 如何使用Scrapy爬取網站數據
如何使用Scrapy爬取網站數據
編者按:斯克里普斯研究所數據科學家Michael Galarnyk介紹了如何使用Scrapy爬取網站數據。
我剛開始在業界工作時,首先意識到的一件事情是,有時候需要自己收集、整理、清洗數據。在這篇教程中,我們將從一個眾籌網站FundRazr收集數據。和許多網站一樣,這個網站有自己的結構、形式,還有眾多有用的數據,但卻沒有一個結構化的API,所以獲取數據并不容易。在這篇教程中,我們將爬取網站數據,將其整理為有序的形式,以創建我們自己的數據集。
我們將使用Scrapy,一個構建網頁爬蟲的框架。Scrapy可以幫助我們創建和維護網頁爬蟲。它讓我們可以專注于使用CSS選擇器和XPath表達式提取數據,更少操心爬蟲的內部工作機制。這篇教程比Scrapy官方教程要深入一點,希望你在讀完這篇教程后,碰到需要抓取有一定難度的數據的情況時,也能自行完成。好了,讓我們開始吧。
預備
如果你已經安裝了anaconda和google chrome(或Firefox),可以跳過這一節。
安裝Anaconda。你可以從官網下載anaconda自行安裝,也可以參考我之前寫的anaconda安裝教程(Mac、Windows、Ubuntu、環境管理)。
安裝Scrapy。其實Anaconda已經自帶了Scrapy,不過如果遇到問題,你也可以自行安裝:
conda install -c conda-forge scrapy
確保你安裝了chrome或firefox. 在這篇教程中,我將使用chrome.
創建新Scrapy項目
用startproject命令可以創建新項目:
該命令會創建一個fundrazr目錄:
fundrazr/
scrapy.cfg # 部署配置文件
fundrazr/ # 項目的Python模塊
__init__.py
items.py # 項目item定義
pipelines.py # 項目pipeline文件
settings.py # 項目設置文件
spiders/ # 爬蟲目錄
__init__.py
scrapy startproject fundrazr
使用chrome(或firefox)的開發者工具查找初始url
在爬蟲框架中,start_urls是爬蟲開始抓取的url列表。我們將通過start_urls列表中的每個元素得到單個項目頁面的鏈接。
下圖顯示,選擇的類別不同,初始url也不一樣。黑框高亮的部分是待抓取的類別。
在本教程中,start_urls列表中的第一項是:
https://fundrazr.com/find?category=Health
接下來,我們將看看如何訪問下一頁,并將相應的url加入start_urls。
第二個url是:
https://fundrazr.com/find?category=Health&page=2
下面是創建start_urls列表的代碼。其中,npages指定翻頁的頁數。
start_urls = ["https://fundrazr.com/find?category=Health"]
npages = 2
for i in range(2, npages + 2 ):
start_urls.append("https://fundrazr.com/find?category=Health&page="+str(i)+"")
使用Srapy shell查找單個項目頁面
使用Scrapy shell是學習如何基于Scrapy提取數據的最好方法。我們將使用XPaths,XPaths可以用來選擇HTML文檔中的元素。
我們首先需要嘗試獲取單個項目頁面鏈接的XPath。我們將利用瀏覽器的檢查元素。
我們將使用XPath提取下圖中紅框內的部分。

我們首先啟動Scrapy shell:
scrapy shell 'https://fundrazr.com/find?category=Health'
在Scrapy shell中輸入以下代碼:
response.xpath("http://h2[contains(@class, 'title headline-font')]/a[contains(@class, 'campaign-link')]//@href").extract()

使用exit()退出Scrapy shell.
