 為什么說AI芯片是FPGA的附庸?
為什么說AI芯片是FPGA的附庸?
央行放水之后,催生出了一大批手握重金的投資機構,而國內優秀的投資標的,特別是高科技領域的標的極為稀缺,AI芯片獲得投資易如反掌,一時間冒出來幾百家AI芯片公司,也給投機分子可乘之機。
作為國內最優秀的AI芯片公司,深鑒科技被以3億美元的價格賣給FPGA巨頭賽靈思。過去兩年,深鑒科技是國內AI芯片領域冉冉升起的一顆明星。這家2016年3月成立的初創公司目前已完成三輪融資,投資方包括金沙江創投、螞蟻金服、三星風投、賽靈思、聯發科等知名機構和公司。據媒體報道,其估值遠超過10億美金。如今以3億美元賣出,并且據稱核心團隊要鎖定4年內不得離開賽靈思。難道深鑒科技被賤賣?當然沒有!這是因為中國真正優秀的企業太少,而追逐的資本太多,優秀企業的估值已經到了完全沒有理性的地步。如果這些企業在美國,估值會萎縮數倍以上。
人工智能算法不大可能用ASIC,因為ASIC的開發周期太長,最少也需要3年才能量產,而人工智能算法迭代速度很快,幾乎是每半年就迭代一次,所謂人工智能ASIC,沒出廠就已經過時。另一個原因是人工智能芯片需要7納米工藝。
7納米時代,不是90納米時代,除非你像谷歌的TPU那樣自產自銷,否則,鐵定長期虧損。根據Gartner推算,10納米芯片的總設計成本約為1.2億美元,7納米芯片則為2.71億美元,較10納米高出兩倍之多!為什么人工智能芯片一定要用7納米?
所謂制程納米,是CMOS FET晶體管閘極的寬度,也就是閘長。閘長可以分為光刻閘長和實際閘長,光刻閘長則是由光刻技術所決定的。由于在光刻中光存在衍射現象以及芯片制造中還要經歷離子注入、蝕刻、等離子沖洗、熱處理等步驟,因此會導致光刻閘長和實際閘長不一致的情況。另外,同樣的制程技術下,實際閘長也會不一樣,比如雖然三星也推出了 14nm 制程芯片,但其芯片的實際閘長和 Intel 的 14nm 制程芯片的實際閘長依然有一定差距。
閘長越短,有兩大好處,一是可以提高晶體管密度,在同樣大小的硅晶圓制造更多的晶體管,需要的運算資源越強,對應的晶體管數量就越多。英偉達的Xavier Tegra處理器號稱是“全球第一個AI汽車超級芯片”,將采用臺積電16nm FinFET+工藝制造,集成多達70億個晶體管,性能方面,Xavier預計可以達到30 DL TOPS,比現在的Drive PX 2平臺提高50%,同時功耗只有30W。擁有多達八個NVIDIA自主設計的ARMv8-A 64位CPU核心,GPU則會基于下一代“Volta”(伏特)架構,最多512個流處理器,還有基于硬件的視頻流編碼解碼器,最高支持7680×4320 8K分辨率,以及各種IO輸入輸出能力。
英偉達還有一片GTX 1080 TI,同樣采用臺積電16nm FinFET+工藝制造,集成多達120億個晶體管,硅片面積是471平方毫米。英特爾至強E5 2600 V4,引入了14nm工藝,456平方毫米的核心面積里集成了72億個晶體管,相比之下上代22nm Haswell-EP Xeon E5-2600 v3只有56.9億個晶體管,而核心面積達662平方毫米。英偉達專為深度學習訂做的芯片Tesla P100,則在600平方毫米內集成了150個晶體管,仍然是臺積電的16nm FinFET+工藝制造,單精度浮點運算能力達9.3TFLOPS。高通的驍龍835則是集成了30億個晶體管。
另一個好處是降低功耗。
