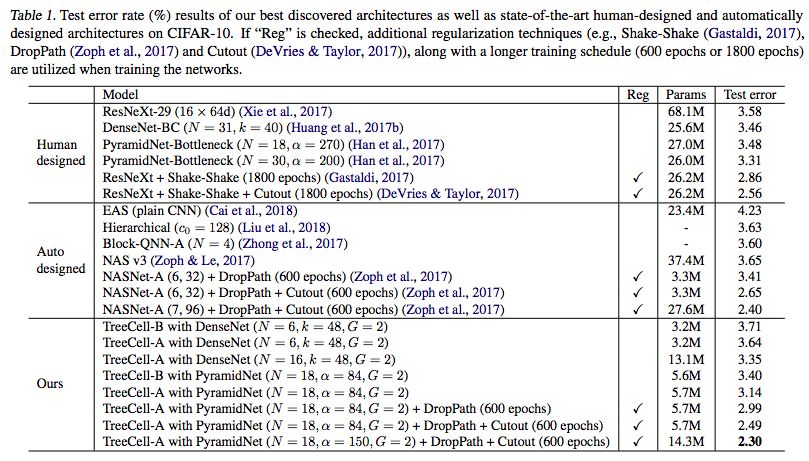
與原始的DenseNet和PyramidNet相比,樹形單元顯著提高了參數效率和測試誤差結果。與其他從頭開始的神經架構搜索方法(NASNet),TreeCell-A可以在大約一半參數的情況下實現更低的測試錯誤率(2.30% test error with 14.3M parameters versus 2.40% test error with 27.6M parameters)。更重要的是,其所使用的計算資源要比NASNet少得多。
當遷移到ImageNet(移動設置)時,與NASNets相比,樹形單元仍然可以獲得稍好的結果。
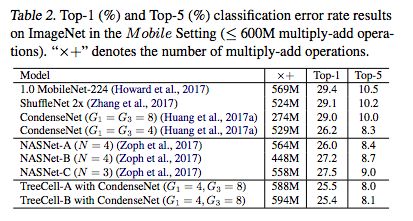
-
控制器
+關注
關注
112文章
16197瀏覽量
177395 -
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
機器學習
+關注
關注
66文章
8377瀏覽量
132406
原文標題:算力節省240倍!上交大、MIT新方法低成本達到谷歌AutoML性能
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
34063的局限性
無線網絡有什么局限性?
運算放大器的精度局限性是什么
一種基于高效采樣算法的時序圖神經網絡系統介紹
一種基于BP網絡的信號動態檢測方法
一種利用強化學習來設計mobile CNN模型的自動神經結構搜索方法

以進化算法為搜索策略實現神經架構搜索的方法
WSN中LEACH協議局限性的分析與改進






 工商網監
工商網監
評論