單個項目頁面
之前我們介紹了如何提取單個項目頁面鏈接。現在我們將介紹如何提取單個項目頁面上的信息。
首先我們前往將要抓取的單個項目頁面(鏈接見下)。
使用上一節提到的方法,檢查頁面的標題。
現在我們將再次使用Scrapy shell,只不過這次是在單個項目頁面啟動。
scrapy shell 'https://fundrazr.com/savemyarm'
提取標題的代碼是:
response.xpath("http://div[contains(@id, 'campaign-title')]/descendant::text()").extract()[0]
頁面其他部分同理:
# 籌款總額
response.xpath("http://span[contains(@class,'stat')]/span[contains(@class, 'amount-raised')]/descendant::text()").extract()
# 籌款目標
response.xpath("http://div[contains(@class, 'stats-primary with-goal')]//span[contains(@class, 'stats-label hidden-phone')]/text()").extract()
# 幣種
response.xpath("http://div[contains(@class, 'stats-primary with-goal')]/@title").extract()
# 截止日期
response.xpath("http://div[contains(@id, 'campaign-stats')]//span[contains(@class,'stats-label hidden-phone')]/span[@class='nowrap']/text()").extract()
# 參與數
response.xpath("http://div[contains(@class, 'stats-secondary with-goal')]//span[contains(@class, 'donation-count stat')]/text()").extract()
# 故事
response.xpath("http://div[contains(@id, 'full-story')]/descendant::text()").extract()
# url
response.xpath("http://meta[@property='og:url']/@content").extract()