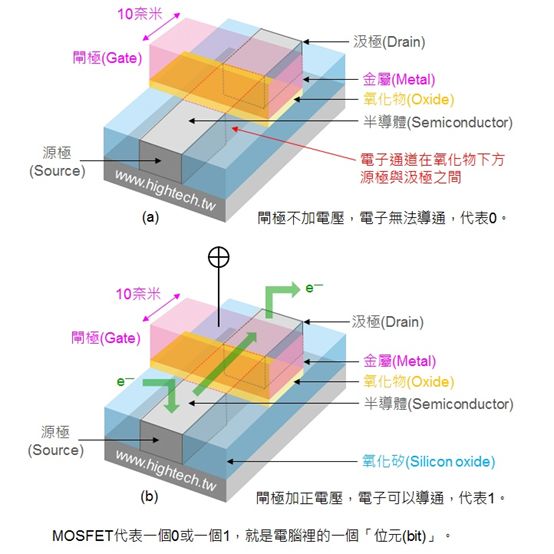
電流從 Source(源極)流入 Drain(漏級),Gate(閘極)相當于閘門,主要負責控制兩端源極和漏級的通斷。電流會損耗,而柵極的寬度則決定了電流通過時的損耗,表現出來就是手機常見的發熱和功耗,寬度越窄,功耗越低。
業內公認,10納米不是關鍵,關鍵是7納米,10納米只是低功耗過渡工藝,性能上與14納米相差無幾,意義不大,7納米才是關鍵之戰。
ASIC性能與功耗比最好,但開發周期長,開發成本最高,靈活性最差,如果出貨量低的話(如果采用7納米工藝,最低也要每年1億的出貨量,才能將芯片單價降低到100美元以下),要么單價高到幾千美元,要么廠家毛利率就是負的。最終結果都一樣,長期虧損。
無人車領域將是ASIC的噩夢,汽車領域對價格非常敏感,有些汽車廠家為了省成本,幾元錢的搖窗電機都要節約。能用商規元件就不用工規,成本也就差幾元。再有就是汽車出貨量低,全球汽車市場每年不過1億輛,遠不能和手機與筆記本電腦比。高端車出貨量更低,每年大約1000萬輛,無人車比高端車還要低。即便你市場占有率再高,出貨量也是很低。再有就是生命周期在縮短,以前一個車型可以有7-8年生命周期,現在競爭激烈,尤其中國市場,三四年不大改款的車就無人問津。雖然相對手機市場生命周期還算長,但趨勢已經很明顯,一款車型的生命周期正在迅速縮短。
臺積電會把你的訂單放到最后一個
芯片代工領域,臺積電拿下所有的7納米訂單,包括獨家供應蘋果的A12,這也是臺積電首次超越英特爾成為半導體制造工藝最先進的廠家,像人工智能這種強調運算能力的數字類邏輯芯片,先進工藝是必須采用的。所以說臺積電也拿下了所有人工智能芯片訂單, 三星毫無能力搶單。
韓國媒體報導三星的7奈米拿下高通驍龍855手機芯片訂單,消息應為誤傳。高通還是會把90%訂單交給臺積電,只把10%產品轉向三星,實際是為了降低供應鏈風險采取的策略。臺積電自然會優先照顧蘋果、高通、AMD、英偉達、華為、聯發科這些出貨量上億的大客戶,把小客戶訂單排在最后,這對Mobileye來說也非常不利。
對于臺積電來說,與一個大客戶合作需要的精力和一個小客戶合作所需要的精力是一致的,臺積電自然要優先照顧大客戶。三星一直是低價搶單,但目前來看,客戶完全不認同,比如華為,原本外界預估,因為臺積電代工費用較高,因此麒麟 710 處理器選擇三星的 10 奈米 LPP 制程來生產制造。但是,如今根據華為官方公布的結果,麒麟 710 處理器仍舊由臺積電的 12 奈米制程來進行代工生產,而非原先傳出的三星 10 奈米制程。顯示之前一直傳三星以較低價格搶單的情況,并沒有發生任何功效。最新的 EUV 曝光機一臺價格超過 1 億歐元,是 DUV 曝光機價格的 2 倍多,且使用 EUV 曝光機批量生產時會消耗 150萬瓦電力,遠超過現有的 DUV 曝光機。最重要是EUV技術不夠成熟,且成本略高,而三星欲速則不達,為了超越臺積電,導入EUV技術,臺積電仍然是DUV技術。當然,等EUV成熟,臺積電也會用。
為何臺積電總能在先進制程上屢戰屢勝呢?首先也是最重要的一點,臺積電從來不會試圖跳躍式發展,一步一步來,慢不代表錯,快不代表對。其次不像其他競爭者,與臺積電無利益沖突的客戶群(蘋果、賽靈思、英偉達、博通/華高、瑞薩、谷歌、海思、聯發科、AMD等)數量龐大,不斷地追求先進制程,投入研發,改善設計規則,與臺積電共同改善制程良率、降低成本,來加快量產速度。也就是說,臺積電不是一個人在戰斗,臺積電背后有著全球所有最頂尖的IC設計公司在支持。而且臺積電有超過50%產能,已完全折舊、做成熟制程;而且五年折舊的新機器設備,約可使用十五年以上,這樣可提供足夠的現金流,來大量投資初期獲利較差的最先進制程。
而三星和英特爾因不具足夠晶圓客戶,三星和英特爾盡量將舊制程轉換成新制程(機器設備多使用三至五年),并利用主流產品(三星的內存,英特爾的中央處理器)現金流,來補助晶圓代工的投資;因此三星會出現虧損,英特爾的營業利潤率和凈利率會遠遠落后臺積電。臺積電則使用其優異的布線,來微縮芯片尺寸和加快速度,而不是一味追求最小硅間閘和金屬間閘(metal pitch or interconnects),進行可能威脅順利量產的微縮。
英特爾也深知晶圓代工這個領域與臺積電競爭無異于自殺,與臺積電合作是雙贏之路。因此英特爾的FPGA大部分仍然由臺積電代工。
FPGA已經不是FPGA,更接近于ASIC
不是短期盈利無望,而是長期盈利無望,賣身給FPGA廠家肯定是最明智的選擇。在大部分人眼里,FPGA缺乏技術含量,純粹靠專利建立起護城河,FPGA只是個軀殼,算法才是靈魂。是深鑒讓FPGA獲得靈魂。果真如此的話,那估值就不是3億美元。實際上聲稱有能力做機器學習算法的公司據說超過3000家,而大規模生產FPGA的獨立廠家全球僅Xilinx一家。
算法應該說像人的視覺系統,FPGA則是人的大腦和軀殼。現在的FPGA早已不是當年的簡單地把寄存器和LUT整合在一起的白紙了,而是越來越像ASIC,或者說SoC。現在的FPGA都包含了復雜的接口資源,收發器資源,存儲器資源,有些則直接加入了多個ARM內核。單純的FPGA幾乎不存在了。
以深度學習、高性能運算、圖形科學領域最常見的Kintex FPGA來看,國內百度、騰訊、阿里都采用了KU115做計算加速。這款FPGA集成了大量資源,包括各種片上存儲器,Xilinx的FPGA中主要有分布式RAM 和 Block RAM 兩種存儲器。用分布式RAM 時其實要用到其所在的SliceM,所以要占用其中的邏輯資源;而Block RAM 是單純的存儲資源,但是要一塊一塊的用,不像分布式RAM 想要多少bit都可以。頂級的Virtex系列FPGA更繼承了高達8GB的HBM高寬帶內存。時鐘方面,有MMCM/PLL。
MMCM(mixed-mode clock manager):混合模式時鐘管理器,用于在與給定輸入時鐘有設定的相位和頻率關系的情況下,生成不同的時鐘信號。PLL(phase-locked loop):鎖相環,主要用于頻率綜合,使用一個PLL可以從一個輸入時鐘信號生成多個時鐘信號。這些主要用在收發器領域。
KU115里還包含5520個DSP,能夠大幅度提高圖像和視頻類任務的處理速度,這是類似GPU的并行運算架構,可以說這片FPGA還包含一個小GPU。這個DSP可以對應乘法累加器、乘加器或單步/n步計數器。級聯多個DSP48E邏輯片可執行復雜的功能。例如,不使用額外的FPGA架構資源的情況下實現復雜乘法器或n階FIR濾波器。對某些如FFT運算,速度大大提升。Virtex系列頂配有12288個DSP,性能達21897GMAC/s。

Xilinx的Soc+FPGA系列產品則完全可以叫SoC了,其不僅包含多個ARM CPU內核,還有針對安全領域的R5內核,還有Mali 400這樣的GPU,最夸張的是RFSoC把射頻的ADC/DAC也集成了,還有SD-FEC。