Items
網頁抓取的主要目標是從無結構的來源提取出結構信息。Scrapy爬蟲以Python字典的形式返回提取數據。盡管Python字典既方便又熟悉,但仍然不夠結構化:字段名容易出現拼寫錯誤,返回不一致的信息,特別是在有多個爬蟲的大型項目中。因此,我們定義Item類來(在輸出數據之前)存儲數據。
import scrapy
classFundrazrItem(scrapy.Item):
campaignTitle = scrapy.Field()
amountRaised = scrapy.Field()
goal = scrapy.Field()
currencyType = scrapy.Field()
endDate = scrapy.Field()
numberContributors = scrapy.Field()
story = scrapy.Field()
url = scrapy.Field()
將其保存在fundrazr/fundrazr目錄下(覆蓋原本的items.py文件)。
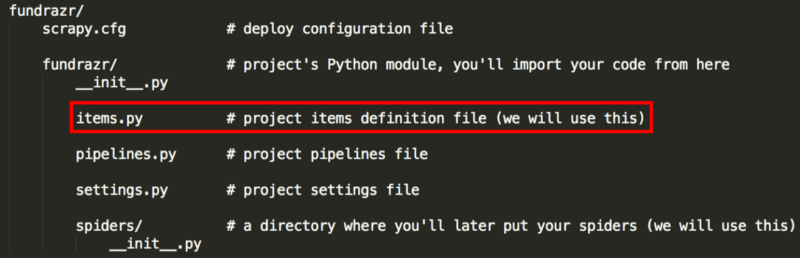
爬蟲
我們定義爬蟲類,供Scrapy使用,以抓取一個網站(或一組網站)的信息。
# 繼承scrapy.Spider類
classFundrazr(scrapy.Spider):
# 指定爬蟲名稱,運行爬蟲時要要到
name = "my_scraper"
# 定義start_urls、npages
# 具體定義見前
def parse(self, response):
for href in response.xpath("http://h2[contains(@class, 'title headline-font')]/a[contains(@class, 'campaign-link')]//@href"):
# 加上協議名稱
url = "https:" + href.extract()
# 異步抓取
yield scrapy.Request(url, callback=self.parse_dir_contents)
# 回調函數定義
def parse_dir_cntents(self, response):
item = FundrazrItem()
# 下面依次定義item的各字段,
# 具體定義參見前面的XPath表達式
yield item