目前集成電路設計基本上都是用IP核搭積木的形式。IP核分為行為(Behavior)、結構(Structure)和物理(Physical)三級不同程度的設計,對應描述功能行為的不同分為三類,即軟核(Soft IP Core)、完成結構描述的固核(Firm IP Core)和基于物理描述并經過工藝驗證的硬核(Hard IP Core)。軟核就是我們熟悉的RTL代碼;固核就是指網表;而硬核就是指指經過驗證的設計版圖。ARM還是以軟核為主的。
IP軟核(Soft IP Core):通常是用硬件描述語言(hardware Description Language,HDL)文本形式提交給用戶,它經過RTL級設計優化和功能驗證,但其中不含有任何具體的物理信息。據此,用戶可以綜合出正確的門電路級設計網表,并可以進行后續的結構設計,具有很大的靈活性,借助于EDA綜合工具可以很容易地與其他外部邏輯電路合成一體,根據各種不同半導體工藝,設計成具有不同性能的器件。其主要缺點是缺乏對時序、面積和功耗的預見性。而且IP軟核以源代碼的形式提供的,IP知識產權不易保護。
IP硬核(Hard IP Core)是基于半導體工藝的物理設計,已有固定的拓撲布局和具體工藝,并已經過工藝驗證,具有可保證的性能。其提供給用戶的形式是電路物理結構掩模版圖和全套工藝文件。由于無需提供寄存器轉移級(Register transfer level,RTL)文件,因而更易于實現IP保護。其缺點是靈活性和可移植性差。
IP固核(Firm IP Core)的設計程度則是介于軟核和硬核之間,除了完成軟核所的設計外,還完成了門級電路綜合和時序仿真等設計環節。一般以門級電路網表的形式提供給用戶。
深鑒只是做了最上層的基于PC的應用算法,要想讓算法在嵌入式系統中流暢運行,還需要大量的工作,而這正是Xilinx做的。這就好像圖像識別算法,基于PC的幾百家都不止,但要一直到車內的ARM系統上,表現會大大折扣,完全不具備實時性,也就無法應用。
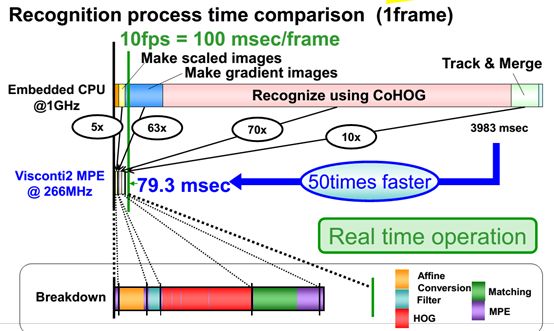
上圖是一個典型的行人識別算法HOG+SVM所需要時間的對比,硬核只需要79.3毫秒,軟核需要3983毫秒,所以純軟核的設計要么用極簡單的算法,要么用英偉達貴到飛起的芯片,即便如此,也不能和硬核比。所以單純的算法公司,特別是復雜視覺處理算法公司如果不能將算法用芯片來承載,那就不可能成功。當然,融資還是能成功的,畢竟還有很多投資者不是真正懂技術。
-
FPGA
+關注
關注
1626文章
21678瀏覽量
602037 -
人工智能
+關注
關注
1791文章
46896瀏覽量
237670
原文標題:AI芯片可能只是FPGA的附庸
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI芯片可能只是FPGA的附庸
手把手教你設計人工智能芯片及系統--(全階設計教程+AI芯片FPGA實現+開發板)
29頁PPT,詳細介紹Ouroboros的語音AI芯片
【免費直播】讓AI芯片擁有最強大腦—AI芯片的操作系統設計介紹.
AI芯片格局最全分析 精選資料分享
ai加速芯片
今日說“法”:FPGA芯片如何選型?
淺析GPU、FPGA、ASIC三種主流AI芯片的區別
用FPGA迎接AI時代而不是專用芯片
FPGA能滿足邊緣AI計算嗎?
FPGA、ASIC等AI芯片特性及對比





 工商網監
工商網監
評論