為了節約篇幅,以上代碼僅僅呈現了爬蟲的大致結構,省略了導入依賴的語句以及前幾節已經涉及的具體代碼。完整代碼可以從我的GitHub倉庫獲取:mGalarnyk/Python_Tutorials
爬蟲代碼保存在fundrazr/spiders目錄下,文件命名為fundrazr_scrape.py。
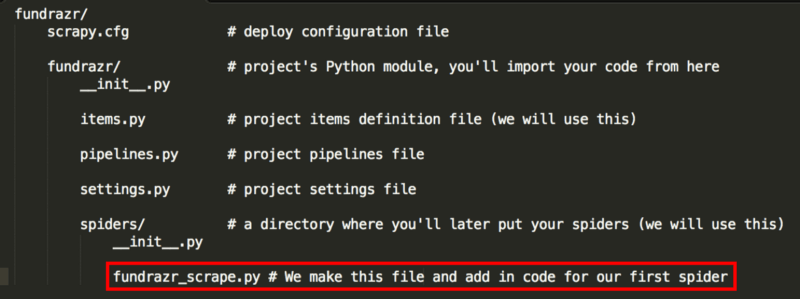
運行爬蟲
在fundrazr/fundrazr目錄下輸入:
scrapy crawl my_scraper -o MonthDay_Year.csv
數據輸出文件位于fundrazr/fundrazr目錄下。
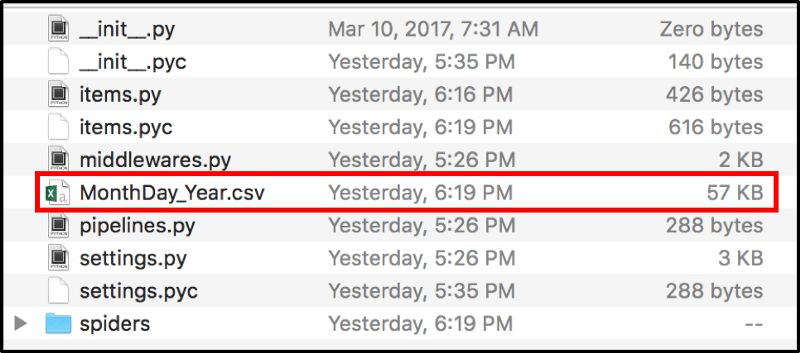
我們的數據
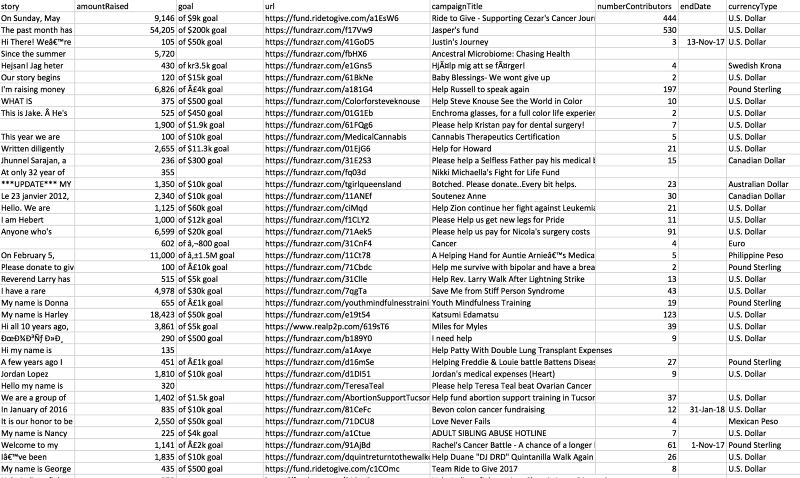
輸出的數據應該類似下面的圖片。由于網站不斷地更新,因此具體的眾籌項目會不同。另外,項目記錄間可能會有空行,這是excel解析csv文件時會出現的現象。
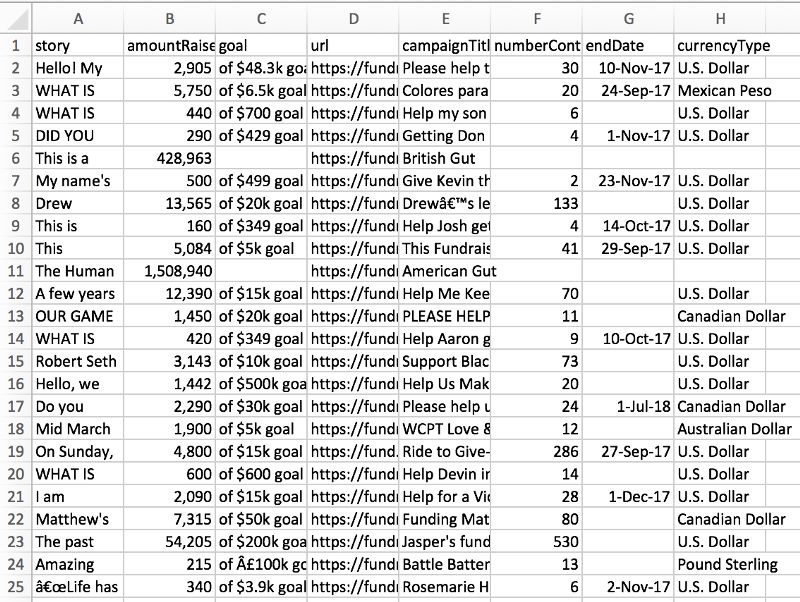
我將npages從2改到了450,并增加了download_delay = 2,抓取了約6000個項目,保存為MiniMorningScrape.csv文件。你可以從我的GitHu倉庫直接下載這一文件:mGalarnyk/Python_Tutorials
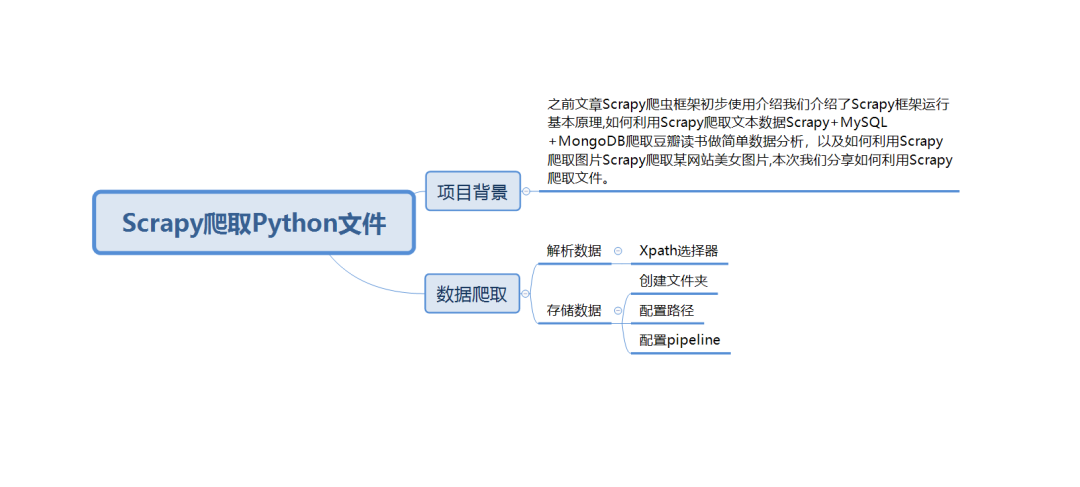
結語
創建數據集可能需要大費周章,而在學習數據科學時卻常常被忽略。
-
數據集
+關注
關注
4文章
1205瀏覽量
24641 -
選擇器
+關注
關注
0文章
106瀏覽量
14523 -
爬蟲
+關注
關注
0文章
82瀏覽量
6839
原文標題:使用Scrapy自建數據集
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Crawler:基于urllib+requests庫+偽裝瀏覽器實現爬取國內知名招聘網站信息(2018430之前)并保存在csv文件內
豆瓣電影Top250信息爬取
python爬蟲框架Scrapy實戰案例!

爬取電影網最新電影資源鏈接地址[1]
![<b class='flag-5'>爬</b><b class='flag-5'>取</b>電影網最新電影資源鏈接地址[1]](https://file.elecfans.com/web1/M00/D9/4E/pIYBAF_1ac2Ac0EEAABDkS1IP1s689.png)





 工商網監
工商網監
評論